Библиотеки логирования Go для понятных логов в продакшене
Библиотеки логирования Go сильно отличаются по JSON-выводу, request ID и времени настройки. Этот обзор сравнивает основные варианты для понятных логов сервиса.
Содержание
Почему сервисные логи превращаются в шум
У большинства сервисных логов одна простая проблема: они описывают отдельные моменты, а не один запрос. Одна строка говорит «обработчик запущен», другая — «таймаут базы данных», но ничто их не связывает. Во время инцидента вы прокручиваете сотни строк и только предполагаете, какие сообщения относятся к одному и тому же действию пользователя.
Шума становится еще больше, когда сервис повторяет одну и ту же ошибку на каждом уровне. Один медленный вызов базы данных может породить почти одинаковые сообщения от обработчика, сервиса, репозитория, цикла повторов и фонового воркера. Команда читает один и тот же сбой пять раз, но все равно не понимает, какой клиент его поймал, какой endpoint его вызвал и сколько занял запрос.
Одно полезное событие лучше десяти шумных. Запись лога с request ID, маршрутом, кодом статуса, задержкой и причиной ошибки дает всю историю в одном месте. Простая строка вроде «платеж не прошел» почти ничего не дает. Все равно придется искать соседние логи, чтобы сложить картину.
Именно поэтому команды начинают сравнивать библиотеки логирования Go. Им не нужен просто больший объем вывода. Им нужны логи, которые несут контекст и не забивают экран дубликатами.
Цель проста: меньше строк, больше контекста. Когда каждое событие показывает, кто отправил запрос, что сервис пытался сделать и где именно он сломался, инциденты становятся короче, а продакшен — менее хаотичным.
Как выглядят полезные логи
Полезные логи быстро отвечают на три вопроса: что произошло, к какому запросу это относится и нужно ли кому-то что-то делать. Если строка лога не помогает хотя бы с одним из этих вопросов, она обычно просто добавляет шум.
Хорошее событие начинается с небольшого набора полей, которые остаются одинаковыми во всем сервисе: время, уровень, сообщение и request_id. Так у вас появляется хронология, ощущение срочности и способ проследить один запрос через обработчики, воркеры и downstream-вызовы. В библиотеках логирования Go это важнее, чем красивое форматирование. Постоянные поля всегда лучше, чем умные сообщения.
После этого добавляйте контекст только тогда, когда он меняет решение, которое вы примете. Маршрут и статус полезны при завершении запроса. Идентификатор пользователя помогает, когда support нужно отследить проблему одного человека. Задержка полезна, когда вы ищете медленные участки или таймауты. Если каждая строка несет все поля сразу, логи становятся тяжелее и их сложнее просматривать.
Одно событие на одно действие работает лучше, чем подробный пересказ каждого шага. Запишите, что попытка оплаты началась, а потом запишите результат с итогом и причиной. Не описывайте каждую функцию, повторную попытку и ветку, если вы не отлаживаете конкретную ошибку.
Также полезно разделять разные типы вывода. События приложения должны описывать бизнес-действия и сбои. Access-логи должны хранить сводку по запросу. Stack trace должен появляться только при реальных ошибках, а не при обычных ошибках валидации. Когда эти потоки разделены, вы можете просмотреть плохой запрос за секунды, а не копаться в стене текста.
Как сравнивать библиотеки логирования Go
Сравнивайте каждый пакет на одном и том же маленьком HTTP-обработчике. Залогируйте один запрос, один таймаут базы данных и одно восстановление после panic. Этот небольшой тест скажет больше, чем любая таблица с фичами.
Начните с сырого вывода. Хорошие библиотеки логирования Go должны давать чистые JSON-логи без лишних оберток, собственных мапперов полей и самописных помощников. Если пакет с первого дня делает структурированное логирование неудобным, позже он обычно тоже останется неудобным.
Затем посмотрите на сопоставление запросов. Логгер должен позволять легко добавлять request ID, user ID, trace ID или название маршрута из context, не превращая каждый вызов функции в возню с прокладками. Если команде приходится помнить о пяти ручных полях в каждой строке лога, в спешке люди начнут их пропускать.
