Go-библиотеки для мультитенантных SaaS-приложений, которые снижают риск
Go libraries for multi tenant SaaS apps могут снизить риск утечек запросов, слабых админ-процессов и хрупкой работы с context. В этом плане разобраны более безопасные варианты пакетов.
Содержание
Откуда берутся ошибки в мультитенантных системах
Большинство утечек между тенантами возникают не из-за какой-то экзотической атаки. Они начинаются с обычного запроса, в котором забыли фильтр по tenant.
Разработчик добавляет новый поиск, экспорт или отчет. Код работает, страница открывается, тест проходит. Но одного пропущенного условия tenant_id достаточно, чтобы подтянуть записи из другого аккаунта. В Go это часто случается, когда команда торопится и надеется, что все будут помнить правило каждый раз.
Именно поэтому люди вообще ищут Go libraries for multi tenant SaaS apps. Риск редко связан с большой идеей архитектуры. Чаще проблема в маленькой, скучной строчке кода, которую кто-то пропустил в загруженный вторник.
Фоновые задачи создают другой тип проблем. Запрос приходит с правильным tenant context, но очередь задач хранит только ID и полезную нагрузку. Спустя несколько часов worker забирает задачу без привязанного тенанта, выполняет запрос и трогает не те данные. Почтовые дайджесты, выставление счетов и задачи очистки — самые частые места, где это всплывает.
Админ-инструменты создают свою острую грань. Команды часто считают внутренние панели особым случаем и обходят обычные проверки ради скорости. Это кажется безобидным, пока действие поддержки не обновит данные не того клиента или массовая задача не пройдет по всем тенантам вместо одного. «Только для внутреннего использования» — это не система безопасности.
Тесты тоже могут скрыть проблему вместо того, чтобы поймать ее. Во многих фикстурах создается один тестовый тенант и дальше он используется везде. При такой схеме scoped queries в Go выглядят правильными, потому что некуда «утекать». Баг проявляется только тогда, когда у двух тенантов похожие записи и появляется не та.
Простой пример: представьте, что у двух компаний есть проект с названием «Website redesign». Если код ищет его по имени проекта и забывает про tenant scope, можно показать запись, которая выглядит правильной, но принадлежит другому клиенту. Это самый неприятный вид бага, потому что его не замечают сразу.
Первые сигналы обычно очевидны: запросы, где tenant ID необязателен; задачи, которые восстанавливают контекст наугад; админ-пути с собственными обходами; тесты, где никогда не создаются конфликтующие данные. Начинать нужно именно с этого.
Что должна делать хорошая библиотека
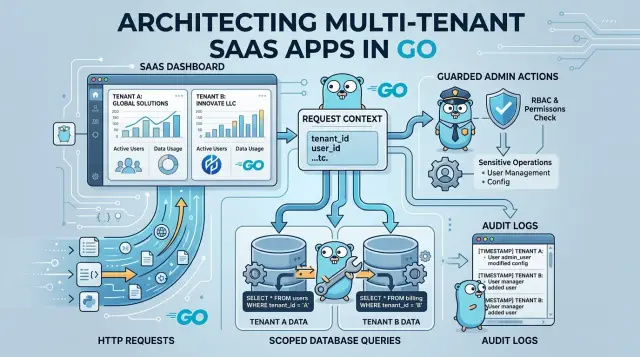
Полезный пакет должен убирать самые простые способы ошибиться с tenant. Если разработчику нужно помнить еще один фильтр в каждом запросе, кто-то обязательно забудет. Пакет должен передавать tenant ID от запроса до вызова базы данных с минимумом ручной работы.
Обычно все начинается на краю приложения. Ваш router или middleware читает tenant из поддомена, токена, заголовка или сессии, а потом кладет его в request context. После этого handlers, services и repositories должны брать одно и то же значение из одного места. Если каждый слой передает tenant ID по-своему, ошибки появляются очень быстро.
Следующая задача — сделать scoped queries в Go поведением по умолчанию, а не привычкой. Хороший пакет должен делать безопасный путь обычным. Когда код загружает счета, пользователей или проекты, фильтр по tenant уже должен быть внутри. Разработчик должен явно включать исключение, а не каждый раз вспоминать, что его нужно включить.
К межтенантному доступу нужен другой подход. Он должен быть заметным, немного раздражающим и очень явным. Если администратору нужно читать данные сразу по нескольким тенантам, код должен вызывать отдельный метод или использовать именованный override с причиной. Тихие обходы — это место, где начинаются плохие инциденты.
