LangGraph против plain code для agent workflows: что выбрать
LangGraph и plain code для agent workflows по-разному влияют на отладку, изменения логики и обновления. Это руководство показывает, где лучше подходит каждый вариант.
Содержание
Почему этот выбор быстро становится запутанным
Большинство команд не начинают с планирования полноценного agent framework. Сначала есть prompt, один вызов инструмента, возможно, повторная попытка и немного памяти. Через неделю в скрипте уже появляются ветвления, fallback-ветки, шаги согласования и логи, которые никто не хочет читать.
Вот тогда framework начинает казаться привлекательным. Он даёт структуру и более понятный поток. Но подвох простой: он может упорядочить хаос, а может просто спрятать его под новыми понятиями, лишним state и правилами, которые вам вообще не были нужны.
Поэтому это решение сложнее, чем кажется. Plain code даёт прямой контроль. Можно отследить каждую функцию, посмотреть каждую переменную и поменять странное поведение без борьбы с графовой моделью. LangGraph даёт более прочную форму для многошаговых агентов, особенно когда поток продолжает расти.
На практике команды чувствуют не архитектурные споры, а вполне приземлённые вещи. Ошибки всплывают только после второй повторной попытки. Агент без видимой причины дважды вызывает один и тот же инструмент. Изменение state на одном шаге ломает следующий. Небольшая правка продукта растекается по слишком большому числу файлов. Обновление меняет поведение, которое вы считали стабильным.
Plain code обычно начинает болеть через расползание. Файлы разрастаются, подходы расходятся, и каждый новый branch добавляет ещё один особый случай. Frameworks часто начинают мешать позже. Появляются скрытый state, более сложная отладка и боль при обновлениях, когда библиотека меняет то, как работают nodes, persistence или callbacks.
Команды теряют время, когда выбирают слишком рано. Одни берут framework, потому что демо выглядит аккуратно. Другие принципиально избегают его, а потом вручную собирают половину того же самого. Ни один из этих шагов автоматически не умнее другого.
Настоящий вопрос в том, где вы хотите держать сложность: в собственном коде, где она видна, или внутри абстракции, которая помогает сейчас, но потом может начать мешать.
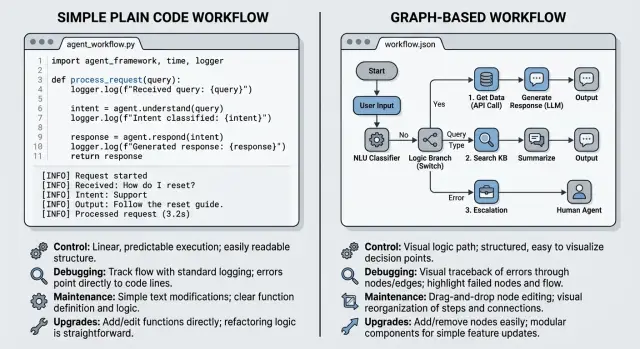
Что даёт plain code
Plain code кажется проще, потому что путь виден в одном месте. Одна функция вызывает следующую, условие отправляет работу в другую ветку, и flow можно прочитать сверху вниз, не изучая сначала framework.
Это важнее, чем многие признают. На раннем этапе прямой код обычно выигрывает по понятности. Если ваш агент принимает сообщение пользователя, определяет intent, достаёт данные и пишет ответ, нескольких небольших функций на Python или TypeScript часто достаточно.
Логи и breakpoint'ы на этом этапе тоже ощущаются естественнее. Можно остановить программу ровно на той строке, где output модели выглядит странно, вывести вход и выход и посмотреть локальные переменные, не переводя всё в nodes, edges и общие объекты state.
Простой вариант может состоять из четырёх функций: classify_request(), search_docs(), draft_answer() и review_answer(). Когда что-то ломается, обычно сразу понятно, где искать, потому что каждый шаг — это просто код.
