Карта зависимостей сервисов: как показать реальное влияние сбоя
Карта зависимостей сервисов помогает командам увидеть, какие приложения, очереди и сторонние сервисы падают вместе, сочетая трассы, заметки об инцидентах и разборы.
Содержание
Почему медленные сервисы приводят к большим отказам
Медленный сервис редко остаётся изолированным. Если auth API добавляет по две секунды к каждому запросу, ущерб распространяется на вход, оформление заказа, административные инструменты и экраны поддержки одновременно. Пользователям всё равно, какой сервис стал причиной — они просто видят, что "сайт кажется сломанным".
Команды часто ловят первый симптом и упускают цепочку за ним. Один алерт говорит, что выросла латентность у Сервиса A. Другой — что выросли ошибки у Сервиса C. Третий — что глубина очереди прыгнула. Каждый сигнал выглядит отдельным, поэтому люди гоняются за шумом, а не за причиной. Тем временем повторные попытки накапливаются, воркеры ждут ответов, и тайм‑ауты растут по всему стеку.
Это усугубляется, когда одно пользовательское действие зависит от нескольких вызовов. Простое нажатие "оформить заказ" может задействовать прайсинг, инвентаризацию, платежи, почту и проверки на мошенничество. Если один вызов замедляется, всё действие может зависнуть, даже если остальные сервисы остаются здоровыми. Поддержка слышит «заказы иногда не проходят», а инженеры смотрят на графики и видят, что большинство систем всё ещё в порядке.
Распределённое трассирование помогает, потому что показывает путь реальных запросов. Вы видите, кто кому позвонил, сколько занял каждый шаг и где началась задержка. Это гораздо лучше, чем домыслы. Но трассы не говорят, кто первым почувствовал проблему и какая бизнес‑задача фактически остановилась.
Эта недостающая часть обычно живёт в заметках об инцидентах. Записи поддержки, операций и дежурных инженеров объясняют, что люди действительно видели: клиенты не могли завершить оплату, сотрудники не могли сделать возврат или внутренним пользователям приходилось пытаться одно и то же действие три раза. Эти детали превращают техническое замедление в чёткую картину влияния.
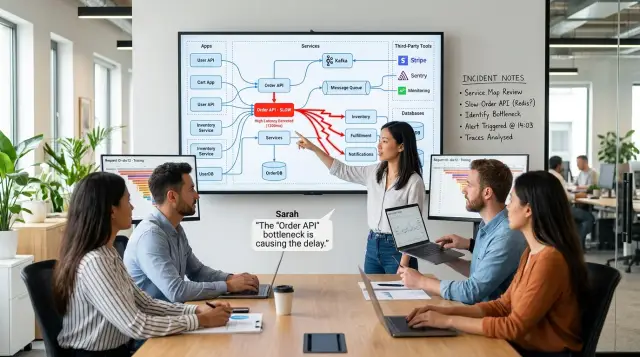
Полезная карта зависимостей сервисов объединяет оба взгляда. Она показывает живую цепочку вызовов из трасс и реальную боль из заметок об инцидентах. Тогда команды видят больше, чем "Сервис B медленный". Они видят, какие пользовательские действия сломались, какие команды заблокированы и почему небольшая задержка превратилась в гораздо больший провал.
Что должна показывать карта зависимостей
Карта зависимостей должна опираться на реальный трафик. Она должна показывать, какие сервисы обмениваются данными во время обычных запросов, а не то, что написано в старой диаграмме. Когда веб‑приложение вызывает auth, auth проверяет кэш, а сервис заказов пишет в базу — карта должна ясно показывать эту цепочку.
Там также нужны элементы, которые команды обычно забывают. Базы данных, очереди, кэши, поисковые индексы, хранилища, шлюзы почты, платёжные провайдеры и другие вендоры должны быть на карте. Многие инциденты начинаются в одной из этих областей и затем перерастают в ошибки, видимые клиентам.
