GraphQL-резолверы на границе: как избежать разрастания связующего кода схемы
Узнайте, как держать GraphQL-резолверы на границе, выносить бизнес-правила в сервисы и не позволять связующему коду схемы превратиться в скрытую логику приложения.
Содержание
Почему связующий код схемы становится проблемой
GraphQL-резолвер часто начинается как тонкий адаптер. Он читает args, вызывает сервис и возвращает данные. Затем кто-то добавляет проверку статуса. На следующей неделе — правило ценообразования. Через месяц резолвер знает про триальные планы, просроченные карты, feature-флаги и роли, которые могут обходить лимиты.
Вот тогда резолвер перестаёт быть клеем и превращается в мини-контроллер. Он всё ещё выглядит безобидно, потому что каждое изменение небольшое. Проблема кумулятивна. Логика распространяется по полям, и вскоре поведение бизнеса живёт в коде схемы.
Дублирование появляется быстро. Один резолвер проверяет, может ли клиент обновиться. Другой проверяет то же правило с небольшой разницей. Третий копирует старую версию и добавляет особый случай для годовой оплаты. Реальное правило теперь не в одном месте — оно разбросано по файлам, которые изначально предназначались лишь для связи GraphQL с приложением.
Небольшое изменение продукта может сломать поведение в неожиданных местах. Допустим, команда поменяла правило апгрейда: приостановленные аккаунты не могут менять план до очистки платежа. Если это правило живёт в трёх резолверах и одном хелпере, путь почти всегда будет пропущен где-то. Схема по-прежнему компилируется. Тесты могут проходить. Баг первым найдёт пользователь.
Глубже проблема в том, что связующий код прячет намерение. Когда бизнес-правила сидят внутри парсинга аргументов, формирования ответа и обработки null, разработчики видят условия, но не понимают политику за ними.
Путаницу можно заметить рано. Разработчикам приходится читать несколько резолверов, чтобы найти одно правило. Одна и та же проверка ценообразования появляется в слегка разных формах. Рефакторинг кажется рискованным, потому что никто не знает, от чего зависит то или иное поле. Новички угадывают, где должна жить логика, и часто ошибаются.
Команды обычно учатся этому по мере роста кодовой базы. Проблема не в GraphQL. Проблема в том, что код схемы становится местом, куда тихо наваливаются бизнес-решения.
Что значит DDD-lite в этой настройке
DDD-lite — это взять полезное из domain-driven design и оставить в стороне церемонию. Вам не нужен лабиринт слоёв, фабрик и абстрактных базовых классов. Нужен ясный дом для бизнес-решений, понятные имена и чистая граница между кодом GraphQL и правилами приложения.
На практике это означает называть вещи по бизнесу, а не по транспортному слою. Резолвер должен говорить о подписках, командах, инвойсах или местах (seats). Он не должен становиться свалкой для парсинга аргументов, правил разрешений, проверок цен и побочных эффектов только потому, что схема это упростила.
Разделение простое. Резолвер переводит запрос в вызов приложения, затем переводит результат обратно в форму схемы. Сервисы или небольшие доменные объекты решают, что разрешено, что меняется и что должно происходить вместе. Если правило ценообразования меняется, вы обновляете сервис. Если меняются имена полей в GraphQL, вы обновляете резолвер. Эти изменения не должны тянуть друг друга за собой.
Вот в чём «lite»: держите модель маленькой. Если правило — несколько строк, обычной функции сервиса часто достаточно. Если у бизнес-концепта несколько связанных правил, дайте ему небольшой доменный объект с методами, читающимися как само бизнес-описание. Пропускайте паттерны, которые добавляют файлы, но не ясность.
Хороший тест прост: может ли кто-то прочитать резолвер и понять поток API за пару секунд? Он должен увидеть маппинг входа, один вызов приложения и маппинг выхода. Ему не должно приходиться просматривать условные конструкции, чтобы узнать, как работает биллинг.
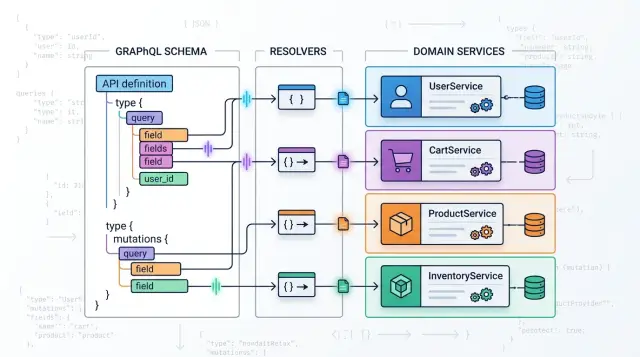
Именно поэтому идея держать резолверы на границе так полезна. Пограничный слой адаптирует данные. Доменный слой принимает решения. Проведите эту линию один раз и держите её очевидной. Код легче менять, когда сдвигается либо схема, либо бизнес.