Plain code также даёт полный контроль над важными деталями. Вы сами решаете, когда повторять неудачный вызов модели, что хранить между шагами, как обрабатывать плохой ответ инструмента и когда останавливаться для human review.
Но у этого удобства есть предел. Когда workflow выходит за пределы нескольких шагов, код начинает расползаться по файлам, helper-функциям и особым случаям. Простая цепочка превращается в ветвления, ретраи, fallback-ветки, обработку таймаутов и проверки state. В какой-то момент логика перестаёт быть очевидной.
Ещё вам приходится строить собственные guardrails. Обычно это означает правила для проверки state, ограничения на количество циклов, восстановление после ошибок, audit logs и безопасную передачу данных между инструментами. Команды часто пропускают эти части, потому что happy path и так работает. Через месяц агент странно ведёт себя на крайних случаях, и никому не нравится разбираться почему.
Так что plain code — это хорошая стартовая форма, но не всегда хорошая долгосрочная. Он остаётся удобным, пока workflow небольшой и команда ещё помнит каждую ветку.
Что меняет LangGraph
LangGraph предлагает описывать агента как graph, а не как скрипт. Node — это один шаг, например планирование, поиск документов, вызов инструмента или написание ответа. Edge решает, куда flow пойдёт дальше. State — это общие данные, которые проходят через весь запуск: запрос пользователя, результаты инструментов и заметки с предыдущих шагов.
Такая структура помогает, когда путь может разветвляться в нескольких направлениях. Если модель запрашивает инструмент, graph может направить выполнение в tool node. Если инструмент зависает по таймауту, graph может повторить попытку. Если ответ выглядит слабым, graph может отправить его на review вместо немедленного возврата.
То же поведение можно построить и на plain code. Разница — в форме. Graph даёт карту workflow, и эта карта становится полезной, когда агент перестаёт быть короткой цепочкой.
Представьте support-агента с несколькими ветками. Он определяет тип вопроса, отвечает на простые случаи напрямую, обращается к инструменту за данными по аккаунту, повторяет попытку один раз, если инструмент упал, и отправляет рискованные ответы на review. Такой поток проще обсуждать в graph, чем в длинном файле, полном вложенных условий.
Компромисс — дополнительная нагрузка на мышление. Команде теперь нужно думать в терминах nodes, edges и transitions state, а не только функций и переменных.
Абстракция также скрывает базовые детали flow. В plain code вы можете видеть весь цикл ретраев, условие остановки и fallback в одном месте. В graph-setup эта логика может оказаться разбросанной между кодом узлов, правилами маршрутизации и state фреймворка. Для большого workflow это может выглядеть чище. Но простой агент может стать сложнее для отслеживания, чем нужно.
Если у агента уже есть ветвления, ретраи, review-этапы и повторные передачи между инструментами, LangGraph начинает иметь смысл. Если он всё ещё ведёт себя как короткий скрипт с несколькими проверками, plain code обычно легче читать и дебажить.
Пример с support
Возьмём support-агента, который обрабатывает запросы на refund. Он читает сообщение, определяет тип проблемы, проверяет refund policy и готовит ответ для human approval. Этого достаточно, чтобы показать компромисс, не превращая всё в огромную систему.
Клиент пишет: «С меня списали дважды. Могу я получить refund?» Агент делает три вещи. Сначала определяет, что это billing. Потом проверяет policy и данные заказа. В конце готовит ответ, который объясняет, подходит ли refund под правила.
В plain code это часто выглядит как одна небольшая функция, вызывающая следующую. Вы классифицируете сообщение, получаете данные policy или заказа, готовите ответ и останавливаетесь за помощью, если на каком-то шаге произошёл сбой. Это скучно, а скучно — часто хорошо.
Если инструмент policy возвращает ошибку, потому что получил неправильный order ID, можно залогировать плохой input, повторить попытку один раз или перейти на заранее подготовленный ответ вроде: «Мне нужен человек, чтобы проверить этот заказ». Ошибка находится прямо рядом с вызовом инструмента, поэтому большинство разработчиков быстро замечают проблему.
