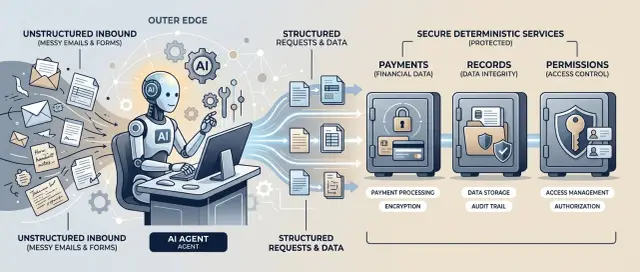
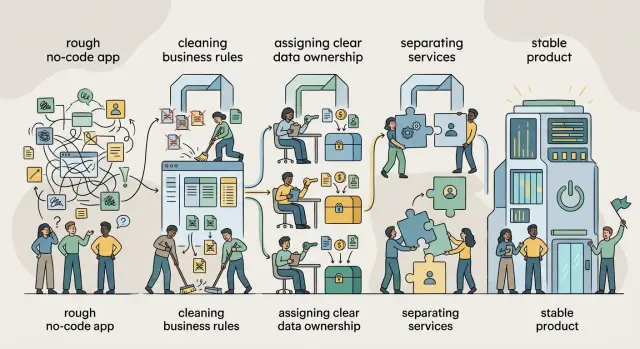
Границы сервисов: используйте боль поддержки, чтобы разделять продуманно
Границы сервисов работают лучше, когда вы изучаете боль поддержки, повторяющиеся инциденты и неясное владение, прежде чем дробить систему по неверным причинам.
Содержание
Какую проблему вы пытаетесь решить?
Плохая граница редко появляется сначала на диаграмме. Она проявляется в обычный рабочий день, когда поддержка получает простой тикет, и никто не может ответить на базовый вопрос: кто это владеет?
Клиент видит один сломанный поток. Компания видит три команды, четыре сервиса и цепочку догадок. Поддержка просит логи. Один инженер проверяет биллинг. Другой — auth. Третий говорит, что служба уведомлений только отправляет то, что получает. Проходит два часа, прежде чем кто‑то посмотрит на полный путь.
Так это выглядит в реальной жизни. Тикеты отскакивают. Клиенты повторяют своё объяснение. Маленькие проблемы превращаются в длинные переписки, потому что каждая команда видит только свою часть. Обычно люди не проектируют это специально. Они наследуют такое состояние.
Орг‑схемы затрудняют обнаружение проблемы. Команды часто выстраиваются вокруг истории, линий отчётности или того, кто что сделал первым. Клиентам всё это безразлично. Они нажимают одну кнопку и ожидают один результат. Если ваше внутреннее устройство разбивает это действие между слишком многими владельцами, диаграмма может скрыть реальную проблему продукта.
Нечёткая граница обычно оставляет одни и те же следы:
- поддержка не может сказать, где начинается ошибка
- инженеры спорят о владении прежде, чем начнут отладку
- одна клиентская проблема требует изменений в нескольких сервисах
- каждая команда говорит: "наша часть работает"
Ни один из этих признаков сам по себе не доказывает необходимость разделения. Важна закономерность. Один запутанный инцидент — возможно, неудача. Тот же самый инцидент каждую неделю — это доказательство.
Неясное владение замедляет исправления скучными и дорогими способами. Каждая передача добавляет время ожидания. Каждая команда просит другой лог или снимок экрана. Накопляются временные заплатки, потому что никто не владеет полным путём достаточно долго, чтобы убрать технический долг. Клиенты чувствуют задержку, а поддержка берет на себя стресс.
Вот почему границы должны определяться повторяющимися инцидентами, а не архитектурным вкусом. Если одна и та же путаница во владении появляется в багах, возвратах, неудачных регистрациях или пропавших письмах, разделение, вероятно, противоречит продукту.
Хорошее разделение уменьшает вопросы во время инцидента. Поддержка знает, куда отправлять кейс. Инженеры знают, где смотреть в первую очередь. Одна команда может исправить проблему, не втягивая полкомпании в звонок.
