Идемпотентность фоновых задач в Python для платежей и синхронизации
Узнайте, как устроена идемпотентность фоновых задач в Python: простые примеры для платежей и синхронизации, безопасные правила повторных попыток, обработка частичных сбоев и шаги очистки.
Содержание
Почему дублирующиеся задачи наносят реальный ущерб
Одно событие может довольно легко создать одну и ту же задачу дважды — чаще, чем ожидают многие команды. Клиент нажимает «Оплатить» ещё раз после медленного спиннера. Вебхук приходит дважды. Очередь возвращает сообщение обратно, потому что воркер не подтвердил его вовремя.
На первый взгляд это звучит безобидно, пока не начинают двигаться деньги или данные. Повторная попытка может ещё раз списать деньги с карты, отправить тот же счёт дважды или импортировать того же клиента в CRM с новым внутренним ID. Первая ошибка бьёт по доверию. Вторая создаёт чистку, которая может затянуться на дни.
Самое неприятное в том, что дубли часто возникают из-за обычных сбоев, а не из-за каких-то экзотических случаев. Воркер может упасть после списания денег, но до того, как сохранит результат. Таймаут может скрыть, принял ли платёжный сервис запрос. Два воркера могут взять одну и ту же задачу почти одновременно. Повторное выполнение может случиться после деплоя, ручного перезапуска или повторной доставки из очереди.
Без идемпотентности фоновых задач в Python повторные попытки превращают обычную обработку ошибок в бизнес-проблему. Повторные попытки нужны — они спасают задачи, когда сеть сбоит или сервисы ложатся на минуту. Но каждая повторная попытка должна приводить к одному и тому же результату в реальном мире, а не создавать новый.
Представьте платёжную задачу для заказа 481. Может случиться десять попыток из-за таймаутов, падений и повторной доставки. Безопасный результат всё равно один: одно списание, одно обновление заказа и один финальный статус в системе.
Тот же принцип работает и для синхронизации. Если задача импорта запускается три раза, контакт всё равно должен существовать один раз и в одном правильном состоянии. Много попыток — это нормально. Один реальный результат — это единственное, что пользователь должен видеть.
Сначала определите контракт задачи
Повторная попытка безопасна только тогда, когда у задачи есть понятный контракт. Для идемпотентности фоновых задач в Python этот контракт важнее самого цикла повторов. Если его пропустить, два воркера могут сделать одну и ту же работу дважды и оба решить, что всё прошло правильно.
Начните с того, чтобы перечислить все побочные эффекты, которые может создать задача. Платёжная задача часто делает больше, чем просто списывает деньги с карты. Она может ещё записать строку платежа, пометить счёт как оплаченный, отправить чек и передать событие в другую систему. Задача синхронизации может создать локальные записи, обновить временные метки и поставить следующую работу в очередь.
Опишите контракт простыми словами:
- Какое внешнее действие может произойти
- Какие строки в базе могут измениться
- Что считается успехом одного запуска
- Что должен сделать второй запуск, если первый уже завершился
- Когда воркер должен остановиться и поднять тревогу
Успех должен означать один бизнес-результат, а не просто «код отработал». Для платёжной задачи успех обычно выглядит так: «клиент списан один раз, и мы сохранили этот результат». Если списание прошло, но воркер упал до сохранения, повторная попытка не должна списывать ещё раз. Она должна найти или подтвердить уже существующее списание и доделать недостающую локальную работу.
Повторные запуски тоже должны иметь определённое возвращаемое значение. Некоторые команды возвращают исходный результат, например ID платежа или импортированной записи. Другие возвращают статус без действия, например «уже обработано». Подойдёт любой вариант, если все вызывающие его части обрабатывают его одинаково.
Правила остановки требуют не меньшего внимания. Если провайдер возвращает противоречивые данные, если запись клиента отсутствует или если задача пять раз подряд упирается в таймаут, нужно прекратить повторные попытки и уведомить человека. Бесконечные повторы превращают маленькую ошибку в хаос с биллингом или в груду дублей.