Пакету также нужен audit trail для админ-действий. Если кто-то меняет tenant context, приложение должно логировать, кто это сделал, когда и зачем. Этот лог должен покрывать сессии поддержки, исправления данных, экспорты и фоновые задачи. Через шесть месяцев вам нужен четкий ответ, а не догадка.
Надежный пакет обычно берет на себя пять задач:
- хранить tenant context один раз и передавать его через запрос
- применять фильтры tenant к обычным чтениям и записям
- требовать явный override для межтенантной работы
- записывать actor, reason и время при переключении tenant
- работать в HTTP handlers, ORM-моделях и очередях задач
Последний пункт часто упускают. Веб-запросы — лишь часть приложения. Cron-задачи, workers и import-скрипты тоже трогают данные, и им нужны те же ограждения. Oleg Sotnikov часто говорит о том, как строить системы, которые остаются компактными без потери безопасности, и это как раз тот случай, когда небольшой общий пакет может спасти от очень дорогой ошибки.
Библиотеки для tenant context
Многие ошибки в multi-tenant появляются еще до базы данных. Запрос приходит, приложение читает заголовок или поддомен, а потом tenant ID теряется где-то на середине вызова. Небольшой middleware-слой в chi или gin помогает закрыть это на раннем этапе.
С go-chi/chi можно добавить middleware, который читает X-Tenant-ID или разбирает поддомен из host. В gin-gonic/gin работает та же идея: первый handler читает данные и сохраняет результат для всей цепочки. Правило простое: определяйте tenant один раз, проверяйте его один раз и считайте это единственным источником tenant для запроса.
Оставьте один типизированный helper для tenant
Не разбрасывайте сырые string-ключи контекста по handlers. Используйте один типизированный helper вокруг context.Context, чтобы все services читали и записывали данные tenant одинаково.
type tenantKey struct{}
func WithTenant(ctx context.Context, tenantID string) context.Context {
return context.WithValue(ctx, tenantKey{}, tenantID)
}
func TenantFrom(ctx context.Context) (string, bool) {
v, ok := ctx.Value(tenantKey{}).(string)
return v, ok
}
Это выглядит скучно, и в этом весь смысл. Скучный код предотвращает странные баги.
Логи должны получать tenant ID в самом начале запроса, а не глубоко внутри кода после трех вызовов функций. Если вы используете log/slog, zap или zerolog, создайте request logger с полем tenant_id один раз и передавайте его дальше. Когда support нужно разобраться с одним плохим экспортом или ошибочным админ-действием, этот параметр экономит реальное время.
Не теряйте tenant context в фоновой работе
Request context заканчивается вместе с запросом. Задачи — нет. Если вы отправляете работу в очередь, передавайте tenant ID в payload задачи или в metadata до enqueue.
Пакеты вроде hibiken/asynq упрощают это, потому что каждая задача может нести payload с tenant_id, user_id и коротким названием действия. Когда worker стартует, он заново собирает тот же tenant context, прежде чем трогать хранилище, логи или внешние API.
Этот дополнительный шаг особенно важен для админ-инструментов. Сотрудник поддержки может повторно запустить импорт для одного клиента, а worker через пять минут на другой машине уже выполнит задачу. Если задача явно не несет tenant, workerу приходится гадать. А догадки — это начало ошибок на границах.
Библиотеки для scoped queries
Большинство утечек между тенантами начинается с одного пропущенного фильтра. Handler строит запрос, забывает tenant_id, и база возвращает строки из другого аккаунта.
Ent помогает тем, что размещает правила приватности рядом со схемой. Это держит проверки tenant ближе к модели данных, а не разбрасывает их по handlers и services. Если ваше приложение хранит tenant info в context, Ent может блокировать запросы, которые не совпадают с ней, даже когда разработчики переходят по связям и подгружают relations.
GORM идет более простым путем через scopes. Scope WithTenant(id) может один раз обернуть фильтр по tenant, а потом каждый метод репозитория сможет его переиспользовать. Это хорошо работает, если команда уже использует GORM, но безопасным такой подход остается только тогда, когда scoped-путь становится по умолчанию, а обходы для админов живут в отдельных методах.
Bun особенно полезен там, где слабое место — записи. Query hooks могут отклонять insert или update без tenant data и подставлять tenant_id из context до выполнения запроса. Это не решает все пути чтения, поэтому Bun лучше всего работает в паре с понятным helper для запросов или правилом репозитория.
Если вы используете raw SQL с pgx, Postgres row level security дает более сильную защиту на уровне базы. Приложение задает tenant для сессии или транзакции, а Postgres сам следит за совпадением даже если кто-то напишет плохой SQL. Это особенно полезно для поиска, экспортов, фоновых задач и support-инструментов, где разработчики часто выходят за рамки ORM.
