Паттерны кэширования LLM, которые сокращают расходы без потери качества
Паттерны кэширования LLM помогают сократить повторные расходы на токены, когда вы переиспользуете подсказки, повторно используете безопасные ответы и добавляете семантический кэш с простыми проверками.
Содержание
Почему расходы растут при обычном трафике LLM
Большинство счетов за LLM растут по простой причине: команды продолжают платить за ту же работу снова и снова.
Пользователь задаёт знакомый вопрос, приложение отправляет полную подсказку снова, и модель обрабатывает её так, будто никогда ничего не видела. Это быстро становится дорогим, когда каждый запрос включает длинную системную подсказку, текст политики, примеры и правила форматирования. Если общие настройки занимают 1500 токенов, вы платите за эти 1500 токенов и за простые вопросы, и за сложные.
Повторы обычно больше, чем команды ожидают. Боты поддержки, внутренние ассистенты и инструменты поиска часто получают одинаковые запросы с незначительными изменениями формулировки. «Как сбросить пароль?» и «Не могу войти, как мне поменять пароль?» часто ведут к одному и тому же ответу, но многие приложения всё равно делают новый вызов модели для обоих.
Проблема растёт тихо. Кто‑то добавляет пару инструкций. Другой человек добавляет юридический текст. Потом примеры. Потом правила вывода. Каждое изменение кажется незначительным, но подсказка продолжает разрастаться, пока настройки не будут стоить больше, чем сам вопрос пользователя.
Многие команды также недооценивают, насколько интенсивный у них повторяющийся трафик. Они смотрят общий объём запросов и общие расходы, но редко разбивают подсказки на точные повторы, близкие повторы и единичные вопросы. Это упущение важно: вы экономите реальные деньги с помощью кэша только если понимаете, какие типы повторов встречаются в продакшене.
Простой пример всё проясняет. Если 2000 пользователей за неделю спрашивают про сроки возврата немного разными словами, модель может сгенерировать почти одинаковый ответ 2000 раз. Без повторного использования вы платите снова за одни и те же инструкции, тот же контекст и часто тот же вывод.
Расходы растут потому, что использование токенов накапливается в фоне. Небольшие повторы, длинные инструкции и незамеченные паттерны трафика складываются, пока счёт не привлечёт внимания.
Где кэширование помогает, а где — нет
Кэширование работает лучше всего, когда модель выполняет одну и ту же работу снова и снова. Если ваше приложение посылает длинную фиксированную подсказку, повторяющийся текст политики или типичные вопросы клиентов, вы часто можете переиспользовать часть работы и сократить расходы без ухудшения результата.
Лучшие кандидаты — предсказуемые задачи: длинные системные инструкции, которые почти не меняются, ответы FAQ, сводки одного и того же документа и задания классификации с небольшим набором стабильных входов. Похожие вопросы тоже выигрывают от семантического кэша, но только если вы тщательно это протестируете.
Кэширование слабеет, когда ответы зависят от свежих фактов. Остатки на складе, живые цены, балансы счетов, недавние тикеты и всё, что привязано к меняющейся базе данных, обычно должны пропускать общие повторные ответы. То же самое касается единичных текстов, сложных исследовательских вопросов и подсказок, где у каждого пользователя много нового контекста.
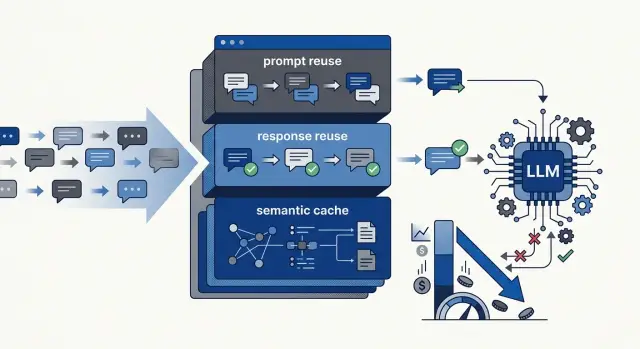
Повторное использование подсказок — самое безопасное начало для большинства команд. Если ваше приложение отправляет одни и те же 1500 токенов инструкций каждый раз, переиспользуйте этот блок и перестаньте платить за него при каждом вызове. Ответ всё ещё может быть свежим, а повторяющийся сетап больше не съедает токены.