Выберите idempotency key, который переживёт повторные попытки
Большинство ошибок с повторами начинаются с неправильного идентификатора. Если каждая повторная попытка получает новый случайный ID, воркер не понимает, видит ли он ту же задачу снова или совсем новую.
Используйте бизнес-ID, который уже что-то значит вне воркера. Для платежа это часто ID заказа или ID счёта. Для задачи синхронизации это обычно ID исходной записи в системе, из которой вы импортируете данные. Эти значения не меняются, когда процесс перезапускается, очередь повторно доставляет сообщение или воркер падает на середине.
Для идемпотентности фоновых задач в Python это особенно важно, потому что повторы — это норма. Сетевой таймаут, деплой или переподключение очереди могут запустить одну и ту же задачу дважды за несколько минут. Если idempotency key меняется между попытками, вы теряете всю защиту.
Простое правило помогает: стройте ключ из бизнес-события, а не из самой попытки доставки.
- Хорошие варианты:
order_18452,invoice_90017,crm_contact_4419 - Плохие варианты: UUID, созданный внутри воркера, текущая временная метка, хеш от сырого payload, если порядок полей может меняться
Временные значения ломаются очень легко. То же относится и к хешам payload, когда два одинаковых по смыслу payload сериализуются в разном порядке. Даже небольшие изменения форматирования могут дать другой хеш для одного и того же действия в реальном мире.
Платёжный пример это хорошо показывает. Если клиент нажимает «Оплатить», а задача запускается три раза, все три попытки должны использовать один и тот же платёжный ключ, привязанный к этому заказу. Тогда платёжный шлюз сможет отвергнуть дубликаты или вернуть первый результат вместо нового списания.
Тот же подход работает и для синхронизации. Если запись клиента с исходным ID 4419 была импортирована сегодня и повторена завтра, воркер всё равно должен искать 4419, а не новый retry token. Стабильный вход даёт стабильное поведение — в этом и есть смысл.
Храните состояние там, где его сможет проверить каждый воркер
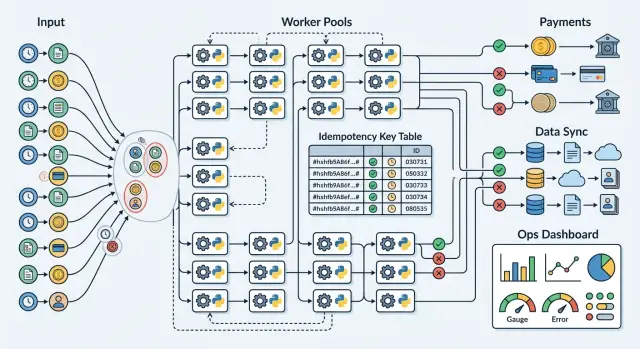
Задача не идемпотентна, если один воркер знает историю, а другой — нет. Память, локальные файлы и кэши на уровне процесса ломаются в тот момент, когда очередь повторно запускает задачу на другой машине. Храните состояние задачи в одном общем месте, обычно в той же базе данных, которой ваши воркеры уже доверяют.
Для идемпотентности фоновых задач в Python правило хранения простое: каждая повторная попытка должна быстро отвечать на два вопроса. Эта задача уже начиналась? И она уже завершилась?
Что сохранять
Обычно достаточно небольшой таблицы:
- idempotency key с уникальным ограничением
- статус вроде started, finished или failed
- ID внешнего запроса, например ID списания у платёжного провайдера или ID batch у синхронизации
- финальный результат, а также временные метки создания, обновления и истечения
Уникальное ограничение важнее, чем думают многие команды. Если два воркера сначала читают, а потом вставляют, они оба могут пройти проверку и оба запустить задачу. Сначала вставьте строку, пусть база отклонит дубликаты, а потом загрузите существующую строку и решите, что делать дальше.