Простое правило помогает лучше, чем смешение подходов:
- Используйте один путь по умолчанию для чтения.
- Используйте один путь по умолчанию для записи.
- Применяйте одно и то же правило tenant к поиску.
- Держите админ-обходы в отдельном, очевидном код-пути.
Смешивание Ent privacy для одних чтений, ad hoc GORM-фильтров для других и raw pgx-запросов для поиска обычно создает дыры. Лучше выбрать один подход, который команда действительно будет использовать каждый день. Для многих Go libraries for multi tenant SaaS apps скучная последовательность надежнее умной схемы.
Библиотеки для более безопасной админ-работы
Админ-инструменты вызывают одни из самых неприятных утечек между тенантами. Обычные пользовательские сценарии, как правило, проходят через одни и те же проверки каждый раз. Support-экраны часто пропускают их, потому что кому-то понадобилось быстрое исправление и он выпустил его в спешке.
Casbin хорошо подходит здесь, если рассматривать действия поддержки как отдельный класс доступа. Пользователь клиента, сотрудник поддержки и супер-администратор не должны жить по одним и тем же правилам политики. Доступ на чтение для диагностики — это одно. Экспорт данных, удаление записей или переключение tenant — это уже другой риск и для него нужны другие правила.
Держите админ-функции в отдельном код-пути. Дайте им отдельные handlers, отдельный middleware и часто отдельные service-методы тоже. Если обычный код приложения принимает tenant из session context, админ-код должен делать то же самое, но с более строгими проверками и более понятным логированием. Использовать публичные handlers с дополнительным параметром "tenant_id" — это частая причина проблем.
Имперсонация должна создавать трение. Она помогает support-командам решать реальные проблемы, но не должна выполняться в один клик. Более безопасный вариант — короткоживущий токен impersonation, который работает только для одного tenant и одной указанной причины, плюс шаг утверждения перед выдачей. В небольших командах даже подтверждение от второго человека заметно снижает риск невнимательных ошибок.
Для audit records важнее структурированные логи, чем красивые дашборды. Встроенный slog в Go или пакет вроде zap могут записывать, кто что сделал, когда и для какого tenant. Храните эти события в append-only audit table, а не только в application logs.
Всегда записывайте такие действия, как:
- экспорт данных
- удаления и массовые правки
- переключение tenant
- начало и завершение impersonation
Сам экран админа тоже должен уменьшать количество ошибок. Показывайте активное имя tenant и ID на каждой странице, в каждом модальном окне и перед каждым опасным действием. Если администратор может удалить запись, он должен видеть, какому tenant она принадлежит, еще до нажатия кнопки.
Хорошие админ-инструменты кажутся чуть медленнее, и это нормально. Пауза в две секунды дешевле, чем объяснять, почему один клиент увидел данные другого клиента.
Простой пример стека
Представьте B2B-приложение, которое обслуживает пять компаний-клиентов в одной базе Postgres. Это обычная схема, но она быстро становится рискованной, если один handler забывает фильтр или админ-инструмент пропускает проверку прав.
Более безопасный стек на Go держит границу tenant сразу в нескольких местах. Нужно, чтобы приложение знало tenant заранее, сохраняло его рядом с каждым запросом и позволяло базе ловить ошибки, когда код приложения дает сбой.
Хороший поток запроса выглядит так:
- middleware в
chiчитает поддомен, сопоставляет его с tenant ID и кладет этот ID в request context. - Код приложения читает tenant из context вместо того, чтобы доверять query-параметрам или input из формы.
- Правила приватности Ent добавляют фильтр tenant на каждый путь запроса, который должен оставаться scoped.
pgxотправляет запросы в Postgres, где row level security работает как второй замок на двери.- Casbin решает, что могут делать внутренние сотрудники, особенно на support-экранах.
Такой микс хорошо работает, потому что у каждого слоя одна задача. chi занимается обвязкой запроса. Ent удерживает обычные чтения и записи в рамках tenant, не заставляя каждого разработчика помнить WHERE tenant_id = ? весь день. pgx дает прямой и быстрый доступ к Postgres, когда он нужен, а Postgres RLS помогает остановить плохой запрос до утечки данных.
Админская часть требует особой осторожности. Командам поддержки часто нужна широкая видимость, но им редко нужен полный доступ на запись. Casbin подходит, если держать правила узкими. Например, сотрудник поддержки может экспортировать данные по использованию для одного клиента и открыть страницу этого аккаунта, но не больше. Он не должен свободно переключать tenant, править billing или просматривать все аккаунты просто потому, что «надо проверить одну вещь».
