Конкурентность запросов Node.js при CPU-емких AI-задачах
Конкурентность запросов в Node.js усложняется, когда AI-работа нагружает CPU. Узнайте, когда лучше подойдут worker threads, очередь или отдельный сервис.
Содержание
Что меняется, когда AI-работа попадает в путь запроса
Обычный API на Node.js спокойно справляется с большим количеством ожидания. Он может зависнуть на чтении из базы данных, HTTP-вызове или загрузке файла и всё равно продолжать обрабатывать другие запросы. Но всё меняется, когда вы помещаете CPU-ёмкую AI-работу прямо в сам запрос — например, генерацию эмбеддингов, очистку OCR, подсчёт токенов или локальный инференс.
Теперь запрос не просто ждёт I/O. Он тратит настоящее время на CPU. В Node.js это бьёт сильнее, чем ожидают многие команды, потому что главному циклу событий достаётся только один ход за раз. Если один запрос тратит 300–500 мс на обработку текста или изображения, остальные запросы тоже ждут дольше.
Вот что часто упускают из виду, когда говорят о конкурентности запросов Node.js. Один медленный запрос может ухудшить работу многих других, даже если эти запросы вообще не касаются AI. Пользователь загружает документ, сервер начинает его обрабатывать, и внезапно логин, поиск и дашборд во всём приложении становятся медленнее.
Первый тревожный сигнал обычно не ошибки, а задержка. Время ответа растёт. P95 и P99 быстро ухудшаются. Приложение всё ещё выглядит как будто "живым", проверки здоровья проходят, а в логах может быть тихо. Пользователи замечают тормоза раньше, чем мониторинг показывает явную аварию.
Добавление новых веб-реплик само по себе не решает корневую проблему. Если каждая реплика выполняет ту же CPU-ёмкую работу внутри пути запроса, вы просто распределяете нагрузку по большему числу процессов и тратите больше денег, но каждый процесс всё равно может начать подвисать под нагрузкой. Проблема остаётся той же — просто у вас становится больше её копий.
Чаще всего это всплывает сразу после запуска AI-функции. На лёгком тестировании всё выглядит нормально. Потом в продакшене приходит несколько одновременных запросов, и сервис начинает казаться вязким.
Почему Node.js замедляется на CPU-работе
Node.js очень хорош в ожидании. Он может обслуживать много открытых запросов, потому что большая часть веб-работы — это I/O: чтение из базы, обращение к другому API или ожидание диска. Пока идёт ожидание, Node может переключиться и сохранить отзывчивость процесса.
CPU-ёмкая AI-работа — это другое. Токенизация, разбор документов, разбиение на чанки, подготовка эмбеддингов, преобразование изображений и локальный инференс реально нагружают саму машину. Даже если каждый шаг кажется маленьким, всё вместе может быстро съедать одно ядро.
Проблема в цикле событий. Он остаётся здоровым, когда задачи завершаются быстро и возвращают управление. Если один запрос запускает 150-миллисекундный CPU-рывок в главном потоке, остальным запросам это время уже не вернуть. Они ждут. Несколько перекрывающихся задач могут превратить бодрый API в медленные запросы Node.js.
Именно поэтому конкурентность запросов Node.js часто отлично выглядит на тестах, а потом разваливается после запуска AI-функции. Вызов базы данных, который занимает 200 мс, обычно не блокирует процесс всё это время. А вот шаг парсинга или генерации эмбеддингов на 200 мс — блокирует.
Большие батчи ухудшают ситуацию ещё сильнее. Допустим, пользователь загружает большой PDF, а приложение за один проход вытаскивает текст со сотен страниц. Процесс создаёт больше строк, массивов и буферов, память растёт, а у V8 появляется больше мусора для очистки.
После этого задержки становятся неровными. Один запрос заканчивается быстро, следующий занимает секунды, и маленькие эндпоинты начинают вести себя непредсказуемо. Паузы на сборку мусора только добавляют хаоса, особенно когда сервер работает близко к лимиту памяти.
