Когда использовать CQRS: разделяйте чтение и запись только при необходимости
Когда стоит использовать CQRS зависит от реальных болей: разные формы запросов, строгие правила записи или требования к масштабированию. Узнайте, где это приносит пользу.
Содержание
Проблема, которую решает CQRS
Обычно одна модель данных — это разумный выбор в начале: один набор таблиц, один формат API, одна мысленная модель. Для небольшого приложения это работает хорошо.
Проблемы начинаются, когда одна и та же модель должна справляться с двумя очень разными задачами. Изменение биллинга требует строгих правил, проверок прав и четких изменений состояния. Страница с историей аккаунта или панель доходов требует объединённых данных, итогов, меток и быстрой фильтрации.
Эти задачи тянут в разные стороны. Записи требуют контроля: отклонения неверных действий, запись изменений и поддержание согласованности системы. Чтения требуют скорости и нужной формы: пользователи хотят, чтобы страницы загружались быстро и возвращали именно те поля, которые нужны, даже если данные берутся из нескольких мест.
Когда одна модель пытается делать и то, и другое, код становится неуклюжим. Логика запросов просачивается в бизнес-логику. Бизнес-правила начинают подстраиваться под требования отчётности. Разработчики добавляют лишние JOIN’ы, кэшированные поля и разовые исключения, потому что один экран требует данных в форме, которой поток записи не предусматривал.
В приложении с подписками это видно особенно ясно. Смена тарифа может требовать проверок статуса оплаты, лимитов мест, правил пробного периода и того, кто может подтвердить изменение. Страница обзора аккаунта — совсем другая задача: в одном ответе могут понадобиться текущий план, статус счетов, дата последней оплаты, активные места и тренды использования. Можно заставить одну модель тянуть и то, и другое, но это обычно делает код сложнее для понимания и менее надёжным.
Именно поэтому существует CQRS. Речь не о разделении чтения и записи ради красивой диаграммы, а о признании того, что отдельная модель чтения и модель записи помогают, когда форма запросов и правила записи уже не помещаются удобно в одной конструкции.
Если в вашей команде постоянно спорят, должна ли модель обслуживать экраны или изменения состояния — модель уже сама отвечает за вас. Проблема не в абстрактной сложности, а в том, что одна структура пытается выполнять две работы с разными правилами.
Что именно разделяется, а что — нет
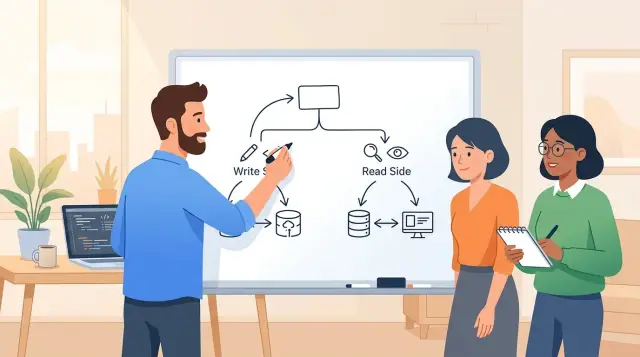
Идея CQRS проста. Команды изменяют состояние. Запросы возвращают данные.
Команда обрабатывает действие, например "создать аккаунт", "сменить план" или "отменить подписку". Она проверяет правила, обновляет данные и фиксирует, что произошло. Если пользователь не имеет права или изменение плана нарушает правило биллинга, команда отклоняет действие. Эта логика принадлежит стороне записи.
Запрос делает другое. Он вытаскивает данные для экрана, API-ответа или отчёта. Он может соединять таблицы, перестраивать поля и возвращать ровно то, что нужно странице. Сторона чтения заботится о быстрых ответах и понятном выводе. Ей не нужно заново дублировать правила записи.