Признаки, что граница размыта
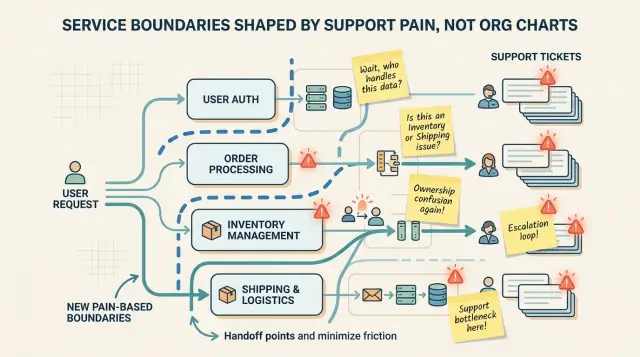
Нечёткая граница появляется в поддержке задолго до того, как она отразится на архитектурных диаграммах. Пользователи сообщают об одной проблеме, а ваша команда обрабатывает её как три разных. Этот разрыв говорит вам больше, чем любая орг‑схема, когда вы решаете, где провести линию.
Первый признак — пинг‑понг тикетов. Поддержка отправляет кейс в биллинг, биллинг отправляет его в auth, auth — команде API, а клиент ждёт, пока все проверяют логи. Одна передача — нормально. Три‑четыре передачи для одной и той же проблемы — нет. Когда этот шаблон повторяется, разделение заставляет людей обходить систему вместо того, чтобы проходить через неё.
Другой признак — простая путаница во владении. Если люди постоянно спрашивают «Кто это владеет?» в чате или заметках инцидента, граница слишком абстрактна или слишком узка. Хорошее владение почти скучное. Команда‑владелец знает это, делает первый просмотр и привлекает других только по необходимости.
Стоит также обратить внимание, когда одна клиентская проблема пересекает слишком много систем, прежде чем кто‑то сможет её исправить. неудачная регистрация может затронуть веб‑приложение, идентификацию, доставку писем, синхронизацию CRM и аналитику. Если поддержке нужны пять команд, чтобы просто объяснить, почему пользователь не получил доступ, путь клиента разрезан в месте, которое не соответствует тому, как возникает проблема.
Самый дорогой признак — баг, который возвращается под новым названием. В прошлом месяце это было «нет письма с инвойсом». В этом месяце — «учётная запись не активирована». В следующем — «пробный период закончился раньше срока». Если под всеми ними лежит один и тот же запутанный шов, у вас не отдельные проблемы. У вас одна сломанная граница в разных масках.
Бережные команды чувствуют это быстрее, потому что укрыться некуда. Поэтому опытные CTO часто начинают с истории инцидентов, а не с диаграмм. Повторяющиеся проблемы поддержки обычно говорят правду быстрее.
Какие инциденты считать сигналом
Один громкий аутейдж может подтолкнуть команду к раннему разделению. Реальный сигнал появляется снова и снова. Если одна и та же клиентская проблема возвращается на протяжении нескольких недель или месяцев, вероятно, это проблема границы, а не временная поломка.
Начните с клиентской проблемы, а не с внутренней ошибки. Группируйте тикеты в корзины вроде «оплата не прошла после апгрейда», «статус заказа не обновился» или «логин сработал, но данные аккаунта неверны». Такие корзины говорят больше, чем логи, в которых мелькают пять сервисов.
Нечёткая граница обычно проявляется в пути тикета. Поддержка открывает кейс, одна команда говорит «не наша», другая проверяет кусок потока, и клиент ждёт, пока люди спорят о владении. Этот след передач важен.
Эти шаблоны стоит отслеживать со временем:
- одна и та же клиентская проблема появляется в разных очередях с немного разными метками
- поддержка не может назвать явного владельца без запроса к нескольким инженерам
- две команды чинят свои части, но весь поток всё равно ломается
- задержки происходят из‑за передач, а не из‑за самого изменения кода
- исправление часто требует скоординированных релизов между сервисами
Одна плохая неделя мало что доказывает. Авария в облаке, неудачный релиз или сломанный сторонний инструмент могут заполнить поддержку и заставить всё выглядеть как проблема дизайна. Ждите повторных доказательств. Шесть‑семь инцидентов за два месяца с тем же путем значат больше, чем одна шумная суббота.