Что должно быть в резолвере
Резолвер должен делать минимально необходимое, чтобы превратить GraphQL-запрос в вызов приложения. В DDD-lite он остаётся ближе к транспортному слою, а не к бизнес-слою.
Его задача начинается с чтения входа. Обычно это аргументы поля, метаданные запроса и текущий пользователь из контекста. Мутация вроде upgradeSubscription может читать planId и подписанный аккаунт, а затем передавать оба в один сервис или юзкейсовый метод.
Этот вызов сервиса должен быть центром резолвера. Один резолвер — одно понятное прикладное действие. Если резолвер начинает проверять цены планов, состояние аккаунта, лимиты триала, даты биллинга и побочные эффекты, это уже не адаптер. Это бизнес-логика, смешанная со связующим кодом схемы.
После возвращения сервиса резолвер может маппить результат в типы GraphQL. Эту часть легко недооценить. Доменные объекты часто используют имена и формы, понятные внутри приложения, а схема — имена, понятные клиентам. Этот перевод принадлежит краю.
Обработка ошибок тоже уместна в резолвере, но только на границе запроса. Если в запросе нет пользователя, если вход некорректен, или если сервис вернул известную доменную ошибку, резолвер должен превратить это в предсказуемый GraphQL-ответ. Команды создают беспорядок, когда один резолвер бросает сырые ошибки, другой возвращает null, а третий придумывает кастомный полезный объект.
Так же важно то, что нужно исключить. Оставьте правила ценообразования, изменения состояний, решения рабочего процесса, детали политики разрешений и порядок записи внутри сервисов. Если клиент может апгрейдиться только раз за биллинговый цикл, сервис решает это. Если апгрейд должен создать счёт, скорректировать лимиты и записать событие, сервис владеет этим потоком.
Полезный тест таков: если вы убрали бы GraphQL завтра и вызвали тот же use case из REST, фоновой задачи или CLI, будет ли поведение бизнеса работать? Если да — разделение здорово. Тонкие резолверы читают запрос, вызывают одно прикладное действие и маппят результат обратно.
Простой пример апгрейда подписки
Представьте мутацию upgradeSubscription. Клиент переходит с Basic на Pro в середине месяца. Запрос выглядит просто, но правила редко таковы. Нужно проверить, залогинен ли пользователь, может ли аккаунт апгрейдиться в триале, как считать проре-цацию и доступен ли план для этого клиента.
Толстый резолвер пытается сделать всё это в одном месте: он читает auth, валидирует ввод, получает данные биллинга, сравнивает планы, считает сборы, пишет обновления, ловит ошибки оплаты и формирует ответ. Так работает неделю или две. Потом резолвер превращается в связующий код с бизнес-правилами внутри.
Если держать резолверы на границе, резолвер остаётся маленьким. Он читает auth, маппит GraphQL-ввод в запрос сервиса и вызывает один сервис.
mutation {
upgradeSubscription(input: { accountId: "a1", targetPlan: PRO }) {
ok
code
message
}
}
Тонкий резолвер может передать такому сервису subscriptionService.upgrade() запрос с:
actorIdиз сессииaccountIdиз входа мутацииtargetPlanиз enum схемы
Сервис владеет правилами. Он решает, в триале ли ещё аккаунт, применяется ли проре-тация сегодня, может ли клиент перейти сразу на Pro и что делать, если платеж не прошёл. Эта логика должна быть вместе, потому что правила меняются вместе.
Сервис должен возвращать простой объект результата, а не логику, ориентированную на GraphQL. Например: ok: true с обновлённым кратким описанием подписки или ok: false с кодом PLAN_NOT_ALLOWED или PAYMENT_FAILED. Резолвер маппит этот результат в ответ схемы и на этом останавливается.
Сравните это с толстым вариантом, который он заменил. В старом резолвере изменение правила биллинга означало правку кода резолвера, тестовых моков и иногда других мутаций, которые копировали те же проверки. В тонком варианте вы обновляете один сервис и не трогаете слой схемы.
Это и есть смысл DDD-lite для GraphQL. Схема объясняет клиентам, как говорить с приложением. Сервис решает, что бизнес разрешает.