Хорошо работает простая оценочная таблица. Можно ли получить читаемый JSON в продакшене и обычный текст локально почти без настройки? Можно ли добавить request ID из context одним очевидным способом? Остается ли API понятным, когда вы добавляете поля, ошибки и информацию о вызывающем коде? Работает ли он быстро под нагрузкой и требует ли мало выделений памяти? Можно ли включить sampling, чтобы повторяющиеся ошибки не заливали логи?
Время настройки важнее, чем многие команды признают. Некоторые пакеты выглядят быстрыми в бенчмарках, но вокруг них нужно много дополнительной обвязки для конфигурации, работы с context или адаптеров для стороннего middleware. Эта цена проявляется каждый раз, когда поднимается новый сервис.
Информацию о вызывающем коде лучше проверять на реальном выводе, а не в документации. Некоторые библиотеки печатают файл и строку аккуратно. Другие добавляют шум или делают строку трудной для чтения. Sampling тоже стоит проверить отдельно. Если одна сломанная зависимость выдает одну и ту же ошибку 20 000 раз, логгер должен сохранить сигнал и убрать спам.
Скорость по-прежнему важна, но сначала нужны понятные логи. Логгер, который экономит пару выделений памяти, не поможет, если разработчики перестанут им пользоваться.
Slog для команд, которым нужен стандартный путь
slog дает командам Go структурированный логгер прямо в стандартной библиотеке. Это важно. Вы получаете уровни логов, именованные поля и общий API, не добавляя еще один пакет в каждый сервис. Для нового кодовой базы это обычно значит меньше споров и более быстрый старт.
Модель обработчиков проста и удобна. Для локальной работы можно использовать text handler, где людям нужно быстро просматривать логи, а в продакшене переключиться на JSON handler, где инструментам логирования нужны чистые поля. Вызовы логгера при этом остаются прежними. Вы меняете обработчик при старте и не трогаете остальной код.
slog тоже хорошо работает с сопоставлением запросов, но это все равно нужно настроить. Middleware может помещать в context значения вроде request_id, user_id или trace_id. Потом ваш логгер или handler может читать эти значения и добавлять их в каждую запись. Так сбой платежа, повторная попытка и таймаут остаются в одной цепочке, а не разбросаны по всему потоку логов.
Сложности появляются, когда вам нужны собственные правила для полей. Переименование полей, скрытие секретов, изменение формата времени или уплощение данных об ошибке часто требует написать собственный handler или аккуратно использовать ReplaceAttr. slog это умеет, но стандартный путь уже не кажется таким простым, как только правила логирования становятся жестче.
slog лучше всего подходит, когда вы запускаете новый сервис, хотите структурированное логирование без лишних зависимостей и не нуждаетесь в глубокой кастомизации с первого дня. Это разумный вариант по умолчанию для команд, которым нужен читаемый код сейчас и запас на рост позже.
Zap для строгих структурированных логов
zap подходит командам, которым важно, чтобы логи оставались предсказуемыми под нагрузкой. Он быстро пишет JSON, держит накладные расходы низкими и подталкивает разработчиков использовать именованные поля вместо простого текста в message.
Первое, что нужно понять, — разница между Logger и SugaredLogger. Logger использует типизированные поля, например zap.String("request_id", id) или zap.Int("status", 500). Такой стиль чуть более многословный, зато логи остаются чистыми и удобными для поиска. SugaredLogger быстрее писать с вызовами вроде Infow, поэтому он хорошо подходит, если команда хочет использовать zap, но не заставлять всех сразу переходить на типизированный API.
zap также хорошо удерживает имена полей в одном виде. Если команда договорилась о request_id, user_id, route и duration_ms, эти названия могут быть одинаковыми в обработчиках, заданиях и внутренних клиентах. Такая последовательность важнее, чем кажется. Как только в логах одновременно появляются req_id, requestId и trace для одной и той же идеи, фильтрация превращается в угадывание.
Сопоставление запросов настраивается просто. Middleware читает входящий request ID или создает его, а затем строит дочерний логгер с logger.With(zap.String("request_id", id)). Каждый обработчик использует этот дочерний логгер, поэтому каждая строка одного и того же запроса несет одно и то же поле без ручного повторения.
zap требует больше настройки, чем более легкие варианты. Нужно выбрать конфигурацию, encoder, формат времени, настройки caller и то, для каких уровней включать stack trace. Это дополнительная работа, но она окупается в загруженных сервисах, где одновременно идет много запросов.