Повторное использование ответов уже более узкое. Оно работает, когда один и тот же ввод должен давать одинаковый или очень похожий вывод. Подумайте о стандартных ответах по политике, повторных модерационных проверках или коротких черновиках с фиксированными правилами. Оно ломается, когда время, тон, история пользователя или живые данные должны изменить ответ.
Конфиденциальность важнее небольшой экономии. Держите персональные данные, данные аккаунта, загруженные файлы и внутренние заметки вне общего кэша. Если нужно кэшировать материал специфичный для пользователя, ограничьте его этим пользователем или арендатором и сделайте время жизни коротким.
Простой тест помогает: если завтра два разных человека зададут это же, должны ли они получить один и тот же ответ? Если да — кэш, скорее всего, помогает. Если нет — снова вызывайте модель.
Повторное использование подсказок сокращает стоимость сетапа в первую очередь
Повторное использование подсказок обычно самое дешевое место для старта. Многие команды платят за один и тот же текст настроек при каждом запросе: роль, тон, правила безопасности, формат вывода, инструкции по инструментам и факты о продукте. Если этот текст редко меняется, держите его в переиспользуемом блоке и отправляйте в одном и том же порядке каждый раз.
Самый чистый подход — разделить подсказку на две части. Поместите стабильные правила в один фиксированный блок. Положите сообщение пользователя, данные аккаунта, недавний контекст и всё, что зависит от времени, в меняющийся блок. Такое разделение делает подсказки короче и упрощает отладку ошибок.
На практике фиксированный блок обычно содержит роль, стиль, правила безопасности, формат вывода и бизнес‑политику. Меняющийся блок держит вопрос, данные клиента, недавние сообщения и конкретные ограничения для запроса.
Если провайдер модели поддерживает кэш подсказок, важно соблюдать консистентность. Держите переиспользуемый блок вверху. Сохраняйте одинаковые пробелы. Не вклинивайте метки времени, идентификаторы запросов или заметки сессии в общую секцию. Небольшие изменения вроде этого часто уничтожают экономию.
Обращайтесь с подсказками как с кодом и версионируйте их. Имена вроде "support_v4" или "summary_v2" достаточно. Когда расходы растут или ответы меняются, теги версий позволят сравнить изменения подсказок вместо того, чтобы гадать.
Измерьте результат перед тем, как объявлять успех. Отслеживайте среднее число входных токенов на запрос, общие расходы для этого потока и качество ответов на небольшой тест‑набор. Бот поддержки, который повторяет 700 токенов сетапа на 20 000 запросов, «съедает» 14 миллионов входных токенов только на сетап. Это обычно самая простая трата для сокращения.
Повторное использование подсказок не уменьшит весь счёт, но окупается быстро, когда много запросов делят длинный стабильный набор инструкций. Поэтому большинству команд стоит начать именно с этого, прежде чем пробовать более агрессивные подходы.
Повторное использование ответов подходит для точных повторов
Если тот же запрос появляется снова и вы ожидаете тот же ответ, не платите модели дважды. Сохраните первый вывод и возвращайте его при следующем точном совпадении. Это часто самый безопасный вид кэширования, потому что правило легко понять.
Это лучше всего работает для стабильных задач: ответы FAQ, текст политики, информация о продукте, которая редко меняется, или задачи форматирования, где один и тот же ввод всегда должен давать один и тот же результат. Если два пользователя задали ровно одинаково, и правила не менялись, переиспользование ответа — правильный выбор.
