Избыточная запись в Postgres из-за журналов аудита в растущих приложениях
Избыточная запись в Postgres может незаметно повышать расходы на CPU, IOPS и хранение, если история аудита живет в горячих таблицах. Узнайте, когда стоит разделить схему.
Содержание
Почему журналы аудита замедляют запись
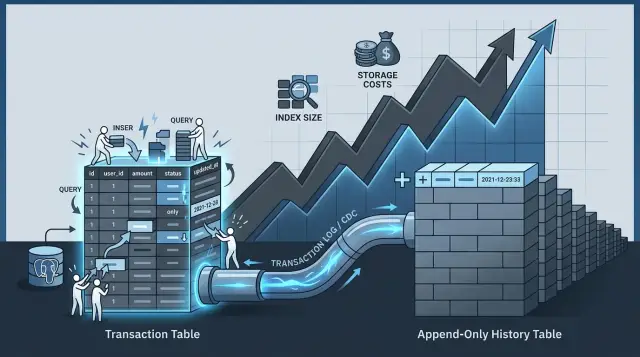
Избыточная запись в Postgres начинается тогда, когда одна бизнес-запись превращается в целый набор операций с хранилищем. Ваше приложение может сохранить всего одно изменение, например перевести заказ из "paid" в "shipped". Но Postgres все равно должен записать новую версию строки, затронуть каждый измененный индекс, записать WAL и следить за видимостью строк и свободным местом.
Поля аудита только усугубляют ситуацию. Таблица с активными заказами часто хранит еще и updated_at, updated_by, номера версий, подсказки по истории статусов или payload с изменениями. Это значит, что одно бизнес-событие меняет не только сам заказ. Оно меняет и служебные данные, а каждый измененный столбец может привести к дополнительным записям страниц.
Размер строки важнее, чем многие команды ожидают. Когда в одной горячей таблице лежат поля аудита, JSON-объекты или длинный текст, на каждой странице помещается меньше строк. Таблица растет быстрее, кэш работает хуже, и базе приходится перебрасывать больше страниц, чтобы выполнить тот же объем работы. Autovacuum тоже получает больше мертвых версий строк, которые нужно чистить.
Индексы добавляют еще один слой затрат. Если вы индексируете поля аудита, чтобы потом искать историю, каждая вставка или обновление требует поддержки большего числа индексных записей. Если индексированное поле аудита меняется при каждой записи, Postgres часто уже не может дешево выполнить обновление. Ему приходится снова менять страницы индекса, а не ограничиваться страницей таблицы.
Паттерн чтения тоже конфликтует. Живые транзакции хотят небольшой, хорошо прогретый набор данных в памяти. Запросам по истории нужны широкие сканы по диапазонам времени, пользователям и типам событий. Когда обе нагрузки живут в одной таблице, они конкурируют за кэш и дисковый ввод-вывод. Отчетный запрос может вытеснить из памяти горячие страницы заказов, и тогда обычный checkout-трафик платит за это.
Сначала такой дизайн кажется аккуратным, потому что все лежит в одном месте. Но в растущем приложении он незаметно одновременно повышает стоимость записи, рост хранилища и шум в запросах. Прежде чем добавлять еще индексы или покупать больше диска, проверьте, не тащит ли ваша горячая транзакционная таблица историю, которая не нужна ни одной живой операции.
Признаки того, что одна таблица делает слишком много
Обычно таблица сама выдает себя еще до полной аварии. Первый признак прост: чтение по-прежнему кажется дешевым, но каждая запись стала дороже, чем месяц назад. Новые строки вставляются медленнее, обновления дольше держат блокировки, а небольшие изменения схемы будто расходятся волнами по всему приложению.
Один распространенный сценарий такой: каждый новый индекс помогает одному запросу, а затем тихо обкладывает налогом все последующие вставки и обновления. Если команда добавляет индекс, чтобы починить отчет, потом еще один для поиска, а затем еще один для админских фильтров, время записи обычно растет шаг за шагом. Это классическая избыточная запись в Postgres. Таблица одновременно выполняет работу по транзакциям и по истории, и эти две задачи мешают друг другу.