Простое правило помогает: считайте инциденты, которые выявляют путаницу, а не просто сбой. Если на чекауте всё ломается и все согласны, кто за это отвечает, возможно, нужны тесты или алерты. Если чекаут ломается, и три команды каждая владеет своей частью ответа, это указывает на границу.
Заметки поддержки очень помогают. Читайте комментарии в тикетах, историю передач и чат инцидента. Самый сильный сигнал часто не сам аутейдж, а момент, когда поддержка спрашивает «Кто это владеет?» и никто не может быстро ответить.
Нанесите боль на карту, прежде чем что‑то разделять
Начните с доказательств за последние 30–60 дней. Соберите тикеты поддержки, отчёты об инцидентах и заметки дежурств в одном месте. Вам нужны реальные проблемы поддержки, а не теории из планёрки.
Затем составьте короткую временную шкалу для каждой повторяющейся проблемы. Отметьте действие клиента, когда поддержка подняла вопрос, когда подключилась инженерия и все передачи команд после этого. Если тот же тикет постоянно прыгает между чекаутом, auth и биллингом, этот отскок — часть проблемы.
Для каждого инцидента фиксируйте несколько фактов:
- что пытался сделать пользователь
- какая команда получила тикет первой
- где случилась первая неправильная догадка о владении
- какие команды коснулись проблемы после этого
- где реально находилась ошибка
Эта первая неправильная догадка многое говорит. Она показывает, где система кажется поддержке и клиентам одним целым, но внутри продукта ведёт себя как несколько слабо связанных частей.
Теперь сравните эти временные шкалы с вашей текущей картой сервисов. Если те же инциденты постоянно пересекают одну и ту же границу между сервисами, ваша система, вероятно, отражает структуру команд больше, чем пользовательский поток. Это создаёт запутанное владение, более медленную триаж и более длительные простои, чем мог бы вызвать просто код.
Представьте знакомый кейс. Клиент не может завершить оплату, поддержка открывает тикет чекаута. Чекаут кажется в порядке, тикет уходит в auth из‑за истёкшей сессии. Auth не находит проблемы и отправляет в биллинг, где кто‑то наконец замечает устаревшее состояние клиента. Баг важен, но большая проблема — никто не смог назвать владельца на раннем этапе.
Не позволяйте одной громкой аварии вести к разделению. Ищите повторы: тот же путь передач, та же первая неправильная догадка, та же задержка прежде, чем правильная команда взяла на себя дело. Три маленьких инцидента с одним и тем же шаблоном обычно говорят больше, чем одно драматичное событие.
Если карта показывает повторный объезд, исправьте эту границу. Если нет, возможно, пока не нужен разрез: хватит ясного владения для полного потока, лучших алертов или одной команды, которая остаётся с проблемой до её полного закрытия.
Простой способ нарисовать лучшую границу
Начните с области, которая постоянно создаёт проблемы поддержки. Может быть, возвраты не проходят, пользователей списывают дважды, и поддержка гоняет кейсы между биллингом, чекаутом и аккаунт‑командой. Этот беспорядок — лучший сигнал, чем любая орг‑схема.
Запишите, за что эта область должна отвечать с точки зрения пользователя. Держите владение сквозным. Для биллинга это может означать: создание списания, подтверждение результата, сохранение квитанции, обработка повторных попыток и предоставление поддержки одного места для проверки статуса.
Хорошие границы обычно исходят из одного ясного обещания, а не из технического слоя. Если обещание звучит расплывчато, линия всё ещё неясна.
Быстрое упражнение помогает. Разделите область на четыре простых вопроса: что решает этот сервис, какие данные он хранит, какие внешние вызовы делает, и что поддержке нужно видеть, когда что‑то ломается.
Это быстро выявляет перекрытия. Если два сервиса оба решают, прошла оплата или нет, у вас проблема владения. Если один сервис хранит правду, а другой отвечает на вопросы поддержки, — это другая проблема.
