Границы доменов AI‑продукта, которые останавливают разрастание промптов
Границы доменов AI‑продукта помогают разделять извлечение, рассуждение, маршрутизацию намерений и выполнение действий, чтобы один промпт не контролировал весь продукт.
Содержание
Что идёт не так, когда один промпт управляет всем
Один гигантский промпт часто начинается с хороших намерений и кончается путаницей. Он просит модель понять пользователя, извлечь факты, обдумать проблему, написать ответ и иногда ещё выполнить действие.
Когда всё это живёт в одном месте, модель смешивает роли, которые лучше держать раздельно. Она может домысливать недостающие факты вместо ожидания данных, воспринимать расплывчатый запрос как команду и пытаться действовать по нему. Так появляются уверенные на вид ответы, которые удаляются от источника, или действия, срабатывающие раньше, чем кто‑то собирался их запускать.
Большая проблема — это видимость. Если бот поддержки дал неверный ответ по возврату денег, что пошло не так? Может быть, он извлёк неверный документ. Может быть, неправильно понял пользователя. Может быть, правило действия оказалось слишком близко к правилу составления ответа, и модель их смешала. В одном большом промпте эти ошибки сливаются в одну расплывчатую проблему.
Маленькие правки делают всё хуже. Команда добавляет одну фразу по безопасности, одно правило форматирования или одно исключение, и что‑то не связанное начинает ломаться. Ассистент внезапно игнорирует базу знаний, задаёт странные уточняющие вопросы или перестаёт использовать нужный инструмент. Ничто не выглядит связанным, но весь промпт теперь толкает модель в ином направлении.
Для небольшой продуктовой команды стоимость отладки быстро растёт. Вы перечитываете длинные промпты, воспроизводите старые чаты, сравниваете выводы строчка в строчку и всё равно не можете понять, пришла ли ошибка из маршрутизации, извлечения, рассуждения или выполнения. Разрастание промптов происходит потому, что каждая фиксация превращается в ещё один абзац в том же файле.
Именно поэтому эти границы важны. Если один промпт владеет всей системой, каждая ошибка выглядит как баг промпта, даже когда настоящая причина где‑то в другом месте.
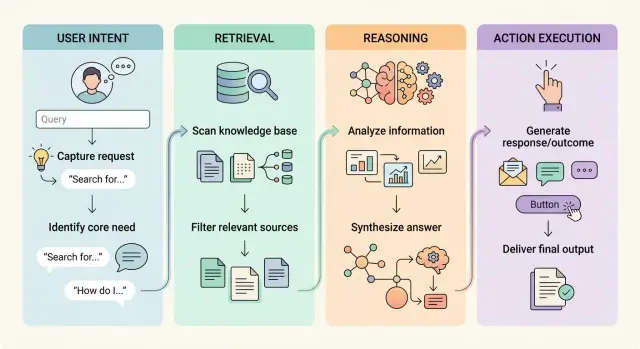
Четыре задачи, которые стоит разделить в вашей AI‑системе
Когда один промпт пытается делать всё, мелкие ошибки быстро распространяются. Бот поддержки может угадывать намерение пользователя, извлечь неверную запись, принять шаткое решение и затем отправить возврат. Разделение системы по задачам ограничивает масштаб ошибок и упрощает их поиск.
Первая задача — намерение пользователя. Она отвечает на простой вопрос: чего этот человек просит прямо сейчас? Вход — сообщение пользователя и немного контекста сессии при необходимости. Выход — короткий ярлык или маршрут, например "вопрос по оплате", "отмена заказа" или "совет по продукту".
Вторая задача — извлечение. Она получает одобренные факты, документы и записи. Вход — выбранное намерение и любые безопасные идентификаторы, например номер заказа или ID аккаунта. Выход — доказательства: несколько записей или отрывков, которые соответствуют запросу. Извлечение не должно решать, что делать. Оно должно только приносить факты.
Третья задача — рассуждение. Этот шаг сравнивает факты, применяет правила и выбирает ответ или следующий шаг. Вход — извлечённые доказательства, намерение пользователя и ваши политики. Выход — предложенный ответ или предлагаемое действие. Рассуждение не должно самостоятельной работать с базами данных и не должно ничего отправлять.
