Более короткие AI-workflow: сокращайте потери перед покупкой большей мощности модели
Более короткие AI-workflow помогают сократить токенные расходы, убирая повторяющиеся промпты, лишние шаги и ненужные вызовы инструментов до покупки большей мощности модели.
Содержание
Почему расходы растут, даже если модель остаётся той же
Команда может месяцами работать на одной и той же модели, а расходы всё равно будут расти. Проблема часто не в модели. Workflow просто стал длиннее.
Кто-то добавляет один лишний промпт, чтобы улучшить результат. Потом ещё один вызов инструмента, чтобы привести формат в порядок. Потом шаг повтора, потому что первый промпт оказался слишком расплывчатым. Каждое изменение по отдельности кажется мелочью. Вместе они превращают дешёвую задачу в дорогую.
Расходы на токены часто скрывают обычные потери в процессе. Если один ответ службы поддержки проходит четыре шага вместо одного, счёт вырастет ещё до того, как кто-то обновит модель. То же самое происходит, когда команды снова и снова отправляют один и тот же контекст, дважды просят об одном и том же резюме или вызывают вторую модель только для того, чтобы исправить слабый первый промпт.
Более крупная модель какое-то время может скрывать этот беспорядок. Она может давать лучшие ответы даже при неаккуратном процессе, и команде кажется, что проблема решена. Это не так. Просто за лишние шаги, которых вообще не должно быть, теперь платят больше.
Короткий workflow против раздутого
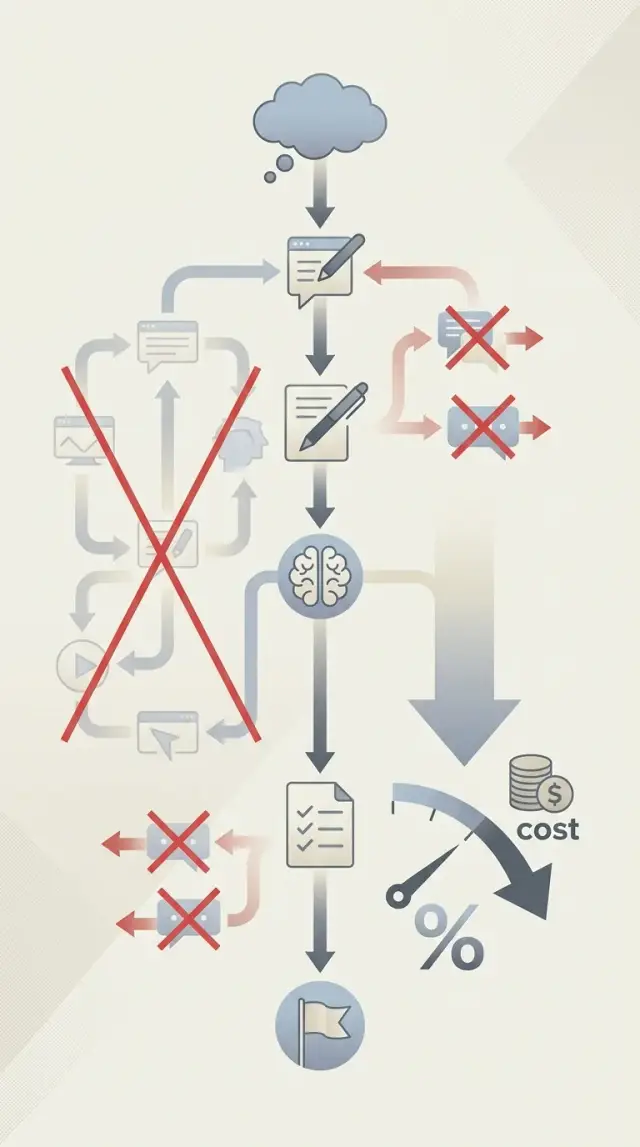
Короткий workflow прямой и понятный. Он один раз получает ясный ввод, выдаёт полезный ответ и идёт дальше.
Раздутый workflow обычно сначала делает черновик промпта из сырых заметок, потом переписывает его в другом инструменте, затем снова отправляет полный контекст, просит краткое резюме ответа, а потом вызывает третий инструмент, чтобы преобразовать формат. Это пять шансов сжечь токены, добавить задержку и внести ошибку.