Он особенно хорошо подходит для HTTP API со стабильным трафиком, фоновых воркеров с повторами и сбоями, команд, которые полагаются на JSON-логи в центральном хранилище логов, и сервисов, где нескольким разработчикам нужен один и тот же формат логов. Среди библиотек логирования Go zap — сильный выбор, когда вам важнее чистая структура и повторяемый вывод, чем максимально быстрый старт.
Zerolog и logrus в реальных командах
zerolog хорошо подходит, когда вам нужны компактные JSON-логи и минимум лишних действий. Его вывод чистый, удобный для машин, и достаточно небольшой, чтобы высоконагруженные сервисы не тратили место на лишний текст. Для занятого API это важно. Более короткие строки лога проще отправлять, хранить и искать.
Внутри обработчиков zerolog ощущается быстрым, потому что поля естественно выстраиваются в цепочку. Вы один раз создаете логгер с request ID, маршрутом или user ID, а потом продолжаете добавлять поля по мере прохождения запроса через сервис. Такой стиль хорошо подходит для сопоставления запросов. Обработчик оплаты может заранее добавить request_id, order_id и customer_id, а все последующие строки лога будут нести тот же контекст без лишних повторений.
logrus многим командам Go кажется более знакомым, особенно если они начинали с классических паттернов WithFields много лет назад. Он по-прежнему справляется со своей задачей, а его API легко читать. Но сегодня он ощущается более старым. Он опирается на подходы, которые появились до slog и до нынешнего движения в сторону более строгих JSON-логов.
История экосистемы здесь двоякая, но практичная. У logrus длинный след хуков, примеров и сторонних пакетов, поэтому он часто живет в старых кодовых базах с общими обертками и кастомными интеграциями. У zerolog хорошая поддержка middleware, особенно для HTTP-сервисов и логирования с учетом context, поэтому он чаще лучше подходит для новых сервисов, когда чистый структурированный вывод важен с самого начала.
Сырая скорость не всегда решающий фактор. Стоимость миграции может быть важнее. Если у вашей команды logrus уже встроен в middleware, алерты и внутренние пакеты, замена может превратиться в недели скучной чистки. Если вы начинаете с нуля, zerolog обычно дает более понятные JSON-логи с меньшим количеством лишнего багажа.
Как пошагово добавить сопоставление запросов
Request ID особенно полезен в худший день, а не в лучший. Когда платежный вызов возвращает 500, а в путь подключаются еще два сервиса, один ID позволяет собрать всю историю за секунды.
Начинайте на границе системы. Принимайте входящий request ID, если доверяете вызывающей стороне и формат выглядит нормально. Если нет — создайте свой в первом middleware или gateway. Сделайте это до запуска любого бизнес-кода. Если каждый обработчик создает собственный ID, сопоставление запросов сразу ломается.
Сохраняйте этот ID в контексте запроса и возвращайте его в заголовке ответа. Тогда support, frontend и backend-команды смогут искать одно и то же значение. Если клиент говорит: «с карты списали деньги, но страница показала ошибку», один ID может связать API-лог, задачу повторной попытки и исходящий вызов к платежному провайдеру.
Создавайте дочерний логгер один раз на запрос. Добавляйте туда поля вроде request_id, route и method. Все последующие строки лога унаследуют их, и JSON-логи останутся чистыми и стабильными. Обработчики должны добавлять только локальные факты, когда они их узнают, например user_id, order_id или имя провайдера.
Логируйте ошибки один раз, близко к тому месту, где вам уже известны итоговый код статуса и маршрут. Обычно это небольшой wrapper вокруг обработчика. Добавьте ошибку, статус и задержку. Не повторяйте привычку писать ту же ошибку в middleware, сервисном коде и слое базы данных. Три копии одного сбоя очень быстро превращаются в шум.
Проводите один и тот же логгер через весь путь. Передавайте его в обработчики, в задания, запущенные от запроса, и в исходящие HTTP-вызовы. Пробрасывайте request ID в заголовках или метаданных сообщения, чтобы следующий сервис сохранил цепочку.