Это не значит, что нужно сразу всё разделять. Многие команды начинают с разделения кода, а не хранения. Они оставляют одну базу данных и один набор таблиц, но перестают использовать одни и те же сервисы для чтения и записи. Уже этого часто достаточно, чтобы убрать беспорядок в приложении.
Возьмите команду смены подписки. Она может затрагивать планы, счета, лимиты и журналы аудита. Запрос обзора аккаунта может возвращать денормализованный вид с текущим планом, датой следующего платежа, использованием и статусом оплаты. Та же база данных — разные пути, потому что задачи разные.
CQRS также не требует event sourcing. Вы можете хранить обычные строки в обычных таблицах и при этом использовать модель команд для записи и модель запросов для чтения. Event sourcing — отдельный выбор. Некоторые команды комбинируют их, многие — нет.
Большинство приложений не должны применять CQRS повсюду. Небольшая страница настроек часто отлично работает с обычным CRUD. Поток биллинга, процесс утверждения или админская панель могут нуждаться в разделении, потому что правила записи строги, а форма чтения неудобна.
Практическая настройка обычно преднамеренно скучна: отдельные обработчики для команд и запросов, сначала одна общая база данных и разделение лишь там, где оно действительно нужно. Если нагрузка вырастет, можно добавить отдельные хранилища для чтения, асинхронные обновления или более специализированные модели там, где это оправдано.
Признаки, что разделение того стоит
CQRS начинает иметь смысл, когда запросы и записи хотят очень разных форм данных. Частый случай — продукт с простыми действиями записи и тяжёлыми экранами для чтения: панели, отчёты, результаты поиска, сводки аккаунтов и итоги использования. Если эти экраны требуют JOIN’ов, подсчётов, фильтров и предварительно вычисленных значений, которые стороне записи никогда не нужны, одна общая модель обычно превращается в гору обходных путей.
Вы обычно видите эту проблему в коде прежде, чем кто‑то её назовёт. Растёт код маппинга. Умножаются специальные объекты запросов. Обработчики набирают странные исключения только для удовлетворения одного экрана. Доменные модели начинают нести заботы о чтении, которые им не нужны. Через время даже маленькие изменения становятся неловкими, потому что каждый новый запрос тянет модель записи в новую форму.
Строгое поведение записи — ещё один сильный сигнал. Команды вроде "отменить подписку", "применить кредит" или "сменить план" часто требуют чётких правил и надёжного журнала аудита. Эти правила должны жить в одном месте. Тут CQRS помогает: сторона записи может сосредоточиться на валидации, изменениях состояния и бизнес‑правилах, а сторона чтения — на быстрых ответах на вопросы.
Характер трафика тоже важен. Если система получает намного больше чтений, чем записей, разделение может быть практичным. Портал клиентов может показывать статус аккаунта и историю платежей тысячи раз в день, в то время как смены плана происходят лишь несколько раз в час. В таком случае модель чтения, оптимизированная под скорость, снимает нагрузку с части системы, которая защищает целостность данных.
Эти сигналы обычно приходят вместе. Экраны чтения требуют сводок, которые не место в модели записи. Действия записи требуют строгих проверок, и вы не хотите, чтобы эти правила разбросали по коду запросов. Трафик чтения растёт, а записи остаются скромными. Новые запросы отчётности делают когда‑то чистую модель сложнее для понимания.
Есть и сигнал продуктовой скорости. Когда каждый новый запрос делает стабильную часть приложения сложнее изменить, общая модель делает слишком много. Обычно именно тогда стоит рассмотреть CQRS. Не потому, что паттерн звучит продвинуто, а потому, что модель перестала быть простой.
Когда CRUD — лучший выбор
Простой CRUD часто правильный ответ, когда одна модель данных обслуживает и редактирование, и отображение без неудобных ухищрений. Если одна запись годится и для формы, и для списка, и для пары отчётов, разделение принесёт мало пользы.
Это распространено в ранних продуктах и небольших внутренних инструментах. Таблицы клиентов, подписок или заказов обычно покрывают создание, обновление, детальные представления и админские списки без драмы.
