Глобальный продукт в одном регионе: исправления, которые дают время
Глобальный продукт в одном регионе кажется медленным и хрупким. Узнайте, как кэширование, изоляция очередей и аккуратные релизы даёт время перед более сложными изменениями.
Содержание
Почему один регион начинает мешать
Продукт может долго работать из одного региона без проблем. Но с ростом это ощущение меняется. Пользователи, удалённые от ваших серверов, платят за каждый сетевой круг, и ожидание складывается быстрее, чем многие команды думают.
Если ваше приложение живёт в одном регионе США, а кто‑то из Сингапура открывает панель управления, странице может потребоваться несколько запросов, прежде чем она станет удобной. Несколько сотен миллисекунд на запрос не пугают на графике. Соберите пять‑шесть таких — и продукт ощущается медленным.
Расстояние — только часть проблемы. Разделяемая инфраструктура часто делает хуже, чем чистая задержка. Одна перегруженная очередь может задерживать письма, импорты, отчёты, вебхуки и другие задачи, которым не место бороться друг с другом. Для пользователей это выглядит как случайная медлительность, устаревшие экраны или действия, которые завершаются через минуты.
Релизы тоже становятся рисковее. Когда один регион обслуживает весь мир, плохой деплой попадает везде сразу. Сломанный вход, долгая миграция или плохие кэши превращаются в глобальную проблему за минуты.
Именно поэтому команды начинают думать о нескольких регионах. Но ловушка проста: дополнительные регионы решают один набор проблем и создают другие. Согласованность данных усложняется. Failover требует реального тестирования. Поддержка становится сложнее, потому что баг может проявляться в одном месте, а в другом — нет. Затраты растут, как и ежедневная операционная работа.
Для многих продуктов первым шагом должны быть скучные вещи. Уберите повторную работу, разделите очереди и упростите отмену релизов. Эти шаги не устраняют расстояние, но часто дают месяцы стабильного роста до того, как имеет смысл мульти‑регион.
Что измерить перед изменением архитектуры
Прежде чем менять архитектуру, найдите, что действительно медленное. Жалобы из Европы или Азии не всегда означают, что география — вся проблема. Иногда один плохой запрос или навязчивый внешний API создаёт большую часть боли.
Тестируйте загрузку страниц из городов, которые соответствуют реальному трафику, а не только из вашего офиса. Если приложение в США, проверьте Лондон, Сингапур и Сидней. Измеряйте время до первого байта, полную загрузку страницы и самые медленные API‑вызовы за экраном. Если жалобы сосредоточены вокруг оформления заказа, поиска или панелей — измеряйте эти пути напрямую.
Затем разбейте медленные запросы на части: время приложения, время базы данных и время внешних сервисов. Эта разбивка меняет разговор. Если приложение тратит 50 мс, база — 800 мс, а внешний сервис — 600 мс, новый регион мало что исправит. Лучше оптимизировать запросы, убрать лишние круги и добавить разумные падения.
Фоновая работа требует отдельного взгляда. Большинство команд отслеживают только время выполнения задачи после того, как воркер её начал. Пользователь сначала чувствует время ожидания в очереди. Задача, которая выполняется 4 секунды, но ждёт 3 минуты, всё ещё кажется сломанной. Снимайте время ожидания по очередям: одна шумная пакетная задача может похоронить живую пользовательскую работу, хотя общее число воркеров выглядит в порядке.
Небольшой дашборд решает четыре вопроса:
- Насколько быстро страницы и API загружаются из удалённых городов?
- Где именно каждый медленный запрос тратит своё время?
- Сколько задач ждут перед тем, как воркеры начнут их выполнять?
- Какой деплой случился прямо перед прыжком задержек или ошибок?
Ставьте метки релизов рядом с графиками ошибок и задержек. Команды часто пропускают это и тратят часы на догадки. Oleg Sotnikov часто советует сначала сопоставлять деплои со всплесками, потому что эта простая привычка может обнаружить проблему с откатом, плохой запрос или отсутствующий кэш до того, как кто‑то начнёт думать о мульти‑регионе.
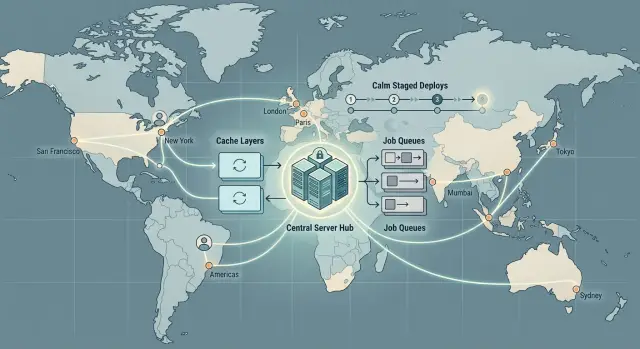
Уберите повторную работу с помощью кэша
Для продукта, который всё ещё работает из одного региона, кэширование часто — самый дешёвый способ сократить задержки без пересмотра архитектуры. Многие медленные запросы медленны не потому, что код ужасен, а потому что приложение повторяет одну и ту же работу снова и снова.
