GraphQL в TypeScript-бэкендах после лёгких побед
GraphQL в TypeScript-бэкендах поначалу работает быстро, а потом владение схемой, N+1-исправления и проверки прав начинают съедать время команды.
Содержание
Почему GraphQL сначала работает быстро, а потом начинает тормозить
GraphQL в TypeScript-бэкендах поначалу часто кажется очень удобным. Одна команда владеет одной схемой, продукт ещё небольшой, и те же несколько человек могут за один проход менять типы, резолверы и клиентские запросы.
Этот первый рывок действительно ощущается. Фронтенд-разработчик просит добавить поле, backend-разработчик его добавляет, а компилятор ловит очевидные ошибки типов ещё до релиза. Всё выглядит аккуратно, предсказуемо и достаточно быстро, чтобы никто не переживал о следующих 50 полях.
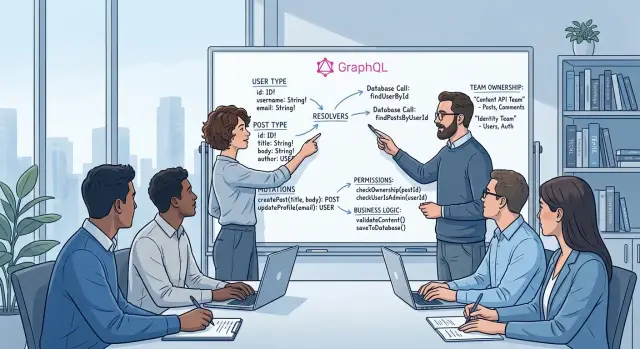
Настроение меняется, когда граф перестаёт быть картой одной команды и превращается в общее пространство для нескольких продуктовых направлений. Биллинг, админка, онбординг, поддержка и отчёты — всем хочется добавить свои поля в одни и те же типы. Простой объект User или Account начинает тащить в себя данные, которые действительно нужны только одному экрану или одной команде.
Количество резолверов растёт быстрее, чем ожидает большинство команд. Каждое поле по отдельности выглядит недорого, но вместе с ним появляются логика загрузки, обработка null, тесты, крайние случаи и ещё какое-нибудь правило о том, кто это поле вообще может видеть. Через некоторое время изменение, которое казалось делом на 10 минут, затрагивает пять файлов и требует трёх ревьюеров.
Мелкие правила авторизации накапливаются так же. Одна проверка живёт в резолвере, другая — в сервисе, а третья спрятана в хелпере, который кто-то скопировал из старой фичи. Поле может зависеть от роли, тарифа, региона, состояния аккаунта или внутреннего флага, и эти правила очень быстро перестают совпадать.
Именно здесь скорость падает. Обычно проблема не в самом GraphQL. Проблема в том, что граф очень легко позволяет добавить ещё одно поле, ещё один резолвер и ещё одно исключение, пока бэкенд не начинает вести себя как переполненный шкаф. Всё по-прежнему помещается, но находить нужное становится всё сложнее с каждым месяцем.
Команды чувствуют это замедление ещё до измерений. Ревью идут дольше, поиск багов занимает больше времени, и люди перестают верить, что общий тип действительно означает один понятный источник правды.
Когда владение схемой превращается во внутреннее трение
Команды, которые строят GraphQL в TypeScript-бэкендах, часто начинают с одной общей схемы, потому что это кажется аккуратным решением. Один граф, один источник правды, одно место для новых полей. Некоторое время это работает. Потом схема перестаёт показывать ответственность и начинает её скрывать.
Тип User — частый пример. Продукт добавляет поля для онбординга. Биллинг добавляет статус счетов. Поддержка добавляет флаги для состояния аккаунта. В итоге три команды редактируют один и тот же тип по разным причинам. Никто не хочет сломать работу другой команды, поэтому каждое изменение получает больше ревью, чем нужно. Небольшие правки застревают в pull request, потому что никто не чувствует себя уверенно, утверждая всю форму целиком.
Общие input-типы создают похожий хаос. Команда переиспользует UpdateUserInput, потому что он уже есть. Другая команда добавляет в него поля для другого сценария. Через несколько месяцев один объект input управляет настройками профиля, продажными предпочтениями и изменениями только для админов. Эти функции не должны были быть вместе, но схема теперь утверждает обратное. Распутать это позже будет сложнее, чем создать новый input-тип с самого начала.
