gRPC REST translation: где помогает и где вредит
Узнайте, когда gRPC REST translation действительно полезен, где gateway добавляет риски и как не дать формам ошибок и статус-кодам расходиться.
Содержание
Почему команды совмещают gRPC и REST
Большинство команд не выбирают между gRPC и REST в вакууме. Они работают сразу с двумя разными аудиториями. Внутри системы разработчикам важны скорость, строгие контракты и меньше неожиданностей. На границе браузеры, мобильные приложения, партнёры и простые скрипты обычно ожидают JSON по обычному HTTP.
Такое разделение логично. Внутренние сервисы часто предпочитают gRPC, потому что контракт там типизирован, клиентский код можно генерировать, а запросы остаются единообразными между командами. Меньше догадок о названиях полей, типах данных и форме запроса.
Внешние клиенты живут в другом мире. Браузер не разговаривает с gRPC так же, как серверный сервис. Многие внешние клиенты тоже ожидают привычное поведение REST: простые эндпоинты, HTTP-статусы и JSON-тела, которые можно посмотреть без специальных инструментов.
Поэтому команды ставят посередине слой перевода. На границе принимаются REST-запросы, а затем они скрыто преобразуются в gRPC-методы. Это может быть API gateway, proxy или собственный backend-код. Именно поэтому gRPC REST translation так часто встречается в реальных продуктах.
Если всё сделано хорошо, такое разделение удобно. Небольшая компания может сохранить чистый внутренний контракт сервисов и при этом дать клиентам API, которым можно пользоваться сразу. Внутренняя команда получает строгую типизацию. Внешние пользователи — привычный интерфейс.
Проблемы начинаются тогда, когда слой на границе не только переводит формат. Если он меняет названия, скрывает поля, переписывает ошибки или превращает одно действие бэкенда в другой смысл на публике, система начинает расходиться.
Тогда REST edge API перестаёт быть тонким адаптером и становится вторым продуктом, который нужно поддерживать. Именно здесь команды и попадают в ловушку. Один сервис возвращает понятную gRPC-ошибку, а граница превращает её в общий 500. Отсутствующее поле становится пустой строкой, потому что маппер подставил значение по умолчанию. Таймаут в одном месте выглядит как ошибка валидации в другом. Клиенты быстро перестают доверять системе, когда одинаковый сбой выглядит по-разному в зависимости от маршрута.
Совмещать gRPC и REST — нормально. Опасно другое: позволять слою перевода придумывать собственное поведение.
Что на самом деле делает слой перевода
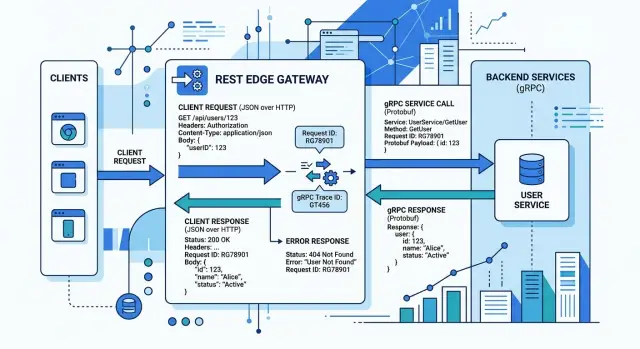
Большинство людей воспринимают edge как конвертер форматов. На деле он делает больше. В gRPC REST translation этот слой принимает HTTP-запрос, сопоставляет его с маршрутом и превращает в конкретный вызов gRPC-метода с нужным request message.
Маршрут вроде POST /v1/orders/123/cancel?reason=duplicate может стать OrderService.CancelOrder. Значение пути 123, значение query duplicate, JSON-тело и заголовки вроде Authorization или X-Request-Id должны получить понятное место в gRPC-запросе или metadata. Используете ли вы API gateway mapping или небольшой собственный proxy, задача остаётся той же.
Этот слой также берёт на себя edge-задачи, которые не должны жить внутри бизнес-логики. Он может проверять auth, применять лимиты, добавлять request ID и писать логи ещё до того, как запрос попадёт в сервис.
Преобразование ошибок — место, где многие команды начинают халтурить. gRPC-сервис может вернуть NOT_FOUND, INVALID_ARGUMENT или FAILED_PRECONDITION со структурированными деталями о полях, лимитах или подсказках для retry. REST edge API должен превратить это в HTTP-статус и стабильную JSON-форму ошибки.