Простой пример платежного API
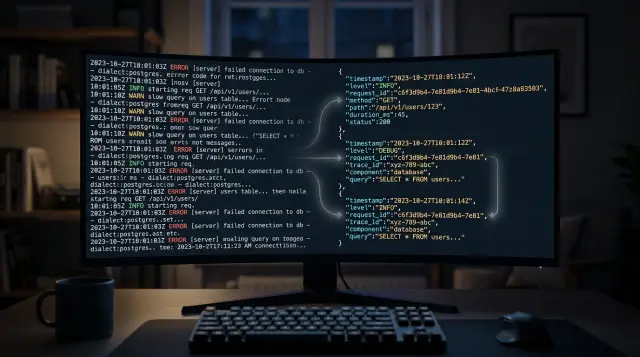
Клиент нажимает Pay, и ваш сервис получает POST /checkout. Обработчик создает request ID вроде req_9f3a, загружает корзину, просит платежного провайдера списать карту и записывает заказ в PostgreSQL. Если каждая строка лога несет один и тот же ID, вы можете проследить один checkout от начала до конца за секунды.
Каждая строка должна сохранять один и тот же небольшой набор полей, чтобы история оставалась читаемой: request_id, method, route, customer_id или cart_id, payment_id, amount, status, error и duration_ms.
Шумные логи обычно выглядят так:
starting checkout
calling provider
db write ok
slow query
payment failed
Эти строки почти ничего не объясняют. Вы не знаете, какой именно запрос упал, произошла ли списание до записи в базу и относится ли медленный запрос к тому же клиенту.
Компактные JSON-логи рассказывают всю историю:
{"level":"info","msg":"checkout_started","request_id":"req_9f3a","method":"POST","route":"/checkout","customer_id":"cus_42","cart_id":"cart_88"}
{"level":"info","msg":"payment_authorized","request_id":"req_9f3a","payment_id":"pay_771","amount":1299,"duration_ms":412}
{"level":"warn","msg":"order_insert_slow","request_id":"req_9f3a","order_id":"ord_901","duration_ms":1840}
{"level":"error","msg":"receipt_email_failed","request_id":"req_9f3a","error":"smtp timeout"}
Теперь медленный запрос виден сразу. Платеж прошел за 412 ms, но вставка заказа заняла 1840 ms. После этого упала отправка письма, так что support может сказать клиенту: «Платеж прошел, но письмо с чеком задерживается».
Этот же request ID делает трассировку полезной между сервисами. Если API, worker и логи базы данных все содержат req_9f3a, один поиск покажет весь путь вместо кучи несвязного шума.
Ошибки, которые прячут сигнал
Шумный поток логов обычно появляется из-за привычек, а не из-за самого логгера. Даже хорошие библиотеки логирования Go мало помогут, если каждый слой пишет одну и ту же ошибку, выгружает половину запроса и называет одно и то же поле разными именами.
Одна из частых ошибок — писать один и тот же сбой четыре раза. Таймаут базы данных начинается в слое хранения, потом его снова логирует сервисный слой, потом еще раз обработчик, а потом middleware добавляет одну запись сверху. Вы не получаете четыре факта. Вы получаете один факт, повторенный четыре раза, и разбор инцидента становится медленнее.
Другая ошибка — выгружать целые объекты в JSON-логи. Это часто затягивает туда пароли, токены, сырые данные клиентов или огромные payload'ы. Это еще и ухудшает поиск. Если платежный запрос падает, логируйте order ID, customer ID, сумму, количество повторов и ошибку. Полное тело запроса оставляйте только для короткой локальной отладки.
Имена полей тоже важнее, чем ожидают команды. Если один сервис пишет request_id, другой — reqId, а третий — trace, ваши фильтры ломаются. Выберите один набор имен и держите его одинаковым во всех сервисах.
Несколько правил помогают. Логируйте ошибку один раз на границе, где с ней уже можно что-то сделать. Считайте debug-логи временной диагностикой, а не обычными бизнес-событиями. Добавляйте ID в задания, повторы, сообщения очереди и фоновые задачи. Держите имена полей одинаковыми в каждом сервисе. Логируйте маленькие, конкретные факты, а не целые структуры.