Разница быстро становится заметной в реальной работе. Основатель может попросить AI превратить расшифровку встречи в продуктовые задачи. В чистой схеме инструмент выделяет действия, группирует их и выдаёт короткий список задач. В запутанной схеме один промпт резюмирует transcript, другой переписывает резюме, третий превращает его в задачи, а четвёртый правит формулировки. Итог может выглядеть почти одинаково, но второй путь стоит в несколько раз дороже.
Вот почему более короткие AI-workflow важны ещё до любого обновления модели. Большинству команд сначала не нужна большая мощность модели. Им нужно меньше передач между шагами, меньше повторяющегося контекста и промпты, которые сразу просят финальный результат.
Простые исправления обычно лучше дорогих. Уберите дублирующиеся промпты. Сократите вызовы инструментов, которые только исправляют прошлые шаги. Сделайте ввод точнее. Если после этого задача всё ещё не работает, тогда уже имеет смысл тестировать более крупную модель.
Где AI-workflow обычно становятся слишком длинными
Большинство раздутых workflow не начинаются такими. Команда добавляет один лишний промпт, чтобы подчистить результат, ещё один вызов инструмента, чтобы чувствовать себя спокойнее, и один ручной этап проверки на крайние случаи. Через месяц процесс стоит вдвое дороже, и никто не может назвать точный момент, когда это произошло.
Первый источник потерь — шаг «на всякий случай». Команды добавляют небольшие действия, которые по отдельности кажутся безвредными, но делают одну и ту же работу дважды. Одна модель чистит текст, другая переписывает тот же текст, а третья форматирует его для следующего инструмента. Во многих случаях один промпт может сделать всё это сам.
Одни и те же лишние действия повторяются снова и снова: очистка текста перед извлечением, хотя извлекатель справится и с сырым вводом; краткое резюме одного и того же документа для каждой последующей задачи; повторное переписывание ответа в тот же тон; проверка структуры моделью после того, как инструмент уже сам удерживает формат; или просьба сделать черновик, а затем ещё и «черновик получше» почти без нового контекста.
Повторяющиеся промпты — ещё одна тихая утечка бюджета. Команды вставляют один и тот же фон в промпты для классификации, резюмирования, черновиков и проверки, потому что каждый шаг сделал разный человек. История клиента, правила продукта и инструкции по стилю снова и снова отправляются в модель. Расход токенов быстро растёт, даже если сама модель не очень большая.
Вызовы инструментов растут по тому же принципу. Один шаг вызывает поиск, следующий — CRM, потом ещё один снова получает ту же запись клиента, потому что предыдущий результат не был передан дальше. Длинные цепочки создают и вторичные потери. Каждый результат инструмента ещё и оборачивается в текст, объясняется и отправляется обратно модели. Вы платите не только за вызов. Вы платите за весь текст вокруг него.
Передача между людьми может сделать это ещё хуже. Сотрудник поддержки просит модель сделать краткое резюме кейса. Потом менеджер копирует тикет в новый промпт и просит рекомендованное действие. Потом сотрудник операций снова вставляет тот же материал, чтобы подготовить ответ клиенту. Три человека, три промпта, один набор фактов.
Эти потери редко выглядят драматично. Они прячутся в повторяющемся контексте, дублирующихся проверках и шагах, которые остались в процессе намного дольше, чем была нужна их первоначальная причина.
Как описать уже существующий workflow
Выберите одну задачу, которая часто повторяется и приносит реальную потерю времени, если что-то идёт не так. Не описывайте сначала всю систему. Одна задача даёт понятную картину и помогает не обмануть себя.
Хорошие примеры простые и конкретные: превратить transcript звонка продаж в заметки для CRM, подготовить ответ службы поддержки или отсортировать счета в нужную очередь. Если у задачи есть чёткое начало и конец, её можно измерить.
Опишите workflow простыми словами, шаг за шагом, как будто объясняете его новому сотруднику. Уберите технические ярлыки там, где обычного предложения достаточно. «Модель читает transcript» лучше, чем ячейка на схеме с туманным названием.
Учтите каждую передачу. Это значит шаги модели, человеческие проверки, действия в приложении, копирование и вставку, а также любое ожидание между ними. Многие команды записывают только «умные» части и пропускают скучные места, где и прячутся потери.