Названия полей тоже начинают нести в себе продуктовые решения, которые никто не записывал. Поле с названием status для одной команды может означать состояние триала, для другой — состояние биллинга, а для поддержки — риск-профиль. Код компилируется. Схема по-прежнему выглядит аккуратной. Но каждому новому инженеру приходится учить скрытый смысл через ревью, переписки в Slack и баги в продакшене.
Обычно вместе появляются несколько признаков:
- один и тот же тип всплывает во многих бэклогах команд
- на ревью приходят люди из несвязанных областей
- одно переименование поля превращается в спор о продукте
- общие input-типы на каждом спринте обрастают необязательными полями
- изменения в резолверах требуют одобрения от людей, которые не владеют фичей
Это не столько проблема GraphQL, сколько проблема неясных границ продукта. Схема всё равно отражает структуру организации, даже если команды это не признают. Если никто не владеет типом от формы API до бизнес-правил, трение будет только расти. Более спокойная схема даёт каждой области понятного владельца, даже если всё по-прежнему проходит через один endpoint.
Как N+1 проявляется в обычной продуктовой работе
В GraphQL в TypeScript-бэкендах эта проблема редко начинается с огромного запроса. Обычно всё стартует с обычной продуктовой задачи. Кто-то добавляет список, счётчик в сайдбаре или ещё одно вложенное поле для дашборда — и сервер внезапно начинает делать гораздо больше работы, чем подразумевает экран.
Частый пример — таблица на 40 или 50 строк. Первый запрос быстро получает сами строки. Затем в каждой строке нужно узнать владельца аккаунта, текущий тариф, последний счёт и сводку по использованию. Если каждый резолвер делает свой отдельный запрос, один просмотр страницы может запустить десятки или даже сотни лишних обращений.
Вложенные поля только ухудшают ситуацию. В списке клиентов могут быть проекты, у каждого проекта — количество участников, а у каждого участника — проверка роли. Браузер по-прежнему отправил один GraphQL-запрос, но бэкенд мог превратить его в цепочку повторяющихся обращений к базе данных.
Команды часто добавляют loaders и думают, что проблема решена. Loaders действительно помогают, когда много резолверов в рамках одного запроса получают один и тот же объект по одному и тому же ID. Но они помогают гораздо меньше, если реальные сценарии используют разные фильтры, смешанные ключи или нестандартные join-ы. В таком случае loader скрывает шум, но не исправляет саму форму запроса.
Кэш может отложить боль. Тёплый кэш делает страницу нормальной в staging или в тихие часы. Потом трафик растёт, промахов по кэшу становится больше, и база данных внезапно выполняет весь объём работы. Поэтому баги N+1 часто проявляются поздно — уже после того, как фича кажется стабильной.
Что логировать
Логи резолверов быстро делают это видимым. Для начала не нужно ничего сложного. Отслеживайте для каждого запроса несколько чисел:
- какие резолверы запускались
- сколько раз запускался каждый резолвер
- общее число обращений к базе данных
- сколько времени занял каждый резолвер
Через день-два закономерности обычно становятся очевидны. Одно поле, которое выглядело безобидным, может запускаться 80 раз на одной странице. В этот момент лучше перестать латать отдельные резолверы и переписать выборку данных под то, как экран реально загружается.
Почему проверки прав расползаются и расходятся
Логика прав доступа обычно начинается с малого. Команда добавляет одну проверку в резолвер, другую — в сервис, а третью — в SQL, потому что так кажется безопаснее. Через шесть месяцев уже никто не может уверенно сказать, какой именно слой решает, кому что можно видеть.
Это особенно дорого в GraphQL в TypeScript-бэкендах, потому что один запрос может пройти сразу по многим путям. Резолвер верхнего уровня может заблокировать доступ к аккаунту, но вложенное поле всё равно способно утечь с суммами счетов, внутренними заметками или email-адресами пользователей, если одна ветка обходит то же правило.