Сохраняйте ID внешнего запроса сразу, как только он появляется. Если платёжный воркер создаёт запрос на списание и падает до того, как записывает обновление заказа, следующая повторная попытка сможет найти тот же внешний ID вместо нового списания. Тот же принцип работает и для задач синхронизации. Если вы уже импортировали клиента A123 в систему, следующая повторная попытка должна использовать это же сопоставление, а не создавать второго клиента.
Сохраняйте и финальный результат, а не только статус. Повторная задача должна по возможности возвращать тот же ответ. Для платежа это может быть «списано» вместе с ID списания и суммой. Для синхронизации это может быть «импортировано» вместе с ID локальной записи.
Не удаляйте эти записи слишком рано. Храните их дольше, чем самый длинный период повторных попыток, и дольше, чем любое окно ручного повторного запуска, которое использует ваша команда. Если повторы могут прийти в течение 72 часов, срок хранения в один день слишком короткий. Многие команды хранят такие строки хотя бы неделю, а платёжным потокам часто нужно ещё дольше.
Если данные растут слишком быстро, архивируйте старые строки. Не выбрасывайте единственное доказательство того, что задача уже запускалась.
Постройте поток шаг за шагом
Для идемпотентности фоновых задач в Python порядок важнее, чем конкретная библиотека воркеров. Безопасный поток прост: проверить состояние, зафиксировать состояние, один раз выполнить внешнее действие, сохранить результат, а потом подтвердить сообщение очереди.
Воркер должен проходить один и тот же путь каждый раз, когда случается повторная попытка:
- Найдите задачу по идентификатору, который безопасен для повторов, до того, как вызовете что-либо вне своей системы. Если финальный результат уже есть, верните его и остановитесь.
- Начните одну транзакцию в базе и вставьте строку задачи или заблокируйте существующую строку. Это не даст двум воркерам одновременно списать одну и ту же карту или импортировать одну и ту же запись.
- Один раз выполните внешнее действие. Это может быть один запрос на платёж или загрузка одной страницы из API партнёра. Сохраняйте весь ответ целиком, включая ID провайдера, коды статуса и детали ошибок.
- Сохраните результат в базе до подтверждения сообщения очереди. Если воркер упадёт после внешнего действия, но до сохранения, следующая повторная попытка не будет иметь доказательств, что действие уже произошло.
- Повторяйте только те части, которые остаются безопасными при повторе. Чтение из базы, проверка статуса и повторная запись того же финального результата обычно безопасны. Второе списание или второй вызов
createобычно — нет.
Этот порядок решает неприятный сценарий, с которым команды сталкиваются в продакшене: платёжный провайдер говорит «success», а потом воркер умирает. При следующем запуске ваш код читает сохранённую строку, видит ссылку на провайдера и пропускает списание. Если сначала сохранить не удалось, а потом ещё и подтвердить сообщение, эта защита исчезает.
Держите модель состояния небольшой. Строки со статусами «started», «finished» и «failed» плюс временные метки и ID внешних ссылок обычно достаточно. Если задача слишком долго висит в started, другой воркер может проверить, произошло ли внешнее действие, а затем закрыть строку, не выполняя действие повторно.
Вот часть, которую многие команды слишком усложняют. Вам не нужен сложный workflow engine, чтобы сделать это правильно уже на этой неделе. Вам нужна одна общая таблица, одна транзакция вокруг блокировки и строгий момент подтверждения сообщения очереди.
Пример с платежами: списать один раз и записать результат
Платежи быстро наказывают за небрежную логику повторов. Если воркер падает после списания, но до записи в базу, следующая повторная попытка может списать деньги ещё раз, если каждый шаг не проверяет один и тот же order_id.
Используйте order_id как стабильный idempotency key. Оставляйте его одним и тем же между повторными попытками, перезапусками воркера и ручными повторными запусками. Если каждая попытка создаёт новый UUID, логика повторов платежа ломается уже при первом таймауте.