Если веб-процесс одновременно обслуживает запросы и выполняет тяжёлую AI-подготовку, простое увеличение количества работы обычно не повышает пропускную способность. Оно лишь делает задержки легче воспроизводимыми.
Как найти настоящий узкий участок
Большинство команд сначала ошибается. Они видят, что конкурентность запросов Node.js проседает, и обвиняют базу данных, API модели или сам Node.js. Начинать нужно с одного теста, где вы одновременно измеряете задержку, загрузку CPU, использование памяти и lag цикла событий.
Если растёт только задержка, вы пока знаете мало. Если задержка растёт вместе с CPU и lag цикла событий, локальные вычисления, скорее всего, блокируют процесс. Если задержка растёт, а CPU остаётся низким, значит, вы, вероятно, ждёте сеть, диск или другой сервис.
Возьмите один нагруженный эндпоинт и проверьте его под трафиком, похожим на реальный. Один запрос в локальной разработке почти ничего не показывает. Двадцать или пятьдесят одновременных запросов часто быстро выявляют проблему, особенно если каждый запрос ещё и запускает токенизацию, разбор изображений, эмбеддинги или другой CPU-ёмкий шаг.
Зафиксируйте четыре показателя в одном и том же окне теста:
- p95 или p99 задержки запроса
- использование CPU на один процесс
- рост памяти и всплески сборки мусора
- lag цикла событий
Эти цифры рассказывают куда более понятную историю, чем среднее время ответа. Высокий CPU при небольшом росте памяти указывает на чистые вычисления. Рост памяти вместе с долгими паузами сборки мусора указывает на давление от аллокаций. Низкий CPU при долгом времени ответа обычно значит, что вы ждёте что-то снаружи процесса.
Отдельно измеряйте время работы внутри эндпоинта. Разделите ожидание сети и локальные вычисления. Например, если вызов API эмбеддингов занимает 900 мс, а ваше приложение ещё 700 мс тратит на разбиение текста на чанки, главная проблема не во внешнем API.
Не меньшее значение имеют ожидания пользователя. Если результат должен быть виден до продолжения страницы, нужен быстрый синхронный путь. Если результат может прийти через 10 секунд, очередь может оказаться лучшим вариантом даже тогда, когда нагрузка на CPU кажется терпимой.
Простой тест из практики Oleg Sotnikov и lean production systems хорошо это показывает: загрузить документ, разобрать его, разбить на части и создать эмбеддинги под реалистичным трафиком. Посмотрите, что ломается первым. Обычно именно первое слабое место и есть настоящий узкий участок.
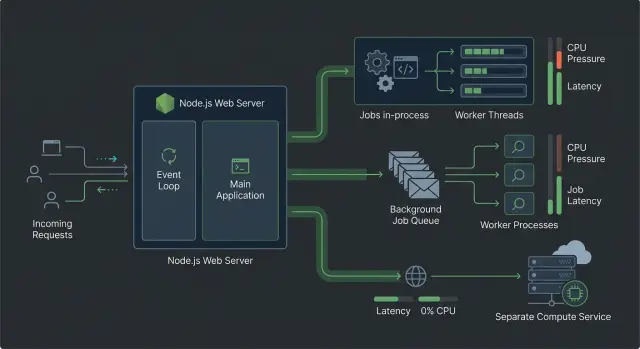
Когда лучше всего подходят worker threads
Worker threads хорошо подходят, когда запрос всё ещё должен дать быстрый ответ, но одна часть работы сильно нагружает CPU. Оставьте веб-приложение точкой входа, а горячий цикл перенесите из главного потока. Так процесс сможет продолжать обслуживать другие запросы вместо того, чтобы зависать на разбиении текста, подготовке изображений, reranking или локальном вызове модели.
