Кардинальность меток в Prometheus: правила именования, которые остаются здравыми
Кардинальность меток в Prometheus быстро дорожает, если метки хранят user ID, URL или хэши. Используйте простые правила, чтобы дашборды оставались быстрыми, а затраты — под контролем.
Содержание
Что происходит, когда метки растут без ограничений
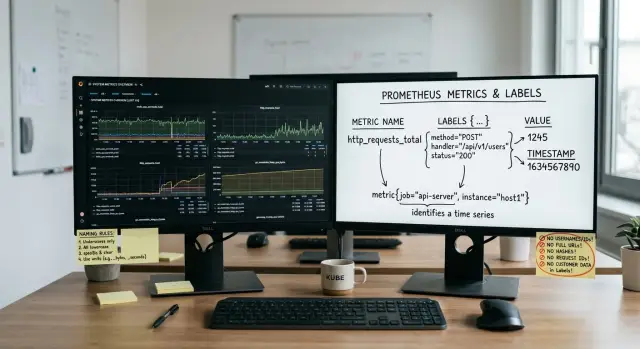
Кардинальность меток в Prometheus — это количество уникальных временных рядов, которые создают ваши метрики. Метрика без меток — это один ряд. Добавьте method="GET" и method="POST", и у вас уже два ряда. Добавьте status, region и instance, и общее число быстро умножается.
Проблемы начинаются, когда метка может породить почти бесконечное количество новых значений. user_id, session_id, request_path, ip или сырое сообщение об ошибке могут выглядеть безобидно в коде. В Prometheus каждое новое значение создаёт ещё один ряд для хранения, индексации и поиска.
Такой рост легко пропустить. Десять сервисов с несколькими стабильными метками обычно остаются в порядке. Те же десять сервисов с метками, меняющимися при каждом запросе, могут превратить одну метрику в тысячи или миллионы рядов. В этот момент метрика перестаёт помогать и начинает сжигать память, диск и время запросов.
Вы обычно замечаете это сначала на дашбордах. Панели, которые раньше грузились за секунду, начинают подвисать или таймаутиться. Простые графики кажутся медленными, потому что Prometheus вынужден искать гораздо больше рядов, чем реально нужно для графика. Если вы также отправляете метрики в долгосрочное хранилище, счёт за хранение растёт вместе с шумом.
Есть и цена за читаемость. Метки с высокой кардинальностью превращают дашборды в захламлённый экран. Вместо того чтобы видеть уровень ошибок по сервису или задержки по маршруту, вы получаете стену крошечных срезов, разделённых случайными ID и единичными значениями. Сигнал всё ещё есть, но он зарыт.
Распространённый пример — задержки запросов с path, в котором хранится полный URL. /product/123, /product/124 и /product/125 становятся отдельными рядами, хотя описывают один и тот же маршрут. Добавьте методы, коды статуса и инстансы, и график быстро раздувается.
Prometheus лучше всего работает, когда метки описывают небольшой набор стабильных измерений. Как только метки начинают напоминать логи, система мониторинга замедляется, и данные становятся менее надёжными.
Метки, которые обычно приводят к проблемам
Большинство проблем с метками возникает из-за значений, которые никогда не устаканиваются. Метка полезна, когда один и тот же небольшой набор значений повторяется с течением времени. Она становится дорогой, когда почти каждый скрейп приносит новое значение, потому что Prometheus хранит отдельный ряд для каждой уникальной комбинации меток.
User IDs — частая ошибка. Кажется полезным фильтровать метрики по конкретному человеку, но метка user_id создаёт новый ряд для каждой учётной записи. В загружённом приложении этот счётчик будет расти весь день.
Request ID и trace ID ещё хуже. Они меняются при каждом вызове, поэтому почти гарантируют бесконечный рост. Session ID, cart ID, order token и похожие поля создают ту же проблему. Держите эти детали в логах или трассировках, где уместны данные уровня событий.
Полные URL дают более тихую версию той же беды. Prometheus не понимает, что /product/101 и /product/102 — одна и та же схема страницы. Он видит только разные значения метки. Метка маршрута вроде /product/:id делает метрику читаемой и прекращает рост числа рядов без причины.
