Лёгкий инфраструктурный стек для команд разработки до десяти человек
Постройте лёгкий инфраструктурный стек: одно место для кода, один путь деплоя, один канал для алертов и одно хранилище логов, прежде чем инструментов станет слишком много.
Содержание
Почему разрастание инструментов мешает маленьким командам
Команда из шести человек редко теряет целый день сразу. Чаще она теряет по 10 минут здесь, 20 там и ещё полчаса, когда люди проверяют три инструмента, прежде чем ответить на один простой вопрос. В сумме это быстро накапливается.
Лишние инструменты почти незаметно создают дублирование работы. Кто-то пишет заметку о релизе в одном приложении, копирует её в чат, а потом вставляет то же самое в задачу. Кто-то другой настраивает алерты в двух местах, потому что никто не доверяет первому. В итоге команда делает одну и ту же работу дважды, лишь бы оставаться на одной волне.
Путаница становится ещё сильнее, когда код, деплои и логи лежат в разных местах. После обеда появляется баг. Один человек проверяет репозиторий, другой открывает панель деплоя, а кто-то третий ищет логи в четвёртой системе. И вместо того чтобы чинить проблему, команда сначала вручную восстанавливает хронологию.
Для команды из пяти или шести человек переключение между контекстами бьёт сильнее, чем принято признавать. Если два инженера по 30 минут прыгают между вкладками, чатами и дашбордами, это уже заметная часть внимания команды, которая уходит впустую. У маленьких команд нет лишних людей на археологию инструментов.
Хорошо работает простой тест: спросите двух коллег, где они посмотрят текущий код, последний деплой и первую ошибку, связанную с инцидентом. Если ответы различаются, стек уже разросся слишком сильно.
Вот почему лёгкие команды часто работают быстрее с меньшим количеством систем, а не с большим. Oleg Sotnikov показывал, что даже большие продакшен-нагрузки могут работать в более компактной схеме, если команда выбирает понятные источники истины и держится их. Скучные инструменты, используемые последовательно, выигрывают у кучи умных решений, которым никто до конца не доверяет.
Четыре места, которые нужны в первую очередь
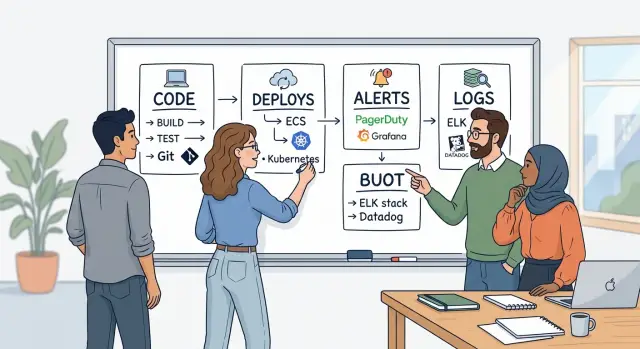
Небольшой команде сначала нужны четыре понятных дома: один для кода, один для деплоя, один для алертов и один для логов. Если на вопрос «Где это смотреть?» люди получают четыре одинаковых ответа, работа сразу становится спокойнее.
Начните с кода. Все должны знать, где находится настоящий репозиторий, где проходят pull request и кто может делать merge. За эту область должен отвечать один человек, обычно тимлид или самый опытный разработчик, чтобы права доступа, правила веток и резервные копии не расползались.
Потом выберите один путь деплоя. Команда должна выпускать изменения всегда одним и тем же способом — будь то один CI-пайплайн или один release-скрипт, которому все доверяют. Назначьте одного ответственного за этот путь, чтобы неудачные сборки, шаги релиза и правила отката оставались простыми, а не превращались в секретные знания внутри команды.
С алертами нужна та же дисциплина. Выберите одно место, которое отправляет уведомления, и сделайте его единственным каналом, который может разбудить людей. Один ответственный должен настраивать пороги и убирать шумные уведомления, потому что канал с ложными тревогами быстро приучает всех игнорировать настоящие.
Логи — последний кусок, и именно они важнее всего, когда что-то ломается в 9:10 в пятницу. Соберите логи приложения в одном месте, где их можно искать, с понятными названиями и базовым правилом хранения. Назначьте одного ответственного за формат логов и доступ к ним, чтобы команда могла искать по сервису, запросу или ошибке без угадываний.
Лёгкий инфраструктурный стек — это не про минимальное количество инструментов. Это про то, чтобы у каждой задачи было одно место и один человек, который поддерживает там порядок.