Бизнес‑пути, а не только имена сервисов
Простая схема из блоков и линий недостаточна. Карта должна отмечать, какие зависимости задействованы при входе, оформлении заказа, биллинге, сбросе пароля и других пользовательских действиях, которые важны для бизнеса. Это быстро меняет разговор. Медленная аналитическая трубопроводка может подождать. Медленный путь биллинга — нет.
Также полезно отделять обязательные системы от опциональных. Некоторые вызовы обязаны пройти, иначе запрос падает. Другие добавляют дополнительные функции — рекомендации, проверки на мошенничество или трекинг событий — и продукт может какое‑то время обходиться без них. Если вы не показываете эту разницу, любой алерт выглядит одинаково срочным.
У каждого сервиса должны быть простые метки: кто им владеет, обязательный он или опциональный, какие пользовательские пути от него зависят и внутренний это сервис или внешний. Владение важнее, чем многие команды ожидают. Во время инцидента люди теряют время, просто пытаясь определить, кто может ответить за сервис. Если у каждого узла есть очевидный владелец, команда может действовать быстрее в первые десять минут — когда путаница наносит наибольший вред.
Подумайте о потоке оформления заказа, который зависит от API‑шлюза, auth, корзины, прайса, инвентаря, платежей, очереди сообщений и почты. Если платеж замедляется, пользователи всё ещё могут смотреть каталог, добавлять товары и входить в систему, но доход останавливается. Хорошая карта делает это очевидным ещё до начала разборов инцидента.
Начинайте с трасс, а не с догадок
Карта зависимостей должна основываться на реальном трафике. Если вы нарисуете её по памяти, люди пропустят медленные вызовы, скрытые повторные попытки и сервисы, которые проявляются только под нагрузкой.
Начните с пользовательских потоков, которые приносят наибольший бизнес‑вес и генерируют больше всего трафика. Для многих команд это вход, поиск, оформление заказа, биллинг или API‑запросы, которые идут весь день. Тихая админ‑страница может показаться простой, но она мало скажет о влиянии при отказе.
Затем сгруппируйте повторяющиеся вызовы в понятные сервисные пути. Вы не пытаетесь поймать все крайние случаи в первый день. Вам нужны пути, которые пользователи проходят снова и снова, например: веб‑приложение -> API -> auth -> пользовательская БД или API -> платёжный сервис -> проверка на мошенничество -> очередь.
Для каждого пути измеряйте сигналы, которые меняют опыт пользователя: латентность на каждом шаге, частоту ошибок, повторные попытки между сервисами и место, где начинаются тайм‑ауты. Эти четыре числа объясняют больше, чем статическая диаграмма. Сервис может выглядеть здоровым, если он всё же отвечает, в то время как пользователи ждут восемь секунд, потому что другой сервис постоянно повторяется в фоне.
Периоды «здоровья» могут вводить в заблуждение, поэтому проверьте и недавние инциденты, даже небольшие, длиной в десять минут. Эти трассы показывают пути, которые первыми сгибаются под нагрузкой. Они также выявляют поведение отката, накопление очередей и странные зависимости, невидимые в обычные дни.
Очистите данные, прежде чем им доверять. Тестовый трафик, нагрузочные тесты, внутренние скрипты и бэконсты могут исказить карту. Если ночная задача пробегает по десяти сервисам подряд, это не значит, что обычное действие клиента зависит от всех десяти. Держите продакшн‑пользовательский трафик отдельно, иначе карта превратится в шум.
Простой пример покажет разницу. Команда может думать, что оформление заказа зависит только от корзины, платежей и базы. Трассы часто показывают больше: расчёт налогов, скоринг на мошенничество, подтверждение по почте, сервис фичфлагов и цикл повторных попыток по инвентарю. Это версия карты зависимостей, которую можно использовать во время инцидента, потому что она отражает то, что действительно триггерят пользователи.
Добавьте то, чего трассы не скажут
Трассы показывают перемещение запросов по сервисам. Они не показывают грязные обходы, которые люди собирают руками в два часа ночи. Если поддержка делает возвраты в бэк‑офисе, когда оформление заказа застопорилось, этот обход должен быть на карте. Если отдел продаж начинает принимать заказы по телефону при замедлении сайта, добавьте и это. Карта должна показывать и софтверные связи, и человеческие пути, которыми команды держат бизнес в движении.