Частый паттерн сначала выглядит безобидно. Резолвер проверяет: «этот пользователь менеджер?» Потом сервис проверяет: «этот пользователь принадлежит этому workspace?» Затем отдельное SQL-условие скрывает архивные строки. Каждое правило само по себе разумно. Вместе они создают лабиринт, и два разработчика прочтут этот лабиринт по-разному.
Соберите правила в одном месте
Правила для полей и правила для строк не должны жить где попало.
Выберите одно место для каждого типа проверок. Например:
- храните доступ к строкам в слое данных, где каждый запрос к заказам, пользователям или счетам применяет один и тот же фильтр по tenant и роли
- храните доступ к полям в одном policy-модуле, чтобы резолверы каждый раз задавали один и тот же вопрос
- держите резолверы тонкими и пусть они вызывают policy-код, а не пересоздают правила заново
- ограничьте число исключений и отдельно запишите те, что всё же остаются
В моменте это менее гибко, но позже экономит время. Когда отдел продаж просит новую роль для поддержки, которая может видеть статус биллинга, но не детали платежей, вы меняете одну policy, а не ищете правила по резолверам и хелперам.
Тесты здесь важнее, чем ожидают команды. Одного теста в духе «админ видит страницу» недостаточно. Нужны тесты на смену ролей, частичный доступ и вложенные поля. Если пользователь теряет доступ к проекту, API должен скрыть и сам проект, и все дочерние поля внутри него.
Исключения очень быстро множатся. У одного enterprise-клиента особое правило для экспорта. Одной внутренней команде нужен обходной путь для поддержки. Один старый запрос по-прежнему возвращает лишние поля, потому что на них завязан старый mobile app. В какой-то момент модель прав доступа перестаёт быть моделью и превращается в набор историй.
Если команда спорит о том, где должна жить проверка, это уже сигнал. Код подсказывает, что правила разъехались по слишком многим местам. Исправить это раньше намного дешевле, чем потом гоняться за очередным утекшим полем в продакшене.
Простой пример из растущего SaaS-приложения
Страница обзора клиента часто выглядит как небольшая фича. В растущем SaaS-приложении она может сразу показать все слабые места API.
Продукт хочет один экран, где агент поддержки видит аккаунт клиента, недавние счета, количество мест и активные алерты. В GraphQL это звучит удобно. Фронтенд отправляет один запрос, получает один ответ и идёт дальше.
Проблемы начинаются, когда в один и тот же тип Customer добавляются поля от четырёх команд. Биллинг владеет счетами. Команда identity владеет количеством мест. Операционная команда владеет алертами. Команда основного приложения владеет записью аккаунта. Каждая команда добавляет свой field resolver, и в отрыве от остального это выглядит разумно.
Поначалу никто не замечает цену. Небольшие тестовые аккаунты загружаются быстро. Локальные моки выглядят нормально. Типы TypeScript совпадают, а схема кажется чистой.
Потом эту страницу открывает крупный клиент. Данные аккаунта возвращаются быстро, но поле alerts вызывает другой сервис с медленным фильтром. Возможно, сначала забирается история алертов, а потом она режется, или выполняется один запрос на каждую настройку аккаунта. И вот одно вложенное поле занимает 1,5 секунды, а весь запрос ждёт его завершения.
GraphQL не волнует, что три части уже успели завершиться. Страница всё равно кажется медленной, потому что браузеру нужен полный ответ. Поддержка начинает видеть таймауты на этом же экране, обычно у самых важных клиентов — у них больше мест, больше счетов и больше правил для алертов.
Обсуждение в команде быстро становится хаотичным.
Фронтенд-команда говорит: «Это одна страница, значит, должен быть один запрос». Биллинг отвечает, что счета не самая медленная часть. Операционная команда говорит, что алерты принадлежат их сервису, поэтому им не нужно менять общую схему. Никто не владеет полной стоимостью запроса, хотя пользователи воспринимают это как одну проблему.
Это типичная точка перелома в GraphQL в TypeScript-бэкендах. Схема на бумаге по-прежнему выглядит опрятно, но ответственность уже разделена между командами с разными целями, ритмом релизов и привычками к производительности.
Страница обзора клиента выглядела как одна фича. В коде она превратилась в четыре отдельные системы, связанные одним именем типа. Обычно именно тогда скорость перестаёт быть главной темой, а координация становится более сложной задачей.