Начните с ответов, которые редко меняются. Страницы с ценами, публичные каталоги, feature‑flags, списки стран, справочный контент и фильтры поиска — частые победы. Если ответ остаётся тем же даже 30–120 секунд, этого часто достаточно, чтобы убрать много повторной нагрузки.
Популярные чтения не должны попадать в базу данных каждый раз. Отдавайте их сначала из быстрого кэша и при необходимости обращайтесь к базе. Пользователи получают быстрый ответ, а база получает передышку при всплесках.
На практике команды обычно начинают с кэширования публичных страниц, которые не меняются каждую минуту, общих справочных данных в API‑ответах и самых горячих чтений в памяти или быстром кэше. Статические файлы тоже заслуживают особого внимания. Изображения, скрипты, стили, шрифты и бандлы приложения должны быть ближе к пользователям, а не пересекать полмира при каждом визите.
Данные живого пользователя требуют аккуратности. Балансы счёта, права доступа, текущий инвентарь, недавние сообщения и состояние оплаты подрывают доверие, если отстают от реальности. В таких местах используйте небольшие целевые кэши вокруг безопасных кусочков данных, а не кэшируйте весь экран.
Короткие времена жизни кэша — безопаснее. Кэш на 60 секунд легче доверять, чем часовой, и он всё равно сильно сокращает повторную работу. Со временем можно увеличивать TTL там, где данные стабильны.
Хороший план кэширования даёт время, потому что убирает лишнюю работу до добавления сложности. Одна команда может сократить большую долю чтений базы за несколько дней. Переезд в несколько регионов может занять месяцы и принести новые режимы отказа.
Не давайте фоновым задачам блокировать пользователей
Когда одна очередь обрабатывает всё, самая громкая нагрузка побеждает. Всплеск обработки изображений, импорты или повторные вебхуки могут занять воркеры на минуты и сделать логин, оформление заказа или биллинг медленными, даже если само приложение в порядке.
Решение прямое. Разделяйте работу по срочности. Действия живых пользователей должны иметь свои очереди, воркеров и лимиты. Медленные или шумные задачи должны ждать в другом месте, чтобы не съедать всю мощность.
На практике это означает держать логин, оформление заказа, биллинг и обновления аккаунта в очереди высокого приоритета, а импорты, письма, ресайз изображений и генерацию отчётов — в низкоприоритетных. Вебхуки заслуживают собственной очереди, потому что внешние сервисы чаще падут или будут медленными. Лимиты на воркеры тоже важны: без них один поток всё равно может съесть все процессы.
Это особенно важно, когда пользователи уже далеко от ваших серверов. Они уже платят за задержки. Если фоновые задачи начнут конкурировать с живыми запросами, продукт быстро станет хуже.
Повторы требуют сдержанности. Команды иногда создают собственный инцидент, повторяя упавшие задачи каждую секунду. Используйте backoff: подождите немного, затем дольше, затем ещё дольше. Многие ошибки проходят сами по себе в течение 30 секунд или нескольких минут.
Дублирование задач наносит тихий урон. Одно событие может сработать дважды после тайм‑аута, повторного запроса клиента или повторной отправки вебхука. Если оба экземпляра выполнены, можно отправить два письма, дважды импортировать файл или списать карту дважды. Idempotency‑ключи или короткое окно дедупликации останавливают это.
Простой пример демонстрирует суть. Один клиент загружает 50 000 контактов, а другой пытается войти и оплатить счёт. Если оба действия идут в одну очередь, импорт может вытеснить биллинг. Отдельные полосы позволяют импорту продвигаться, не заставляя второго клиента ждать.
Делайте релизы спокойными и обратимыми
Команды часто теряют больше времени на шумные релизы, чем на чистую задержку. Когда один регион обслуживает всех, плохой деплой поражает всю базу клиентов одновременно. Растут ошибки, попытки повторов накапливаются, очереди раздуваются, и команда начинает гадать.
Малые релизы снижают этот риск. Небольшой дифф проще ревьюить, легче понять и легче откатить. Если что‑то ломается, причину найти быстрее.