Заметки об инцидентах — самый быстрый способ найти этот недостающий контекст. Читайте старые постмортемы, обсуждения в чатах и сводки дежурств. Ищите строки вроде "ops перезапустили импортёр", "support отключили проверки на мошенничество" или "engineering переключил трафик на кэшированные цены". Это реальные зависимости, даже если трасса их не записала.
Некоторые скрытые связи кажутся мелкими, пока не выйдут из строя. Тайм‑ауты DNS могут заставить выглядеть сервисы как упавшие. Хранилища сессий и auth могут блокировать все входы. Фичфлаги могут скрывать оформление заказа или поиск. Лимиты вендоров по платежам, почте или SMS могут превратиться в видимые клиентам сбои. Cron‑задачи и пакетные импорты могут раз в час давить на базу и замедлять всё вокруг.
Бизнес‑влияние важно не меньше технической структуры. Медленный сервис изображений может раздражать пользователей. Медленный вызов расчёта налогов, платежей или прайса может остановить доход за минуты. Отмечайте, какие ошибки блокируют продажи, увеличивают нагрузку на поддержку или создают риски соответствия требованиям. Это делает анализ влияния отказа честнее: команды оценивают ущерб, а не просто считают ошибки.
Также запишите, кого в первую очередь зовут на пейдж и кто реально решает проблему. Иногда первый алерт попадает к API‑команде, но настоящий владелец — identity, сеть или внешний вендор. Этот разрыв может стоить двадцати минут, пока никто не начнёт работать над реальной проблемой. Отобразите это на карте.
Когда начнётся следующий инцидент, люди должны видеть больше, чем "A вызывает B". Они должны видеть скрытую цепочку: если B замедляется, оформление заказа падает, нагрузка на поддержку удваивается, может быть задействован лимит вендора, и платформенная команда будет втянута раньше, чем настоящий владелец подтвердит проблему.
Стройте карту шаг за шагом
Начните с пользовательских путей, которые при поломке стоят вам денег или доверия. Выберите небольшой набор в начале: регистрация, оформление заказа, сброс пароля и доставка счетов. Если пытаться картографировать все потоки сразу, работа застопорится и карта превратится в стену блоков, которой никто не пользуется.
Затем пройдите каждый путь по реальным трассам. Начните с первого запроса и двигайтесь, пока клиент не увидит результат, даже если часть работы перемещается в очередь или выполняется фоном. Чистого пути запроса недостаточно, если результат зависит от воркера, вебхука или стороннего API, который завершает задачу спустя минуты.
По мере рисования каждой связи добавляйте простые заметки о бизнес‑эффекте. Линия между двумя сервисами должна говорить не только "A вызывает B", но и что ломается, если B замедляется, сколько времени пользователи ждут до первого замечаемого отклика и влияет ли это на доход, поддержку или качество данных.
Простой формат помогает. Для каждой связи отмечайте нормальную латентность, медленную латентность, поведение при тайм‑аутах и повторных попытках, владельца сервиса, что видит пользователь при отказе и какие есть ручные обходы.
Затем ищите одиночные точки отказа. Некоторые очевидны, например единый сервис auth, которым пользуются все продукты. Другие скрыты во fallback‑пути. Фоллбек может поддерживать систему «на бумаге», но сильно ухудшать опыт — например переключение на устаревшие данные по инвентарю или задержка подтверждения заказа до завершения фоновой задачи.
Здесь и пригодятся заметки об инцидентах. Трассы покажут, что зависимость замедлилась. Заметки из прошлых сбоев объяснят реальный ущерб: пик тикетов в поддержку, рост возвратов или необходимость приостановить деплои на шесть часов. Этот контекст делает карту честной.