Для простой карты достаточно пяти колонок: название шага, кто его выполняет, что входит, что выходит и что чаще всего идёт не так.
Когда весь путь становится виден, отметьте места, где модель ждёт, повторяет попытку или повторяет саму себя. Их легко пропустить, потому что каждый лишний шаг по отдельности выглядит безобидно.
Следите за тем, не отправляется ли один и тот же контекст больше одного раза. Команда может отправить transcript, чтобы создать заметки, отправить тот же transcript ещё раз, чтобы написать письмо, а потом отправить его в третий раз, чтобы сделать список задач. Когда система растёт по частям, это кажется нормальным, но это всё равно повторная работа.
Посчитайте элементы, которые создают расходы и задержку: промпты на задачу, вызовы инструментов на промпт, циклы повторов, циклы проверок и места, где люди по-новому формулируют одну и ту же инструкцию.
Если точных данных нет, используйте грубые оценки. Даже быстрая прикидка помогает. Если одна задача использует шесть промптов, два поиска в интернете и три человеческие проверки, вы уже понимаете, где искать потери, прежде чем покупать больше мощности модели.
Небольшой пример делает это понятнее. Допустим, служба поддержки получает письмо, просит модель сделать черновик ответа, просит ещё раз, потому что тон не тот, отправляет кейс в поиск по базе знаний, а потом просит финальную версию после того, как сотрудник добавил заметки. Это не одно AI-действие. Это цепочка с повторяющимся контекстом, повторяющейся оценкой и лишним ожиданием.
Когда ваша карта помещается на одной странице и в ней отмечены все промпты, вызовы инструментов и циклы проверок, потери перестают прятаться в процессе.
Как шаг за шагом сократить workflow
Начинайте не с модели, а с пути, который проходит работа. Большая часть потерь возникает из-за лишних движений: один и тот же контекст вставлен дважды, вызов инструмента никто не читает, или второй промпт просто переписывает то, что уже сказал первый.
Более короткий процесс обычно даёт два выигрыша сразу. Вы тратите меньше токенов, а результат становится стабильнее, потому что у процесса меньше мест, где он может «съехать».
Сначала ищите шаги, которые только переписывают текст. Если один промпт делает черновик, а следующий говорит «сделай понятнее» или «сделай это более профессионально», объедините их. Сразу попросите нужный тон и структуру в первом промпте.
Затем объедините промпты, которые повторяют один и тот же фон. Команды часто отправляют одни и те же заметки клиента, данные о продукте или текст политики в два или три отдельных шага. Если второму шагу нужен тот же контекст, объедините задачи и отправьте этот контекст один раз.
После этого уберите вызовы инструментов, которые не меняют ответ. Многие workflow тянут лишние записи, ищут в логах или вытягивают метаданные только потому, что этот шаг добавили несколько месяцев назад. Посмотрите на итоговый результат и задайте простой вопрос: повлияло ли это на ответ? Если нет — убирайте вызов.
Задайте один формат результата и не меняйте его. Переделки часто начинаются, когда один шаг возвращает абзац, следующий ожидает таблицу, а потом человеку приходится всё чистить. Выберите формат заранее, например короткое резюме плюс три поля, и сделайте его обязательным для каждого запуска.
И наконец, протестируйте более короткую версию на небольшой партии. Используйте 10–20 реальных примеров, а не один идеальный. Сравните стоимость, скорость и частоту ошибок. Если более короткий процесс даёт тот же уровень качества, оставляйте его.
Одно небольшое изменение может убрать много потерь. У службы поддержки может быть workflow, который классифицирует тикет, резюмирует его, получает данные по аккаунту, переписывает резюме и потом готовит ответ. Если данные по аккаунту вообще не влияют на черновик, а шаг переписывания меняет только тон, такой пятишаговый процесс можно сократить до трёх шагов.
В этом и смысл более коротких AI-workflow. Вы не просите модель делать меньше полезной работы. Вы убираете повторение одной и той же работы дважды.
Простой пример из реальной бизнес-задачи
Клиент пишет: «Мой заказ должен был прийти вчера. Где он?» На вид всё просто, но многие команды превращают это в длинную AI-цепочку. Такая цепочка часто стоит дороже самого ответа.