Этот подход подходит для задач, которые короткие, предсказуемые и тесно связаны с запросом. Если пользователь загружает файл и вам нужно разбить текст на чанки перед сохранением, worker threads обычно достаточно. Пользователь получает один ответ, код остаётся в одном сервисе, и вам не нужны лишние сущности вроде очереди или отдельного CPU-сервиса.
Worker threads помогают с конкурентностью запросов Node.js только если настроить их аккуратно. Частая ошибка — запускать слишком много worker'ов и заставлять машину бороться сама с собой. Подберите число worker'ов под реальные CPU-ядра, а потом оставьте место для главного процесса и клиента базы данных.
Несколько правил помогают сделать такую схему устойчивой:
- Передавайте worker'ам маленькие полезные нагрузки. Большие объекты долго копируются и могут съесть весь выигрыш.
- Держите задачи worker'ов узкими. Лучше всего работает чистая CPU-работа.
- Ставьте лимиты по времени. Если задача зависла, остановите её и верните понятную ошибку.
- Если трафик стабильный, переиспользуйте worker'ы через пул.
Если задача требует много памяти, работает много секунд или иногда резко разрастается под нагрузкой, worker threads начинают казаться тесными. Тогда веб-процесс всё ещё несёт слишком много риска. Но для медленных запросов Node.js, вызванных умеренными CPU-рывками, worker threads часто оказываются самым простым решением с минимальным числом новых частей.
Когда очередь имеет больше смысла
Очередь лучше работает, когда пользователю не нужен результат AI в том же самом ответе. Веб-приложение может сохранить запрос, создать задачу и ответить сразу. После этого тяжёлую работу выполнит воркер, и один медленный job не будет держать весь путь запроса.
Этот подход подходит для задач, которые пользователи и так ожидают не мгновенно:
- краткие summaries для длинных документов
- запланированные отчёты
- пакетная разметка
- фоновые эмбеддинги
- обработка аудио или изображений
Пользовательский опыт часто становится лучше, а не хуже. Ждать 30–60 секунд в одном запросе ощущается как поломка, даже если в итоге всё успешно завершилось. Быстрый ответ с понятным статусом вроде "в очереди" или "обрабатывается" воспринимается куда надёжнее.
Храните состояние задачи там, где приложение сможет потом его прочитать. Сохраняйте ID задачи, текущий статус, время старта, время завершения и детали ошибки, если что-то пошло не так. Если у задачи есть этапы, записывайте простые обновления прогресса вроде "загружено", "разбито на чанки" и "готово", чтобы пользователь понимал, на каком она шаге.
Очереди также делают сбои менее болезненными. Если воркер упал на середине отчёта или запуска эмбеддингов, задачу можно повторить, не заставляя пользователя отправлять всё заново. Это важнее, чем кажется, особенно когда загрузки большие или подготовка промпта дорогая.
Масштабировать систему тоже проще. Можно держать небольшое веб-приложение для быстрых ответов и добавлять воркеры только тогда, когда AI-задач становится больше. Такое разделение защищает конкурентность запросов Node.js намного лучше, чем попытка запихнуть всю CPU-работу в веб-процесс.
Небольшая команда может начать с одной очереди и одного воркера. Если спрос вырастет, добавляют ещё воркеры — а не дополнительное время ожидания для каждого пользователя.
Когда стоит вынести CPU-работу в отдельный сервис
Отдельный CPU-сервис начинает иметь смысл, когда вместе растут и запросы, и объём AI-задач. Если каждый новый upload, chat или search-запрос ещё и запускает эмбеддинги, OCR, reranking или разбор документов, веб-приложение начинает выполнять две совершенно разные роли. После этого конкурентность запросов Node.js становится не вопросом настройки, а вопросом границы между системами.
Ранние признаки обычно такие:
- Время ответа растёт, когда AI-задач становится больше
- Память резко скачет при больших документах или пакетных запусках
- AI-код требует деплоя чаще, чем веб-роуты или изменения страниц
- Вы хотите больше вычислительных воркеров без увеличения числа веб-серверов
Ещё одна причина разделять — падения и всплески памяти. Плохой парсер или прожорливая библиотека модели может быстро съесть RAM. Если этот код живёт внутри пользовательского приложения, люди почувствуют это сразу через медленные страницы, таймауты и рестарты. Отдельный сервис позволяет ограничить ущерб.