Как провести аудит бэкенда без большой переписки
Начните с трафика, а не со стиля кода. В GraphQL в TypeScript-бэкендах основная боль чаще всего приходит от небольшой группы запросов, которые выполняются весь день. Возьмите логи за неделю и отсортируйте операции по числу запросов, p95-латентности и частоте ошибок. Запрос, который немного медленный, но очень частый, нередко вреднее редкого worst-case сценария.
Потом разберите самые загруженные операции end to end. Проследите каждый резолвер до базы данных, кэша, очереди и внешних сервисов, к которым он обращается. Команды часто думают, что один запрос равен одному вызову сервиса. На практике запрос для дашборда может породить 20 SQL-операций, одну проверку биллинга, поиск feature flag и ещё две проверки прав в разных местах.
Для начала достаточно простого audit-листа:
- название операции и как часто её вызывают клиенты
- общее количество запросов к базе и самый медленный путь резолвера
- внешние сервисы, от которых она зависит
- где сейчас выполняются правила прав доступа
- кто владеет загруженными типами и резолверами
Ответственность важнее, чем многие команды ожидают. Если тип вроде User, Organization или Project встречается повсюду, одна команда должна решать, как он развивается. Когда никто не владеет загруженной частью схемы, поля накапливаются, исправления буксуют, а одна и та же логика копируется в новые резолверы.
Правила доступа тоже нуждаются в такой же чистке. Если одно правило живёт в резолвере, другое — в сервисе, а третье — в проверке на фронтенде, они обязательно разъедутся. Выберите один backend-слой для обычного контроля доступа и оставьте исключения редкими. Так баги легче находить, а ревью проходят гораздо быстрее.
Поставьте ограничения на дорогие запросы ещё до того, как начнёте вручную тюнить каждый резолвер. Задайте лимиты на глубину, общую сложность и стоимость полей. Запрос на id и name должен оставаться дешёвым. А вложенная цепочка через комментарии, авторов, команды и audit logs должна либо упереться в понятный лимит, либо пойти другим путём.
И, наконец, удалите поля, которыми никто не пользуется. Проверьте логи клиентских операций, код приложения или persisted queries и отметьте поля с нулевым использованием за разумный период. Старые поля выглядят безобидно, но именно они продолжают держать в живых код прав доступа, тесты и споры о схеме.
Один проход аудита не решит всё. Но он покажет, какие запросы заслуживают внимания, какие участки схемы нуждаются в владельце, а какие части API должны стать меньше, а не больше.
Ошибки, из-за которых боль остаётся надолго
Большинство команд не ломает GraphQL API одной большой ошибкой. Обычно это набор небольших сокращений, которые в первую неделю кажутся безобидными, а через полгода обходятся дорого. Такие проблемы часто появляются в GraphQL в TypeScript-бэкендах, потому что добавить ещё один резолвер кажется мелочью, пока вся система не начинает тянуться в разные стороны.
Одна из типичных ошибок — ждать жалоб пользователей, прежде чем чинить N+1-запросы. Один резолвер, который загружает пользователя, на ревью выглядит нормально. Потом тот же экран просит 30 пользователей, 30 команд и 30 записей о тарифах — и база данных получает удар. Если команда добавляет loaders только после того, как замедление уже дошло до продакшена, приходится латать горячие точки под давлением вместо того, чтобы заранее ввести правило batching.
Проверки авторизации расползаются не медленнее. Одна команда проверяет строку роли в резолвере. Другая проверяет состояние аккаунта в хелпере. Третья добавляет tenant-правила в middleware. В итоге получается грязно и ненадёжно. Два поля, которые выглядят одинаково, могут возвращать разные ответы одному и тому же человеку, и никто не уверен, какой из них верный.
Ещё одна ловушка — прятать бизнес-правила внутри GraphQL-типов и field resolvers. Поле вроде canEditInvoice может сначала быть вспомогательной штукой для интерфейса, а потом постепенно вобрать в себя лимиты тарифа, состояние платежа и права команды. В какой-то момент схема становится единственным местом, где вообще существует это правило. Задачи, админские скрипты и другие API не могут переиспользовать его без копирования логики.