Передавайте этот же order_id платёжному провайдеру, когда создаёте списание. Тогда провайдер сможет вернуть исходный результат для повторного запроса вместо создания второго списания. Теперь и приложение, и провайдер отслеживают один и тот же платёж по одной и той же идентичности.
Строго соблюдайте порядок действий:
- Загрузите заказ и остановитесь, если он уже оплачен.
- Проверьте общее состояние по
order_idи используйте любой уже сохранённый результат. - Создайте или подтвердите списание у провайдера, используя тот же idempotency key.
- Сохраните
charge_idи статус провайдера в базе. - Помечайте заказ как оплаченный только после успешной записи.
С таймаутами нужно обращаться особенно аккуратно. Если вызов провайдеру завершился таймаутом, считайте результат неизвестным, пока не проверите списание. Не помечайте его как неудачное и не повторяйте попытку вслепую.
Представьте реальный сбой: списание по карте прошло, но воркер умер до того, как сохранил charge_id. Следующий запуск задачи не должен сначала делать возврат или новое списание. Он должен спросить провайдера, существует ли уже списание для этого order_id, восстановить недостающий charge_id, сохранить его локально и только потом завершить обновление заказа.
Эту проверку на восстановление нужно выполнять до любого возврата или второй попытки списания. Если провайдер показывает успешное списание, зафиксируйте это и закройте разрыв в базе. Если провайдер не показывает списание, повторите попытку с тем же order_id. Именно эта часть идемпотентности фоновых задач в Python экономит деньги, время поддержки и злые письма.
Пример с синхронизацией: импортировать записи без дублей
Задача синхронизации быстро ломается, если считает каждую входящую запись новой. Очереди повторяют доставку, вебхуки приходят снова, а системы-источники присылают события не по порядку. Если воркер слепо вставляет данные, вы получаете дубли клиентов, неправильные счётчики и тяжёлую ручную чистку.
Используйте ID исходной записи как то, что остаётся неизменным между повторными попытками. Для импорта из CRM это может быть source_contact_id. Для синхронизации e-commerce это может быть удалённый ID заказа. Не стройте это на локальном ID базы или на временной метке, созданной воркером. Они слишком легко меняются.
Когда воркер получает запись, он должен выполнять upsert. Это значит «создать строку, если её ещё нет, или обновить существующую, если она уже есть». В Python команды часто делают это с уникальным ограничением на source_id и запросом INSERT ... ON CONFLICT DO UPDATE. Один и тот же source ID — одна и та же локальная строка. Это правило не пускает дубли.
Вам также нужен один параметр, который показывает, какая версия записи новее. Выберите лучший вариант, который даёт источник:
- номер версии
- контрольную сумму исходного payload
- временную метку
updated_at - ID события, если события идут по порядку
Когда старое событие приходит после нового, сравните это значение с тем, что уже сохранено. Если входящая запись старее, пропустите её и зафиксируйте это решение в логах. Иначе обновите строку. Это не даёт устаревшей повторной попытке перезаписать свежие данные.
Небольшой audit trail тоже полезен. Компактной таблицы import_events с source_id, event_id, source_updated_at, checksum и result обычно достаточно. Тогда, если запись 42 придёт три раза, команда сможет увидеть, импортировал ли её воркер, пропустил как устаревшую или повторил после сбоя.
Обрабатывайте частичные сбои и правила очистки
Повторная попытка становится рискованной, когда один шаг завершился, а следующий — нет. Разделяйте внешние побочные эффекты и локальные обновления намеренно. В платёжном воркере сначала вызовите платёжного провайдера, а потом запишите результат в базу с тем же idempotency key. Если воркер упадёт между этими шагами, не гадайте, что случилось.
Для идемпотентности фоновых задач в Python статус «unknown» — это нормальный статус. Используйте его, когда провайдер мог принять списание, но приложение не сохранило финальное состояние. Небольшая задача восстановления позже может спросить у провайдера статус списания и обновить записи без повторного списания.