Другие плохие кандидаты: хэши, контрольные суммы, точные временные метки, полные пути к файлам, сырые поисковые термины и адреса электронной почты. Эти значения редко повторяются, а некоторые — почти никогда. Данные могут быть важны, но им место в логах, трассировках или базе данных, а не в метрике.
Простое правило ловит большинство ошибок: если метка будет каждый день получать новые значения и вы не можете назвать явный предел, не кладите её в метрику. Команды часто добавляют такие метки в процессе отладки, а потом забывают убрать. Сказать «нет» сразу гораздо проще, чем чистить всё через месяцы.
Правила именования, которые остаются понятными
Многие проблемы с кардинальностью начинаются с имён, которые выглядят безобидно. Команда быстро добавляет метки, каждый сервис придумывает свой стиль, и через шесть месяцев никто не знает, означают ли region, zone и location одно и то же.
Хорошие имена меток короткие, простые и скучные. Это комплимент. Если кто‑то открывает запрос в 2 утра, он должен понимать каждую метку без копания в коде или старых чатах.
Каждая метка должна везде означать одно и то же. Если status означает HTTP‑статус в одной метрике, не используйте status для состояния заказа или задания в другом месте. Называйте их http_status и job_state. Понятные имена экономят время.
Метки с небольшим ограниченным набором значений обычно безопасны. region, method, status_code и env остаются читаемыми, потому что список значений мал и предсказуем. Если метка может расти без явного ограничения, как user_id, email, request_id или сырый путь URL, ей не место в метрике.
Последовательность важнее идеального имени. Если один сервис использует method, а другой — http_method, запросы быстро становятся громоздкими. Держите одно имя и используйте его в командах и сервисах.
Читаемость также означает выбирать имена, которые люди смогут угадать с первого взгляда. az экономит два символа, но многие начнут спрашивать, что это значит. availability_zone длиннее, но понятно.
Быстрый тест работает хорошо: покажите метрику человеку вне команды. Если он может объяснить, что означает каждая метка и какие значения она может принимать, имя, вероятно, в порядке. Если нужен экскурсовод — переименуйте до распространения.
Как решить, принадлежит ли метка метрике
Метка должна заслужить своё место. Прежде чем добавить её, задайте простой вопрос: какое решение поможет принять эта метка, когда график всплескает или сработает алерт? Если вы не можете ясно ответить, метка, скорее всего, шум.
Хорошие метки отвечают на операционные вопросы: «какой регион медленный?» или «какой код статуса растёт?». Плохие метки дают одну запросную мелочь, вроде request ID, email, session token или полного URL с пользовательскими частями.
Проверьте размер набора значений, не только сегодня, но и через шесть месяцев. region="us-east-1" остаётся небольшим. customer_id="847221" — нет. Метка, которая начинается с 20 значений и вырастает до 200000, навредит скорости запросов, использованию памяти и стоимости хранения.
Если никто не будет группировать или фильтровать по метке, уберите её. Метка, которая никогда не появляется в дашбордах, алертах или recording rules, только добавляет расходы. Команды часто оставляют метки «на всякий случай» и потом об этом жалеют.
Пять вопросов перед добавлением метки
Сохраните метку только если на большинство из этих вопросов вы ответите «да»:
- Вы можете назвать график или алерт, для которых она нужна.
- Набор значений остаётся малым и предсказуемым.
- Люди будут группировать или фильтровать по ней во время инцидентов.
- Метка не является уникальным идентификатором.
- Логи или трассы не несут те же детали лучше.
Небольшое веб‑приложение ясно это показывает. endpoint="/checkout" имеет смысл, если команда сравнивает задержки по нескольким маршрутам. user_id — нет. Если поддержке нужно посмотреть один неудачный checkout, логи или трассы могут хранить user_id и request_id, а метрика оставит только метки, суммирующие поведение.
Это правило звучит скучно — и именно поэтому оно работает. Метрики должны оставаться грубыми настолько, чтобы быстро отвечать на системные вопросы. Уникальные или растущие значения отправляйте в другое место.
Как постепенно убрать плохие метки
Начните с одной метрики, а не со всего стека. Запишите все метки, которые она экспортирует. Если метрика запросов имеет method, status, path, user_id, session_id и trace_id, перечислите все шесть перед тем, как что‑то менять.