То же самое про запросы. Если экраны нуждаются в нескольких фильтрах, одной‑двух сортировках, пагинации и паре JOIN’ов — оставьте всё простым. Обычная база данных с нормальными индексами справится.
Разделение между моделью чтения и моделью записи начинает иметь смысл лишь тогда, когда чтения и записи действительно хотят разных форм. Если этого не происходит, CQRS добавляет церемоний, не решая реальной проблемы.
Сохраняйте простоту отладки
Маленькие команды платят реальную цену за лишние части. Когда один разработчик может проследить баг от запроса до базы за десять минут, эта скорость важнее красивых архитектурных диаграмм.
CQRS добавляет обработчики, проекции, синхронизацию, ретраи и больше тестов. Всё это не бесплатно. Вы пишете больше кода, ввод в команду занимает больше времени, и вы тратите силы на гонку за устаревшими данными и пограничными случаями.
CRUD обычно достаточно, когда модель поддерживает формы и списки чисто, запросы предсказуемы, одна база справляется с текущим трафиком, и eventual consistency только запутает пользователей. Маленькая SaaS‑бэк‑офис часть — хороший пример: поддержка редактирует планы, ищет подписчиков, сортирует по дате продления и проверяет статус платежа — одна схема часто справляется.
Дополнительные части должны оправдывать себя. Если очереди, проекции и дублирующие модели не экономят время и не решают боли — это просто лишняя поддержка.
Если не уверены, начните с CRUD, если только текущая форма явно не противоречит вам. Разделяйте чтение и запись позже и только там, где действительно расходятся формы запросов и правила записи.
Пошаговый способ принять решение
Большинство команд не должны разделять чтение и запись по всему приложению. Начните с тех частей, которые люди используют каждый день, и проверьте, тянут ли стороны чтения и записи в разные стороны.
Простой обзор работает хорошо.
- Перечислите самые часто открываемые экраны, затем перечислите действия, которые изменяют данные. Панель, страница поиска, форма биллинга и админский экран часто ставят разные требования к одним и тем же таблицам.
- Запишите точные данные, которые нужны каждому экрану. Включите итоги, бейджи, фильтры, подсчёты, порядок сортировки и связанные записи. "Страница клиента" слишком расплывчато. "Страница клиента с текущим планом, последним счётом, флагом неудачной оплаты и использованием за текущий месяц" — полезно.
- Пометьте правила, которые каждая запись должна защищать. Возможно, у аккаунта может быть только один активный план. Возможно, возврат всегда должен создавать запись в аудите. Возможно, пользователь не может отменить план, который уже истёк.
- Ищите места, где одна модель создаёт неудобный код. Повторяющиеся JOIN’ы, растущий код маппинга, медленные запросы и обработчики, полные исключений под конкретный экран, обычно означают, что модель делает две работы.
- Сначала разделите один болезненный поток. Оставьте всё остальное в покое, пока боль не станет явной.
Это держит обсуждение привязанным к продукту. Вы не решаете, нужно ли всему приложению CQRS. Вы спрашиваете, нужна ли отдельная форма чтения для той части, где она реально облегчает работу по сравнению с моделью записи.
Дашборд поддержки — частый пример. Экран может требовать статус аккаунта, последние счёта, открытые тикеты и флаги риска в одном быстром запросе. Сторона записи работает по‑другому: она должна защищать правила биллинга, сохранять чистый журнал аудита и корректно менять состояние. Когда эти потребности расходятся, отдельная модель чтения может сделать код меньше, а не больше.
Именно тогда часто стоит разделять: один срез больно тянет, и причина боли — разные формы запросов и правила записи. Если разделение делает поток проще для чтения, тестирования и изменения — оставляйте. Если добавляет слои без снятия боли — откатывайте и оставляйте CRUD.