Как поэтапно рефакторить жирный резолвер
Не рефакторьте все резолверы сразу. Выберите одну мутацию, которая меняет данные и уже причиняет боль: повторяющиеся баги, тяжёлые ревью или правила, которым никто не доверяет. Если хотите тоньше резолверы, начните там, где стоимость очевидна.
Хорошая цель — резолвер с множеством решений. Обычно вы увидите проверки ролей, состояния, правила биллинга, прямые записи в БД, отправку событий и формирование ответа, всё смешано вместе. Именно этот микс делает мелкие правки рискованными.
Рефактор лучше делать короткими, скучными шагами. Прочитайте резолвер строчка за строчкой и пометьте каждую часть. Парсинг аргументов, чтение контекста и возвращение типов схемы — в резолвере. Правила вроде «этот пользователь может архивировать проект только если биллинг активен» — не в резолвере.
Затем создайте один именованный метод сервиса для бизнес-действия. Дайте ему простое имя, например archiveProject или changePlan. DDD-lite не требует огромной доменной модели. Требуется ясный дом для правил.
Переносите по одному правилу в метод сервиса. Начните с правила, которое чаще всего ломается: переходы состояний или проверки разрешений, связанные с бизнес-политикой. Оставляйте парсинг запроса и финальный маппинг в резолвере.
Прежде чем удалять старый код, добавьте тесты вокруг сервиса. Покройте по крайней мере один разрешённый кейс, один заблокированный и один побочный эффект, например сохранённую запись или поставленное в очередь событие.
Когда закончите, резолвер в основном должен читать вход, вызывать сервис и маппить результат в ответ схемы.
Это работает лучше, чем большой рефактор, потому что каждый шаг небольшой и легко ревьюится. Вы можете остановиться на любом шаге и безопасно деплоить.
Небольшая проверка помогает в конце. Если резолвер всё ещё решает цены, шаги workflow или лимиты аккаунта, он всё ещё толст. Если он в основном переводит GraphQL-ввод в вызов сервиса и переводит результат обратно, вы близки к цели.
Где должна быть валидация, авторизация и маппинг
Это разделение лучше всего работает, когда резолверы обрабатывают пограничные вопросы, а затем передают чистый ввод в прикладный код. Как только резолвер начинает проверять правила плана, декодировать ID, навязывать роли и вручную формировать каждую ошибку, он превращается во второй слой сервисов.
Валидируйте форму запроса на API-границе. Отсутствующие поля, неверные значения enum, некорректные ID и пустые строки должны проваливаться до того, как домен их увидит. Ваш сервис должен получать простые доверенные значения, а не сырые nullable-поля GraphQL.
Авторизация лучше располагать близко к точке входа юзкейса, обычно в application service или command handler. Резолвер может передать текущего пользователя, рабочее пространство или сессию из контекста, но сервис должен решить, может ли этот актёр апгрейдить подписку или смотреть биллинг. Это правило часто важно и вне GraphQL, например в фоновой задаче или админ-скрипте.
Валидация и авторизация легко спутать, но они отвечают на разные вопросы. «Является ли этот ID корректным?» — это пограничный вопрос. «Может ли этот пользователь изменить этот аккаунт?» — бизнес-вопрос. Держите их раздельно, и оба слоя останутся читаемыми.
Обычный поток запроса такой:
- Резолвер читает args и context.
- Пограничный код парсит ID, enum и обязательные поля.
- Сервис проверяет разрешения и бизнес-правила.
- Маппер формирует ответ для GraphQL.
- Один транслятор превращает доменные ошибки в GraphQL-ошибки.
Этот последний шаг важнее, чем команды часто думают. Если один резолвер превращает PlanLocked в понятную клиентскую ошибку, а другой превращает её в общую серверную ошибку, API кажется случайным. Поместите эту трансляцию в одно место. Тогда домен может возвращать простые ошибки, а GraphQL-слой маппит их в стабильные коды и сообщения.
Маппинг выхода должен оставаться скучным и последовательным. Если ваша доменная модель использует объекты денег, внутренние статусы или ID из БД, маппьте их один раз одинаково везде. Не разбрасывайте форматирование по разным резолверам.
Ошибки, которые совершают команды при попытке разделения
Команды часто выносят логику из резолверов и думают, что сделали дело слишком рано. Резолвер становится тоньше, но беспорядок просто переезжает в другое место.
Одна распространённая версия — гигантский helper-файл. Через месяц graphqlHelpers.ts содержит правила цен, проверки доступа, форматирование дат и полдюжины запросов к БД. Это всё ещё связующий код, просто с другим именем.