В graph тот же flow делится на nodes и edges. Один node классифицирует. Другой проверяет policy. Третий готовит ответ. Если вызов инструмента падает, graph может направить запуск в retry node, затем в fallback node, а потом вернуть его в основной путь.
Это аккуратно, когда ветвлений много. Но это же меняет то, где вы ищете проблему. В plain code вы смотрите одну функцию и логи рядом с ней. В graph вы проверяете state узлов, правила edges и сохранённую историю запуска. Если агент повторяет попытку там, где должен был остановиться, баг может быть в routing rule, а не в самом вызове инструмента.
Ни один вариант не является магией. Для support-flow с одним основным путём и одной-двумя аварийными ситуациями plain code обычно проще представить и исправить. Если позже этому же агенту понадобятся approvals, escalations, циклы и отдельные пути для billing, shipping и fraud, graph начинает отрабатывать свою сложность.
Как принять решение
Начните с одного реального workflow, который уже создаёт работу или ошибки. Не проектируйте под воображаемое будущее с десятью агентами и бесконечными edge cases. Возьмите что-то конкретное, например support-агента, который проверяет заказ, готовит ответ и просит человека одобрить refunds выше заданной суммы.
Это скажет вам больше, чем любая таблица функций. Реальная работа показывает важные части: state, retries, шаги approvals и точки отказа.
Запишите workflow от начала до конца на одной странице. Включите каждый вызов инструмента, каждое решение и каждое место, где вмешивается человек. Потом посчитайте ветвления, ретраи, таймауты и циклы. Если у вас два или три чистых пути, plain code часто проще читать и тестировать. Если flow постоянно прыгает между состояниями, graph начинает себя оправдывать.
Потом спросите, кто будет дебажить это в 2 часа ночи. Если этому человеку комфортно жить в Python или TypeScript, логах, трассировках и stack trace, plain code может быть более безопасным выбором. Если нескольким людям нужно быстро видеть одну и ту же state machine и разбираться в transitions, LangGraph может помочь.
Ещё смотрите на поддержку, а не только на скорость сборки. Кто-то будет обновлять prompts, править tool schemas, чинить retries и разбираться с изменениями в библиотеке. Выбирайте ту схему, которую команда сможет понимать и через шесть месяцев.
Маленьким командам здесь особенно важно быть честными. Если всем владеет один senior engineer, ещё одна абстракция может превратить простой инцидент в поиски по всему проекту. С другой стороны, если workflow уже включает review-gates, возобновляемые шаги и повторные передачи между инструментами, тащить всё это в ad hoc code быстро надоедает.
Лучший выбор — тот, который команда сможет дебажить под давлением, менять без страха и объяснить новому сотруднику за десять минут.
Где отладка становится сложной
Отладка — это место, где спор перестаёт быть теоретическим.
В plain code вы обычно начинаете со stack trace. У вас есть файл, номер строки, локальные переменные и путь в коде, на котором всё сломалось. И снова: скучно — это хорошо, когда прод падает в 2 часа ночи.
В graph tool первым делом часто смотрят на state: какой node выполнился, что он записал, что решил следующий edge и как выглядели сохранённые данные на каждом шаге. Это может быть полезно, особенно когда агент проходит несколько веток перед тем, как упасть. Но это добавляет второй слой мышления. Теперь вы дебажите и бизнес-логику, и runtime графа.
Скрытый state — это то место, где поиск бага начинает буксовать. Узел может сам по себе выглядеть нормально, а настоящая проблема сидит в изменённом объекте state, хранилище памяти, изменившей форму tool result или callback, который записал что-то неожиданное. Чем дольше выполняется workflow, тем выше шанс, что плохое значение появилось несколько шагов назад.
Replay звучит как очевидный плюс, и иногда так и есть. Если вы можете заново прогнать те же inputs, те же model settings и те же tool outputs, replay помогает найти точный момент, когда всё пошло не так.