Прежде чем доверять черновику, проверьте его с тремя группами. Инженеры обычно находят отсутствующие асинхронные задачи и циклы повторных попыток. Саппорт укажет паттерны отказов, которые клиенты видят первыми. Продакт подскажет, какие пути заслуживают больше внимания, потому что они влияют на удержание, конверсию или онбординг.
Если всё сделано правильно, карта перестаёт быть архитектурной схемой и начинает работать как план действий при сбое.
Простой пример отказа
В 10:12 магазин начинает получать жалобы. Клиенты жалуются, что оформление заказа висит, и некоторые пытаются повторить оплату. Поддержка вскоре видит вторую проблему: дубликаты заказов. На первый взгляд проблемы выглядят разными. На деле — нет.
Трассы показывают самый загруженный путь через несколько минут. Большинство медленных запросов проходят через оформление заказа, затем прайсинг, затем Redis. Прайсинг ждёт Redis для кэшированных правил скидок, и когда Redis отвечает с задержкой, весь запрос оформления заказа накапливается. Это даёт команде одну ясную цепочку вместо пяти случайных предположений.
Но трассы всё ещё упускают часть истории. Они показывают, что вызовы платёжного провайдера тоже замедлились примерно в то же время, но не объясняют почему. Здесь приходят на помощь заметки об инциденте. Кто‑то уже записал, что платёжный провайдер сообщил о повышенной латентности в одном регионе примерно за десять минут до первых жалоб клиентов.
Теперь карта зависимостей становится полезной. Она не просто говорит "оформление зависит от прайса" и "прайсинг зависит от Redis". Она также показывает, что поведение повторных попыток на клиентской стороне может превратить замедление в дублирование заказов, и что проблема с платёжным провайдером добавляет задержку в наихудший момент. Одна слабая точка запускает другую.
Эта картина меняет реакцию. Команда должна ставить алерты на латентность Redis там, где она влияет на прайсинг, а не только на тайм‑ауты оформления заказа. Нужны также алерты по платёжной латентности, когда она поднимается до уровня, провоцирующего всплески повторных попыток. Для фоллбека прайсингу может понадобиться набор правил по умолчанию или опция использовать устаревший кэш, а в оформлении заказа — механизмы идемпотентности, чтобы один и тот же заказ не списывался дважды.
Хорошая карта зависимостей делает всё это проще и быстрее увидеть. Трассы отвечают на вопрос "куда уходит время?". Заметки об инцидентах — на вопрос "что ещё поменялось вокруг нас?". Соедините их, и команда увидит реальное влияние отказа вместо того, чтобы тушить каждый симптом как отдельный пожар.
Ошибки, которые делают карту бесполезной
Чистая диаграмма всё ещё может ввести команду в заблуждение. Самая частая проблема — охват. Люди пытаются нарисовать каждый внутренний вызов в первый же день и в итоге получают стену стрелок, которую никто не читает во время инцидента.
Начните меньше. Сначала картируйте пути, важные для действий клиентов: вход, оформление заказа, поиск или генерация отчётов. Если карта не помогает ответить "кто посыпется следующим, если это замедлится?" за минуту‑две, она уже слишком перегружена.
Ещё одна распространённая ошибка — исключение работы, которая происходит вне основного пути запроса. Плановые задачи, пакетные импорты, cron‑задачи, админ‑панели и инструменты поддержки часто делают реальный вред, когда падают. Ночная синхронизация может залить базу. Бэк‑офисный инструмент может блокировать записи. Эти связи важны, даже если пользователи их напрямую не видят.
Команды также упрощают карту, когда на самом деле зависимость не плоская. Если все линии выглядят одинаково важными, картинка почти ничего не говорит. Тайм‑аут кэша, проблема с платёжным шлюзом и опечатка в внутреннем вызове метрик не должны иметь одинаковый вес.
Используйте простые метки, чтобы показать, насколько важна каждая зависимость. Отмечайте, обязательна ли она, мягкая, асинхронная, редкая или только для персонала. Этот шаг превращает беспорядочную картину в то, чему люди начнут доверять.