Когда баг попадает в продакшен, процесс должен быть очевидным:
- проверить репозиторий и найти изменение
- посмотреть историю деплоев и понять, что именно вышло
- проверить алерт и увидеть, когда началась проблема
- открыть логи и найти точную ошибку
Если эти четыре места понятны, даже команда из пяти человек может работать спокойнее и с меньшим количеством встреч.
Как выбрать стек за один день
У большинства маленьких команд сначала проблема не в инструментах. Проблема в доверии. Если код лежит в одном месте, деплой происходит в двух, алерты приходят из трёх приложений, а логи хранятся где попало, люди просто теряют время на догадки.
Начните с быстрого инвентаря. Откройте документ или доску и перечислите все инструменты, которые команда использовала за последний месяц для кода, деплоя, алертов и логов. Включите и «временные» тоже. Лёгкий инфраструктурный стек начинает проступать как только вы видите дубли.
Потом задайте по одному прямому вопросу в каждой области: какой инструмент люди действительно проверяют в обычный рабочий день? Оставьте тот, который закрывает ежедневную задачу. Не держите второй только потому, что когда-то он помог в редком случае в 2 часа ночи. Редкие проблемы важны, но они не должны определять всю схему для команды из шести человек.
Простой способ принять решение:
- Запишите все текущие инструменты в разделах кода, деплоя, алертов и логов.
- Обведите тот, которому команда больше всего доверяет в каждой области.
- Проверьте, закрывает ли он большую часть повседневной работы без лишних связок.
- Запишите, какие инструменты вы отключите в этом месяце.
- Поставьте ревью в календарь через 30 дней.
Список «перестать использовать» должен быть явным. Если не назвать инструменты, от которых вы отказываетесь, они продолжают жить в привычках, старых закладках и случайных уведомлениях. Так хаос возвращается.
Простой пример: если инженеры пушат код в GitLab, деплои идут из GitLab CI, но алерты по-прежнему приходят из трёх облачных панелей, оставьте GitLab для кода и деплоя, а потом выберите один источник алертов и отключите остальные. Для логов действуйте по тому же принципу. Одно место с поиском лучше, чем четыре неполных.
Через 30 дней посмотрите, что люди открывали, игнорировали и обходили. Если никто не скучал по отключённому инструменту, значит, решение было удачным.
Выберите одно место для кода
Лёгкий инфраструктурный стек начинается с одного понятного дома для кода. Если исходники лежат в одном инструменте, pull request — в другом, а CI — в третьем, маленькая команда теряет время на базовых вопросах: какая ветка сейчас актуальна? Где было согласование? Какой билд соответствует этому изменению?
Старайтесь держать код, ревью и CI как можно ближе друг к другу. Обычно лучше всего подходит один инструмент. Когда в одном месте видны коммит, обсуждение, пайплайн и тег релиза, люди ошибаются реже, а новые коллеги быстрее входят в работу.
Oleg часто использует для этого self-hosted GitLab, потому что код, merge request и CI остаются вместе. Сам инструмент не так важен, как правило: выберите один дом и перестаньте разносить решения по коду между чатом, почтой и личными заметками.
Используйте одно правило ветвления, которое всем легко запомнить без wiki. Для команды меньше десяти человек часто хватает такого набора:
- держать
mainготовой к выпуску - использовать короткие ветки для каждого изменения
- требовать одно ревью перед merge
- исправлять сломанные сборки до начала новой работы
Каждому репозиторию нужен ещё и владелец. Это не значит, что один человек охраняет каждую строку. Это значит, что один человек поддерживает репозиторий в порядке, закрывает старые ветки, обновляет базовую документацию и решает, кто должен ревьюить неясные изменения.
Release notes и решения по коду должны оставаться рядом с кодом. Если кто-то объясняет рискованное изменение только в Slack, этот контекст исчезнет через неделю. Пишите причину в merge request, в сообщении коммита или в короткой заметке в репозитории.
Права доступа должны быть скучными. Дайте права на запись тем, кто выпускает работу, права администратора — очень немногим, и не делайте уникальных исключений для каждого человека. Маленькие команды обычно вляпываются в проблемы тогда, когда правила доступа начинают напоминать таблицу.
Когда одно место хранит всю историю кода — от идеи до merge, остальной стек становится намного проще доверять.
Выберите один путь деплоя, которому доверяет вся команда
Деплой должен быть скучным. Если один человек знает «правильный» способ, а все остальные спрашивают в чате, процесс уже слабый.