Представьте медленный вариант. Система поддержки отправляет сообщение одной модели, чтобы определить тип проблемы. Потом вызывает систему заказов, отправляет результат во второй промпт для резюме, просит первый черновик, просит более тёплую версию и делает ещё один проход, чтобы проверить формулировки политики.
Это пять вызовов модели, два отдельных запроса к заказу и одна финальная человеческая проверка после двух или трёх черновиков.
Ничего из этого по отдельности не выглядит странным. Потери возникают из-за повторения. Один и тот же номер заказа, дата доставки и извинительная формулировка копируются из промпта в промпт. Потом сотрудник читает несколько версий одного и того же ответа, чтобы утвердить только одну.
Более короткая версия делает один запрос к данным и один вызов модели. Система один раз получает статус заказа: задерживается в пути, новая дата доставки — пятница, возврат пока не нужен. Потом отправляет эти данные вместе с сообщением клиента в один промпт с инструкцией: объяснить задержку простыми словами, извиниться один раз, назвать новую дату и предложить дальнейшие шаги, если до пятницы ничего не изменится.
Черновик может быть коротким:
«Извините за задержку. Я проверил ваш заказ — он всё ещё в пути. Последнее обновление от перевозчика показывает доставку к пятнице. Если к этому времени посылка не придёт, ответьте на это сообщение, и мы поможем с заменой или возвратом средств.»
Обычно такого ответа достаточно для быстрой проверки сотрудником. Он подтверждает дату и отправляет сообщение. Без второго переписывания. Без дополнительной правки тона. Без повторной проверки политики, если нужная формулировка уже есть в промпте.
Что меняется на практике
Большинство команд здесь экономят не секунды, а целые россыпи мелких задержек в течение дня.
Длинный workflow может использовать примерно 1800–2400 токенов, занимать 45–90 секунд системного времени и требовать ещё 30–60 секунд работы проверяющего. Короткий workflow может использовать 250–500 токенов, занимать 10–20 секунд системного времени и требовать 10–15 секунд проверки.
Более короткий путь ещё и упрощает поиск ошибок. Когда один черновик получается из одного запроса к данным, сотрудник видит, что произошло. Когда три промпта переписывают друг друга, плохая формулировка теряется в цепочке.
Прежде чем покупать больше мощности, проверьте, не раздут ли сам процесс. Обычный ответ службы поддержки часто требует одного хорошего промпта, одного надёжного запроса к данным и человека, который за десять секунд убедится, что сообщение совпадает с фактами.
Ошибки, которые удерживают потери в системе
Первая ошибка легко заметна, если начать её искать: расходы растут, и команда покупает более крупную модель, не очищая процесс. Это кажется логичным, но обычно скрывает более глубокую проблему. Если workflow повторяет инструкции, снова и снова использует один и тот же контекст или отправляет сырой результат в другую модель для чистки, более крупная модель просто сжигает ещё больше денег на тех же потерях.
Команды также добавляют инструменты для проблем, которые начинаются в самом промпте. Если ответы получаются слишком длинными, добавляют summarizer. Если формат выглядит грязно, добавляют parser. Если тон кажется неправильным, добавляют ещё один проход модели. Служба поддержки может сначала подготовить ответ клиенту, потом сократить его вторым промптом, а затем прогнать через formatter перед отправкой. Один более точный промпт мог бы справиться со всем этим сам.
Проверки на безопасность тоже могут превратиться в лишний шум. Один человек добавляет проверку политики внутри приложения. Другой добавляет то же правило в системный промпт. Третий добавляет инструмент постпроверки результата. Каждый шаг по отдельности выглядит разумно, но три перекрывающиеся проверки стоят дороже, замедляют результат и иногда конфликтуют друг с другом.
Проверки людьми создают ту же проблему. Когда каждый член команды может добавлять этапы согласования, workflow становится длиннее без чьего-либо замечания. Маркетинг хочет проверку тона. Юристы хотят ревью обычных ответов. Операции хотят финальный просмотр «на всякий случай». В итоге простая задача требует четырёх вызовов модели и двух людей для одобрения.
Ещё одна ловушка — локальная оптимизация. Команды тратят дни на настройку одного промпта, а вся цепочка остаётся слишком длинной. Сэкономить несколько токенов на втором шаге не так важно, если задача всё равно запускает шесть промптов, два вызова инструментов и дублирующиеся проверки. Обычно больше всего экономит удаление целого шага.