Если один эндпоинт возвращает 404 с code и message, а другой — 400 с обычной строкой, клиенты начинают писать исключения для каждого случая. Так и начинается дрейф. Бэкенд по-прежнему работает одним образом, но edge рассказывает другую историю.
Здоровый слой перевода держит два обещания. Во-первых, он не придумывает бизнес-правила. Если клиент не может отменить уже оплаченную счёт-фактуру, это должен решать сервис. Во-вторых, он сохраняет смысл. Если бэкенд говорит, что поле некорректно, клиент должен получить тот же смысл после status code mapping, а не расплывчатый bad request.
Именно поэтому этот слой выглядит маленьким на схеме, но затрагивает почти каждый запрос. Если он остаётся тонким и последовательным, команда получает пользу от gRPC внутри и простой HTTP-срез снаружи без кучи исключений для каждого случая.
Где слои перевода помогают
Слой перевода полезен тогда, когда у публичного API одна задача, а у внутренних сервисов — другая. Веб-приложения, мобильные приложения, партнёрские интеграции и простые скрипты обычно хотят обычный HTTP и JSON. А команда бэкенда может по-прежнему предпочитать gRPC, потому что protobuf строгий, быстрый и проще поддерживать единообразным внутри системы.
Такое разделение часто очень практично. gRPC REST translation позволяет клиентским командам использовать привычные формы запросов и ответов, не заставляя их разбираться с файлами protobuf, сгенерированными клиентами или деталями HTTP/2. Для многих продуктов это сразу снижает трение.
Кроме того, вы получаете чёткую границу вокруг внутренней части системы. Внешним клиентам не нужно знать, что эндпоинт ведёт в UserService, BillingService или в три более мелких сервиса за gateway. Им не нужно знать номера портов, правила service discovery или то, как запросы проходят по сети. Позже вы сможете переименовать, разделить или переместить внутренние сервисы и оставить edge API стабильным.
Это особенно важно, когда команды двигаются с разной скоростью. Backend-инженеры могут сохранять protobuf-контракты между сервисами и развивать их для внутреннего использования. Frontend- и mobile-команды могут продолжать работать с REST edge API, который меняется реже. Обе стороны получают интерфейс, подходящий под их работу.
Gateway также — хорошее место для того, чтобы один раз применить общие правила вместо повторения их в каждом сервисе. Частые примеры:
- проверка токенов авторизации до того, как запрос попадёт в приватные сервисы
- ограничение частоты для публичного трафика
- добавление request ID для трассировки
- блокировка или сглаживание трафика во время пиков
Вот где API gateway mapping действительно окупается. Один слой может последовательно переводить пути, методы, заголовки и payload'ы.
Простой пример всё проясняет. Мобильное приложение отправляет POST /orders с JSON. Gateway проверяет пользователя, добавляет внутренние метаданные и маппит этот запрос в CreateOrder на gRPC-сервисе. Если позже бэкенд разделит заказную логику на два сервиса, приложению может вообще не понадобиться менять код.
В таком использовании слой перевода работает как буфер. Он сохраняет простоту публичной стороны и даёт бэкенду пространство для изменений, не превращая каждый внутренний рефакторинг в обновление клиента.
Где слои перевода вредят
Слой перевода добавляет ещё один подвижный элемент между клиентом и сервисом. На диаграмме это выглядит мелочью. На практике это ещё одно место, где API может начать расходиться.
У gRPC-метода есть чёткий контракт в protobuf. У REST edge API часто есть собственные JSON-формы, правила статус-кодов, названия полей и тексты ошибок. Если команда обновляет одну сторону и забывает про другую, у клиентов начинается странное поведение. Поле может существовать в gRPC, но так и не появиться в JSON. Обязательное значение может стать необязательным на gateway. Даже мелкие изменения названий, например когда user_id превращается в userId, могут создавать баги, которые никто не замечает, пока не ломается мобильное приложение.
Задержка тоже растёт, даже если каждый шаг сам по себе кажется быстрым. Gateway должен принять HTTP, распарсить JSON, преобразовать его в protobuf, отправить gRPC-вызов, получить ответ, конвертировать его обратно в JSON и записать финальный статус-код. Каждый этап добавляет работу. Один запрос может отнять всего несколько лишних миллисекунд, но под нагрузкой эти мелкие затраты складываются.