Неопределённость лучше ошибочной уверенности
Ложная уверенность приносит больше вреда, чем временное состояние unknown. Если запрос на списание мог выйти из вашей системы, сохраните строку и пометьте её как unknown. Если задача синхронизации могла отправить запись клиента, но не успела сохранить внешний ID, пометьте эту запись на повторную проверку вместо того, чтобы создавать новую на следующей попытке.
Заполнители помогают воркерам избежать двойной работы, но удаляйте их только если внешнего действия не было. Если воркер упал до отправки API-запроса, вы можете безопасно удалить placeholder и повторить попытку. Если API-запрос мог уйти, оставьте placeholder, сохраните состояние задачи и дайте логике восстановления закончить историю.
Очистка должна быть небольшой
Широкие скрипты очистки создают новые проблемы. Делайте каждый скрипт узким, простым для тестирования и простым для отката, если он затронул не те строки.
Хорошая задача восстановления обычно делает только несколько вещей:
- фильтрует по типу задачи и небольшому временному окну
- перепроверяет неизвестные состояния во внешней системе
- обновляет по одному полю статуса за раз
- пишет audit log с ключом задачи, старым состоянием, новым состоянием и причиной
То же правило подходит и для синхронизации. Если импорт остановился после 320 записей, сначала восстановите те строки, в которых есть неопределённость. Не нужно стирать весь пакет и запускать всё заново. Очистка должна закрывать пробелы, а не создавать новые дубли.
Ошибки, которые ломают идемпотентность
Большинство багов с идемпотентностью возникают из-за маленьких решений, которые кажутся безобидными при обычном запуске. Они проявляются позже — когда воркер падает, таймаут скрывает успех или повторная попытка приходит через несколько часов после первой.
Одна типичная ошибка в платежах проста: повторная попытка создаёт новый idempotency key. Воркер думает, что повторяет то же списание, а провайдер видит совершенно новый запрос. Если первый запрос на самом деле сработал, клиент получает двойное списание.
Другая ошибка возникает ещё раньше. Команды вызывают платёжного провайдера или сторонний API до того, как сохраняют состояние задачи в общем хранилище. Если процесс умирает после внешнего вызова, но до сохранения, следующий воркер не знает, что произошло, и делает действие ещё раз.
Именно эти паттерны чаще всего создают ущерб:
- Повторная попытка создаёт новый idempotency key вместо того, чтобы использовать исходный.
- Задача отправляет внешний запрос до того, как запишет состояние «started» или «in progress».
- Команда хранит данные для дедупликации только в кэше, хотя повторы могут случиться через дни.
- Воркер считает любой таймаут проваленной операцией и повторяет попытку, не проверив сначала провайдера.
- Очистка удаляет старые строки идемпотентности до окончания окна повторных попыток и окна сверки.
Отслеживать всё только в кэше опасно для длинных окон повторных попыток. Redis может помочь со скоростью, но он не должен быть единственным источником истины для платежа или синхронизации, которые могут повториться после задержки очереди, деплоя или сбоя на выходных. Держите надёжную запись в базе, которую сможет прочитать каждый воркер.
С таймаутами нужно быть особенно аккуратными. Таймаут означает «вы не знаете», а не «это не сработало». Для платежей сначала спросите провайдера о статусе, используя тот же idempotency key или тот же внешний reference, прежде чем повторять попытку. Для задач синхронизации сначала проверьте, существует ли целевая запись, прежде чем писать её снова.
Очистка тоже может сломать хорошую работу. Если удалять строки идемпотентности через 24 часа, а некоторые повторы приходят через 72, вы снова открываете дверь для дублей. Храните строки достаточно долго, чтобы покрыть задержки очереди, задержки провайдера, ручные перезапуски, а также проверки по возвратам платежей или аудиту. Обычно дешевле хранить данные, чем потом разбирать двойное списание.