Последняя задача — выполнение действия. Это любой шаг, который меняет данные, отправляет письмо, создаёт тикет или списывает деньги. Вход — структурированная инструкция с уже пройденными проверками. Выход — результат, например "тикет создан" или "возврат заблокирован".
Каждая задача нуждается в своих входах и выходах, потому что каждая ломается по‑разному. Как только вы разделите их, можно тестировать каждый фрагмент, менять инструменты позже и не давать одному плохому промпту увести весь продукт в сторону.
Решайте намерение пользователя до извлечения или рассуждений
Большинство плохих AI‑потоков начинают с преждевременного извлечения данных. Если система подтягивает документы до того, как поймёт, чего хочет пользователь, она тратит токены, тянет шум и даёт модели слишком много точек отказа.
Начните с короткого фиксированного набора намерений. Большинству продуктов нужно несколько типов: ответ на факт, объяснение или сравнение вариантов, устранение неполадки, составление или переработка текста, запрос на действие или отметка как вне зоны ответственности.
На расплывчатый запрос нужен один уточняющий вопрос, а не интервью. Если пользователь говорит: "Можете это проверить?", задайте один чистый вопрос, например: "Вам нужно объяснение, диагностика или изменение?" Если он по‑прежнему остаётся расплывчатым, приостановитесь вместо угадывания.
Ранние остановки тоже важны. Если запрос выходит за рамки задач продукта, скажите об этом до начала извлечения или рассуждения. Ассистент по биллингу не должен скатываться в юридические советы. Fractional CTO‑ассистент не должен воспринимать "измените нашу production‑конфигурацию сейчас" так же, как "посмотрите наши затраты в облаке".
Сохраняйте выбранное намерение как структурированные данные, а не как предложение, спрятанное в промпте. Поля типа intent=troubleshoot, domain=infra, action_allowed=false и needs_followup=true упрощают маршрутизацию, делают логи чище и дают последующим шагам понятные правила.
Когда система сначала маркирует намерение, извлечение остаётся узким, рассуждение — сфокусированным, а действия — за проверками.
Держите извлечение узким и фактическим
После того как система знает намерение пользователя, извлечение должно выполнять одну небольшую задачу: вернуть те немногие факты, которые соответствуют этому намерению. Ничего лишнего. Если пользователь спрашивает о возврате, ищите записи по возвратам и политику возвратов, а не весь центр помощи, историю аккаунта и все старые тикеты.
Извлечение не должно догадываться, объяснять или решать. Оно должно собрать минимальный набор свежих фактов, которые нужны следующему шагу. На практике это обычно короткие фрагменты, а не дампы целых документов: ID записей и временные метки, последняя релевантная версия записи и один выдержанный фрагмент политики, отделённый от данных клиента.
Это разделение экономит массу проблем. Текст политики отвечает на вопрос "что должно произойти". Данные клиента и продуктовые данные отвечают на вопрос "что произошло". Когда вы смешиваете их в один клубок, модель начинает путать правила с фактами и становится неаккуратной.
Устаревшие и дублирующиеся записи тоже тихо вредят. Модель, увидевшая две версии одной и той же политики возврата, может процитировать старую. Модель, получившая пять копий одной заметки из CRM, может воспринять повторение как доказательство. Очистите это до того, как модель увидит данные.
Пример для поддержки показывает это ясно. Если кто‑то спрашивает: "Где мой возврат?", извлеките транзакцию возврата, её текущий статус, время последнего обновления и выдержку политики по срокам, если это важно. Не отправляйте полный профиль пользователя, несвязанные события доставки или длинную инструкцию по политике.
Малые полезные нагрузки извлечения делают ответы более надёжными. Они также упрощают тестирование: можно точно увидеть, какие факты модель использовала, а каких не было.
Дайте рассуждению отдельное рабочее пространство
Модель лучше рассуждает в небольшой чистой комнате. Дайте ей только факты, важные для одного решения, и оставьте всё остальное за пределами. Если вы дампите всю историю чата, схемы инструментов, текст политик и сырые документы в один промпт, модель начнёт догадываться, какая часть важна.