Обычно это видно по нескольким признакам:
- Задержка вставки растет после каждого добавленного индекса, даже если трафик почти не меняется.
- Autovacuum работает дольше, запускается чаще или, кажется, вообще не успевает.
- Использование диска растет намного быстрее, чем количество новых заказов, счетов или событий.
- Простые выборки по первичному ключу остаются быстрыми, а части приложения с большим числом записей становятся дороже.
Autovacuum — сильный сигнал, потому что он показывает реальную нагрузку на таблицу. Когда в одной таблице хранятся и актуальное состояние бизнеса, и растущий audit trail, мертвые кортежи накапливаются быстрее, индексы раздуваются, а очистка занимает больше времени. Потом очистка начинает конкурировать с обычным трафиком. Вы платите дважды: сначала на записи, а потом еще раз, когда Postgres вынужден убирать за ней.
Рост хранилища тоже может ввести в заблуждение. Если число транзакций выросло на 20 процентов, а размер таблицы — на 60 процентов, разницу часто лучше объясняют исторические строки, повторяющиеся смены статусов и дополнительное обслуживание индексов, а не рост числа клиентов.
Хорошая таблица может быть загруженной. Перегруженная таблица ощущается странно неравномерной. Приложение по-прежнему быстро отвечает на простые чтения, но запись начинает съедать CPU, IOPS и маржу. Когда появляется такой разрыв, большее хранилище редко решает настоящую проблему. Таблице, скорее всего, нужна более узкая задача.
Что оставить в горячей таблице
Горячая таблица должна хранить факты, которые нужны приложению каждый раз, когда оно открывает экран, проверяет статус или связывает связанные записи. Думайте о ней как о текущем снимке, а не о полной истории. Если строка часто меняется, держите ее компактной, потому что избыточная запись в Postgres усиливается, когда каждое обновление должно затрагивать широкие строки и слишком много индексов.
Для большинства приложений это значит только текущее состояние. В таблице заказов оставьте поля вроде order_id, customer_id, current_status, payment_status, total, currency, created_at и updated_at. Это те столбцы, которые приложение читает почти в каждом запросе, и они позволяют быстро отвечать на простые вопросы: что это за заказ, кому он принадлежит и в каком он сейчас состоянии?
По возможности держите маленькими поля для соединений и фильтров. Обычно достаточно идентификаторов, меток времени, коротких перечислений и компактных флагов. Короткий код статуса работает лучше, чем длинное текстовое описание, которое часто меняется. Если приложение фильтрует по команде, аккаунту, региону или состоянию, эти поля тоже должны быть здесь, но только если ими действительно пользуются каждый день.
Полезное правило простое:
- Оставляйте столбцы, которые определяют текущий интерфейс и ответы API.
- Оставляйте столбцы, которые используются в частых фильтрах и соединениях.
- Оставляйте столбцы, нужные для биллинга, прав доступа или бизнес-правил в момент записи.
- Оставляйте только немного свежего отладочного контекста.
Последний пункт особенно важен. Командам поддержки иногда нужен быстрый ответ, когда что-то ломается, поэтому короткое окно для диагностики можно оставить в горячей таблице. Но держите его маленьким: last_error_code, last_error_at, retry_count или метку времени последнего изменения состояния. Так у операторов будет достаточно контекста для свежих проблем, но главная таблица не превратится в журнал аудита.
Тот же подход применяйте к индексам. Добавляйте только те, что защищают ежедневные запросы, а не все запросы, которые кто-то может запустить раз в месяц. Если приложение всегда ищет по order_id и часто фильтрует по customer_id и current_status, индексируйте именно эти пути. Редкие отчетные сценарии не должны находиться в горячей таблице. Они не должны делать каждую запись дороже.
Что переносить в append-only историю
Переносите все, что объясняет прошлое, но не помогает быстрее завершить следующую запись. Горячая таблица должна отвечать на один вопрос: что верно прямо сейчас? Таблица истории должна хранить след того, как это состояние возникло.