Держите staging и production на одном и том же пути. Соберите приложение один раз, прогоните те же проверки и двигайте один и тот же релиз дальше. Когда у production есть свои тайные шаги, маленькие команды выпускают вместе с кодом ещё и страх.
Любой инженер должен уметь запустить обычный деплой по письменной инструкции. Это не значит, что у всех должен быть свободный доступ к production. Это значит, что никому не нужны скрытые знания вроде «попроси Alex перезапустить worker» или «для этого сервиса используй другую команду».
Храните правила окружений в одном месте, внутри вашего deployment pipeline и его конфигурации. Там же держите правила согласования, правила веток, обработку секретов и шаги релиза. Если половина правил живёт в wiki, а вторая половина — в старых shell-скриптах, люди начнут гадать, а угадывать в production быстро становится дорого.
Откат нужно тренировать, а не надеяться на него. Проведите безопасный тестовый rollback до первого реального инцидента. Засеките время. Если команде нужно пятнадцать минут, чтобы вспомнить шаги, исправьте это сейчас, а не во время аварии.
История деплоев должна отвечать на пять вопросов без лишних поисков:
- кто запустил деплой
- какой commit или версия вышли
- какое окружение изменилось
- прошли ли проверки
- когда кто-то сделал rollback
Это важнее, чем многие ожидают. Когда баг появляется после обеда, понятная история деплоев может сэкономить тридцать минут обвинений и путаницы.
Если вы уже используете инструмент вроде GitLab CI/CD, держите путь простым и понятным именно там, а не разносите его по дополнительным дашбордам. Один доверенный поток деплоя делает для инфраструктуры маленькой команды больше, чем набор хитрых скриптов.
Настройте алерты на реальные проблемы
Большинство команд до десяти человек попадает в неприятности, когда алертят на мелочи системы, а не на боль пользователей. Начните с поломок, которые заметны сразу: не работает вход, не проходят платежи, страницы выдают 500 errors, или фоновая задача зависает настолько, что блокирует заказы, отчёты или сообщения.
Хороший лёгкий инфраструктурный стек относится к алертам как к прерыванию работы, а не к украшению. Если алерт будит человека, у этого человека должно быть понятное действие, которое можно выполнить за несколько минут.
Отправляйте все алерты в один общий канал и в один on-call путь. Общий канал даёт всей команде контекст. On-call путь будит только того, кто отвечает в этот момент. Если страницы приходят всем на всё, люди быстро начинают глушить уведомления.
Для начала достаточно короткого списка:
- у реальных пользователей не работает вход или checkout
- error rate вышел за пределы обычного диапазона
- очередь задач выросла настолько, что задерживает работу с клиентами
- диск, сертификат или база данных почти дошли до предела и могут сломать production
Убирайте всё, на что никто не реагирует. Если алерт срабатывает три раза, а команда говорит «это можно игнорировать», удалите его или превратите в проверку на дашборде. Всплеск CPU, который сам быстро проходит, часто просто шум. Сбой платежа — нет.
Каждому алерту нужна короткая заметка о реакции. Пишите просто: что это значит, куда смотреть в первую очередь, как безопасно сделать rollback и кто отвечает за исправление. Одна короткая заметка может сэкономить 20 минут догадок, когда человек устал.
Проверьте хотя бы один алерт специально. Безопасно сломайте что-то в staging или на минуту отключите неважный worker. Потом посмотрите, что произошло. Пришёл ли алерт? Объяснил ли он, что именно сломалось? Смог ли on-call человек исправить это без лишних вопросов? Команды, которые используют Sentry, Prometheus, Grafana или простые uptime checks, сталкиваются с одним и тем же правилом: если по алерту никто не может действовать, это не алерт.
Храните логи в одном месте, где их можно искать
Когда появляется ошибка, никто не хочет прыгать между тремя дашбордами и двумя серверами только ради понимания, что случилось. Соберите логи приложения, фоновых задач и прокси в одном месте с самого начала. Если запрос ломается на границе, затем таймаутится в приложении и после этого падает worker, вы должны уметь пройти этот путь за минуты.
Используйте одинаковые названия сервисов везде. Если приложение в production называется billing-api, не называйте его в других окружениях billing, billing-service и api-billing. Единые названия помогают фильтрам работать, делают алерты понятнее и не заставляют людей гадать, какой поток логов правильный.