Именно поэтому Go libraries for multi tenant SaaS apps лучше работают слоями, а не как один магический пакет. Один слой переносит tenant context в Go, другой обеспечивает scoped queries в Go, а третий ограничивает действия сотрудников, которые могут подорвать доверие.
Если вы строите систему так, то пропущенный фильтр в одном handler уже не становится вашей единственной линией обороны. Запрос, ORM, база и админ-политика тянут в одну сторону. Именно такая избыточность спасает команды от неприятных инцидентов.
Как собрать все вместе
Порядок сборки важнее, чем думают многие команды. Начните с одного источника tenant identity и относитесь к нему как к факту, который остальная часть приложения потребляет, а не как к чему-то, что каждый handler выясняет сам. Это может быть поддомен, подписанный токен или session, но в итоге это должно стать одним типизированным значением в request context и оставаться неизменным весь запрос.
После этого оберните доступ к базе, прежде чем добавлять больше продуктовой логики. Именно здесь многие multi tenant приложения делают ошибку: команда сначала добавляет функции, а потом пытается залатать правила доступа. На практике каждый repository, query helper или ORM hook должен требовать tenant context заранее.
Хорошее правило простое: raw queries не должны жить в обычном коде приложения. Если кому-то нужен кастомный запрос, он должен пройти через wrapper, который автоматически добавляет tenant scope или вообще отказывается выполняться. Для scoped queries в Go скучность полезна. Если безопасный путь занимает одну строку, а небезопасный требует специального утверждения, разработчики обычно выбирают правильный путь.
Небольшой стек часто выглядит так:
- middleware один раз определяет tenant ID и роль пользователя
- context передает этот tenant через handlers, jobs и services
- слой данных отклоняет чтения и записи без tenant scope
- отдельный админ-путь обрабатывает межтенантный доступ
Только после этого базового слоя стоит добавлять админ-инструменты. Командам поддержки иногда действительно нужен более широкий доступ, но более безопасные админ-операции зависят от трения в нужных местах. Запрашивайте tenant первым, требуйте причину для чувствительных действий и записывайте, кто и что просматривал или менял.
Пакеты авторизации для Go помогают, но они должны стоять поверх tenant scoping, а не заменять его. Проверка роли говорит, кто может действовать. Фильтры tenant говорят, к каким данным можно прикасаться. Нужны оба.
Тесты должны специально пытаться сломать границу. Напишите один тест, который загружает запись из tenant A, пока запрос несет tenant B, и убедитесь, что приложение ничего не возвращает. Сделайте то же самое для background jobs, exports и admin screens. Если простой тест может перейти границу tenant, настоящий пользователь когда-нибудь тоже сможет.
Ошибки, которые ломают границы tenant
Большинство утечек между тенантами начинается с удобства. Handler читает tenant_id из заголовка, передает его как обычную строку через вызовы сервисов, и через три слоя один запрос забывает его использовать. Эта строка не имеет смысла для компилятора, поэтому любая функция может удалить ее, подменить или заменить пустым значением.
Если вы пишете на Go, сделайте tenant context трудным для игнорирования. Используйте типизированный tenant ID, аккуратно кладите его в request context и требуйте его на уровне repository. Go libraries for multi tenant SaaS apps помогают, но лучше всего они работают тогда, когда сигнатуры ваших функций делают безопасный путь очевидным.
Еще одна частая утечка появляется, когда команда смешивает ORM-код с raw SQL. ORM может по умолчанию добавить tenant scope, а потом один отчетный запрос использует raw SQL ради скорости и забывает про WHERE. Такой короткий путь может открыть строки всех клиентов. Исправление скучное, но эффективное: оборачивайте raw queries в helper, который требует tenant scope, и оставляйте unscoped-доступ только для очень маленького админ-пути.
Свои проблемы создает и админ-код. Команды часто переиспользуют внутренний endpoint «list all invoices» для обычных пользовательских экранов и надеются, что фронтенд отфильтрует результаты. Это перевернуто с ног на голову. Сервер должен решать, что может видеть пользователь. Фильтры на фронтенде меняют только отображение. Они не защищают данные.
Фоновые задачи тоже могут нарушать правила. Ночная синхронизация, отправка писем или задача очистки часто запускаются без tenant context, потому что никто не проходил через запрос перед этим. В итоге задача обновляет все строки, отправляет не тот отчет или удаляет файлы между аккаунтами. Каждая задача должна явно определять, работает ли она для одного tenant или для всех, и код должен считать эти два режима разными путями.