Пример: страница поддержки подписки
Агент поддержки открывает страницу аккаунта в приложении подписки. Ему нужны ответы быстро, не экскурсия по базе данных. Один экран должен показать, кто клиент, что он заплатил, сколько использовал и есть ли открытые инциденты.
Эта страница обычно тянет данные из нескольких мест: профиль из таблицы клиентов, последние счета из биллинга, итоги использования из метринга и открытые тикеты из системы поддержки.
Это в основном проблема чтения. Агент не меняет все эти данные — ему нужен один быстрый и понятный экран.
Модель чтения здесь хороша тем, что подстраивает данные под страницу. Вместо того чтобы каждый раз делать несколько JOIN’ов, приложение может держать вид, который уже совпадает с макетом страницы. Результат — проще код экрана и быстрее ответы для команды поддержки.
Теперь посмотрите на действия на той же странице. Агент может сменить план или оформить возврат. Эти действия очень отличаются от чтения. Возврат требует правил: нужно проверить, оплачен ли счёт, не был ли уже сделан возврат, разрешена ли сумма и есть ли у агента право на это. Также нужно сохранить ясный аудиторский след с причиной и временем.
Этот путь записи должен оставаться строгим. Он не должен зависеть от представления страницы, созданного для удобства. Команда вроде IssueRefund нуждается в собственных проверках и собственном потоке, даже если страница аккаунта показывает контекст.
Это хороший пример того, как CQRS решает реальное несоответствие. Сторона чтения помогает странице поддержки быстро ответить на многие вопросы в одном месте. Сторона записи защищает операции с деньгами и держит правила в строгости. То же самое можно сделать и через CRUD, но тогда страница аккаунта станет грязной, или логика возврата окажется слишком свободной.
Ошибки, делающие CQRS болезненным
CQRS становится грязным, когда команды разделяют всё слишком рано и повсеместно. Берут нормальное приложение, превращают каждый эндпоинт в отдельный путь чтения и записи и получают вдвое больше кода до того, как решён хоть один настоящий кейс.
Обычно это начинается с благих намерений: команда хочет чистые модели, быстрые экраны или пространство для роста. Затем они дробят простые CRUD‑потоки, которые уже работали. Результат — лишние обработчики, тесты, шаги деплоя и больше мест, где могут прятаться баги.
Обычная ошибка — добавление очередей, шины и фоновых воркеров до того, как это действительно нужно. Если одну транзакцию базы достаточно — используйте её. Шина сообщений имеет смысл, когда чтения и записи могут расходиться, когда нагрузки сильно отличаются или когда одно действие запускает несколько downstream‑обновлений. Без такого давления — это просто лишние части.
Ещё одна ловушка — копирование бизнес‑правил на сторону чтения. Решает сторона записи, что разрешено: кто может отменять, когда можно менять план, применяется ли возврат. Сторона чтения должна формировать данные для экранов и отчётов. Как только обе стороны начинают применять правила, они расходятся. Тогда пользователь видит одно на дашборде и получает другое при попытке сохранить.
Модели чтения порождают свой собственный режим отказа, когда никто не знает, как их пересоздать. Проекция, которая работает только если она никогда не пропускает событие, хрупка. Командам нужен ясный способ проиграть данные, заполнить поле задним числом и восстановиться после бага. Если восстановление занимает дни или зависит от tribal knowledge, дизайн ломкий.
Худшая ошибка — культурная. Некоторые команды воспринимают CQRS как доказательство архитектурной зрелости. Они копируют диаграмму с конференции в малый проект, разделяют сначала, спрашивают зачем потом и хранят сложность дольше, чем нужно.
Небольшое приложение подписки — хороший пример. Если правила биллинга строги, а панель клиента требует быстрых сводок, разделение может помочь. Но это не значит, что инструменты поддержки, админские страницы и внутренние формы тоже нуждаются в CQRS. Хорошие команды держат разделение узким: решают одну сложную часть и оставляют остальное как есть.