Читаемые строки логов в начале важнее, чем навороченная структура. Простая строка с меткой времени, уровнем, названием сервиса, request ID и понятным сообщением лучше, чем неаккуратный JSON-blob с полями, которыми никто не пользуется. Более сложную структуру можно добавить позже, если у команды действительно появится такая необходимость.
Правило хранения должно быть простым. Оставляйте столько истории, сколько нужно, чтобы разбирать реальные проблемы. Для многих маленьких команд 7–30 дней полноценных логов достаточно, а более долгое хранение нужно только для аудита или биллинга. Всё, что живёт дольше, должно иметь причину, потому что расходы на хранение тихо растут.
Несколько сохранённых поисков тоже помогают сильнее, чем кажется.
- 5xx errors по сервисам
- упавшие фоновые задачи
- медленные запросы от прокси
- логи по одному request ID
- ошибки в окне деплоя за последний час
Это одна из тихих побед в лёгком инфраструктурном стеке. Oleg часто строит работу вокруг простой observability-схемы с централизованными логами и понятными названиями сервисов, потому что маленьким командам лучше живётся с одним поиском, которому они доверяют, чем с грудой инструментов, в которых никто до конца не разбирается.
Простая схема для команды из шести человек
Команда из шести человек может держать всё очень компактно. Представьте один продукт, один API и одно web-приложение. Два инженера в основном занимаются backend-задачами, два — frontend и изменениями продукта, один человек ведёт продукт, и один отвечает за поддержку.
Такой команде обычно хватает только четырёх домов для повседневной работы:
- GitLab для кода, merge request и истории изменений
- GitLab CI/CD для всех сборок, тестов и деплоев
- Grafana alerting для сбоев, замедлений и всплесков ошибок
- Loki для логов API, web-приложения и фоновых задач
Эта схема закрывает большую часть работы, потому что все идут по одному пути. Разработчик пушит код, открывает merge request, и GitLab CI запускает тесты. Если проверки проходят, пайплайн деплоит сначала в staging, потом в production. Никто не хранит секретный скрипт на ноутбуке. Никто не деплоит вручную «только один раз».
Когда деплой ломается, команда может отреагировать быстро, потому что сначала смотреть нужно только в одно место. GitLab показывает упавший шаг. Если деплой прошёл, но пользователи получают ошибки, Grafana alerting срабатывает в течение нескольких минут. Loki показывает точный сервис, запрос и время, поэтому инженер видит, проблема в API, web-приложении или плохой конфигурации.
Rollback тоже должен идти тем же путём деплоя. Один инженер откатывает изменение или продвигает предыдущий релиз, и команда возвращается на стабильную базу за несколько минут, а не ищет что-то по серверам.
Во время инцидента продукт и поддержка не должны копаться в технических инструментах. Им нужен один общий дашборд Grafana с несколькими понятными метриками: uptime, количество ошибок, время ответа и то, запущен ли последний релиз. Этого достаточно, чтобы отвечать клиентам и решать, нужно ли ставить запуск на паузу, не дергая инженеров на каждое обновление.
Частые ошибки, из-за которых стек становится грязным
Большинство маленьких команд не создают грязный стек специально. Они приходят к нему по одному «небольшому улучшению» за раз. Кто-то добавляет второй инструмент, потому что на одном экране всё выглядит красивее, кто-то оставляет старый «пока что», и через пару месяцев уже никто не помнит, где живёт настоящий источник истины.
Частая ошибка — менять инструменты ради одной приятной функции вместо реальной потребности. Более красивый вид деплоя или более удобный график алертов редко исправляют слабый процесс. Если команда уже коммитит код в одном месте, то и деплой должен идти по тому же пути, если только сама система не требует чего-то иного.
Миграции создают ещё одну путаницу. Команды переносят алерты в новый сервис, но старые правила не выключают. Потом люди получают дублирующиеся страницы, игнорируют их и приучают себя воспринимать алерты как фоновый шум. Так настоящие проблемы и пропускают.
Деплои часто расползаются по неправильной причине. Backend-команда использует один способ, frontend-команда — другой, а кто-то всё ещё выкатывает worker со скрипта на ноутбуке. Для разных систем действительно могут быть нужны разные шаги. Но разным командам не нужны отдельные привычки только потому, что они сидят в разных чатах.
Логи чаще всего ломаются тише. Они остаются на серверах, которые никто не проверяет, пока что-то не упадёт. Во время инцидента разработчик открывает терминал, ищет вручную и тратит 20 минут, пытаясь собрать картину из кусочков. Одно searchable-хранилище логов экономит это время каждый раз.