Небольшой пример делает это наглядным. Support-инструмент позволяет сотрудникам входить в аккаунт клиента от его имени. Если этот инструмент переиспользует обычные endpoints и просто подменяет tenant ID в браузере, одна пропущенная проверка может превратить доступ поддержки в глобальный доступ. Более безопасные админ-операции начинаются с отдельных маршрутов, явных audit logs и второго подтверждения перед любым межтенантным действием.
Скучное правило выигрывает: никогда не доверяйте данным клиента, никогда не предполагайте scope и никогда не прячьте глобальный доступ внутри общего кода. Безопасность в multi-tenant обычно ломается на тихих обходах, а не на больших архитектурных решениях.
Быстрые проверки перед релизом
Большинство утечек между tenant скучные. Handler пропускает один фильтр, support-инструмент держит последний tenant в памяти или задача запускается вообще без tenant. Десять минут осознанных проверок могут выявить больше рисков, чем еще один проход по стилю кода.
Используйте это как release gate, а не как приятное дополнение. Когда вы выбираете Go libraries for multi tenant SaaS apps, оценивайте их по тому, что происходит, когда разработчик забывает сделать один шаг.
- Войдите под одним тестовым пользователем, а затем попробуйте получить запись другого tenant, изменив ID в URL, API-вызове или input формы. Вам нужен чистый отказ, а не частичный ответ.
- Запустите background job, например отправку счетов или синхронизацию отчетов. Первая строка лога должна содержать tenant ID и job ID, чтобы быстро отслеживать ошибки.
- Откройте действия экспорта и удаления в админ-инструментах. Они должны просить второе подтверждение, а hard delete должен ощущаться медленным и осознанным.
- Посмотрите, как support-пользователь переключает tenant. Он всегда должен понимать, в каком tenant находится, зачем переключился и как вернуться назад без догадок.
- Проверьте, где живет default scoping. Один пакет должен владеть tenant context и default query scope, чтобы каждый handler не придумывал свои правила.
Простой пример хорошо показывает суть. Если админ открывает страницу CSV-экспорта, а значок tenant отсутствует, остановитесь. Обычно это означает, что действие зависит от скрытого состояния, а скрытое состояние — это способ, которым данные одного клиента оказываются в файле другого.
То же правило относится к удалениям. Если разрушительное действие требует всего одного клика, его слишком легко запустить не в том tenant. Типизированное подтверждение, видимое имя tenant и audit log — скучные, но рабочие меры защиты.
Следите за раздельной ответственностью. Если middleware задает tenant context, а repository-пакет тоже принимает сырые tenant ID, кто-то обязательно обойдет безопасный путь под давлением дедлайна. Более безопасные админ-операции начинаются со скучного правила: один источник истины, default deny и логи, где каждый раз назван tenant.
Следующие шаги к более безопасной схеме
Начните с простого инвентаря кода. Отметьте все места, где читается, записывается, фильтруется или соединяется tenant_id. Проверьте request handlers, background jobs, imports, exports, cron-задачи, support-скрипты и admin screens.
Большинство команд неплохо знают основной путь приложения. Утечки обычно сидят в боковых путях, которые никто не проверяет, пока клиент не сообщит о странных данных.
Потом выберите один шаблон для tenant-проверок и используйте его везде. Если одна часть приложения использует request context, другая вручную добавляет SQL-фильтры, а третья доверяет admin-флагу, правила начнут расходиться. Один пакетный шаблон для tenant context и scoped queries проще проверять, тестировать и объяснять новым разработчикам.
Короткий план очистки работает лучше, чем большой rewrite:
- Проследите
tenant_idот входа запроса до каждого вызова базы. - Замените копированные фильтры запросов общими helper или одним правилом пакета.
- По умолчанию блокируйте unscoped admin-чтения.
- Логируйте каждое межтенантное админ-действие с actor, target и временем.
Начните audit trail с админ-действий. Вам не нужен огромный проект по логированию, чтобы получить пользу. Простая запись о том, кто что сделал, для какого tenant и когда, может сэкономить часы при разборе инцидента.
Если вы все еще сравниваете Go libraries for multi tenant SaaS apps, используйте свою историю багов, чтобы сократить список. Выбирайте пакет, который делает рискованный путь труднее для написания, а не тот, у которого самый длинный список возможностей.
Если ваш Go SaaS уже кажется запутанным, внешняя экспертиза может помочь. Oleg Sotnikov может посмотреть на текущую схему и помочь спланировать более безопасный путь без полного переписывания. Такой разбор особенно полезен, когда вы уже знаете болевые точки, но нужен понятный порядок их исправления.
Более безопасная схема не начинается с идеальной архитектуры. Она начинается тогда, когда каждая проверка tenant следует одному правилу, каждое админ-действие оставляет след, и никто не может обойти scope случайно.