Рискованные изменения сначала направляйте на небольшой срез пользователей. Ставьте поведение за feature‑флагом, направляйте немного трафика, или включайте для сотрудников до широкого релиза. Если задержки или ошибки растут — остановитесь. Эта пауза дешевле полного простоя.
Релиз не готов, пока откат не готов. Выберите версию, к которой вы вернётесь, убедитесь, что старый образ доступен, и проверьте, не блокирует ли откат изменение схемы. Если релиз меняет данные, заранее решите, можно ли откатить или нужен фикc вперёд.
Работа с базой требует осторожности. Долгие миграции в часы пик могут заморозить запросы по всему миру, даже если код приложения в порядке. Разбивайте большие изменения на мелкие шаги, делайте тяжёлую работу в низкий трафик и тестируйте тайминги на данных, приближённых к продакшену.
Короткий рукбук лучше длинного регламента. Один человек должен смотреть за ошибками, задержками и глубиной очередей во время выката. Один человек принимает решение об откате. Команда должна заранее согласовать стоп‑линию, например удвоение ошибок на пять минут. Команды запрашивают команды отката и feature‑флаги до начала движения трафика, а шаги с базой по возможности держат отдельными от деплоя приложения.
Это близко к тому, как Oleg Sotnikov управляет высокодоступными системами на тонкой инфраструктуре: делайте изменения маленькими, держите зону ответственности ясной и делайте откаты скучными. Пользователи едва должны заметить, что вы что‑то выпустили.
План спасения в порядке действий
Когда глобальный продукт начинает казаться медленным, сопротивляйтесь желанию перестраивать всё. Большинство команд получают больше пользы от аккуратной недели измерений и пары скучных фиксов, чем от спешки в мульти‑регион.
Начните с недели чисел. Отслеживайте p95 задержку, время ожидания в очередях и уровень ошибок по часам. Смотрите обычные дни, часы пик и хотя бы один релиз. Если пропустить это, вы будете лечить симптомы и пропустите реальный узкий горлышко.
Затем уберите повторную работу. Сначала кэшируйте статические ресурсы, потом чтения, которые люди запрашивают снова и снова. Публичные страницы, настройки, данные каталога и частые lookup‑ы — хорошие первые цели. Если страница загружается 10 000 раз и меняется дважды в день, приложение не должно перестраивать её 10 000 раз.
Далее вынесите медленные внешние вызовы из пользовательских запросов. Отправки писем, записи аналитики, синки CRM, проверки мошенничества и AI‑вызовы часто не обязаны завершаться до загрузки страницы. Поставьте их в очередь или выполните после ответа. Это одно действие может срезать болезненные секунды для дальних пользователей.
После этого разделите фоновые задачи по бизнес‑приоритету. Держите логин, оплату и другие срочные вещи отдельно от генерации отчётов, импортов, экспортов и пакетной очистки. Одна шумная задача может заставить продукт казаться сломанным.
Затем ужесточите дисциплину релизов. Выпускайте меньшие изменения, избегайте рискованных релизов в часы пик, добавьте health‑checks и потренируйте один откат. Команды, которые репетируют откат один раз, восстанавливаются намного быстрее, когда что‑то идёт не так.
Наконец, снова протестируйте опыт дальнего пользователя и сравните с первой неделей. Если задержки, время ожидания в очередях и ошибки снизились достаточно, вы выиграли время без мульти‑региональной сложности.
Простой пример
SaaS‑компания всё запускала из одного региона США. Клиенты в Европе, Азии и Южной Америке могли войти и пользоваться, но каждое утро проявлялась одна и та же проблема. Крупные импорты клиентов попадали в дефолтную очередь в начале рабочего дня в США, что пересекалось с активными часами в других регионах.
Сайт не падал полностью. Боль проявлялась на шаг позже.
Когда импорты заполняли очередь, отчёты ждали. Ждали и вебхуки. Менеджер в Берлине открывал панель и видел устаревшие числа. Команда в Сан‑Паулу запрашивала отчёт и получала его значительно позже, чем ожидалось. В саппорт сыпались одинаковые тикеты: "Приложение работает, но всё важное задерживается."
Команда не стала менять архитектуру и сначала убрала пробку.
Они разделили фоновые работы на отдельные очереди. Импорты пошли в одну очередь, отчёты — в другую, вебхуки — в третью. Это остановило блокировку всего остального одной тяжёлой задачей.
Потом они изменили кэширование отчётов. Если несколько человек просили один и тот же отчёт с одинаковыми фильтрами, приложение использовало недавний результат в течение короткого времени вместо перестройки отчёта каждый раз. Это сократило повторную работу с базой и сделало популярные отчёты быстрее, даже для пользователей далеко от региона в США.