Асинхронная работа часто остается без внимания. Worker повтора, который пишет «платеж не прошел» без job ID, номера попытки или родительского request ID, почти бесполезен. Когда система занята, отсутствие контекста стоит реального времени.
Быстрые проверки перед выбором
Выбор логгера быстро становится привязкой на годы. Как только логи начинают кормить алерты, дашборды и привычки on-call, сменить пакет позже стоит дороже, чем ожидает большинство команд.
Когда сравниваете библиотеки логирования Go, начните с вывода. Если ваш сервис уже отправляет логи в инструмент для логов, JSON с первого дня обычно безопаснее. Обычный текст удобен на ноутбуке, но продакшен-инструментам нужны стабильные поля вроде level, service, request_id и error.
Потом проверьте сопоставление запросов на реальном обработчике. Добавьте request ID в middleware, вызовите две внутренние функции и посмотрите, сохраняется ли один и тот же ID во всех строках без неудобной обвязки. Если API здесь сопротивляется, люди перестанут добавлять контекст, когда будут заняты.
Используйте короткую проверку на здравый смысл. Может ли новый коллега открыть один обработчик и сразу понять логирующий вызов? Могут ли ваши тесты проверять несколько полей вместо сравнения целых строк лога? Разбирают ли ваши текущие инструменты timestamps, вложенные поля и ошибки так, как этот пакет их выводит? Можно ли добавить request_id в каждом обработчике, не передавая пять лишних аргументов?
Часть с тестами подводит команды чаще, чем они ожидают. Полные снимки логов ломаются от крошечных изменений формата, и после этого никто не доверяет тестам. Обычно лучше декодировать вывод логов и проверять несколько полей, например level, message и request_id.
Последняя проверка скучная, но экономит настоящую боль. Прогоните примерные логи через инструменты, которыми вы уже пользуетесь, и убедитесь, что поиск, фильтры и алерты работают с полями, которые выдает этот пакет. Если ваш парсер теряет половину контекста, самый красивый API в мире не спасет от шума в продакшене.
Что выбрать для вашей команды
Большинство библиотек логирования Go умеют писать JSON и выводить ошибки. Но в реальной продакшен-работе это не делает их одинаковыми. Выбирайте ту, которой команда будет пользоваться одинаково, когда запрос падает, срабатывают алерты и кому-то нужно проследить одно действие пользователя через несколько сервисов.
slog — самый безопасный вариант по умолчанию для многих команд. Он встроен в Go, поэтому кажется знакомым, и новому разработчику легко его читать. Если вам нужна привязка к стандартной библиотеке и простой путь к структурированному логированию, slog обычно правильный выбор.
zap подходит командам, которым нужны более строгие привычки. Он хорошо работает, когда вы заботитесь о фиксированных именах полей, чистых JSON-логах и зрелой настройке, которую люди уже годами используют в продакшене. Он требует большей дисциплины на старте, но это часто окупается, когда несколько сервисов разделяют одни и те же правила логирования.
zerolog — хороший выбор, когда объем логов высок, а вам нужны компактные JSON-логи с очень низкими накладными расходами. Для занятых API и воркеров это часто полезно. Если вашей команде нравится легкий стиль и ее не смущают особенности API, это может быть практичный вариант.
Оставляйте logrus только тогда, когда цена миграции выше выигрыша. Многие команды по-прежнему работают с ним без серьезных проблем. Но если вы начинаете с нуля, новые варианты обычно проще помогают держать сопоставление запросов и структурированные поля в одном стиле.
Простое правило работает хорошо: берите slog как базовый долгосрочный путь, zap — когда нужна более строгая структура и зрелые продакшен-паттерны, zerolog — для компактного JSON и скорости, а logrus оставляйте только там, где замена просто отнимет слишком много времени.
Не выбирайте только по таблицам бенчмарков. Правильный логгер должен соответствовать тому, как ваша команда пишет обработчики, ревьюит код и разбирает инциденты.