Этот шаг не должен управлять инструментами. Попросите модель принять решение, составить ранжированный план или дать короткое объяснение компромиссов. Затем другая часть системы решит, разрешено ли выполнять действие.
Хороший вход для рассуждения — узкий. Для случая с возвратом поддержке модели может понадобиться статус заказа, результат оплаты, политика возвратов и запрос пользователя. Ей не нужны креденшелы к базе, полные логи или все прошлые тикеты этого клиента.
Заставляйте модель говорить, чего ей ещё не хватает, прежде чем двигаться дальше. Эта привычка сокращает число плохих решений. Если статус доставки отсутствует или версия политики неясна, модель должна вернуть "missing facts" вместо того, чтобы домыслить.
Держите вывод компактным
Следующий шаг должен получить короткий структурированный результат, а не ещё одно эссе. Часто достаточно четырёх полей: decision, reason, missing_facts и confidence.
Такой вывод легко тестировать, логировать и просматривать. Он также не даёт рассуждениям притворяться действием. Рассуждение остаётся рассуждением. Извлечение находит факты. Исполнение действий происходит позже, под проверками.
На диаграмме это выглядит скучно, но на практике экономит время при разборе инцидентов. Вы сможете увидеть, получила ли модель плохие факты, приняла ли неправильное решение или передала слабый результат дальше.
Ставьте действия за жёсткими проверками
Самая острая граница — там, где система может что‑то изменить вне чата. Читать данные — одно. Отправлять деньги, менять аккаунт, удалять файлы или публиковать сообщения — другое. Этот шаг нуждается в правилах, через которые модель не сможет просто проговориться.
Начните с явных имён действий и типизированных аргументов. Не позволяйте модели писать расплывчатую инструкцию вроде "почините проблему с биллингом". Заставьте её выбрать определённое действие, например issue_refund(customer_id, amount, reason) или suspend_account(account_id, duration). Типизированные входы ловят неаккуратные догадки заранее и упрощают ревью.
Перед любым сайд‑эффектом ваше приложение должно проверить права, применить лимиты, отклонить недостающие или некорректные аргументы и заблокировать действия, касающиеся защищённых аккаунтов или систем. Эти проверки должны жить вне промпта. Если модель просит списать возврат выше лимита, система должна отказать. Если модель пытается отправить письма всем клиентам вместо одного, система должна остановить её.
Некоторые действия требуют второго шага с человеком. Попросите подтверждение перед движением денег, отправкой массовых сообщений или изменением данных аккаунта. Один лишний клик дешевле, чем извинения перед 800 клиентами.
Ведите аудиторский след. Логируйте, кто запросил действие, кто его утвердил, точные аргументы, которые модель передала, и итоговый результат. Когда бот поддержки выдаёт кредиты или внутренний ассистент запускает деплой, нужен след, который можно будет позднее проверить.
Многие команды становятся небрежными здесь. Они строят хорошего ассистента, а потом дают ему широкий доступ к инструментам. Более безопасная схема воспринимает выполнение действия как закрытую дверь: модель может попросить доступ, но продукт решает, откроют её или нет.
Стройте поток простыми шагами
Начните с малого. Выберите одно намерение пользователя и одно действие, которое легко проверить, например "сброс пароля" и "отправить ссылку для сброса после подтверждения". Узкая первая версия облегчает поиск багов и сохраняет границы ясными.
Простой порядок сборки лучше, чем один гигантский промпт:
- Создайте маршрутизатор намерений, который сортирует сообщения по нескольким понятным корзинам.
- Подключите одно безопасное действие с жёсткими правилами, например проверки прав и шаг подтверждения.
- Добавьте извлечение только после того, как маршрутизация хорошо работает на реальных сообщениях.
- Добавьте рассуждение как отдельный вызов, который возвращает строгий формат вроде JSON.
Этот порядок важен. Если маршрутизатор слаб, извлечение подтянет неверные факты, и рассуждение начнёт с плохого входа. Команды часто винят модель, когда настоящая проблема лежит раньше в потоке.