Признаки становятся очевидными, когда знаешь, на что смотреть. Одно и то же правило безопасности встречается в нескольких местах. Люди продолжают добавлять этапы проверки, но никто не убирает старые. Вызов инструмента остаётся в процессе просто потому, что когда-то помог, а не потому, что задаче он нужен всегда. Один промпт постоянно правят, а вся остальная цепочка остаётся раздутой.
Oleg применяет тот же принцип, когда сокращает расходы на софт и инфраструктуру: сначала уберите дублирующуюся работу, а уже потом платите за большую мощность. AI-системы ничем не отличаются. Если для простого ответа задаче нужны пять промптов, три проверки и два инструмента, сначала нужно привести в порядок сам процесс.
Быстрые проверки перед масштабированием
Более высокая мощность модели часто маскирует неаккуратный процесс. Прежде чем платить за большее окно контекста, больше агентов или больше вызовов инструментов, проверьте, не делает ли сам workflow лишнюю работу.
Сначала спросите, не делают ли два шага одну и ту же работу. Это часто случается, когда один промпт резюмирует текст, а следующий переписывает это же резюме чуть другими словами. Если второй шаг не добавляет реального решения, объедините его с первым или удалите.
Потом проверьте, не видит ли модель один и тот же контекст дважды. Команды часто передают полный бриф в первый шаг, а затем этот же бриф плюс первый результат — во второй. Это быстро удваивает расход токенов. Оставляйте только тот контекст, который нужен каждому шагу.
Посмотрите на каждый вызов инструмента и спросите, меняет ли он финальный ответ. Запрос к базе данных, поиск или форматирующий инструмент должны заслужить своё место. Если ответ выглядит одинаково с этим вызовом и без него, уберите его.
То же самое сделайте с человеческой проверкой. Проверка полезна, когда кто-то что-то утверждает, отклоняет или исправляет. Она бесполезна, когда человек просто читает ответ, сомневается и жмёт продолжить.
Отслеживайте расход токенов не только по модели, но и по задаче. Панели модели могут создавать впечатление нормальных затрат, даже когда одна задача сжигает в три раза больше токенов, чем остальные. Измеряйте весь путь для одного запроса клиента, одного кейса поддержки или одного отчёта.
Простой тест помогает быстро увидеть потери. Возьмите одну реальную задачу и запишите каждый шаг простыми словами: какой промпт отправлен, какой контекст прикреплён, какие инструменты вызваны, какие проверки сделал человек и какой получился итог. Потом прогоните задачу один раз со всеми шагами и один раз, убрав один шаг. Если качество не меняется, этот шаг, скорее всего, был балластом.
Допустим, команда продаж использует AI, чтобы превращать transcript звонка в заметки для CRM. Workflow расшифровывает звонок, резюмирует его, переписывает резюме в буллеты, отправляет буллеты в другую модель для очистки тона, а затем просит менеджера проверять каждую запись. Во многих случаях один промпт может сразу делать чистые CRM-заметки из transcript, а менеджеру нужно проверять только редкие исключения. Это сокращает время, токены и задержки.
Если хотите более короткие AI-workflow, начинайте с дублирования. Повторяющиеся промпты, повторяющийся контекст и повторяющиеся проверки — это обычно и есть тихие потери.
Что делать дальше
Начните с одного workflow, а не со всего стека. Выберите тот процесс, который стоит дороже всего, запускается чаще всего или раздражает людей каждый день. Черновик ответа поддержки, чистка заметок продаж или цепочка резюме документа обычно уже достаточно, чтобы быстро найти реальные потери.
На этой неделе опишите этот workflow на одной странице. Запишите каждый промпт, каждый вызов инструмента, каждый повтор и каждую передачу между системами или людьми. Большинство команд сразу замечают одну и ту же проблему: модель спрашивают дважды почти об одном и том же, либо инструмент запускается даже тогда, когда его результат никто не использует.
Первый проход может быть простым. Перечислите шаги по порядку — от ввода до финального результата. Отметьте любой повторяющийся промпт, который снова просит о том же резюме, переписывании или проверке. Отметьте любой вызов инструмента, который запускается по умолчанию, но редко меняет ответ. Потом уберите один дублирующийся промпт и один слабый вызов инструмента и сравните новую версию со старой.