С ошибками всё обычно ломается раньше всего. gRPC может вернуть структурированные детали, например какое поле не прошло валидацию или столкнулся ли вызывающий с ограничением по частоте. Плоская JSON-обёртка часто сводит это к чему-то вроде {\"error\":\"bad request\"} с обычным 400. Клиент теряет детали, support — контекст, а разработчики начинают гадать.
Потеря деталей мешает и отладке. Если логи обрываются на gateway, команда видит REST-запрос и финальный сбой, но не весь путь между ними. Может быть непонятно, ошибка в payload клиента, в правиле маппинга, в backend-сервисе или в преобразовании статус-кода. Простая ошибка валидации может занять час, потому что gateway скрыл исходный gRPC-статус и metadata запроса.
Типичный пример — форма регистрации. Бэкенд возвращает INVALID_ARGUMENT с деталями по полям email и password. Gateway превращает это в общий 400 с одной строкой сообщения. Веб-приложение больше не может подсветить конкретные поля, а support видит в логах только «signup failed».
Вот главная цена gRPC REST translation: больше совместимости на границе, но и больше шансов на дрейф, более медленные запросы, бедные ошибки и более сложную работу во время инцидентов.
Простой пример
Мобильное приложение обращается к REST edge API, потому что телефоны, браузеры и сторонние клиенты обычно лучше работают с обычным HTTP и JSON. Приложение отправляет POST /orders, чтобы оформить заказ, и POST /payments, чтобы списать деньги с карты. За edge gateway эти два маршрута вызывают разные gRPC-сервисы.
/orders идёт в OrdersService.CreateOrder. /payments идёт в PaymentsService.Charge. В обычный день такое разделение выглядит чисто. Клиент получает REST, бэкенд — быстрые service-to-service вызовы, а слой gRPC REST translation почти не мешает.
Проблемы начинаются, когда оба пути сталкиваются с одной и той же неполадкой, но сообщают о ней по-разному.
Представим, что платёжный провайдер стал отвечать медленно. Маршрут заказов ждёт ответ от платежного сервиса через gateway, достигает таймаута, и gateway возвращает 504 Gateway Timeout. Тело ответа выглядит так:
{
"error": "gateway_timeout",
"message": "upstream service did not respond in time"
}
А через несколько секунд мобильное приложение напрямую вызывает /payments. Запрос доходит до платежного gRPC-сервиса, который сталкивается с тем же медленным вызовом провайдера, оборачивает его как внутреннюю ошибку сервера и отправляет обратно через другое правило маппинга. Клиент получает 500 с другим телом:
{
"code": "internal_error",
"details": "payment processor timeout"
}
Теперь support видит два тикета на один и тот же сбой. Один клиент говорит, что приложение показало timeout. Другой — что сервер упал. Команда ищет в логах два имени ошибок, два статус-кода и две формы тела ответа. Сам баг не стал сложнее, но разбирать последствия теперь тяжелее.
Именно здесь слои перевода и вредят. Они могут скрывать детали бэкенда, но также могут создавать новые различия в зависимости от маршрута. Если один таймаут превращается в 504, а другой — в 500, люди перестают доверять API. Клиенты начинают писать исправления под каждый маршрут, и дрейф быстро распространяется.
Лучше, когда публичный API использует одну форму ошибки и одно правило маппинга для таймаутов, независимо от того, какой gRPC-сервис сломался.
Как удержать один контракт ошибок
Клиентам всё равно, начался сбой в gRPC или на REST-границе. Им важно, чтобы ошибка каждый раз выглядела одинаково. Если один путь возвращает INVALID_ARGUMENT, а другой — расплывчатый 400 с другим телом, поддержка усложняется, а клиентский код быстро становится неаккуратным.
Начните с небольшого набора кодов ошибок, которым можно доверять. Сохраняйте их стабильными. Большинству команд хватает нескольких значений: validation_error, not_found, auth_required, permission_denied, rate_limited, conflict, internal_error и service_unavailable. Этого достаточно для понятного поведения клиента без лишних деталей о внутреннем устройстве.