Совпадение должно оставаться строгим. Постройте ключ кэша из всего, что влияет на ответ, а не только из видимого текста пользователя. Обычно это включает системную подсказку, локаль, настройки модели и любые фиксированные инструкции. Очищать безвредные различия, такие как лишние пробелы, нормально. Размывать смысл — нет.
Сохраняйте версию подсказки с каждым кэшированным ответом. Это избегает распространённой ошибки: если вы измените системную подсказку, ужесточите стиль или добавите новое поле вывода, старые ответы должны перестать совпадать сразу.
Время имеет значение. Некоторые ответы остаются корректными недели, другие устаревают к обеду. Цены, статус на складе, часы работы и обновления политики требуют короткого срока жизни. Для быстро меняющихся тем лучше допустить больше промахов кэша, чем выдавать устаревшую информацию.
Несколько правил сохраняют безопасность повторного использования ответов:
- Переиспользуйте только тогда, когда один и тот же ввод должен возвращать один и тот же ответ.
- Привязывайте версию подсказки к каждому кэшированному результату.
- Для часто меняющихся фактов используйте короткие сроки жизни.
- Не переиспользуйте, если время, история пользователя или свежие данные могут изменить ответ.
Точное совпадение — не модно, и в этом его сила. Оно быстро снижает расходы, делает поведение предсказуемым и реже ломается, чем более продвинутые стратегии кэширования.
Семантический кэш экономит на похожих запросах
Семантический кэш сравнивает запросы по смыслу, а не по тексту. Это важно, когда два пользователя формулируют одно и то же по‑разному. «Как сбросить пароль?» и «Не могу войти, как поменять пароль?» могут заслуживать одинакового ответа, хотя слова различаются.
Такой подход быстро сокращает расходы в поддержке, поиске и потоках с большим количеством FAQ. Он также уменьшает задержки, потому что система возвращает сохранённый ответ вместо нового вызова модели.
Сложность в том, чтобы решить, когда два запроса действительно достаточно похожи.
Хорошая отправная точка — порог похожести, а дальше тестирование на реальном трафике. Если порог слишком свободный, пользователи получают ответы, которые кажутся близкими, но неверны. Если слишком строгий, вы упускаете лёгкие экономии и часто обращаетесь к модели.
Перед тем как полностью доверять семантическим совпадениям в продакшене, протестируйте разные пары: вопросы, которые должны разделять один ответ; похожие на вид, но требующие разных ответов; короткие «грязные» запросы, сленг, опечатки и крайние случаи, связанные с датами, ценами или деталями аккаунта.
Начинайте с низкорисковых задач. Вопросы о политике возврата, часы работы, базовая информация о продукте и типичные шаги установки — обычно хорошие кандидаты. Споры по оплате, медицинские консультации, юридические формулировки и всё, что связано с живыми данными пользователя, — нет.
Например, команда поддержки может кэшировать ответ на «Вы делаете возвраты?» и переиспользовать для «Можно ли вернуть деньги?» если политика стабильна. Ту же команду не стоит кэшировать для «Почему с моей карты списали деньги дважды?» — правильный ответ зависит от записи пользователя.
Когда уверенность совпадения падает, снова вызывайте модель. Такое поведение защищает качество лучше, чем принудительная выдача почти‑совпадений из кэша.
Консервативный подход здесь обычно лучше: меньший семантический кэш с чистыми совпадениями предпочтительнее большого, полного почти‑правильных ответов.
Пошаговые ограждения при развёртывании
Хорошее кэширование начинается с сдержанности. Выберите один узкий рабочий процесс, где форма ответа остаётся стабильной, например ответы поддержки по настройке аккаунта или внутренняя помощь по политике. Если пытаться кэшировать всё сразу, вы потратите больше времени на исправление ошибок, чем сэкономите.