Ещё ошибка — построить один сервис, который делает всё для одного запроса. Метод вроде upgradePlan() начинает с SQL, проверяет права, применяет правила биллинга, маппит вывод для GraphQL и форматирует метки для UI. Такой сервис трудно тестировать, потому что он смешивает хранение, политику, доменные решения и презентацию.
Широкое использование одного метода в разных сценариях тоже приносит проблемы. Поток апгрейда, админская коррекция и промо-кампания могут менять одну и ту же подписку, но правила у них разные. Если один метод пытается охватить всё, исключения быстро накапливаются. Появляются флаги вроде isAdmin или skipEmail, и код перестаёт рассказывать понятную историю.
Просачивание типов GraphQL в доменный код — ещё одна тихая проблема. Когда сервисы принимают GraphQLResolveInfo, возвращают объекты, привязанные к схеме, или знают имена полей API, ваш домен перестаёт быть переносимым. Тогда любое изменение схемы отзывается через код, который не должен об этом знать.
Самая дорогостоящая ошибка — рефакторинг имён без тестов. Переименование planService в subscriptionDomainService ничего не меняет, если никто не проверил поведение. Толстый резолвер в новом каталоге всё ещё остаётся толстым.
Пара ранних симптомов:
- Сервисы импортируют пакеты GraphQL.
- Один метод содержит и запросы к БД, и формирование ответа.
- Несвязанные действия вызывают один и тот же метод с множеством boolean-флагов.
- Переименование было шире, чем разница в тестах.
Это разделение особенно важно для команд, которые активно используют AI в разработке. Агенты ревью, генерация кода и автоматизированные тесты работают лучше, когда каждый слой отвечает за одну задачу. Держите резолверы тонкими, бизнес-правила в сервисах и каждый сервис сфокусированным на одном рабочем процессе, который можно описать одним предложением.
Быстрые проверки для каждого резолвера
Резолвер должен быть скучным. Если он начинает вызывать ценовые проверки, проверять лимиты апгрейда и переписывать данные для трёх разных случаев, он делает слишком много.
Резолвер должен читать ввод, передать его в нужный сервис и сформировать ответ. Бизнес-правило должно жить в коде, который можно вызвать из тестов, задач или другого API.
Короткий чеклист для ревью:
- Если код не помещается на один экран — вероятно, нужно помочь.
- Если два файла могут решить одно и то же бизнес-правило — перенесите правило в один сервис.
- Если вы не можете протестировать правило без старта GraphQL — логика в неправильном месте.
- Если REST-эндпоинт или фонова задача нуждаются в том же поведении, оба должны вызывать один и тот же метод.
- Если новый участник не способен указать файл, где живёт реальное правило — разделение всё ещё смазано.
Небольшой поток апгрейда подписки делает это просто заметным. Резолвер читает user ID, plan ID и сессию. Затем он вызывает upgradeSubscription(...) и возвращает результат в форме GraphQL. Лимиты триала, проре-тация, блокировки даунгрейда и проверки состояния аккаунта остаются в сервисе. Это код, который вы хотите юнит-тестировать тщательно.
Если одна из таких проверок ломается, исправьте структуру, прежде чем добавлять новый код. Толстый резолвер почти никогда не становится тоньше сам по себе. Команды продолжают его патчить, потому что следующее изменение кажется маленьким, и через полгода никто не хочет его трогать.
Это разделение также делает повторное использование очевидным. Если позже вы добавите админ-панель, REST-маршрут или воркер очереди, они все должны вызывать один и тот же бизнес-метод. Тогда другой разработчик откроет кодовую базу и сразу увидит правило в одном месте, а не будет рыскать по связующему коду.
Следующие шаги для чище кода GraphQL
Большинству команд не стоит пытаться починить каждый резолвер за один проход. Начните с одной мутации, которая уже выглядит запутанной. Запишите её границы простым языком: что приходит из схемы, что решает доменный сервис и что возвращается клиенту.
Это небольшое упражнение обычно обнажает реальную проблему. Резолвер часто начинался как простой связующий код, затем накопил правила цен, проверки разрешений, изменения статусов и побочные эффекты. Как только вы назовёте эти части, станет проще переносить их.
Небольшое командное правило помогает больше, чем большой рефактор. Ограничьте резолвер несколькими обязанностями: читать args и context, валидировать форму запроса, передать понятную команду application service и маппить результат в форму GraphQL.
Если бизнес-решения появляются в резолвере, остановитесь и опустите их на уровень ниже. Хороший тест: если то же правило важно в CLI, воркере или REST-эндпоинте, оно не должно жить в резолвере.