Хороший первый кандидат — старые версии строк. Если заказ меняет статус шесть раз, самой записи обычно нужны только текущий статус, текущие суммы и текущие данные по доставке. Предыдущие пять версий по-прежнему важны для аудита, поддержки или проверки споров, но им не место в том же пути записи, что и живой checkout.
То же относится к контексту каждого изменения. Причину обновления, кто его сделал, и исходный payload события храните в append-only истории. Эти данные полезны, но большинству приложений они не нужны, когда клиент входит в аккаунт, оплачивает заказ или редактирует профиль. Если вынести их из горячих транзакционных таблиц, уменьшается число лишних переписываний строк и снижается избыточная запись в Postgres.
Редко читаемые примечания по соответствию требованиям тоже должны лежать там. Команды часто держат рядом с активными записями комментарии проверки, заметки об утверждении или снимки политик, потому что так кажется аккуратнее. На практике это обычно дорого. Такие поля со временем растут и делают каждое обновление тяжелее, даже если в обычной работе приложения их никто не читает.
Отчетные индексы — еще одна типичная ловушка. Если индекс помогает экспортам для финансов, поиску по аудиту или ежемесячным операционным отчетам, по возможности держите его на стороне истории. Не заставляйте checkout или login платить за индексы, которые помогают только отчету, запускаемому два раза в неделю.
Рабочее правило простое:
- Храните текущее состояние в горячей таблице.
- Переносите предыдущие состояния в историю.
- Переносите в историю actor, reason и исходные данные события.
- Переносите в историю примечания по соответствию требованиям и индексы, ориентированные на отчеты.
Например, таблица заказов может хранить status = shipped и последний адрес. Таблица истории может хранить, что заказ прошел путь от paid к packed и затем к shipped, какой сотрудник это изменил и какое исходное событие запустило каждый шаг. Поддержка по-прежнему видит полную картину, но повседневные записи остаются легче.
Простой пример системы заказов
Представьте небольшой ecommerce-сервис с тысячами заказов каждую неделю. Поддержке нужно открыть заказ, проверить текущий статус, подтвердить сумму и ответить клиенту за несколько секунд. Им не нужно читать каждое изменение статуса, которое когда-либо пережил заказ.
Таблица orders должна хранить текущую правду для повседневной работы. Обычно это одна строка на заказ с полями вроде customer_id, текущего status, текущего total, состояния оплаты, состояния доставки и времени последнего обновления. Когда клиент меняет адрес или платеж проходит, приложение обновляет именно эту строку, чтобы последнее состояние оставалось легко доступным для чтения.
Вторая таблица, которую часто называют order_history, записывает каждое изменение отдельной строкой. Она может хранить order_id, метку времени, источник изменения, например user, support или system, и само событие. Для одного заказа история может показать: создан в 10:02, платеж подтвержден в 10:03, адрес исправлен в 10:11, упакован в 14:20, отправлен в 18:05.
Такое разделение меняет и то, как люди работают с базой. Сотрудники поддержки читают таблицу orders, когда ищут недавние заказы, фильтруют по клиенту или сортируют по последней активности. Эти запросы остаются быстрыми, потому что они проходят по текущим строкам, а не по многолетним правкам.
Финансы и compliance используют order_history для другой задачи. Им может понадобиться проверить, кто изменил возврат, когда изменились налоговые значения или как заказ проходил проверку. Эти отчеты могут выполняться по собственному расписанию, потому что они не мешают быстрому пути, который приложение использует весь день.
Это простой способ уменьшить избыточную запись в Postgres. Горячая таблица остается легкой и индексированной для текущих поисков. Таблица истории хранит полный след, не заставляя каждый поиск поддержки пробираться через старые записи об изменениях.
Хорошее правило такое: если поле отвечает на вопрос «что верно прямо сейчас?», храните его в orders. Если оно отвечает на вопрос «что было раньше?», записывайте его в order_history. Одно это решение обычно экономит больше, чем еще один раунд индексов.