Быстрые проверки перед релизом
Задача не становится идемпотентной просто потому, что код выглядит аккуратно. Она идемпотентна тогда, когда вы можете специально сломать её и всё равно получить один чистый результат.
Перед релизом прогоните несколько неприятных тестов. Они находят ошибки, которые обычные happy-path тесты пропускают, особенно в платежах и синхронизации.
- Запустите одну и ту же задачу дважды одновременно с одним и тем же id. Один воркер должен захватить её, а второй — увидеть существующую запись и остановиться. Если проходят оба, ваша блокировка, уникальное ограничение или шаг захвата слишком слабые.
- Уроните воркер после внешнего действия, но до финальной записи в базу. Потом запустите задачу снова. В итоге всё равно должно быть одно списание, одно письмо или один импортированный набор записей, а не два.
- Проверьте, что видит поддержка. Сотрудники должны находить задачу по клиенту, заказу или reference провайдера и видеть простой статус вроде pending, done, failed или needs review.
- Проверьте путь восстановления для неизвестных состояний. Если воркер умирает после отправки платёжного запроса, ваша команда должна суметь запустить задачу восстановления, которая спросит у провайдера, что произошло, и обновит запись без ручного SQL.
Небольшой административный экран важнее, чем думают многие команды. Когда клиент говорит: «Кажется, у меня списали деньги дважды», поддержке нужны не сырые логи. Им нужен job ID, request ID, внешний reference, последняя ошибка и время последней повторной попытки.
Правила восстановления тоже должны быть узкими и скучными. Например, если платёжная запись всё ещё pending через 15 минут, запросите статус у платёжного провайдера, сохраните финальный статус и закройте задачу. Если задача синхронизации импортировала 80 из 100 строк до сбоя, повторный запуск должен пропустить 80 уже отмеченных как done строк и завершить последние 20.
Если эти тесты проходят, повторные попытки перестают казаться рискованными. Они становятся обычной частью процесса.
Что сделать на этой неделе
Начните с одной задачи, которая может стоить денег или испортить данные, если выполнится дважды. Хороший первый кандидат — задача списания платежа. Ещё один сильный вариант — синхронизация, которая импортирует клиентов, счета или подписки из другой системы. Выберите реальную задачу, которая уже повторяется под нагрузкой, а не чистый демонстрационный пример.
Первый проход оставьте простым и практичным:
- Добавьте таблицу идемпотентности, которую сможет проверять каждый воркер.
- Поставьте уникальное ограничение на idempotency key.
- Принудительно уроните процесс после внешнего вызова и до локального сохранения.
- Напишите одну задачу восстановления для случаев, которые заканчиваются в неопределённом состоянии.
Этот небольшой набор изменений ловит сбои, которые команды обычно пропускают. Тест на падение важнее всего. Многие ошибки прячутся в крошечном промежутке между «провайдер принял запрос» и «приложение сохранило результат». Если ваш воркер умирает в этом промежутке, нужен понятный способ восстановиться без двойного списания или повторного импорта той же записи.
Храните состояние скучным. Сохраняйте idempotency key, текущий статус, ID запроса провайдера, если он есть, последнюю ошибку и временные метки. Этого достаточно для большинства Python-воркеров. Вам не нужна огромная платформа, чтобы сделать это правильно.
Задача восстановления должна отвечать на один вопрос: что на самом деле произошло? Для платёжной задачи она может спросить у провайдера, существует ли списание, а потом пометить локальную запись как paid или failed. Для задачи синхронизации она может перепроверить, какие записи уже дошли, и завершить только недостающие записи.
Если вам нужна вторая точка зрения на дизайн Python-задач, повторные попытки или правила очистки, Oleg Sotnikov занимается такой работой в формате Fractional CTO. Короткий разбор может найти слабые места до того, как они превратятся в возвраты, дубли или ночную чистку.