Вопросы, которые стоит задать перед тем, как решиться
Если вы всё ещё не уверены, задайте несколько прямых вопросов перед тем, как добавлять вторую модель, путь синхронизации и лишние части. Разделение может упростить, но может и удвоить объём того, что нужно объяснить и поддерживать.
Начните с экранов, которые люди реально используют. Если две‑три важные страницы требуют одних и тех же данных в кардинально разных формах, отдельная модель чтения может помочь. Если большинство страниц показывает те же поля с парой JOIN’ов и фильтров — CRUD, как правило, достаточно.
Потом посмотрите на сторону записи. CQRS окупается, когда правила записи продолжают просачиваться в контроллеры, сервисы и код запросов. Если создание или изменение записи требует утверждений, проверок, побочных эффектов и аккуратных изменений состояния — модель записи может помочь держать это в одном месте.
Производительность тоже важна, но будьте честны в причине. Медленные страницы не всегда означают, что нужен CQRS. Многие команды разделяют чтение и запись, когда реальной проблемой был индекс, простой запрос или кеширование. Используйте CQRS, когда проблема в форме запроса, а не когда база просто требует обычной оптимизации.
Короткий чеклист:
- Требуют ли ваши самые загруженные экраны данных, которые совсем не похожи на таблицы, в которые вы записываете?
- Распылены ли правила записи по различным обработчикам и вспомогательным методам?
- Остаются ли медленные запросы медленными после оптимизации индексов и очевидных узких мест?
- Может ли ваша команда чётко объяснить обе модели без путаницы через месяц?
- Если разделение не получится, сможете ли вы вернуть всё назад без переписывания половины приложения?
Последний вопрос важнее, чем большинство команд признаются. Держите изменение локальным сначала. Разделите один рабочий поток, не весь продукт. Если новая модель чтения делает одну страницу быстрее и поток записи проще для рассуждений — расширяйте. Если в основном добавляет баги синхронизации и путаницу — откатывайте раньше.
Лучшее решение по CQRS обычно узкое. Используйте там, где формы запросов и правила записи действительно расходятся, и оставляйте остальное в покое.
Что делать дальше
Не разделяйте всё приложение сразу. Выберите одно место, где чтение и запись уже конфликтуют, и меняйте только его. Одна модель чтения для медленной панели или один поток команд со строгими правилами записи — достаточно для обучения.
Держите эксперимент маленьким и прозаичным. Если изменение работает, вы почувствуете это в повседневной работе, а не в архитектурных диаграммах. Команды обычно замечают меньше обходных путей, чище код и меньше времени на латание запросов, которые не вписываются в модель записи.
Простой подход работает лучше. Выберите экран или рабочий поток, который постоянно вызывает трения. Сначала разделите либо чтение, либо запись, не оба сразу. Измерьте время запросов, churn кода и количество багов до и после. Потом запишите, что стало проще, а что усложнилось.
Эти записи важны. CQRS может выглядеть умно на бумаге и всё же стоить слишком дорого в реальном коде. Ведите краткий журнал для каждого изменения: какую проблему вы пытались решить, какой дополнительный код добавили, кто за это отвечает и оправдано ли разделение через пару недель.
Это самый практичный ответ на вопрос. Используйте CQRS там, где разделение снимает реальное трение. Остановитесь там, где оно начинает создавать церемонии, дублировать логику или добавлять лишние части для функции, которая этого не заслуживает.
Если архитектурные споры тормозят продуктовую работу, внешний обзор может помочь. Oleg Sotnikov на oleg.is работает со стартапами и небольшими компаниями как Fractional CTO, помогая командам разобрать архитектуру продукта, инфраструктуру и практическое внедрение AI, без превращения каждого архитектурного решения в крупный рефакторинг.
Следующий хороший шаг обычно скромен: одно аккуратное изменение, один набор метрик и честный обзор, оправдало ли оно себя.