Скорость деплоя тоже важна. Веб-код и AI-код почти никогда не меняются в одном ритме. Продуктовая команда может несколько раз в неделю менять формы, авторизацию или API-ответы, а AI-часть — правила чанкинга, настройки модели или нативные зависимости — по другому графику. Раздельные сервисы позволяют выкатывать одно, не трогая другое.
Масштабирование тоже становится понятнее. Веб-уровень должен расти вместе с HTTP-трафиком. Вычислительный уровень — вместе с количеством ядер, глубиной очереди и временем выполнения задач. Это может означать два веб-экземпляра и восемь CPU-воркеров, даже если трафик на страницы остаётся прежним. Если всё это живёт в одном наборе Node.js-процессов, вы тратите деньги впустую и хуже понимаете реальную ёмкость системы.
Сделайте первое разделение минимальным. Достаточно одного сфокусированного сервиса. Для многих команд это один сервис для эмбеддингов или парсинга файлов с понятным API и базовыми health checks. Большая внутренняя платформа не нужна. Нужна одна чистая граница, которая защищает приложение, которым действительно пользуются.
Простой способ выбрать подход
Выбирайте подход по времени, а не по вкусу. Сначала задайте один вопрос: должен ли пользователь получить результат до того, как страница сможет продолжить работу?
Если да, держите работу рядом с запросом только тогда, когда каждая задача короткая и достаточно предсказуемая. Хорошая отправная точка — worker threads в Node.js для задач вроде обработки одного файла, изменения размера одного изображения или генерации небольшой партии эмбеддингов. Веб-процесс остаётся свободным для новых запросов, пока другой поток занимается CPU-работой.
Затем прикиньте пиковую нагрузку. Если одна задача занимает 200 мс CPU-времени и 30 пользователей могут запустить её одновременно, то почти одновременно приходит около 6 CPU-секунд работы. Именно тогда начинают появляться медленные запросы Node.js, даже если средний трафик выглядит нормальным. Смотрите на пиковые цифры, а не на дневные средние.
Если пользователю не нужно ждать, очередь AI-задач обычно безопаснее. Запрос может быстро вернуть ответ, сохранить задачу и позже обновить статус. Это хорошо подходит для индексирования документов, длинных summaries, крупных прогонов эмбеддингов и другой работы, которая может занять несколько секунд или больше. Очередь также даёт повторы и больше контроля при скачках трафика.
Отдельный CPU-сервис имеет больше смысла, когда важнее изоляция, чем простота. Выбирайте этот путь, если CPU-работе нужно собственное масштабирование, если она зависит от тяжёлых нативных библиотек, если у неё другой цикл деплоя или если она может утянуть вниз веб-приложение при всплеске нагрузки. Это также более аккуратно, когда одна команда отвечает за продуктовый API, а другая — за AI-пайплайн.
Рабочее правило простое:
- Пользователь должен ждать, а задача короткая: используйте worker threads.
- Пользователь может подождать: используйте очередь.
- Работа требует независимого масштабирования или более сильной изоляции: выносите её в отдельный сервис.
Большинству команд стоит начинать с малого. Для конкурентности запросов Node.js worker threads часто становятся первым шагом, очередь — следующим, а отдельный сервис стоит дополнительной сложности только тогда, когда нагрузка, риск или распределение ответственности в команде делают этот компромисс очевидным.
Реалистичный пример: загрузка документа и эмбеддинги
Пользователь загружает PDF на 40 страниц и ждёт быструю подтверждающую реакцию, а не крутящийся таб в браузере 30 секунд. Лучший ответ обычно простой: "Загрузка принята. Обработка началась."