Большие схемы тоже умеют вводить команды в заблуждение. Больше типов и больше полей может выглядеть как прогресс, но один размер ничего не доказывает. Иногда это лишь значит, что никто не удаляет старые поля, никто не объединяет дублирующие идеи, и каждая команда выпускает свою версию истины.
Внутренним инструментам ограничения тоже нужны. Команды часто пропускают проверки глубины или стоимости запросов, потому что этими экранами пользуются только сотрудники. Это ошибка. Внутренние пользователи задают неудобные вопросы, запускают широкие отчёты и вставляют гигантские запросы в дашборды. Один неконтролируемый admin-запрос может нанести больше вреда, чем публичный клиент.
Большая часть этой боли держится на месте, потому что исправления звучат скучно. Один дом для бизнес-правил, один способ batching для чтения, один общий слой авторизации и понятные лимиты запросов не выглядят эффектно. Но они действительно помогают бэкенду оставаться спокойным, когда продукт становится более нагруженным.
Быстрые проверки, прежде чем добавлять ещё поля
Схема GraphQL растёт по одному безопасно выглядящему полю за раз. Потом команда начинает видеть медленные страницы, странные баги с доступом и мелкие изменения, для которых нужны три человека на одобрение. Прежде чем добавлять ещё данные в запрос, остановитесь и проверьте форму, которая у вас уже есть.
Если вы работаете с GraphQL в TypeScript-бэкендах, начните с ответственности. Выберите верхнеуровневый тип вроде User, Account или Invoice. Кто-то в команде должен уметь сказать, кто им владеет, кто ревьюит изменения и кто решает, какие поля туда относятся. Если никто не знает ответа, этот тип уже стал общей свалкой.
Потом проверьте один реальный экран, а не синтетический нагрузочный тест. Списка клиентов на 25 строк уже достаточно. Если каждая строка вызывает ещё одну загрузку для планов, количества мест, тегов или активности, страница платит налог N+1 в обычной продуктовой работе. Именно тогда команды начинают добавлять loaders, кэши и разовые фиксы, из-за которых код становится труднее читать.
Проверки прав доступа нуждаются в той же проверке на прочность. Возьмите пользователя, у которого доступ есть сегодня, и уберите одно разрешение. Ваши тесты должны упасть понятным образом. Если страница частично рендерится, показывает неправильное число или скрывает данные без срабатывания теста, скорее всего, ваши auth-правила расползлись по резолверам и больше не совпадают друг с другом.
В медленных логах тоже должны быть названы резолверы, а не только маршрут. Лог вида «/graphql занял 1,8 с» — этого недостаточно. Нужно видеть, задержка пришла из organization.members, invoice.total или project.activityFeed. Это резко сокращает время на отладку.
Ещё одна проверка говорит очень о многом: уберите вложенное поле с загруженной страницы и перезагрузите её. Если страница ломается, значит, фронтенд зависит от побочных эффектов или скрытых предположений о форме запроса. Обычно это означает, что добавление ещё одного поля окажется дороже, чем кажется.
Эти проверки скучны специально. Они ловят те места, где схема перестаёт ощущаться простой и начинает начислять проценты на каждое новое поле.
Когда смешанное API работает лучше
GraphQL чаще всего лучше всего справляется с одной задачей: гибким чтением для экранов, которым нужны данные из нескольких мест сразу. Дашборд, страница поиска или админский экран действительно могут выиграть от одного запроса, который забирает ровно то, что нужно клиенту. Именно здесь GraphQL в TypeScript-бэкендах всё ещё выглядит чистым и оправдывает свой оверхед.
Проблемы начинаются, когда команды пытаются прогонять через одну и ту же схему вообще все backend-задачи. Стабильным операциям записи обычно не нужен этот дополнительный слой. Если создание счёта всегда требует одного и того же input и возвращает один и тот же результат, обычный service call или REST endpoint часто проще тестировать, проще защищать и проще менять без затрагивания лишних частей графа.
Смешанное API — это не компромисс. Часто это просто более честный дизайн.