Начните с точечного кэширования ответов — это наименее рискованный вариант, потому что один и тот же ввод возвращает тот же сохранённый ответ. Затем вынесите длинные инструкции в переиспользуемые блоки подсказок. Многие команды получают значительную экономию только от этих двух изменений.
Только после этого тестируйте семантическое совпадение на небольшой доле трафика. Оно может сэкономить ещё больше, но и добавить рисков. Похожие вопросы не всегда должны получать одинаковый ответ. Вопрос по биллингу из одной страны и похожий вопрос из другой могут выглядеть достаточно близко, чтобы совпасть, но требовать разных ответов.
Простой порядок развёртывания работает хорошо:
- Выберите один рабочий процесс с низким риском и большим числом повторов.
- Добавьте точечное повторное использование ответов и просмотрите выборку вручную.
- Вынесите повторяющиеся инструкции в переиспользуемые блоки подсказок.
- Тестируйте семантическое совпадение только после анализа пропусков и почти‑совпадений.
- Логируйте попадания, промахи и плохие переиспользования, чтобы ужесточать правила.
Эти логи важнее, чем многие команды ожидают. Отслеживайте частоту попаданий кэша, сэкономленные суммы и какие переиспользованные ответы потребовали повторной генерации. Если переиспользованные ответы вызывают даже небольшое увеличение исправлений, ужесточите правила перед расширением кэша на другие потоки.
Простой пример для бота поддержки
Магазин обычно получает сотни одинаковых вопросов о возвратах в день. Клиенты спрашивают про сроки возврата, сроки получения возврата денег, комиссии за перестановку и возмещение доставки. Это именно то место, где кэш может окупаться.
Начните с точных совпадений. Если один клиент пишет «Можно ли получить возврат в течение 30 дней?», а следующий присылает тот же текст, бот должен вернуть кэшированный ответ вместо нового вызова модели.
Большая часть трафика поддержки похожа, но не идентична. Кто‑то спросит «Как долго у меня есть, чтобы вернуть товар?» Другой — «Могу ли я отправить обратно через две недели?» Формулировки меняются, но намерение обычно одно. Семантический кэш может поймать такие почти‑дубликаты и переиспользовать подходящий ответ.
Но боты поддержки не должны кэшировать всё. Вопрос «Где мой возврат по заказу 18427?» требует свежих данных. Ответ зависит от пользователя, заказа и текущего статуса платежа. Кэшированная политика подойдёт для общих правил, но специфичные вопросы аккаунта требуют живой проверки и, чаще всего, нового вызова системы.
Практический поток прост: сначала ищите точное совпадение; если нет — ищите близкое семантическое совпадение; и полностью пропускайте кэш, если в вопросе есть данные заказа, статус аккаунта или чувствительный по времени случай. Когда система генерирует новый ответ, сохраняйте его с коротким сроком жизни.
Срок жизни важен. Правила возврата могут измениться после сезона распродаж, обновления цен или пересмотра политики. Если кэш хранится слишком долго, бот начинает уверенно выдавать устаревшие инструкции. Для вопросов политики несколько часов или день обычно безопаснее, чем недели.
Такой подход позволяет кэшу обрабатывать рутинную работу, а новым вызовам модели — случаи, где ошибка стоит дороже лишнего запроса.
Ошибки, которые ухудшают выводы
Самый быстрый способ потерять доверие — кэшировать ответы, зависящие от живых данных. Цены, остатки на складе, балансы, сроки доставки и детали политики могут измениться после первого ответа модели. Если вы повторно используете старый текст, он будет звучать уверенно, но быть неверным.
Бот поддержки может переиспользовать сводку правил возврата. Но он не должен переиспользовать вчерашнюю указанную цену для сегодняшнего покупателя. Когда источник меняется часто, сначала получайте свежие данные и делайте окно кэша коротким.