Держите шаг рассуждения в коробке. Дайте ему намерение пользователя, небольшой набор извлечённых фактов и требуемую форму вывода вроде {\"decision\":\"approve|reject\",\"reason\":\"...\"}. Не давайте ему вызывать инструменты напрямую. Другой слой должен решать, можно ли запускать действие.
Перед подключением живых инструментов намеренно тестируйте граничные случаи. Пробуйте расплывчатые запросы, смешанные намерения, отсутствующие данные аккаунта, устаревшие документы и пользователей, которые требуют действий, на которые у них нет прав. Бот поддержки, хорошо работающий с "Я не могу войти", может провалиться на "Я сменил телефон и потерял доступ ко всему".
Измеряйте ошибки на каждом рукаве, а не только по финальному ответу. Отслеживайте несоответствия намерений, плохое извлечение, поломанные форматы вывода и заблокированные действия. Когда вы видите, где поток ломается, исправлять становится гораздо быстрее.
Простой пример из поддержки
Бот поддержки для изменения адреса доставки показывает, зачем важно такое разделение. Пользователь пишет: "Я переехал. Отправьте заказ на 18 Pine Street, пожалуйста." Кажется просто, но систему нельзя заставлять одним промптом угадывать намерение, подтягивать данные, принимать решение по политике и редактировать заказ за один проход.
Сначала запрос идёт через маршрутизацию намерений. Система помечает его как запрос на изменение заказа, а не возврат, не вопрос по отслеживанию и не общее сообщение. Это решение сужает следующие шаги.
Затем извлечение подтягивает только те факты, которые нужны боту: статус заказа, совпадает ли вошедший пользователь с аккаунтом в заказе, и правила адресов для этого типа заказа. Если посылка уже отправлена или заказ принадлежит другому аккаунту, у бота теперь есть ясные факты вместо расплывчатого контекста.
Рассуждение идёт после этого. Его задача — прочитать факты и выбрать один из трёх путей: разрешить изменение, отказать или передать человеку. Если заказ ещё в обработке и аккаунт совпадает, модель может предложить обновление. Если заказ уже покинул склад, она должна отказать и объяснить почему. Если запрос выглядит рискованным, — эскалировать.
Слой действий остаётся отдельным от этого решения. Он не доверяет свободному тексту. Он проверяет разрешённый исход и затем делает одну маленькую вещь: просит пользователя подтвердить новый адрес или открывает тикет поддержки для человека.
Такое разделение делает бота спокойным и предсказуемым. Оно также значительно уменьшает разрастание промптов, потому что каждый кусок делает только одно дело.
Ошибки, которые стирают границы
Команды обычно стирают границы, когда пытаются сделать один умный промпт, выполняющий все задачи. Сначала это кажется быстрее. Потом бот начинает догадываться, подтягивать слишком много контекста и действовать по слабым сигналам.
Обычная ошибка начинается с извлечения. Вместо того чтобы взять несколько нужных фактов, система хватается за целые руководства, старые тикеты, заметки по политике и случайную историю чатов «на всякий случай». Такой лишний текст не делает ответ умнее. Он даёт модели больше поводов зацепиться за неверную деталь.
Следующая ошибка — слишком широкий доступ к инструментам. Модель рассуждения, которой достаточно объяснить проблему с оплатой, не должна иметь права отменять план, менять данные аккаунта или рассылать письма. Когда команды не разделяют извлечение и рассуждение, модель может незаметно соскользнуть из «думать» в «делать» без чистой передачи.
Ещё одна проблема прячется в самом промпте. Правила политики, долговременная память, извлечённые документы, инструкции пользователя и логика действий набиваются в один гигантский блок. После этого маршрутизация намерений мутнеет. Модель пытается одновременно решить, что хочет пользователь, какие факты важны и что разрешено — в одном проходе.
Небольшой пример из поддержки показывает, как это ломается. Клиент говорит: "С меня сняли два раза. Можете это исправить?" Бот подтягивает все статьи по биллингу, читает устаревшее правило возврата, решает, что клиент хочет возврат, и запускает кредит без подтверждения. Ответ звучит гладко, но поток ошибочен на трёх уровнях: намерение, факты и действие.