Теперь проиграйте несколько реальных инцидентов против эскизной границы. Берите недавние тикеты, а не выдуманные крайние случаи. Спросите: кто бы ответил первым, кто мог бы исправить проблему без ожидания другой команды и где поддержка проверяла бы статус.
Возьмём пример с подпиской. Клиент меняет план, но число мест меняется в одном месте, а счёт — в другом. Поддержка видит рассогласование, продукт говорит, что это биллинг, а биллинг — что это подписки. Лучше дать одному сервису полную ответственность за изменения подписки и вытекающие счёты, или сделать один источник правды, а другой — простым последователем. Совместный контроль — обычно начало боли.
Завершите именованием одной команды, которая отвечает за результат. Эта команда может опираться на других, но именно она владеет исходом для клиента, алертами и путём в поддержку. Если никто не готов взять полную ответственность, граница ещё не достаточно ясна.
Реалистичный пример из клиентского потока
Обычный тикет поддержки кажется безобидным: клиент платит за апгрейд, видит списание на карте, но по‑прежнему не может пользоваться платной функцией.
Поддержка открывает запись аккаунта. План всё ещё показывает «free». Они отправляют кейс в команду аккаунтов.
Аккаунты проверяют профиль и не находят ничего сломанного. Почта верна, рабочее пространство активно, клиент существует в системе. Они переводят тикет в биллинг, потому что оплата могла не пройти.
Биллинг находит успешное списание за секунды. Счёт есть, платёж прошёл, риск возврата низкий. С их стороны всё сработало. Они передают дело в продукт, потому что доступ не обновился.
Теперь клиент ждёт часы, иногда целый день, пока три команды доказывают свою часть в порядке.
Глубже проблема — владение. Никто не владеет полным путём от «деньги получены» до «доступ выдан». Одна команда отвечает за списания, другая — за записи аккаунтов, ещё одна — за флаги функций или права доступа. Каждая чинит свою часть, но разрыв между ними остаётся.
Этот разрыв часто возникает из мелких решений, которые накапливаются. Биллинг отправляет событие. Продукт читает кэш. Аккаунты хранят данные о плане в отдельной таблице. Повторная попытка однажды проваливается, и никто не замечает, потому что каждый сервис считает себя здоровым в своей коробке.
Здесь начинается смысл разреза. Если правила платежей и правила доступа постоянно сталкиваются в тикетах, дежурных алертах и ручных исправлениях, текущая схема, вероятно, неверна.
Чёткая граница даёт каждой части системы одну ясную задачу. Биллинг решает, сдвинулись ли деньги. Доступ решает, чем клиент может пользоваться. Контракт между ними остаётся маленьким и скучным: платеж подтверждён, подписка активна, подписка отменена, возмещение выдано.
Это не уберёт все баги, но сделает сбои проще для обнаружения и даст одному владельцу полный клиентский результат на наблюдение. Когда один и тот же тикет продолжает отскакивать между поддержкой, биллингом и продуктом, это не невезение. Это карта того, куда граница должна сдвинуться.
Ошибки, которые ухудшают поддержку
Разрез может успокоить поддержку или превратить одну путаную проблему в три отдельных тикета. Разница редко связана со стилем архитектуры. Она зависит от того, совпадает ли новая граница с проблемой, с которой пользователи и службы поддержки сталкиваются каждую неделю.
Одна частая ошибка — разделять систему, потому что так сделал другой бизнес. Команды копируют формы, не копируя причину. Бизнес с миллионами заказов, строгими региональными правилами или десятками линий продуктов может нуждаться в отдельном сервисе там, где вы — нет. Если ваши инциденты всё ещё указывают на простой поток, разделение часто добавляет больше погонь, больше логов и больше обвинений.
Другая ошибка — проводить линии вокруг команд вместо пользовательских проблем. Если поддержка постоянно видит одну проблему через регистрацию, биллинг и доступ к аккаунту, эти части, возможно, нуждаются в более тесном владении, а не в отдельных коробках, которые повторяют орг‑схему. Пользователям всё равно, какая команда за что отвечает. Им важно, что один сломанный шаг останавливает всю задачу.