Но replay ещё и вводит людей в заблуждение. Если output модели меняется от запуска к запуску или инструмент обращается к живому API, replay перестаёт быть настоящим replay. Вы можете воспроизвести общую схему сбоя, но не сам сбой.
Есть простой тест. Можете ли вы точно повторить один упавший запуск? Можете ли вы посмотреть state до и после каждого шага? Видно ли, какой именно вызов инструмента или модели изменил результат? Сможет ли новый инженер пройти путь до ошибки меньше чем за 15 минут?
Если ответ нет, workflow сложнее в отладке, чем кажется. Часто именно в этот момент plain code кажется медленнее в разработке, но гораздо надёжнее.
Где появляется боль от обновлений
Боль от обновлений редко появляется в первую неделю. Она приходит позже, когда workflow уже работает, люди на него полагаются и никто не хочет тормозить поставку.
В plain code большинство изменений остаются локальными. Вы меняете функцию, обновляете тест и правите несколько своих call sites. Это всё ещё может раздражать, но радиус затрагивания обычно виден.
Обновления framework ощущаются иначе. Смена версии может поменять graph APIs, обработку state, правила checkpointing или поведение retries. Ваш код может продолжать работать, но выдавать другие результаты на edge cases. Это хуже, чем громкая ошибка, потому что команды доверяют зелёному deploy.
Расхождение state быстро становится дорогим
Изменение формы state — частая ловушка. Сначала команды передают loose object через несколько nodes и продолжают работу. Через полгода в этом объекте уже лежат routing flags, частичные ответы, метаданные пользователя, счётчики повторов и трассировки для human review.
Потом кто-то переименовывает поле, разделяет одно значение на два или меняет вложенную структуру. В plain code данные часто можно проследить через поиск и тесты. В graph setup старые checkpoints, возобновляемые запуски и вспомогательные слои могут дольше обычного сохранять старую форму.
Проблема усугубляется, когда команды строят обёртки вокруг framework. Небольшой helper для регистрации nodes сначала выглядит безобидно. Потом он разрастается в decorators, общие builders state, custom retry logic, hooks для трассировки и внутренние правила. И вот вы уже привязаны к двум движущимся целям: версии framework и собственному glue code.
Именно на это уходит время. Вы обновляете не только imports. Вы ещё и правите код, который изначально делал framework удобным.
Загруженные продукты платят больше за одно и то же изменение
Миграции ощущаются тяжелее, когда продукт уже активно используется. Если пользователи запускают flows каждый час, нельзя всё поставить на паузу и спокойно переписать state.
Боль от обновлений резко растёт, если у вас есть сохранённые checkpoints, очереди задач, общие helpers, используемые в нескольких workflow, дашборды, завязанные на старую форму событий, и on-call команды, которым нужны предсказуемые режимы отказа.
Небольшое breaking change может превратиться в неделю аккуратного rollout, replay-тестов и fallback-кода. Небольшие команды замечают это первыми. Если uptime важен, скучный код под вашим контролем часто стареет лучше, чем умная абстракция, за которой нужно присматривать.
Ошибки, которые команды делают в начале
Одна частая ошибка — добавлять framework слишком рано. Демонстрация работает, graph выглядит аккуратно, и кто-то решает, что workflow сразу нужен в формальной оболочке. Это часто создаёт больше работы по очистке позже.
Если flow всё ещё меняется каждую неделю, plain code переписывать проще. Можно быстро двигать шаги, переименовывать сущности и удалять плохие идеи, не таща за собой старые nodes и routing rules.
Ещё одна ошибка — зашивать бизнес-правила в prompt glue. Тогда простое правило, например кто может одобрить refund или когда lead должен эскалироваться в sales, оказывается размазанным между текстом prompt, условиями маршрутизации и helper-функциями. Через несколько недель никто уже не знает, где живёт настоящее правило.
Делите роли проще. Prompts должны отвечать за язык. Code должен отвечать за политику, проверки и side effects.