Они также ужесточили дисциплину релизов: вместо больших батчей пару раз в неделю — маленькие релизы с чётким планом отката. Это уменьшило сюрпризы и не давало воркерам застревать после изменений.
Ничего гламурного. Просто аккуратная работа с тем, что пользователи чувствовали каждый день.
Объём поддержки упал: отчёты стали приходить вовремя, вебхуки очищались быстрее, и меньше релизов вызывали побочные эффекты. Команда выиграла достаточно времени, чтобы отложить мульти‑регион и спланировать его правильно.
Ошибки, которые всё ухудшают
Когда пользователи жалуются на задержки, команды часто хватаются за самое большое решение. Это обычно означает большие затраты, больше подвижных частей и неясный выигрыш. Один регион может прожить дольше, если избегать нескольких распространённых ошибок.
Первая — неосторожное кэширование. Команда видит медленную страницу, добавляет кэш и идёт дальше. Затем пользователи открывают страницу заказа, экран биллинга или панель поддержки и видят устаревшие данные, которые должны были измениться секунды назад. Быстро и неправильно ломает доверие. Кэшируйте повторные чтения, публичные страницы и дорогие запросы. Держите критичные для пользователя данные свежими или давайте очень короткий TTL и понятный путь обновления.
Следующая ошибка — дизайн очередей. Многие приложения стартуют с одной очереди для всего: письма, импорты, обработка изображений, вебхуки, уборочные задачи и события аккаунта. Это работает, пока одна шумная задача не возьмёт верх. Большой CSV‑импорт никогда не должен задерживать письма для сброса пароля или подтверждения оплаты. Разделяйте очереди по срочности и пределу распространения. Если одна очередь застряла, продукт целиком не должен это чувствовать.
Повторы тоже создают проблемы. Если внешний API падает и ваши воркеры ретраят каждые несколько секунд без ограничений, вы создаёте собственный всплеск. Логи растут, воркеры заняты, а реальная работа ждёт. Экспоненциальный backoff, пределы попыток и dead‑letter очереди — скучные инструменты, но они спасают от самодельных инцидентов.
Релизы падают по той же причине: слишком много изменений за раз. Если вы деплойите код, миграции, правки конфигурации и инфраструктурные изменения в одном шаге, никто не сможет понять, что вызвало проблему. Откаты становятся грязными. Маленькие обратимые релизы кажутся медленнее на бумаге, но в реальности позволяют остановить ущерб рано.
Последняя ошибка — считать мульти‑регион первым ответом, а не последним средством. Дополнительные регионы добавляют репликацию, больше путей релизов, сложную отладку и повышенные счета. Oleg Sotnikov часто советует сначала убрать архитектурный мусор: правила кэширования, изоляция очередей, спокойные повторы и чистые релизы часто дают месяцы перед необходимостью добавлять регионы.
Быстрые проверки перед мульти‑регионом
Мульти‑регион стоит времени и внимания. Если продукт всё ещё шаток, проверьте, изменили ли простые фиксы показатели. Многие команды переходят слишком рано и получают более сложный маршрутизинг, трудную синхронизацию данных и больше способов сломать продакшен.
Один регион всегда имеет очевидную слабость: расстояние. Но после улучшения кэшей, изоляции очередей и спокойных релизов это расстояние должно болеть меньше, чем месяц назад. Сравнивайте недавние данные с вашей собственной базой, а не с идеальной системой.
- Протестируйте продукт из удалённых локаций и сравните результаты с прошлым месяцем. Быстрее загружающиеся страницы, API и статические активы обычно означают, что кэширование купило вам время.
- Смотрите время ожидания в очередях во время импортов, обратно‑заполнений или всплесков трафика. Если очередь остаётся стабильной, а не растёт часами — фоновая работа больше не контролирует всё приложение.
- Потренируйте откат в контролируемом релизе. Если команда может вернуть предыдущую версию за минуты — дисциплина релизов работает.
- Проверьте, что происходит при падении одной задачи. Сломанный импорт, отчёт или вебхук не должны замедлять поиск, вход, оплату или другие несвязанные пути.
- Почитайте недавние тикеты поддержки. Меньше жалоб на тайм‑ауты, устаревшие экраны и страницы, которые никогда не заканчивают загрузку, важно не меньше графиков.
Если большинство этих проверок стало лучше — подождите с регионами. Спокойный продукт часто даёт несколько дополнительных месяцев, чтобы улучшить сам продукт, а не перестраивать фундамент. Если после этих исправлений дальние пользователи всё ещё ждут слишком долго или один регион всё ещё создаёт неприемлемый риск — тогда добавление регионов начинает иметь смысл.