Следующие шаги
Выберите один сервис, который уже получает реальный трафик. Не переносите новый стиль логирования сразу на всю кодовую базу. Задайте одну JSON-схему, один формат request ID и небольшой набор полей, которые появляются в каждой важной строке лога, например service, route, request_id, level, duration_ms и error.
Сделайте тонкий слой middleware до того, как логирование расползется по обработчикам, воркерам и вспомогательным пакетам. Этот middleware должен создавать или читать request ID, добавлять общие поля и сохранять одинаковые имена. Большинство библиотек логирования Go хорошо работают, когда эти правила понятны.
Потом дайте сервису поработать неделю и посмотрите на логи на реальном трафике. Шум обычно всплывает быстро. Болтливый health check, цикл повторов или путь валидации могут заглушить строки, которые вам действительно нужны во время инцидента.
Такая проверка обычно показывает несколько простых исправлений. Уберите логи, которые повторяются на каждом обычном запросе. Оставьте имена полей ошибок одинаковыми вместо того, чтобы менять их от пакета к пакету. Логируйте одно итоговое сообщение для повторов вместо каждой неудачной попытки. Убедитесь, что request_id присутствует от точки входа до вызова базы данных.
Если команда все еще спорит о выборе логгера, на время перестаньте обсуждать названия пакетов. Сначала определите правила, а потом выберите инструмент, который лучше всего им соответствует и меньше всего мешает. slog часто бывает достаточно. zap или zerolog имеют смысл, когда вам нужен более жесткий контроль или меньшие накладные расходы.
Если хотите получить второе мнение до того, как это распространится по продакшену, Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами как Fractional CTO и может помочь выстроить logging и tracing так, чтобы они оставались читаемыми под нагрузкой.
Часто задаваемые вопросы
Which Go logger should most teams start with?
Начните со slog, если нужен самый простой долгосрочный путь. Он встроен в Go, дает структурированные поля и позволяет команде использовать один знакомый API без лишних пакетов.
When does zap make more sense than slog?
Выбирайте zap, когда нужны более строгие JSON-логи и единые имена полей во всех сервисах. Настройка у него сложнее, чем у slog, но командам часто нравится такой обмен на типизированные поля и предсказуемый вывод под нагрузкой.
Is zerolog a good choice for high-volume services?
zerolog хорошо работает, когда API или воркеры пишут много логов и нужен компактный JSON с очень низкими накладными расходами. Он также удобен, если вы хотите один раз добавить контекст запроса и дальше просто дополнять поля по мере его прохождения.
Should I replace logrus in an older codebase?
Оставьте logrus, если сервис уже на нем завязан и замена только отнимет время. Для нового сервиса slog, zap или zerolog обычно позволяют проще поддерживать структурированные логи и сопоставление запросов.
How do I add request IDs without touching every function?
Используйте middleware на границе приложения, чтобы принять или создать request_id, сохранить его в context и собрать дочерний логгер с этим полем. Тогда обработчики и downstream-вызовы смогут переиспользовать один и тот же логгер вместо ручного добавления ID в каждой строке.
What fields should every request log include?
Держите общие поля небольшими: time, level, message и request_id. Добавляйте route, status, duration_ms и ID пользователя или заказа только тогда, когда они помогают понять событие или принять решение.
Where should I log an error?
Логируйте сбой один раз, рядом с границей, где можно что-то предпринять. Если это делает обработчик или обертка запроса, сервисный и storage-слои должны просто вернуть ошибку, а не писать тот же факт снова.
Should production logs use JSON or plain text?
Используйте JSON в продакшене, чтобы ваши инструменты логов могли фильтровать поля вроде request_id, service и error без догадок. Оставьте обычный текст для локальной работы, если команда читает логи в терминале и хочет быстрее их просматривать.
How many log lines should one request create?
Старайтесь делать одно событие на одно значимое действие, а не подробный пересказ каждого вызова функции. Обычно лучше работают стартовое событие и событие с результатом, чем десять почти одинаковых строк от ретраев, помощников и middleware.
How should I test a logging library before choosing it?
Запустите небольшой реальный тест до выбора. Залогируйте один запрос, один таймаут и одно восстановление после panic, а затем проверьте сырой вывод, сопоставление запросов и то, как ваши текущие инструменты поиска и алертов разбирают нужные поля.