Медленная часть часто начинается ещё до любого вызова модели. Извлечение текста из PDF, очистка и разбиение на чанки могут сильно нагружать CPU, особенно если файл сканированный, с кривой версткой или просто большой. Если ваш веб-процесс делает всё это внутри запроса, медленные запросы Node.js быстро начинают затрагивать и других пользователей.
Более аккуратный поток выглядит так:
- Веб-приложение сохраняет файл и создаёт запись задачи.
- Запрос на загрузку сразу возвращает успех.
- Фоновый воркер извлекает текст, делит его на чанки и создаёт эмбеддинги.
- Интерфейс показывает экран статуса, пока документ не будет готов к поиску.
Такая схема защищает конкурентность запросов Node.js, потому что веб-приложение остаётся сосредоточенным на короткой I/O-работе: загрузках, проверке авторизации и поисковых запросах. Поисковые запросы остаются быстрыми, потому что не стоят в очереди за чужой PDF, который обрабатывается локальным CPU.
Сначала воркер может работать в той же системе, но вне пути веб-запроса. Если библиотеки для извлечения текста потребляют много памяти или иногда падают на битых файлах, перенос этой работы в отдельный процесс обычно безопаснее. Вы изолируете сбой и сохраняете отзывчивость основного приложения.
Экран статуса работает лучше, чем один длинный зависший запрос. Люди нормально воспринимают "обрабатывается", когда видят прогресс или хотя бы понятное состояние вроде в очереди, извлекается текст, создаются эмбеддинги или готово. Они не воспринимают нормально страницу, которая выглядит зависшей и потом уходит в таймаут.
Обычно одно это изменение в потоке даёт больше пользы для воспринимаемой скорости, чем попытка сэкономить несколько секунд на самой задаче эмбеддингов.
Ошибки, которые вредят конкурентности
Самый быстрый способ испортить конкурентность запросов Node.js — впихнуть CPU-работу в тот же обработчик, который обслуживает пользователя. Приходит запрос, ваш роут в Express или Next.js начинает делить текст на чанки, менять размер изображений, создавать эмбеддинги или разбирать большой файл, и цикл событий перестаёт быть лёгким. Одна медленная функция может притормозить вообще не связанные запросы, даже если на тестах сервер выглядел нормально.
Worker threads помогают, но люди часто относятся к ним как к мусоропроводу: всё тяжёлое туда, без лимитов, без очереди, без тайм-аута. Обычно это создаёт другую проблему. Потоки накапливаются, память растёт, а задержки становятся странными, потому что приложение по-прежнему принимает больше работы, чем способно завершить. Если задачи приходят быстрее, чем выполняются, вам нужна обратная защита от перегрузки, а не дополнительный оптимизм.
Ещё одна частая ошибка — передавать между потоками огромные объекты. Если вы гоняете туда-сюда большие документы, буферы изображений или гигантские JSON-объекты, сериализация и копирование съедают время, которое, как вам казалось, вы экономите. Держите сообщения маленькими. Передавайте ID, пути к файлам или компактные чанки, а уже воркер пусть сам загружает то, что ему нужно.
Масштабирование web-подов тоже не лечит плохой горячий путь. Если одна CPU-ёмкая функция блокирует каждый pod, добавление новых pod'ов в основном даёт вам больше заблокированных pod'ов. Вы платите больше, логи шумят сильнее, а пользователи всё равно ждут. На это особенно часто попадаются команды, которые масштабируют веб-уровень до того, как измерят, куда на самом деле уходит время.
Отмена задачи слишком часто игнорируется. Пользователь закрывает вкладку, повторяет загрузку или уходит на другую страницу, а сервер всё равно продолжает жевать ту же дорогую задачу. Это расходует CPU и отодвигает остальные запросы. Если результат больше не нужен, остановите работу или пометьте её устаревшей до того, как она дойдёт до дорогого шага.
Полезно держаться одного правила: оставляйте веб-процесс лёгким, ограничивайте количество тяжёлой работы, которая может идти одновременно, и не переносите большие полезные нагрузки туда-сюда без необходимости.