Разделяйте путь записи поэтапно
Не разделяйте нагруженную таблицу одним большим переносом. Небольшие шаги безопаснее, проще для измерения и их легче откатить, если какой-то отчет или экран все еще зависит от старых данных.
Начните с запросов, которые должны оставаться быстрыми в течение дня. Подумайте об экранах и задачах, которые работают с живыми заказами, платежами, корзинами или балансами счетов. Если запрос существует только для аудита, выгрузок или расследований, он не должен определять дизайн горячих транзакционных таблиц.
- Запишите, какие чтения и записи важнее всего в обычные рабочие часы. Сфокусируйте горячую таблицу на текущем состоянии: статусе, суммах, владельце и тех нескольких метках времени, которые приложению нужны прямо сейчас.
- Создайте таблицу истории с простым паттерном append-only history. Храните по одной строке на изменение с полями вроде ID записи, времени события, actor, типа события и payload со старыми и новыми значениями.
- Сначала перенесите более старые изменения в эту таблицу истории. Делайте это пакетами, чтобы обычный трафик продолжал идти, и проверяйте количество строк по ходу.
- Когда обратная загрузка выглядит правильно, отправляйте все новые audit events в таблицу истории. Не держите в горячей таблице журналы изменений, если приложению не нужен текущий сводный показатель.
- Когда отчеты и инструменты поддержки без проблем читают историю, по одному убирайте лишние индексы с горячей таблицы. Лишние индексы часто усиливают избыточную запись в Postgres, даже если на бумаге чтение выглядит нормально.
Для простой таблицы истории обычно нужно меньше индексов, чем для живой таблицы. Многие команды начинают только с того, что помогает находить записи по ID родителя и диапазону времени. Это удешевляет вставки и делает рост хранилища более предсказуемым.
После каждого шага смотрите на три числа: задержку вставки, раздувание таблицы и использование хранилища. Если после переноса audit events write latency падает, вы движетесь в правильную сторону. Если раздувание не уменьшается, autovacuum, возможно, все еще гоняется за слишком большим числом обновлений в горячей таблице, или старые индексы по-прежнему делают работу, которая больше не нужна.
Такой поэтапный раздел занимает больше времени, чем переписывание за выходные, но он избегает типичного сюрприза: быстрее чтение в одном месте и более медленная запись везде остальном.
Ошибки, которые удерживают расходы на высоком уровне
Многие команды замечают медленную запись, а затем покупают больше диска или добавляют CPU. Но настоящая утечка часто сидит в дизайне таблиц. Избыточная запись в Postgres усиливается, когда данные аудита едут вместе с повседневными транзакциями.
Одна дорогая ошибка — считать историю второй копией живой таблицы. Команды клонируют в audit trail все индексы из текущей таблицы, хотя историю никто не ищет так же, как текущие данные. Каждый лишний индекс делает вставки тяжелее, быстрее раздувает хранилище и добавляет работы при обслуживании.
Еще один частый промах — оставлять большие JSON-объекты в горячем пути. Если каждое обновление тянет полный payload через самую загруженную таблицу, записи становятся тяжелее, а vacuum получает больше работы по очистке. Держите поля, нужные для текущей работы, под рукой. Снимки, тела запросов и подробные метаданные изменений переносите в append-only историю.
Некоторые экраны создают лишние расходы без необходимости. Пользователь открывает страницу заказа, а приложение соединяет текущий заказ с многолетней историей изменений, потому что
Быстрая проверка перед тем, как добавлять новые индексы или диски
Прежде чем добавлять еще один индекс или платить за более крупные диски, проверьте, что несет каждая запись. Избыточная запись в Postgres часто начинается со строк, которые стали слишком широкими, и таблиц, которые пытаются делать две задачи одновременно.
Простой тест помогает: откройте главный экран, который ваши пользователи видят каждый день, и посмотрите на все поля, хранящиеся в живой таблице. Если на экране никогда не показываются «заметка последнего проверяющего», «старый адрес доставки» или каждое изменение статуса, эти данные, возможно, не должны лежать в горячей строке. Одна более узкая строка может сразу снизить нагрузку на запись, потому что Postgres нужно меньше переписывать, меньше обновлять индексных данных и меньше затрагивать страниц.