Команды ещё и пропускают тесты для сложных путей. Happy path проходит, и все идут дальше. Реальные сбои появляются в ретраях, таймаутах, пустом выводе инструмента, дублирующихся вызовах и fallback-ветках, которые срабатывают только под нагрузкой.
Небольшой support-агент может отлично выглядеть в staging и всё равно ломаться в production, потому что никто не проверил, что произойдёт после второго неудачного вызова инструмента. Именно там начинаются циклы, тихие потери данных и плохие ответы пользователю.
Диаграммы тоже получают слишком много кредита. Graph может сделать workflow более наглядным, но он не делает его проще в поддержке. Если каждый node скрывает кастомный state, правки prompt и правила retries, диаграмма — это просто украшение.
Ещё одна слабая зона — ownership. После запуска кто-то должен отвечать за изменения prompt, contracts инструментов, разбор инцидентов и обновления framework. Если никто не владеет этими задачами, workflow постепенно превращается в общий беспорядок.
Быстрая проверка перед добавлением ещё одного слоя
Новый framework в первый день кажется аккуратным. Через два месяца команда может платить за этот красивый diagram более медленными исправлениями, странными багами и кодом, к которому никто не хочет прикасаться.
Возьмите один реальный запрос как тест. Выберите запуск, который вызывает модель, использует инструмент, сохраняет state и возвращает что-то, что видит пользователь. Потом задайте несколько простых вопросов.
Сможет ли новый коллега пройти этот запрос от входа до финального результата без экскурсии? Если вы меняете один шаг, например заменяете retrieval call другим инструментом, вы правите один файл или гоняетесь за побочными эффектами по полпроекта? Если запуск падает, можно ли воспроизвести его с тем же prompt, state и результатами инструментов? Если модель изменится в следующем квартале, сможете ли вы заменить её без перестройки всего flow? И если кто-то спросит, зачем вообще нужен framework, сможет ли команда ответить одной-двумя конкретными фразами?
Последний вопрос особенно важен. «Потому что так чище» — это не настоящая причина. «Нам нужно сохранять state между шагами, иметь простой replay и графовый обзор для долгих запусков» — это настоящая причина. «Потому что все так делают» — нет.
Небольшой пример делает это нагляднее. Допустим, ваш support-агент читает тикет, проверяет данные аккаунта, просит модель подготовить черновик и отправляет ответ на approval. Если один таймаут на шаге account заставляет вас копаться в decorators, скрытом state и callbacks framework, вы добавили вес, а не ясность.
Если на большинство этих вопросов ответы слабые, подержитесь за plain code подольше. Небольшие функции проще тестировать, логировать и заменять. Добавляйте ещё один слой только тогда, когда боль реальная, повторяющаяся и достаточно дорогая, чтобы её оправдать.
Что делать дальше
Выберите один workflow, который уже приносит проблемы. Может быть, это support bot, который зацикливается, или lead triage flow, который отправляет неправильный ответ. Начните там, где сбой стоит денег, отнимает время команды или вызывает злые письма. Демо-flow мало что скажет.
Перед тем как выбирать инструмент, запишите, как workflow ломается сейчас. Держите это простым и конкретным. Возможно, модель выбирает не тот инструмент, state пропадает между шагами, ретраи скрывают первую ошибку, логи не показывают, какой prompt вызвал сбой, или обновление пакета меняет поведение небольшим, но неприятным образом.
Этот короткий список решает две задачи. Он показывает, что измерять, и не даёт команде выбрать graph library только потому, что диаграмма выглядит красиво.
Потом погоняйте workflow в реальной работе, или как можно ближе к ней, в течение нескольких недель. Смотрите, где люди реально застревают. Команды часто ошибаются в начале. Простой скрипт с чистыми логами может быть лучше более абстрактной схемы, пока flow не получит достаточно ветвлений, передач между шагами и путей восстановления, чтобы оправдать дополнительный слой.