Внешние сервисы легко забыть, потому что они кажутся «чужими» и кем‑то другим управляются. Но они всё равно ломают ваш продукт. DNS, провайдеры аутентификации, доставка почты, облачное хранилище, feature flags и API с лимитами могут упаковать потоки, которые внутри вашего кода выглядят здоровыми.
Auth — хороший пример. Одна команда может думать, что только вход зависит от него, но обновление токенов, админ‑действия, мобильные сессии и фоновые воркеры могут все вызывать тот же сервис auth. Если вы это пропустите, анализ радиуса воздействия будет неполным.
Последняя ошибка проста: команды не обновляют карту после реальных инцидентов. Карта быстро устаревает, потому что системы меняются быстро. Появляется новый цикл повторных попыток, старая очередь исчезает, кто‑то добавляет фоллбек, который никто не документировал.
Обновляйте карту после каждого инцидента, пока детали ещё свежи. Добавьте скрытую зависимость, удалите мёртвую, отметьте, какой путь упал первым. Если вы будете делать это каждый раз, карта останется маленькой, честной и полезной под давлением.
Быстрая проверка перед тем, как доверять карте
Карта заслуживает доверия только тогда, когда новому человеку можно ею воспользоваться под давлением. Откройте один распространённый пользовательский путь, например вход, оформление заказа или загрузку файла, и попросите коллегу, который не рисовал карту, пройти от первого запроса до последнего побочного эффекта. Он должен увидеть основной путь, фоновые задачи и внешние вызовы без дополнительных вопросов. Если он теряется, карта отражает организационную схему больше, чем систему.
Владение должно быть очевидным. Каждый сервис, который может разбудить людей в 2 утра, нуждается в именованной команде или человеке и краткой заметке о том, что он контролирует. Блок без владельца создаёт задержки при инциденте. Люди тратят время на то, чтобы узнать, кто может перезапустить сервис, кто знает базу данных или кто может одобрить откат.
Полезная карта также показывает бизнес‑боль, а не только трафик. Отметьте, какое замедление бьёт по деньгам в первую очередь. Для одного продукта это может быть оформление заказа, для другого — регистрация, поиск или доставка рекламы. Если все сервисы выглядят одинаково серьёзными, карта не поможет выбирать, что чинить вначале.
Затем сравните трассы с заметками об инцидентах. Трассы показывают тайминг и пути вызовов. Заметки объясняют обходы, скрытые зависимости, лимиты и человеческие шаги, которые трассы упускают. Если трассы говорят, что проблема началась в сервисе A, а журнал инцидентов утверждает, что реальная боль началась, когда повторы биллинга забили очередь, разберитесь в расхождении. Одна из записей устарела, неполна или и то, и другое.
Перед тем как считать карту завершённой, проверьте пять вещей:
- Новая команда может проследить один поток клиента от начала до конца.
- Каждый сервис с риском отказа имеет явного владельца.
- На карте отмечено, какое падение бьёт по доходу в первую очередь.
- Заметки об инцидентах и трассы рассказывают одну и ту же историю.
- Команда обновила карту после последнего инцидента, миграции или крупного релиза.
Последний пункт важнее, чем многие признают. Системы меняются тихо. Один новый кэш, переименованная очередь или сдвинутый cron‑таск может сделать карту аккуратной и всё же вводящей в заблуждение, когда в продакшне что‑то идёт не так.
Что делать дальше
Не начинайте с покрытия всех сервисов. Выберите один поток, который сильно бьёт при сбое, и замапьте его на этой неделе. Для большинства команд это регистрация, вход, оформление заказа, биллинг или тот API‑путь, который приносит больше всего тикетов в поддержку.
Первая версия карты не обязана быть идеальной. Ей достаточно быстро отвечать на простой вопрос: если этот сервис замедлится, кто почувствует это, как скоро и что должен первым проверить дежурный?