Затем трезво посмотрите на индексы. Многие команды сохраняют индекс только потому, что один отчет однажды работал медленно. Это дорого, если отчет запускается несколько раз в неделю, а таблица получает записи весь день. Оставляйте индексы, которые поддерживают частые чтения: поиск заказа, текущий статус, недавнюю активность для поддержки. По возможности переносите тяжелые отчетные чтения в таблицы истории, сводные таблицы или плановые выгрузки.
Отчеты часто и есть скрытая причина, почему живые таблицы остаются раздутыми. Если finance, compliance или ops в основном читают прошлые состояния, ночная задача может читать append-only history вместо текущих транзакционных строк. Это скучно, но работает. Приложение днем сохраняет быстрые записи, а отчеты все равно получают полный набор данных.
Старая история тоже нуждается в понятном месте. Если audit rows бесконечно копятся в той же активной области, резервные копии растут, vacuum делает больше работы, а каждое обслуживание занимает дольше. Архивация по датам обычно — самый простой способ исправить ситуацию. Даже простое помесячное разделение упрощает правила хранения и уменьшает рабочий набор.
Задайте себе пять прямых вопросов, прежде чем тратить больше на хранение:
- Нужен ли пользователю этот столбец на главном экране или только в старой записи?
- Ускоряет ли этот индекс частое чтение или только один отчет?
- Может ли ночная задача читать историю вместо живых строк?
- Можно ли архивировать историю по датам с правилом хранения?
- Если сегодня уменьшить живую строку, станут ли записи легче сразу?
Если большинство ответов уводят вас от горячей таблицы, вероятно, вам пока не нужно больше железа. Вам нужен более узкий путь записи.
Что делать дальше
Не начинайте с покупки дополнительного диска или еще одного индекса. Начните с одной занятой таблицы и соберите цифры, которым можно доверять. Измерьте p95 задержку записи, раздувание таблицы, dead tuples, рост WAL и то, как быстро каждую неделю растут индексы.
Этот первый снимок покажет, есть ли у вас реальная проблема избыточной записи в Postgres или только запрос, который нужно привести в порядок. Если одна таблица отвечает и за текущее состояние, и за каждое прошлое изменение, она часто становится дорогой быстрее, чем команды ожидают.
Выберите один поток с большим количеством аудита и протестируйте разделение на небольшом масштабе. Таблица статусов заказов — частый кандидат, потому что она часто обновляется, а старые изменения в основном нужны для compliance, поддержки или отчетов.
Рабочий план обычно такой:
- Держите горячую таблицу сфокусированной на текущем состоянии и тех столбцах, которые приложение читает весь день.
- Записывайте каждое изменение в отдельную append-only таблицу истории.
- Сравните задержку записи, поведение autovacuum и рост индексов до и после разделения.
- Дайте тесту идти достаточно долго, чтобы поймать обычный трафик, а не только тихий час.
Задайте правила хранения до того, как тратить деньги на диск. Многие команды держат годы истории в той же базе, не спрашивая, кто вообще ее еще читает. Такая привычка превращает старые audit rows в налог на каждую новую запись.
Будьте конкретны. Решите, как долго свежая история должна быть удобно доступна в Postgres, когда более старые строки переезжают на более дешевое хранилище и какие индексы на самом деле нужны таблице истории. Обычно для истории нужно меньше индексов, чем для горячих транзакционных таблиц.
Если тест выглядит хорошо, выкатывайте его по одному потоку за раз. Не пытайтесь переписать всю схему во всем продукте сразу. Небольшая победа на одной занятой таблице часто достаточно ясно показывает паттерн, чтобы применить его и в других местах.
Второе мнение может сэкономить много переделок, если изменение затрагивает логику приложения, миграции или отчеты. Oleg Sotnikov проверяет дизайн схемы и план выката как fractional CTO, а его опыт в lean infrastructure и production systems делает такую проверку практичной, а не теоретической.