Сопоставляйте gRPC-статусы с HTTP-статусами осознанно, а не случайно. Выберите по одному HTTP-статусу для каждого gRPC-статуса и зафиксируйте это один раз. Часто используют такую схему:
INVALID_ARGUMENT->400UNAUTHENTICATED->401PERMISSION_DENIED->403NOT_FOUND->404RESOURCE_EXHAUSTED->429INTERNAL->500UNAVAILABLE->503DEADLINE_EXCEEDED->504
Тело ответа тоже должно оставаться стабильным. Возвращайте одни и те же поля всегда, даже когда бэкенд ломается по-новому. Для большинства случаев хорошо работают четыре поля: code, message, request_id и details.
{
"code": "validation_error",
"message": "email is invalid",
"request_id": "req_9f2c1",
"details": {
"field": "email"
}
}
request_id реально экономит время в продакшене. Клиент может передать одну строку в support, и ваша команда найдёт нужные логи за секунды.
Не пишите один и тот же маппинг вручную в трёх местах. Так и начинается дрейф. Лучше держать один источник истины, а из него генерировать правила gateway, общие константы и документацию. Для многих команд таким источником становится enum в protobuf плюс небольшая таблица маппинга в том же репозитории, что и сервис.
CI должен прогонять один и тот же сбой через оба пути. Отправьте один плохой запрос по gRPC, отправьте эквивалентный REST-запрос через gateway и сравните результат. Транспорт может отличаться. Контракт — нет. Проверяйте код приложения, HTTP-статус и поля ответа в одном и том же тесте.
Если клиентская команда может обрабатывать ошибки через один простой switch, значит с контрактом всё в порядке. Если ей нужны transport-specific исключения, контракт уже начал расходиться.
Частые ошибки, которые вызывают дрейф
Дрейф начинается незаметно. Одна команда добавляет новое имя ошибки, другой маршрут возвращает другую JSON-форму, а gateway маппит один и тот же сбой бэкенда в два HTTP-статуса. Через месяц клиенты перестают доверять API, потому что одна и та же проблема выглядит по-разному в зависимости от пути.
Чаще всего причина — решения на местах. Каждая команда сервиса пытается сделать ошибки «понятнее» для своего эндпоинта, но в целом системе пользоваться становится сложнее. В gRPC REST translation это обычно проявляется в четырёх местах:
- сервисы придумывают собственные коды ошибок и названия для одного и того же сбоя
- одни маршруты пропускают сырые gRPC-сообщения, а другие оборачивают их в custom JSON
- команды по-разному маппят HTTP-статусы, не проверяя, как уже работают веб- или мобильные клиенты
- документация меняется вручную после того, как поведение уже изменилось в коде
Первая проблема распространяется очень быстро. Один сервис возвращает USER_NOT_FOUND, другой — ACCOUNT_MISSING, а третий пишет 404_entity_absent. Все три варианта означают одно и то же. Теперь клиентам нужны отдельные исключения, а support-командам — шпаргалка, чтобы просто читать логи.
Смешанные формы ошибок ничуть не лучше. Если один маршрут REST edge API возвращает { "error": "timeout" }, а другой показывает сырой gRPC-текст, клиенты не могут стабильно парсить сбои. Им приходится сравнивать строки, а строковое сравнение всегда ломается. Сохраняйте публичную форму неизменной, даже когда внутренние сервисы меняются.
Дрейф HTTP-статусов наносит тихий ущерб. Команда может поменять таймаут с 503 на 500, потому что так «выглядит правильнее». Код при этом продолжит собираться, но поведение клиента изменится. Мобильное приложение может делать retry на 503 и перестать retry'ить на 500. Из-за этого временная проблема бэкенда превращается в пользовательский сбой.
Документация расходится быстрее кода
Ручная правка документации почти всегда отстаёт. Кто-то меняет маппинг gateway, забывает про docs, и в итоге документация обещает одно, а продакшен ведёт себя по-другому. Этот разрыв тратит время в QA, support и фронтенде.
Лучшее правило простое: генерируйте как можно больше контракта из одного источника истины. Если ваш protobuf, конфиг gateway и опубликованная схема ошибок не идут из одного места, дрейф — это не риск. Это настройка по умолчанию.
Команды, которые живут с компактной инфраструктурой, быстро это понимают. Oleg Sotnikov часто подталкивает компании к одному контракту, одной таблице маппинга и одному набору тестов вокруг него. Это менее эффектно, чем добавлять новые правила gateway, но сильно экономит переделки.
Если клиентам нужен стабильный API, воспринимайте форму ошибки, маппинг статусов и документацию как единое целое. Меняйте их вместе или не меняйте вовсе.