Затем отметьте каждую метку как ограниченную или неограниченную. Ограниченная метка имеет небольшой известный набор значений, например GET и POST, 200 и 500, или маршрут вроде /users/:id. Неограниченная метка может продолжать расти бесконечно: сырые URL, ID аккаунтов, email, хэши, поисковые запросы, тела запросов и произвольные тексты ошибок.
Этот простой обзор ловит большинство проблем с кардинальностью до того, как они дойдут до хранилища.
Оставляйте метки с небольшим фиксированным набором значений. Заменяйте сырые пути и URL шаблонами маршрутов. Удаляйте ID, UUID, хэши, временные метки и свободный текст. Если можете, уберите плохую метку в приложении до выхода из процесса. Если быстро изменить приложение нельзя, используйте relabeling, чтобы переписать или удалить метку до сохранения.
Сырые URL — распространённая ловушка. /product/123 и /product/124 почти одинаковы для человека, но Prometheus хранит их как разные ряды. Поменяйте их на /product/:id или другой стабильный шаблон, соответствующий вашему роутеру.
Если метка полезна только при отладке одного запроса одним человеком, её обычно не место в метрике. Поместите такие детали в логи или трассы. Метрики должны показывать закономерности по множеству запросов, а не отпечатки одного события.
После очистки протестируйте результат в dev или staging. Сравните число временных рядов до и после, затем прогоните наиболее важные запросы дашбордов. Если метрика упала с 50 000 рядов до 500, хранение подешевеет, и дашборды обычно снова станут быстрыми.
Простой пример из веб‑приложения
Представьте небольшое SaaS‑приложение с API за дашбордом. Каждый запрос увеличивает один счётчик, и команде нужны метки, достаточные для быстрых ответов на базовые вопросы: какой сервис обработал запрос, какой маршрут использовался, какой HTTP‑метод пришёл и какой код статуса ушёл.
Это обычно выглядит так:
http_requests_total{service="billing",route="/users/:id",method="GET",status="200"}
Эти метки остаются полезными, потому что у них есть явные границы. У вас может быть несколько сервисов, фиксированный набор маршрутов, несколько методов и небольшой диапазон кодов статуса. Дашборды остаются быстрыми, и числа всё ещё дают понятную картину.
Проблема начинается, когда кто‑то добавляет customer_id ко всем метрикам запросов.
http_requests_total{service="billing",route="/users/123",method="GET",status="200",customer_id="84721"}
Теперь каждый клиент создаёт новый временной ряд. Если у сервиса 20 маршрутов, 2 метода и 5 распространённых кодов статуса, у вас около 200 рядов. Добавьте 50 000 customer_id, и метрика стремится к 10 миллионам рядов.
Значение маршрута создаёт вторую проблему. Если приложение экспортирует /users/123, /users/124 и /users/125 как разные метки, каждая пользовательская страница порождает новые ряды. Исправление простое: превращайте динамические пути в шаблоны перед экспортом. /users/123 становится /users/:id. /orders/9981/items/7 — /orders/:id/items/:item_id.
Детали о клиентах всё ещё важны, но метрики — не то место для них. Кладите customer_id, email, имя аккаунта и другие пользовательские значения в логи. Затем добавляйте request ID или trace ID туда, чтобы позже связать всплеск ошибок с конкретной сессией клиента.
Одна небольшая правка делает большую часть работы: удалите customer_id из метрик запросов и нормализуйте маршрут. Вы сохраните те вопросы дашборда, которые люди задают каждый день, и остановите рост числа рядов до того, как вырастет потребление памяти и упадёт скорость запросов.
Ошибки, которые замедляют дашборды
Большинство медленных Prometheus‑дашбордов происходят от одного небольшого выбора: метки, которая создаёт новый временной ряд почти для каждого запроса. Одна метрика превращается в тысячи, прежде чем кто‑то это заметит, и тогда запросы становятся тяжёлыми, панели таймаутятся, а стоимость хранения растёт.
session_id — классический пример. Кажется полезным, потому что помогает проследить путь пользователя, но метрики — не то место для этой детали. Если почти у каждого запроса свой session ID, число рядов прыгает быстро.
Сырые тексты ошибок вызывают ту же проблему. Команды часто добавляют полное сообщение об ошибке как метку, чтобы группировать ошибки в Grafana. Звучит удобно, пока каждое изменение формулировки не создаёт новое значение метки. Таймаут, ошибка SQL и валидационная ошибка обычно сводятся к небольшому набору, например error_type="timeout" или error_type="db".