Также нужна привычка ревью. Когда кто-то добавляет новое поле или мутацию, спрашивайте, где живёт правило. Если ответ «пока внутри резолвера», это обычно предупреждение. Команды экономят много времени на чистке, ловя такие случаи рано, а не после того, как пять похожих резолверов скопировали логику.
Код-ревью — хорошее место, чтобы показывать паттерн на очень коротких примерах. Один маленький дифф «до и после» достаточно. Покажите резолвер, который проверяет три бизнес-условия, затем покажите тот же резолвер, вызывающий subscriptionService.upgrade(...) и маппящий результат. На таких примерах люди учатся быстрее, чем из длинного документа.
Через несколько проходов кодовая база устаканивается. Новые изменения схемы становятся безопаснее, потому что правила живут в одном месте.
Если ваша команда распутывает границы API и домена, Oleg Sotnikov на oleg.is работает в роли Fractional CTO и консультирует стартапы по таким чисткам. Практический внешний обзор поможет решить, какой резолвер чинить первым и где на самом деле должны располагаться границы сервисов.
Часто задаваемые вопросы
How do I know a resolver is getting too fat?
Ищите принятие решений в резолвере. Если он проверяет цены, состояние аккаунта, лимиты триала, даты биллинга или побочные эффекты до вызова сервиса, значит он вырос за рамки адаптера. Ещё один признак — боль при повторном использовании: одно и то же правило появляется в двух или трёх резолверах с мелкими отличиями.
What should stay inside a GraphQL resolver?
Держите резолвер близко к границе запроса. Он должен читать аргументы и контекст, отклонять некорректный ввод, вызывать одно прикладное действие и маппить результат в форму GraphQL. Если он начинает решать, что бизнес разрешает, вынесите логику в сервис.
Where should business rules live instead of schema code?
Вынесите такие правила в application service или небольшой доменный объект. Этот код должен отвечать на вопросы вроде «кто может апгрейдить», «когда применяется проре-тация» или «какие изменения состояний должны происходить вместе». Тогда GraphQL остаётся тонким, а другие точки входа могут вызывать те же правила.
Should auth checks live in the resolver or the service?
Пусть резолвер передаёт текущего актёра из context, а сервис решает доступ. Резолвер может проверить, есть ли вообще пользователь, но сервис должен решать, может ли этот пользователь изменять подписку, архивировать проект или смотреть биллинг.
Where should I handle input validation?
Валидируйте форму запроса на краю: плохие ID, отсутствующие поля, пустые строки и неверные значения enum должны падать до домена. Так сервис получает простые доверенные значения, а не необработанный GraphQL-ввод с nullable-полюсами и особенностями транспорта.
How do I refactor a messy resolver without breaking things?
Начните с одной мутации, которая уже доставляет проблем. Перемещайте по одному правилу в именованный метод сервиса, оставляйте парсинг и маппинг ответа в резолвере и добавляйте тесты вокруг сервиса перед удалением старого кода. Маленькие шаги облегчают ревью и откат.
Can the same business logic work for REST endpoints and background jobs?
Да. Это хороший тест разделения: если REST, CLI или задачик нуждаются в том же поведении, они должны вызывать тот же метод сервиса. Если правило работает только в контексте GraphQL — значит резолвер всё ещё слишком много контролирует.
What mistakes do teams make when they move logic out of resolvers?
Частая ошибка — переместить мусор в один большой helper-файл. Через месяц graphqlHelpers.ts содержит правила цен, проверки доступа, форматирование дат и несколько запросов в БД — это всё ещё связующий код. Другая ошибка — единый огромный сервис, который смешивает SQL, политику, бизнес-правила и форматирование ответа для GraphQL. Следите за флагами типа isAdmin или skipEmail — часто это признак того, что метод пытается покрыть слишком много сценариев.
How should I return domain errors to GraphQL clients?
Держите доменные ошибки простыми внутри сервиса, а затем один раз переводите их на границе GraphQL. Например, сервис может возвращать PLAN_NOT_ALLOWED или PAYMENT_FAILED, а слой GraphQL превращает это в стабильные коды и сообщения для клиента. Это делает API предсказуемым.
When should I ask for outside help with GraphQL and service boundaries?
Когда команда постоянно патчит одни и те же резолверы, ревью длятся вечно или нет согласия, где должны жить правила. Короткий архитектурный обзор поможет выбрать первую мутацию для чистки и где на самом деле должны быть границы сервисов. Если нужно такое практическое сопровождение, Oleg Sotnikov на oleg.is предлагает Fractional CTO и консультации для стартапов.