Не меняйте сразу пять вещей. Сделайте одно сокращение, запустите workflow и сравните результат. После каждого изменения отслеживайте три метрики: стоимость, скорость и качество результата. Если стоимость падает, а качество ухудшается, откатите изменение и попробуйте менее резкую правку.
Небольшой пример помогает увидеть это лучше. Допустим, у команды есть workflow для клиентских писем, который делает черновик ответа, потом просит второй промпт изменить тон, а затем каждый раз вызывает поисковый инструмент для правил компании. Если первый промпт уже чаще всего даёт правильный тон, шаг переписывания только увеличивает расходы. Если только 10% сообщений требуют проверки политики, поиск должен запускаться только в этих случаях. Вот так более короткие AI-workflow экономят деньги без покупки большей мощности модели.
Когда найдёте лучшую версию, задокументируйте её простыми словами. Храните промпт, правила принятия решений и разрешённые вызовы инструментов в одном месте. Если команда не запишет более короткий workflow, лишние шаги вернутся уже через месяц.
Некоторым командам нужен свежий взгляд со стороны. Если ваш workflow рос постепенно и никто не отвечает за весь процесс целиком, внешний разбор может помочь. Oleg Sotnikov делает такую Fractional CTO-работу через oleg.is, с практическим фокусом на AI-инженерию, маршрутизацию инструментов и контроль затрат до того, как команда потратит больше на мощность.
Назначьте срок первого разбора. К концу недели у вас должна быть одна карта «до и после», один измеренный тест и одно решение: сохранить изменение, доработать его или убрать.
Часто задаваемые вопросы
Как понять, что более высокие расходы на AI связаны с потерями в workflow?
Посмотрите на одну задачу от начала до конца, а не только на счёт за модель. Если задача теперь использует больше промптов, больше повторных попыток, больше вызовов инструментов или больше скопированного контекста, чем раньше, значит, workflow разросся, и расходы выросли вместе с ним.
Что стоит убрать первым в длинном AI-workflow?
Начните с шагов, которые только переписывают уже готовый текст. Если один промпт делает черновик, а следующий лишь меняет тон, формулировки или формат, объедините их в один более сильный промпт.
Стоит ли переходить на более крупную модель, если результаты кажутся непоследовательными?
Нет. Сначала очистите процесс. Более крупная модель может замаскировать слабые промпты и лишние шаги, но вы всё равно платите за эту лишнюю работу каждый раз, когда задача запускается.
Как заметить повторяющийся контекст в промптах?
Возьмите одну реальную задачу и выпишите все входные данные, которые получает каждый шаг. Когда один и тот же transcript, заметки, правила политики или история клиента появляются в нескольких промптах, вы нашли повторяющийся контекст.
Когда вызов инструмента действительно стоит оставить?
Оставляйте вызов инструмента только тогда, когда он меняет итоговый ответ или реально снижает риск. Если результат остаётся тем же без этого поиска, запроса в базу или форматтера, уберите его.
Как проще всего описать AI-workflow?
Самый простой способ — взять одну частую задачу с понятным началом и концом. Опишите каждый шаг простыми словами, включая промпты, вызовы инструментов, проверки человеком, повторы и ожидание, чтобы потери не спрятались между системами.
Что нужно измерить после упрощения workflow?
Сравните расходы, скорость и качество результата на небольшой партии реальной работы. Если более короткая версия сохраняет качество и снижает стоимость или задержку, оставляйте изменения.
Может ли один промпт заменить несколько шагов переписывания?
Часто да. Попросите сразу выдать финальный результат с нужным тоном, структурой и правилами, вместо того чтобы сначала делать черновик, а потом его полировать. Это обычно экономит токены и уменьшает расхождения.
Сколько человеческой проверки стоит оставить в процессе?
Оставляйте человеческую проверку там, где кто-то сверяет факты, подтверждает риск или исправляет редкие случаи. Убирайте проверки, где человек только просматривает ответ и жмёт дальше — это добавляет задержку почти без пользы.
Когда имеет смысл привлечь внешнего эксперта для проверки workflow?
Привлекайте внешнюю помощь, когда workflow рос по частям и никто не контролирует всю цепочку целиком. Свежий взгляд помогает найти дублирующиеся промпты, слабую маршрутизацию инструментов и лишние этапы согласования ещё до того, как вы потратите больше на мощность модели.