Ещё одна лёгкая ошибка — держать и маршрут, и полный путь в одной метрике. Маршрут может быть /users/:id, а полный путь — /users/123. Маршрут даёт чистую агрегацию, а полный путь взрывает число рядов. Используйте маршрут в метриках и оставляйте сырые пути для логов или трасс.
Дрейф в именах тоже вреден. Одна команда пишет service, другая — app, третья — app_name для одного и того же. Запросы становятся длиннее, дашборды — неопрятными, и люди начинают дублировать панели, потому что метки не совпадают.
Копирование меток из трассировки в каждую метрику — ещё одна ловушка. Трассировочные данные часто включают request ID, user ID, полные URL и другие неограниченные значения. Метрики требуют противоположного подхода: небольшой стабильный набор меток, который остаётся полезным со временем.
Безопасные дефолты обычно просты. Используйте route, а не полный путь. Используйте код статуса или небольшой тип ошибки, а не сырое сообщение. Одно имя метки на концепцию по всей инфраструктуре. Держите request ID, session ID и trace ID вне метрик.
Если метка помогает вас разобрать один запрос, но не показывает закономерности по множеству запросов, вероятно, её место не в Prometheus.
Быстрая проверка перед релизом
Метрика может выглядеть безобидно в коде и при этом превратиться в шум в продакшне. Большинство ошибок с метками очевидны, если потратить пять минут и посмотреть на реальный вывод, вместо того чтобы слепо доверять коду.
Перед тем как отправить новую метрику или изменение меток, посчитайте, сколько различных значений может давать каждая метка. Несколько HTTP‑кодов — нормально. Метка, привязанная к пользователям, заказам или запросам — нет. Просканируйте на предмет всего неограниченного: ID, UUID, хэши, email, session токены, временные метки и сырые пути URL. Спросите, на какой вопрос отвечает метрика в дашборде или алерте. Если никто не будет группировать или фильтровать по этой метке — удалите её.
Затем сравните имена меток с остальными метриками. Если один сервис пишет env, а другой — environment для одного и того же, запросы быстро запутаются. Наконец, просмотрите один пример скрейпа перед релизом. Реальный вывод выявляет сюрпризы: полные пути, динамические имена job или метки, скопированные из заголовков запроса.
Эти проблемы обычно начинаются с одной метки, которая казалась удобной в разработке. Кто‑то хочет больше деталей, добавляет user_id или path, и метрика работает на ноутбуке. Неделю спустя дашборды тормозят, память растёт, и счёт за хранение следует за этим.
Хорошая метка остаётся небольшой и предсказуемой с течением времени. Она должна помогать отвечать на реальный вопрос. method имеет смысл, потому что люди сравнивают GET и POST. build_sha обычно нет, если только вы действительно не разбиваете метрики по каждому деплою каждый день.
Примерный скрейп часто даёт лучший проверочный эффект. В веб‑приложении route="/users/:id" обычно безопасна. path="/users/123" — нет, потому что каждый новый ID создаёт ещё один ряд. То же правило относится к именам арендаторов, названиям файлов и всему, что копируется прямо из пользовательского ввода.
Если вы не можете оценить количество значений метки за минуту, считайте её подозрительной. Эта короткая пауза перед релизом гораздо дешевле, чем чистка шумного сервера Prometheus позже.
Что делать дальше
Запишите короткую политику именования и повесьте её там, где её увидит каждый инженер. Решите, как должны читаться имена метрик, какие метки разрешены и какие значения никогда не должны быть в метках, например user IDs, сырые URL, адреса почты, request ID и временные метки.
Держите политику короткой. Часто одной страницы хватает. Если для добавления одной метрики нужен долгий митинг — правила, вероятно, слишком расплывчаты.
Сделайте политику частью ежедневной работы. Проверяйте новые метрики в код‑ревью. Добавьте CI‑чеки на распространённые плохие шаблоны. Блокируйте очевидные случаи, где метки содержат неограниченные значения. Храните пару хороших примеров метрик в документации команды, чтобы инженеры копировали правильный шаблон, а не придумывали новый.
Это быстро окупается. Плохие метки добавляются за минуты, но могут замедлить дашборды, поднять стоимость хранения и зарыть нужные вашей команде числа во время инцидента.