Другая распространённая ошибка — делиться кэшированным текстом между пользователями без проверки, кто спрашивал. Два человека могут написать почти одинаково, но одному нужен ответ с деталями аккаунта, лимитами плана или внутренними заметками, которые нельзя показывать другому.
Устаревшие ответы наносят тихий вред. Они не всегда выглядят сломанными, поэтому сидят в системе неделями. Назначайте время жизни по теме, а не общей настройке для всего. Описание продукта может быть актуально несколько дней. Ответ по биллингу — может потребовать минут.
Неправильные настройки семантического кэша тоже вредят: если порог похожести слишком низкий, система начинает считать разные вопросы одинаковыми. Это экономит деньги, но затем пользователи получают ответы, которые отличаются одной важной деталью — достаточно, чтобы делать ответ бесполезным.
Несколько ограждений предотвратят большинство проблем:
- Не кэшируйте ответы, связанные с живыми ценами или личными данными, без перепроверки источника.
- Делайте короткие TTL для быстро меняющихся тем.
- Используйте более строгие семантические совпадения, чем вам кажется нужным.
- Разделяйте кэши по пользователю, арендатору, региону или тарифу, когда ответы могут отличаться.
- Очищайте или версионируйте кэш при изменении системной подсказки или логики извлечения.
Последний пункт часто упускают. Обновление подсказки меняет поведение, тон и правила модели. Если старые кэшированные ответы продолжают возвращаться после обновления, вы фактически тестируете две системы одновременно и обвиняете модель в проблеме кэша.
Быстрые проверки перед включением
Кэширование проваливается, когда команды включают его везде одновременно. Проведите короткое ревью и пропустите любую задачу, где устаревший или неверный ответ может причинить реальный вред.
Перед выбором стратегии кэширования задайте себе простые вопросы. Если десять пользователей спрашивают одно и то же, могут ли они все получить одинаковый ответ? Использует ли задача живые, приватные или пользовательские данные? Как долго ответ может оставаться актуальным? Какие события должны инициировать новый вызов модели? И кто будет проверять плохие попадания кэша?
Одно простое правило работает хорошо: чем более персональная или чувствительная по времени задача, тем короче срок жизни кэша. Если ответ касается денег, безопасности или комплаенса, начните только с повторного использования подсказок. Это сокращает токены сетапа, не повторяя текст, который может быть неверен для следующего пользователя.
Семантическое совпадение требует дополнительной осторожности. Две подсказки могут выглядеть близко, но просить разные действия. «Как отменить тариф?» и «Как приостановить тариф?» совпадают по словам, но не по намерению. Если неправильное совпадение может направить пользователя не туда, снизьте порог похожести или пропустите семантику для этого рабочего процесса.
Если у системы нет владельца для ревью плохих попаданий, всё начнёт дрейфовать. Небольшая проверка в начале предотвращает большинство проблем позже.
Что делать дальше
Начните с одного потока, который уже стоит реальных денег. Хорошие кандидаты — ответы поддержки, документ‑Q&A или любая функция, которая посылает тот же набор подсказок снова и снова. Измерьте, сколько запросов повторяются точно, сколько — лишь похоже, и сколько стоит каждый запрос, прежде чем что‑то менять.
Добавляйте только один слой кэша за раз. Большинство команд должны начать с повторного использования подсказок — это самый безопасный способ сократить трату. Если это сработало, добавьте точечное повторное использование ответов для повторяющихся вопросов. Семантическое совпадение оставьте на потом, когда вы поймёте, где похожие запросы помогают, а где создают риск.
Маленькое поэтапное развёртывание лучше, чем хитроумное. Выберите один дорогой путь, логируйте повторяющиеся запросы неделю‑две, добавьте первый кэш только туда и отслеживайте экономию рядом с показателем неправильных ответов. Просматривайте промахи и плохие попадания раз в несколько дней. Расширяйте только если числа остаются стабильными.