Разрастание инструментов начинается и тогда, когда никто не отвечает за решение. Команды покупают новый продукт ещё до того, как назовут человека, который будет чистить старые алерты, удалять мёртвые дашборды и говорить «нет» дублированию. Лёгкий инфраструктурный стек остаётся лёгким тогда, когда у каждого инструмента есть одна задача и один владелец. Если вы не можете назвать оба пункта за десять секунд, стек уже уходит в сторону.
Быстрые проверки перед добавлением нового инструмента
Лёгкий инфраструктурный стек остаётся лёгким потому, что команда чаще говорит «нет», чем «да». Большинство лишних инструментов не проваливаются в первый день. Они проваливаются через три месяца, когда никто уже не помнит, зачем их добавили, а у всех появилось ещё одно окно, которое можно игнорировать.
Прежде чем что-то подключать, запишите причину в одну строку. Если вы не можете объяснить проблему простым предложением, команда, скорее всего, реагирует на шум, а не закрывает реальный пробел.
Используйте такой короткий тест:
- Спросите, может ли текущий инструмент решить задачу через одну настройку, небольшой скрипт или более чистый workflow. Многие команды покупают новое приложение ради проблемы, которую можно решить за 20 минут.
- Решите, кто будет отвечать за новый инструмент следующие шесть месяцев. Если никто не хочет эту работу, не добавляйте его.
- Проверьте, заменяет ли он что-то старое. Если он только добавляет ещё одну панель, ещё один вход и ещё один источник алертов, это, скорее всего, лишний шум.
- Смотрите на еженедельное использование, а не на редкие крайние случаи. Если вся команда не будет трогать его почти каждую неделю, планка для такого инструмента должна быть очень высокой.
- Проговорите причину вслух другому человеку. Если она звучит расплывчато или слишком громоздко, идея ещё сырая.
Простой пример помогает. Допустим, команда хочет отдельное приложение для инцидентов, потому что один алерт в прошлую пятницу выглядел неаккуратно. Это слабый аргумент. Если текущий инструмент алертов может лучше маршрутизировать сообщения и глушить дубликаты, начните с этого. Если новое приложение заменит два старых инструмента, и один инженер согласится за него отвечать, аргумент становится сильнее.
Маленьким командам лучше всего подходят скучные решения, которые можно быстро объяснить. Если инструмент экономит время, что-то заменяет и у него есть понятный владелец, добавляйте его. Если он просто даёт команде ещё одну вкладку, пропустите.
Что делать, если стек уже разросся
Начните с того, где команда теряет время каждый день. Если люди постоянно спрашивают, какой репозиторий актуален, какой pipeline действительно деплоит или какой канал алертов важен, это и есть первая задача для уборки. Исправляйте то, что создаёт повторяющуюся путаницу, а не то, что просто некрасиво выглядит на схеме.
Не меняйте всё сразу. Маленькие команды часто создают вторую путаницу, когда в один и тот же месяц одновременно меняют хостинг кода, деплой, логи и алерты. Уберите один перекрывающийся инструмент, перенесите привычку вместе с ним, а потом дайте команде немного времени почувствовать разницу.
Короткая карта стека помогает больше, чем ещё один спор. Держите её на одной странице, чтобы новый сотрудник мог прочитать её за пять минут и понять, куда идти.
- Какой репозиторий является источником истины?
- Какой путь выводит код в production?
- Какие алерты будят человека?
- Где сначала ищут логи?
Такая простая карта быстро показывает и дубли. Если уведомления о деплое приходят из одного инструмента, сбои — из другого, а логи лежат в двух местах, у вас не лёгкий инфраструктурный стек. У вас лишний шум.
Команды также часто застревают потому, что у каждого есть любимый инструмент. В таком случае попросите короткое внешнее ревью. Свежий взгляд может заметить пересечения, которые команда уже считает нормой.
Вот где может помочь fractional CTO. Oleg Sotnikov много лет сокращает инфраструктурные потери, упрощает продакшен-системы и помогает командам внедрять AI-assisted operations, не ломая повседневную работу. Короткий разбор от человека с таким опытом может закрыть споры об инструментах, убрать дублирование и задать более безопасный порядок изменений.
Лучше всего уборка работает тогда, когда она остаётся скучной. Выберите одну проблему, удалите один дубль, обновите карту стека и продолжайте, пока люди перестанут спрашивать, где что находится.