Крошечные сервисы с разделённым владением хуже, чем большой сервис с одним ясным владельцем. Когда две‑три команды могут менять один и тот же поток, поддержка теряет время быстро. Никто не знает, кто должен расследовать первым, и все предполагают, что проблема началась где‑то ещё.
Старые передачи часто переживают разделение, и это создаёт скрытый налог. Поддержка всё ещё шлёт тикет Команде A, Команда A просит логи у Команды B, Команда B просит контекст у аналитиков, и клиент ждёт. Если разделение настоящее, модель передач тоже должна измениться.
Мнения тоже вредят, когда команды игнорируют данные поддержки. Самый громкий инженер может хотеть красивых коробок на бумаге, но повторяющиеся инциденты рассказывают лучшую историю. Смотрите на показатели повторных открытий, время до первого полезного ответа, маршруты между командами и как часто одна клиентская проблема затрагивает несколько репозиториев.
Задайте несколько простых вопросов, прежде чем принять решение. Одна клиентская проблема всё ещё отскакивает между командами? Может ли поддержка назвать ясного владельца без расспросов? Убирает ли предполагаемый разрез одну передачу или создаёт новую? Показывают ли заметки инцидента ту же путаницу более одного раза? Если ответы слабые, разделение, вероятно, ухудшит ситуацию прежде, чем улучшит.
Быстрая проверка перед финальным решением
Разрез должен упростить жизнь клиентам и людям, которые их поддерживают. Если поддержке всё ещё приходится гадать, гоняться за тремя командами и пересылать тикет, новая граница мало что исправила.
Перед тем как менять что‑то, протестируйте идею на реальных проблемах поддержки. Старые заметки об инцидентах ценнее архитектурных мнений, потому что показывают, где работа реально застревает.
Пара простых проверок ловят плохие разделения на раннем этапе. Попросите поддержку описать владение в одном предложении. Если они не могут сказать «Биллинг отвечает за неуспешные списания» или «Identity отвечает за восстановление логина» без оговорок, линия всё ещё размита. Проверьте, может ли одна команда контролировать полный клиентский исход. Если сброс пароля каждый раз требует правок от команд identity, messaging и profile, клиенты всё равно ощутят разрыв.
Ищите повторяющиеся инциденты, которые ломаются на одном и том же шве. Одна плохая неделя может быть случайной. Один и тот же путь передачи, ломающийся снова и снова, обычно настоящее доказательство. Считайте передачи после разделения, а не только сервисы на диаграмме. Хороший разрез убирает координацию для типичных проблем. Плохой превращает один тикет в три.
Решите, как будете измерять результат, до внедрения изменений. Меньше пересылаемых тикетов, меньше повторных открытий и меньше времени на поиск владельца — надёжные признаки, что изменение сработало.
Небольшой тест часто говорит больше, чем большой редизайн. Выберите одну высокочастотную проблему, например, подтверждения чекаута, и проследите, кто касается её от первого алерта до ответа клиенту. Если ответ включает несколько команд, но нет явного владельца, вы нашли шов, который стоит исправить.
Будьте строги в определении «владельца». Владелец — не команда, которая написала большую часть кода много лет назад. Владелец — это команда, которая может диагностировать проблему, изменить код, выпустить исправление и ответить поддержке без ожидания ещё двух групп.
Если вы не можете предсказать снижение числа пересылаемых тикетов, остановитесь и пересмотрите план. Красивый дизайн на бумаге недостаточен. Поддержка должна почувствовать разницу в течение нескольких недель.
Что делать дальше
Не перерисовывайте половину системы. Выберите одну границу, которая постоянно создаёт повторяющиеся тикеты, медленные передачи или постоянные споры о владении. Именно там обычно первое полезное изменение.
Держите первое изменение маленьким. Передайте одну часть потока под одну ясную ответственность и запишите, что этот владелец контролирует, что не контролирует и когда подключается другая команда. Если никто не может объяснить это простым языком, граница всё ещё размыта.
Проводите изменение как короткое испытание, а не грандиозный редизайн. 2–4 недели часто достаточно, чтобы понять, стало ли поддержке проще или боль просто сместилась. В течение теста назначьте одну команду первой точкой для инцидентов в этой области, чтобы поддержка не прыгала между почтовыми ящиками.