Неправильная метрика быстро вас обманет. Кэш, который сокращает расходы на 40%, — плохая сделка, если он подаёт устаревшие ответы, повторяет старые цены или путает контекст пользователя. Держите простую таблицу: процент попаданий, сэкономленные деньги, изменение задержки и доля неправильных ответов. Если одно число улучшается, а доверие падает — остановитесь и ужесточите правила.
Именно здесь многие команды становятся небрежными. Они добавляют семантический кэш слишком рано, ставят свободные пороги и затем обвиняют модель, когда пользователи получают неверные ответы. На практике более скучные правила работают лучше: короткие TTL, строгие совпадения для чувствительных задач и отсутствие повторного использования, когда речь о данных пользователя или фактах, зависящих от времени.
Если хотите второе мнение перед масштабированием, Oleg Sotnikov на oleg.is работает как внештатный CTO и консультант стартапов и помогает командам строить практичные AI‑системы с понятными ограждениями. Такое ревью может сэкономить много проб и ошибок, особенно когда важны и контроль затрат, и качество вывода.
Часто задаваемые вопросы
Что кэшировать в первую очередь?
Выберите один поток с большим количеством повторов и низким риском, например ответы FAQ или внутреннюю справку по политике. Повторное использование подсказок обычно дает самый безопасный первый выигрыш: вы сокращаете повторяющиеся токены сетапа, не переиспользуя целый ответ.
Безопаснее ли повторное использование подсказок, чем кэш ответов?
Обычно да. Повторное использование стабильного блока инструкций сохраняет ответы свежими, убирая при этом повторяющуюся стоимость сетапа. Полное повторное использование ответов тоже работает, но только когда один и тот же ввод действительно должен возвращать одинаковый ответ.
Когда стоит полностью отказаться от кэширования?
Избегайте кэша, когда ответ зависит от живых фактов или приватных данных. Цены, остатки на складе, балансы счетов, статус заказов и всё, что связано с конкретным пользователем, обычно требует свежей проверки и часто — нового вызова модели.
Как разделить подсказку для повторного использования?
Разделяйте подсказку на фиксированный блок и меняющийся блок. В фиксированную часть поместите роль, стиль, политику и правила формата, а в меняющуюся — сообщение пользователя, недавний контекст и данные аккаунта.
Что делает точечное кэширование ответов безопасным?
Постройте ключ кэша из всего, что влияет на ответ, а не только из текста пользователя. Включайте версию подсказки, локаль, настройки модели и фиксированные инструкции, чтобы старый ответ не подошёл после изменения правил.
Как долго должен храниться кэшированный ответ?
Устанавливайте время жизни по теме, а не одно правило для всего. Стабильный ответ по политике может жить часы или день, тогда как ответы по биллингу, ценам или доставке часто требуют минут или вовсе не должны кэшироваться совместно.
Работает ли семантическое кэширование для вопросов поддержки?
Может, но только для узких задач со стабильными ответами. Держите порог похожести строгим, тестируйте пары вопросов из реального трафика и при сомнениях возвращайтесь к вызову модели.
Как понять, что кэширование портит качество ответов?
Следите не только за процентом попаданий. Отслеживайте сэкономленные деньги, задержки, повторные попытки и долю неправильных ответов, а также вручную проверяйте выборку переиспользованных ответов. Если экономия растёт, а количество исправлений — тоже, ужесточите правила.
Стоит ли использовать один общий кэш для всех пользователей?
Нет, не по умолчанию. Общий кэш может привести к утечке данных аккаунта или учетных записей арендатора. Ограничивайте приватные данные кэшем, привязанным к пользователю или арендаторам, и делайте такой кэш короткоживущим.
Какой порядок развёртывания минимизирует риски?
Развертывайте слоями. Сначала добавьте точечное повторное использование ответов в одном рабочем процессе, затем повторное использование подсказок для повторяющихся инструкций и только потом — семантическое совпадение на небольшой доле трафика.