Вернитесь к выбору после того, как у вас появятся реальные traces, реальные сбои и несколько болезненных инцидентов, из которых можно учиться. Если дебаг всё ещё ощущается мутным или изменения продолжают ломать старые пути, поднимайтесь на следующий уровень абстракции. Если plain code по-прежнему легко отслеживать и менять, оставьте его.
Если нужна вторая точка зрения, Oleg Sotnikov на oleg.is делает такой разбор как Fractional CTO и startup advisor. Короткая внешняя проверка помогает, когда вам нужен ясный ответ по дизайну workflow, настройке дебага или рискам обновления без превращения всего проекта в упражнение по framework.
Часто задаваемые вопросы
С чего лучше начать: с plain code или LangGraph?
Начинайте с plain code, если только ваш workflow уже не содержит много ветвлений, ретраев, approvals или долго живущего состояния. Несколько небольших функций проще читать, тестировать и исправлять. Переходите к LangGraph, когда поток постоянно скачет между шагами и скрипт уже не получается держать понятным в одном месте.
Когда plain code перестаёт быть хорошим вариантом?
Обычно это чувствуется не в первый день, а в поддержке. Если одно изменение в продукте затрагивает много файлов, логика ретраев расползается повсюду или никто не может объяснить весь путь, не открыв полпроекта, значит plain code вырос больше, чем удобно.
Какой агентный workflow лучше всего подходит для LangGraph?
LangGraph лучше всего подходит для workflows с ветвящимися путями, повторной передачей задач между инструментами, человеческой проверкой и возобновляемыми запусками. Если вашему агенту нужно маршрутизировать между billing, fraud, approval и fallback-ветками, граф помогает держать это проще для обсуждения и проверки.
LangGraph сложнее дебажить?
Часто да. В plain code вы можете перейти к строке, посмотреть локальные переменные и пройтись по stack trace. В LangGraph нужно ещё смотреть на state узлов, правила маршрутизации и сохранённую историю запусков, поэтому поиск бага может занять больше времени, если команда плохо знает runtime.
Как понять, что replay действительно поможет?
Сначала возьмите один упавший запуск и попробуйте воспроизвести его с тем же prompt, state, model settings и результатами tool calls. Если это не получается, replay даст только грубую копию проблемы. Хороший replay требует стабильных входных данных и понятного состояния до и после каждого шага.
Где боль от обновлений появляется раньше всего?
Фреймворк-обновления обычно бьют сильнее, потому что могут менять обработку state, retries, callbacks или checkpointing так, что всё выглядит нормально, пока не ломаются edge cases. Plain code чаще оставляет изменения локальными, поэтому радиус проблем виден раньше.
Стоит ли помещать бизнес-правила в prompts?
Держите prompts сосредоточенными на языке, а правила — в коде. Лимиты approvals, логика escalation, проверки refund и side effects должны жить в обычном коде, где их можно тестировать. Когда команды прячут эти правила в текст prompt и glue-код маршрутизации, исправления быстро становятся запутанными.
Что нужно хранить в agent state?
Сохраняйте только то, что действительно нужно следующим шагам. Держите структуру маленькой, называйте поля понятно и не складывайте все промежуточные значения в один общий объект. Большие объекты state со временем расползаются, и одно переименованное поле может сломать retries, checkpoints или review-steps.
Как небольшой команде не переусложнить agent workflows?
Используйте один реальный workflow как тест и дайте ему поработать достаточно долго, чтобы он начал ломаться по-честному. Если текущий скрипт всё ещё легко отследить и изменить, не добавляйте ещё один слой. Небольшие команды экономят время, когда ждут повторяющейся боли, а не планируют на все будущие ветки сразу.
Когда стоит попросить внешнюю проверку?
Приглашайте внешнюю помощь, когда команда продолжает спорить о инструментах, инциденты слишком долго разбираются или обновления кажутся рискованными, но никто не может объяснить почему. Короткий внешний разбор от опытного CTO может дать ясный ответ по форме workflow, настройке дебага и рискам обновления ещё до того, как вы зафиксируете лишнюю сложность.