Что проверить перед запуском
Перед тем как выпускать gRPC REST translation, тестируйте не happy path, который и так работает, а те сбои, с которыми люди столкнутся в первый день. Успешный create-запрос мало что говорит. Неверный токен, отсутствующая запись или медленный upstream-под запрос покажут, ощущается ли REST edge API последовательным или запутанным.
Сравните одни и те же сбои на обеих сторонах
Возьмите четыре случая и прогоните каждый через gRPC и через REST edge API: сбой авторизации, ошибка валидации, таймаут и not found. Для каждого случая сравните HTTP-статус, gRPC-статус, внутренний код ошибки, текст сообщения и любые детали на уровне поля. Если REST-ответ говорит 404, а сервис возвращает invalid argument, ваш API gateway mapping уже начал расходиться.
Проверку держите простой и повторяемой:
- Auth: просроченный токен, отсутствующий токен, неверная scope
- Validation: обязательное поле отсутствует, неверный формат
- Timeout: медленный upstream-вызов, deadline exceeded
- Not found: неверный ID, удалённая запись
Короткой тестовой таблицы достаточно. Вам нужно, чтобы оба интерфейса отвечали на один и тот же вопрос одинаково: что сломалось, почему это сломалось и что должен сделать вызывающий дальше.
Каждая ошибка должна содержать request ID. Поместите его в заголовки и в тело ответа, если ваш формат это позволяет. Когда клиент присылает скриншот или фрагмент лога, этот ID помогает вашей команде быстро отследить запрос через gateway и gRPC-сервис.
Измеряйте оба слоя
Одной цифры задержки недостаточно. Отслеживайте latency gateway и latency сервиса отдельно, иначе вы будете обвинять не тот слой. Gateway может добавлять 30–50 мс из-за проверки авторизации, маппинга JSON и retries, даже если бэкенд работает быстро. Бывает и наоборот: edge выглядит медленным только потому, что сервис ждёт базу данных.
Если вы уже используете Grafana, Prometheus или Sentry, разделяйте дашборды на edge и backend. Так после релиза проще заметить регрессии.
Не запускайте систему, пока ваша команда не сможет ответить на три простых вопроса по любому упавшему запросу: какой слой его отклонил, какую форму ошибки увидел клиент и какой request ID связывает весь путь вместе.
Что делать дальше
Не переводите весь бэкенд сразу. Выберите один эндпоинт, которым реальные пользователи часто пользуются, аккуратно смэппьте его и посмотрите, как он ведёт себя в продакшене. Один маршрут быстро покажет большую часть проблем: отсутствующие поля, странный status code mapping и сообщения об ошибках, которые понятны backend-инженерам, но путают клиентские приложения.
Делайте публичный REST edge API меньше, чем внутренний gRPC API. Внутренние сервисы могут оставаться детальными и быстрыми. Публичные эндпоинты должны быть стабильными, простыми и удобными для документации. Если ваш gRPC-сервис имеет десять методов, на границе REST вам могут понадобиться только три маршрута.
Хороший запуск обычно выглядит так:
- Выберите один эндпоинт с понятными входными данными и небольшим ответом.
- Зафиксируйте REST-запрос, REST-ответ и все формы ошибок, которые вы допускаете.
- Сравните реальные клиентские сбои с вашим маппингом, а не только с тестами на happy path.
- Исправьте названия, статус-коды и тела ошибок до того, как добавлять новые маршруты.
Именно здесь многие команды торопятся. Они добавляют пять или десять маппингов, а потом неделями расчищают дрейф. Дешевле замедлиться в начале. Если мобильные клиенты видят 404 для одной отсутствующей записи, 400 для того же случая на другом маршруте и сырой gRPC-сообщение на третьем, доверие быстро падает.
Относитесь к разбору ошибок как к части дизайна, а не как к уборке. Сохраняйте примеры из логов, тикетов поддержки и клиентских тестовых прогонов. Затем смотрите на них рядом. Если два маршрута описывают одну и ту же проблему по-разному, объедините их сейчас. Такая дисциплина важнее, чем сложная конфигурация gateway.
Если вашей команде нужен второй взгляд, Oleg Sotnikov может помочь как Fractional CTO с дизайном API, инфраструктурой и практическими AI-first workflow для разработки. Такой внешний разбор часто особенно полезен, когда gRPC REST translation начинается с малого, но уже готов распространиться на весь продукт.