Быстрые проверки перед релизом
Большинство проблем с конкурентностью всплывает на самых неприятных входных данных, а не на средних. Текстовый файл на 500 КБ может выглядеть нормально на тестах, а PDF на 40 МБ с длинным OCR-выводом — заблокировать процесс и замедлить все остальные запросы.
Запускайте нагрузочное тестирование, похожее на реальный трафик. Используйте размеры файлов, длины промптов, размер батчей и настройки таймаутов, которые ждёте в продакшене. Если приложение принимает документы, проверьте маленькие файлы, обычные файлы и один-два больших файла, которые подходят близко к вашему лимиту.
Короткий чеклист перед релизом полезнее, чем ещё один круг догадок:
- Задайте жёсткий максимальный размер задачи. Отклоняйте слишком большие работы до того, как они попадут в CPU-ёмкий путь.
- Измеряйте lag цикла событий, глубину очереди, задержку запроса и процент таймаутов. Если lag растёт во время AI-работы, веб-процесс всё ещё делает слишком много.
- Специально протестируйте повторы. Отправьте одну и ту же задачу дважды и проверьте, что вы не создаёте дубликаты и не списываете оплату дважды.
- Сломайте один шаг посередине. Посмотрите, что произойдёт, если загрузка удалась, а генерация эмбеддингов упала, или если воркер умер после частичного прогресса.
- Запишите, кто отвечает за каждый worker, очередь, дашборд и оповещение. Когда ночью всё забьётся, размытая ответственность только отнимает время.
Для конкурентности запросов Node.js такие проверки часто полезнее, чем микробенчмарки. Быстрый демо-результат может скрыть плохую продовую конфигурацию.
Один принцип стоит соблюдать особенно строго: если задача может расти без понятного потолка, потолок нужно поставить сейчас. Ограничения по размеру, времени и правилам повторов кажутся скучными, но именно они не дают одному плохому запросу превратиться в россыпь медленных запросов Node.js.
Если вы проверяете только счастливый путь, вы всё ещё просто гадаете.
Что делать дальше
Начните с простой карты всех AI-задач, которые выполняет ваше приложение. Для каждой задачи выберите то место, которое соответствует её поведению, а не то, что сегодня кажется проще. Так вы защитите конкурентность запросов Node.js, когда CPU-работы станет больше.
- Оставляйте её в пути запроса, если она завершается быстро, а пользователю нужен ответ сразу.
- Используйте worker thread, если задача CPU-ёмкая, но небольшая, локальная и тесно привязана к одному веб-серверу.
- Используйте очередь, если пользователь может подождать, трафик приходит рывками или вам нужны повторы.
- Выносите в отдельный сервис, если CPU-работа доминирует, требует своих правил масштабирования или тянет веб-процесс вниз.
Затем выберите один эндпоинт, а не пять. Измерьте его текущие p95, загрузку CPU, использование памяти и процент таймаутов. Измените одну вещь, выкатите её и измерьте снова. Если узкое место — это загрузка документа плюс эмбеддинги, начните с неё, а не с рефакторинга всего приложения.
Сделайте первую версию скучной. Простая очередь с одним воркером и понятными правилами повтора проще в эксплуатации, чем хитрая схема с кучей движущихся частей. Вам нужно решение, которое команда сможет отлаживать в 2 часа ночи без догадок.
Понаблюдайте за цифрами несколько дней после изменения. Если p95 падает, а память растёт, значит, работы ещё много. Если CPU остаётся примерно на том же уровне, а задержка запроса улучшается, значит, вы, скорее всего, правильно вынесли узкое место из веб-процесса.
Некоторые команды застревают потому, что проблема уже не только в коде. Она касается деплоя, ответственности, стоимости и того, как люди выкатывают изменения. Если вы именно в такой точке, Oleg Sotnikov может как Fractional CTO помочь оценить компромиссы и спланировать более безопасный запуск.