Где GraphQL подходит лучше всего
Используйте GraphQL там, где клиент действительно выигрывает от выбора полей и объединения связанных данных. На практике это часто означает:
- клиентские дашборды
- страницы настроек аккаунта со связанными записями
- внутренние админские инструменты
- экраны поиска и фильтрации
Тяжёлая отчётность — отдельная история. Ежемесячные выгрузки, финансовые сводки и большие аналитические запросы могут замедлять интерактивный трафик, если проходят по тому же пути. Такие задачи обычно лучше работают через отдельные report endpoints, асинхронные задачи или предварительно рассчитанные таблицы. Пользователям всё равно, из GraphQL пришёл отчёт или нет. Им важно, чтобы страница оставалась быстрой, а цифры были правильными.
То же правило относится к фоновым задачам. Webhooks, sync workers, импорты и плановые очистки не становятся лучше только потому, что проходят через схему. Если силой загнать их в GraphQL, можно добавить код резолверов, ветки прав доступа и исправления N+1 там, где раньше они вообще не были нужны.
Хороший тест — время команды. Измерьте, сколько времени занимают обычные изменения. Если добавление одного поля означает правки типов схемы, резолверов, loaders, правил прав доступа и client fragments, то форма запроса — уже не единственная ваша стоимость. Следите за временем ревью, количеством багфиксов и тем, как часто разработчикам нужна помощь другой команды, чтобы выпустить маленькое изменение.
Если GraphQL хорошо справляется с гибким чтением, пусть делает именно это. Пусть стабильные записи остаются скучными. Пусть отчёты и backend-задачи идут своим путём. Такое разделение обычно снижает трение быстрее, чем очередная чистка схемы.
Что делать дальше, чтобы бэкенд стал спокойнее
Если команда чувствует, что с каждой новой полкой бэкенд становится медленнее, остановитесь на неделю и не добавляйте новые поля. Используйте это время, чтобы посмотреть, что уже болит. В GraphQL в TypeScript-бэкендах стоимость почти никогда не приходит из одной большой ошибки. Обычно это три маленькие проблемы, которые накапливаются: неясное владение схемой, лоскутная загрузка данных и auth-проверки, разбросанные по резолверам, сервисам и хелперам.
Начните с одного пользовательского сценария, с которым люди работают каждый день, например страницы аккаунта, биллинга или командного дашборда. Проследите весь запрос от поля схемы до резолвера, затем до обращения к базе и проверки прав доступа. Посчитайте дублирующиеся запросы. Отметьте все места, где разработчику пришлось угадывать, кто владеет полем или где должны жить правила доступа. Такой короткий аудит часто говорит больше, чем ещё один месяц общей чистки.
Хороший первый шаг — полностью исправить один болезненный запрос, а не расправляться с ним кусками. Если дашборд загружается медленно, возьмите именно этот запрос и наведите порядок сразу во владении, загрузке данных и авторизации. Дайте одной команде или одному сервису ясный контроль над задействованными полями. Добавьте batching или предварительную загрузку там, где происходит fan-out запроса. Перенесите логику прав доступа в один понятный слой и заставьте резолверы вызывать его вместо повторения тех же проверок с мелкими различиями.
Несколько коротких письменных правил помогают лучше, чем длинный архитектурный документ:
- Определите, кто может добавлять или менять поля схемы для каждого домена.
- Выберите одно место, где живут проверки прав доступа для обычных путей чтения и записи.
- Требуйте проверки запроса перед добавлением полей, которые затрагивают списки или вложенные связи.
- Отмечайте поля, которым нужен особый контроль, потому что они ходят в медленные сервисы или работают с чувствительными данными.
Делайте правила достаточно короткими, чтобы новый разработчик мог следовать им уже на второй день. Если для правил каждый раз нужна отдельная встреча, значит, они слишком расплывчатые.
Некоторым командам также нужен внешний взгляд, потому что внутри уже никто не успевает оспорить старые решения. Это бывает полезно, когда одновременно растут стоимость, задержки и внутреннее трение в команде. Oleg Sotnikov предлагает Fractional CTO-поддержку с фокусом на архитектуру backend, контроль затрат и практичную AI-first engineering-работу — это подходит командам, которым нужен прямой технический разбор, а не длинный консалтинговый процесс.
Спокойный бэкенд не появляется из переписывания всего подряд. Он появляется тогда, когда вы делаете один запрос скучным — а потом повторяете это там, где боль сильнее всего.