Простая еженедельная рутина работает хорошо. Выбирайте один пользовательский поток и проходите его по трассам от первого запроса до последнего downstream‑вызова. Добавляйте контекст, который не видно в трассах: лимиты вендоров, пакетные задачи, внешние API, feature flags и известные слабые места. Отмечайте ошибки, которые реально замечают пользователи: медленные страницы, неудачные оплаты или задержанные письма. Затем сохраняйте карту там, где инженеры и дежурные уже работают, и обновляйте её после следующего инцидента.
Когда у вас появится первая карта, используйте её при каждом разборе инцидента. Постмортемы становятся полезнее, когда команда может указать точный путь ущерба вместо споров и догадок. Обзоры дежурств улучшаются тоже. Вы начнёте видеть повторяющиеся слепые зоны: тайм‑аут, который никто не настраивал, очередь, которую никто не смотрит, фоллбек, который на самом деле не работает.
Повторяющиеся заметки об инцидентах не должны оставаться в старых тикетах. Превратите их в короткие руководы и алерты. Если инженеры постоянно пишут "Сервис B замедляется при всплеске промахов кэша" или "платежи падают, когда провайдер возвращает 429", это уже не просто заметка — это эксплуатационная догма.
Если хотите внешнюю проверку, Oleg Sotnikov на oleg.is работает с командами по трассированию, инфраструктуре и в качестве fractional CTO. Такой аудит обычно наиболее полезен, когда у вас уже есть трассы, некоторая история инцидентов и карта, которая почти работает, но всё ещё упускает реальное влияние отказов.
Часто задаваемые вопросы
What is a service dependency map?
Карта зависимостей сервисов показывает, как одно пользовательское действие проходит через вашу систему. Она соединяет сервисы, базы данных, очереди, вендоров и фоновые задачи, чтобы команда видела, что ломается, когда какая‑то часть замедляется.
Why are traces not enough on their own?
Трассы показывают последовательность и время вызовов, но не отражают ручные обходы и реальную боль бизнеса. Заметки об инцидентах говорят, кто первым почувствовал проблему, что видел пользователь и какие ручные шаги поддерживали работу.
What should I include besides services?
Добавьте базы данных, кэши, очереди, хранилища, поиск, доставку почты, платёжных провайдеров, DNS, feature flags и любые пакетные задания, которые затрагивают поток. Если при сбоях поддержка или операторы выполняют ручной обход — тоже добавьте это.
Which user flows should I map first?
Начните с потоков, которые при сбое приводят к потере денег или доверия. Для большинства команд это вход, оформление заказа, биллинг, регистрация, поиск или API‑маршруты, которые генерируют больше всего тикетов в поддержку.
How do I show which dependencies matter most?
Отмечайте каждую зависимость как обязательную, необязательную, асинхронную, редкую или доступную только для персонала. Добавьте короткую заметку о том, что видит пользователь при замедлении или падении этой зависимости.
How do incident notes make the map better?
Прочитайте прошлые постмортемы, ветки в чатах и сводки on‑call. Эти заметки часто выявляют лимиты вендоров, всплески повторных попыток, бэк‑офисные шаги и путаницу с владельцами — то, чего трассы не показывают.
What signals should I track for each dependency?
Отслеживайте латентность, уровень ошибок, повторные попытки и место, где начинаются тайм‑ауты. Эти четыре сигнала обычно объясняют, почему пользователи ощущают задержки, даже если большинство сервисов всё ещё отвечают.
How do I stop the map from becoming a wall of arrows?
Держите первую версию маленькой и сосредоточенной на одном пользовательском пути. Если карта не помогает ответить «кто пострадает следующим, если это замедлится?» за минуту‑две, урежьте её.
How does the map help during an incident?
Во время инцидента карта помогает быстрее найти ломающийся путь и вызвать правильного владельца. Она также показывает бизнес‑влияние, поэтому команда чинит оформление заказа раньше, чем гоняется за несущественной внутренней ошибкой.
How often should I update the dependency map?
Обновляйте карту после каждого сбоя, миграции или крупного релиза. Системы меняются быстро, и один новый кэш, переименованная очередь или правило повторных попыток могут сделать старую карту вводящей в заблуждение.