Затем оцените изменения. Сосчитайте инциденты, затрагивавшие эту границу до и после. Отследите, сколько времени поддержка тратит на поиск владельца. Посмотрите, сколько команд подключается к каждому инциденту. Проверьте, как часто тикеты переоткрываются из‑за того, что первый фикс промахнулся по реальной причине.
Цифры помогают, но прочитайте и несколько заметок инцидентов. Снижение числа тикетов — хорошо, но один громкий инцидент может показать, что разделение всё ещё неверно. Если агенты поддержки всё ещё спрашивают «Кто владеет этой частью?», значит работа ещё не закончена.
Не позволяйте орг‑схеме решать результат. Чистая коробка на диаграмме может создавать ежедневную путаницу для клиентов и поддержки. Если одна команда может починить проблему от начала до конца, это часто лучше, чем аккуратная, но хрупкая передача.
Иногда внешняя экспертиза экономит время. Если дискуссия постоянно скатывается в политические споры, Oleg Sotnikov at oleg.is может просмотреть след инцидентов, протестировать предложенную границу на реальных проблемах поддержки и дать взгляд Fractional CTO без вовлечения во внутренние территориальные споры.
Если пробный тест уменьшил путаницу — оставьте его и задокументируйте. Если нет — откатите, сохраните заметки и протестируйте следующую границу с той же дисциплиной.
Часто задаваемые вопросы
How do I know a boundary problem is real and not just a bad incident?
Смотрите на повторяющиеся проблемы поддержки, а не на единичный громкий инцидент. Если одна и та же проблема постоянно перепрыгивает между командами, поддержка постоянно спрашивает «Кто это владеет?», и исправления требуют нескольких сервисов одновременно, значит граница, вероятно, мешает потоку продукта.
Which incidents should I count when I review support pain?
Учтите инциденты, которые показывают путаницу во владении. Баг в чекауте с ясным владельцем указывает на тесты или алерты. Баг в чекауте, который гоняет поддержку через биллинг, auth и продукт, указывает на проблему разделения.
How many repeated incidents do I need before I change a boundary?
Ищите закономерность. Шесть или семь похожих инцидентов за месяц‑два обычно говорят больше, чем одна шумная неделя. Повторы имеют значение, особенно если след передачи одинаков.
Should I design service boundaries around teams or the org chart?
Нет. Начните с действия пользователя, которое ломается, затем проследите, кто касается тикета от первого обращения до финального исправления. Организационная диаграмма объясняет историю; она редко объясняет, почему поддержка застревает.
What does clear ownership actually look like?
Владелец должен отвечать за результат от начала до конца: диагностировать проблему, изменить код, выпустить исправление и ответить поддержке без ожидания двух других групп в типичных случаях.
Should one team own the full customer outcome?
Да, в большинстве случаев. Одна команда должна отвечать за клиентский результат, даже если другие системы поддерживают поток. Это уменьшает передачи и даёт поддержке одно место для старта.
Can I test a new boundary without a big rewrite?
Запустите небольшой пробный тест. Выберите одну высоконагруженную проблему, дайте одной команде первичное владение на 2–4 недели и отследите, тратит ли поддержка меньше времени на поиск правильного владельца и уменьшается ли число пересылок тикетов.
What mistakes usually make support worse after a split?
Команды часто копируют чужую архитектуру, разделяют по орг‑схеме или сохраняют старые передачи после изменения. Тогда поддержка гоняется за большим числом людей, а не за меньшим. Общий контроль над потоком быстро создаёт проблемы.
What should I measure after I change a boundary?
Отслеживайте число пересланных тикетов, показатель повторного открытия, время до первого полезного ответа и сколько команд участвует в одном инциденте. Прочитайте несколько заметок в тикетах. Если поддержка всё ещё спрашивает «кто владеет этим?», значит изменения не были достаточно сильными.
When does it make sense to ask an outside expert for help?
Когда дискуссия превращается в политические споры команд или никто не может договориться о владении. Внешний CTO может просмотреть след инцидентов, протестировать предложенный разрез на реальных кейсах и дать честный вывод без вовлечения во внутренние споры.