Проверяйте старые дашборды и алерты тоже. Ищите панели, которые сканируют слишком много рядов, зависят от широких регулярных выражений или тянут метки, которыми никто не пользуется для принятия решения. Старые запросы часто держат дорогие метрики в живых задолго до того, как оригинальная причина исчезнет.
Чистите исходники, а не только графики. Скрытие шумной метки в дашборде не уменьшит кардинальность. Удалите плохие метки в инструментировании или relabeling, затем отключите неиспользуемые метрики из scrape‑job, алертов и recording rules.
Также полезно назначить одного человека ответственным за «гигиену» метрик. Ему не нужно одобрять каждое изменение, но он должен держать правила ясными, отвечать на вопросы и замечать дрейф до того, как он распространится.
Если ваш Prometheus уже кажется беспорядочным, стороннее мнение может сэкономить время. Oleg Sotnikov at oleg.is работает как Fractional CTO и советник для стартапов; его опыт управления продакшн‑инфраструктурой упрощает такие очистки и помогает выработать понятный план.
Поставьте регулярный аудит в календаре. Проверяйте новые метрики, задания с большим числом рядов и медленные дашборды раз в месяц. Проблемы с кардинальностью возвращаются незаметно, поэтому короткий обзор сейчас гораздо дешевле, чем очередная очистка после скачка счёта.
Часто задаваемые вопросы
Что такое кардинальность меток в Prometheus?
Prometheus создаёт один временной ряд для каждой уникальной комбинации метрики и набора меток. Если добавлять метки с большим количеством значений, одна метрика может превратиться в тысячи или миллионы рядов, что замедлит запросы, повысит потребление памяти и увеличит стоимость хранения.
Какие метки обычно вызывают проблемы с кардинальностью?
Избегайте меток, которые постоянно получают новые значения, например user_id, request_id, session_id, trace_id, адреса электронной почты, сырые IP, хэши, временные метки и сырые текстовые сообщения об ошибках. Такие данные лучше хранить в логах или трассировке, а не в метриках.
Плохо ли использовать `path` как метку для метрик запросов?
Да, если вы храните полный путь вроде /users/123. Это создаёт новый временной ряд для каждого ID. Используйте стабильную метку маршрута, например /users/:id, чтобы Prometheus группировал похожие запросы.
Как решить, должна ли метка находиться в метрике?
Оставляйте метку только если кто‑то будет группировать или фильтровать по ней в дашборде, алерте или recording rule. Хорошие метки отвечают на системные вопросы: какой регион медленный, какой код статуса растёт и т. п. Если метка помогает только для одного запроса — не добавляйте её.
Как понять, слишком ли велик набор значений метки?
Посмотрите реальные метрики и спросите, сколько различных значений может иметь каждая метка за месяц, а не только сегодня. Если вы не можете за минуту назвать разумный предел, считайте метку рискованной.
Что использовать вместо `user_id` или `request_id` в метриках?
Поместите эти данные в логи или трассы, а метрику держите грубой. В логах можно хранить user_id, request_id и полные URL, затем связать всплеск по метрикам с конкретным сеансом по request или trace ID.
Поможет ли relabeling, если я не могу сразу поменять приложение?
Да. Если вы не можете быстро изменить инструментирование, используйте relabeling, чтобы удалить или переписать плохие метки до того, как Prometheus их сохранит. Это удобно для сырых путей, скопированных заголовков и других шумных значений.
Какие правила именования делают метрики читаемыми?
Выберите одно название для каждой концепции и используйте его везде. Если один сервис пишет method, а другой — http_method, запросы быстро станут громоздкими. Ясные имена вроде http_status, route, service и env обычно работают долго.
Стоит ли класть `build_sha` или информацию о версии в метки?
Обычно нет. Метка build_sha разделит каждую метрику по каждому деплою, что быстро добавит рядов и редко даст много пользы. Оставляйте данные о релизе в метаданных релиза, если только вы действительно не сравниваете метрики по версиям каждый день.
Как часто нужно проводить аудит метрик и меток?
Проверяйте новые метрики перед релизом и проводите аудит стека по расписанию, часто раз в месяц. Если дашборды уже тормозят или наборы рядов выглядят грязными, запросите свежий обзор от того, кто знает Prometheus и продакшн‑системы.