Уверенность усугубляет это. Если ответ звучит полированно, команды пропускают финальную проверку. Это опасно для всего, что меняет данные, отправляет сообщения или тратит деньги. Действия требуют жёсткой паузы, понятного правила или прямого подтверждения пользователя.
Обработка ошибок тоже часто игнорируется. Многие продукты прячут ошибки за общей извинительной фразой. Пользователям и операторам нужно знать, какой шаг упал: детекция намерения, извлечение, рассуждение или выполнение действия. Так вы будете отлаживать разрастание промптов, а не подпитывать его.
Быстрые проверки перед запуском
Чистая демка может скрывать грязные границы. Перед запуском прогоните систему через несколько «уродливых» кейсов и убедитесь, что каждый шаг падает так, чтобы команда действительно увидела это.
Пройдите короткий чек‑лист перед релизом:
- Прочитайте логи для одного неудачного запроса. Вы должны видеть точный шаг, который сломался: маршрутизация намерений, извлечение, рассуждение или действие. Если всё отображается как один большой кусок промпта, отладка затянется.
- Попробуйте вызвать действие без метки намерения. Модель должна отказаться, задать уточняющий вопрос или остановиться. Она не должна угадывать и отправлять, обновлять или удалять что‑то.
- Подайте системе устаревшие данные и сравните результат. Если старое состояние аккаунта, запасы или текст политики могут изменить выполняемое действие, добавьте проверки свежести перед исполнением.
- Отключите действия и задайте те же вопросы снова. Система должна по‑прежнему безопасно отвечать, объяснять ограничения и останавливаться на уровне совета. Если возникает рискованный кейс, человеческий ревьювер должен понять его за секунды, а не после чтения сырых дампов промптов.
Эти проверки кажутся простыми, но они ловят большинство утечек между частями системы. Они также показывают, существуют ли границы в коде или только на диаграмме.
Пример в поддержке это демонстрирует. Если пользователь говорит: "Верните деньги за мой последний заказ", система должна сначала пометить намерение, затем получить состояние заказа, потом рассуждать по политике и просить обзор, если кейс рискованный. Если ваши логи не показывают эту цепочку или устаревшие данные меняют итоговое действие, запуск преждевременен.
Команды часто пропускают эти проверки, потому что «happy path» работает. Но проблема не в нём. Настоящим испытанием является сложный запрос в 16:55 в пятницу.
Следующие шаги для вашей продуктовой команды
Большинству команд не нужен полный ребилд. Им нужна чёткая карта уже существующей системы. Возьмите текущий промпт и разберите его на четыре блока: намерение, извлечение, рассуждение и действие.
Выберите один рабочий поток, который может причинить реальный вред, если он будет угадывать или выходить за рамки. Часто это подтверждения возвратов, изменения аккаунтов, исключения по ценообразованию и исходящие письма. Исправьте этот путь в первую очередь. Узкое изменение проще тестировать и показывает команде, где реально лежат проблемы с границами.
Короткий контракт между шагами помогает больше, чем длинный промпт. Шаг намерения должен возвращать метку и оценку доверия. Извлечение — только одобренные факты. Рассуждение — черновик ответа или предложенное действие. Шаг выполнения запускается только после прохождения проверок.
Напишите эти контракты до добавления новых промптов. Определите, что каждый шаг может читать, что он может возвращать и что должно останавливать поток. Если шаг падает, отправляйте запрос человеку или спрашивайте пользователя уточнение. Это обычно лучше, чем позволять одному промпту импровизировать.
Ранний обзор правил действий тоже важен. Решите, кто может запускать реальное действие, какие логи сохраняются и какие действия всегда требуют подтверждения. Небольшие ограждения предотвращают дорогостоящие ошибки.
Если нужен внешний обзор, Oleg Sotnikov на oleg.is работает как Fractional CTO и стартап‑консультант; такого рода ревью архитектуры системы ему свойственно. Легче всего исправлять границы, пока рабочий поток ещё достаточно мал, чтобы быстро его изменить.