Что делать дальше
Начните с пользовательских действий, которые люди замечают сразу: вход, открытие основной панели, поиск, сохранение изменения и завершение покупки или другой критичной формы.
Проверьте, как эти действия работают для пользователей в разных частях мира. Если в основном рынке действие занимает 800 мс, а в другом — 3 секунды, у вас есть чёткая цель. Нет нужды ускорять всё сразу.
Для многих команд следующий вопрос — стоимость, а не престиж. Оцените дополнительные регионы, реплики, новые базы, работу по фейловеру и время команды, нужное для всего этого. Затем сравните это с тем, что можно получить от лучшего кэширования, изоляции очередей и спокойных релизов.
Эти простые фиксы часто дают месяцы, иногда годы. Закэшированный дашборд резко сокращает повторные запросы. Изоляция фоновых задач останавливает импорты, письма или генерацию отчётов от замедления живых пользовательских запросов. Безопасные релизы не дают маленькой ошибке превратиться в глобальную проблему.
Перед добавлением регионов назначьте короткое архитектурное ревью. Одной встречи часто достаточно, если команда придёт подготовленной с числами по задержкам, уровню ошибок, задержкам очередей, временем отката и ежемесячной стоимостью инфраструктуры. Вопрос прост: вы перерастаете один регион или всё ещё платите заavoidable потери?
Если нужен внешний взгляд, Oleg Sotnikov просматривает такие настройки через oleg.is. Его работа как Fractional CTO и стартап‑консультанта охватывает инфраструктуру, поток релизов, дизайн очередей, AI‑поддержку разработки и контроль затрат — именно те области, где команды застревают перед мульти‑регионом.
Если самые быстрые пути для пользователей всё ещё слишком медленные после этих изменений — дополнительные регионы могут быть следующим шагом. Если они улучшились достаточно — вы купили время, не усложнив эксплуатацию слишком сильно.
Часто задаваемые вопросы
Когда стоит переходить с одного региона на несколько?
Добавляйте регионы после того, как вы измерили действительно медленные пути и устранили явный мусор. Если кэширование, разделение очередей, меньшие релизы и вынос внешних вызовов из пользовательских запросов всё ещё оставляют далёких пользователей в ожидании — тогда имеет смысл рассматривать дополнительные регионы.
Что нужно измерить перед изменением архитектуры?
Начните с p95 задержек, времени ожидания в очередях, уровня ошибок и времени релизов. Снимайте эти метрики из городов, где живут реальные пользователи, чтобы понять — виновата ли география, медленные запросы или внешние сервисы.
Может ли кэширование реально выиграть время, если приложение всё ещё в одном регионе?
Да. Часто это работает лучше, чем ожидают команды. Короткие кэши для статических ресурсов, общих справочных данных и частых запросов резко сокращают повторные обращения к базе без полной переработки системы.
Что не стоит кэшировать?
Не кэшируйте то, что пользователи ожидают увидеть точно и немедленно: балансы, состояние платежей, недавние сообщения, права доступа или актуальный инвентарь. Если всё же кэшируете часть таких потоков — держите очень маленький TTL и узкую область кэширования.
Как понять, что очереди замедляют систему?
Смотрите время ожидания в очереди, а не только время выполнения. Если работа выполняется быстро после старта воркера, но пользователи всё равно ждут минуты — вероятно, одна очередь смешивает срочную работу с шумной пакетной задачей.
Какие задачи нужно вынести в отдельные очереди в первую очередь?
Сначала выделите отдельную полосу для живых пользовательских действий: логин, оплата, биллинг и обновления аккаунта не должны конкурировать с импортами, рассылками, обработкой изображений, отчётами или повторными вебхуками.
Как повторять упавшие задачи, чтобы не усугубить проблему?
Используйте экспоненциальный откат вместо повторных попыток каждые несколько секунд. Подождите немного, потом дольше, и установите общий предел попыток, чтобы падающий сервис не держал воркеры занятыми и не блокировал реальную работу пользователей.
Могут ли внешние API заставить приложение в одном регионе казаться медленнее, чем просто расстояние?
Вынесите всё, что не обязательно для ответа страницы, из пользовательского пути: отправки писем, записи в аналитику, синхронизацию CRM, часть fraud‑проверок и многие AI‑вызовы можно выполнять после ответа или поставить в очередь.
Что делает релизы безопаснее, когда один регион обслуживает всех?
Меньшие релизы, флаги фич и заранее продуманный план отката. По возможности отделяйте изменения в базе от релиза приложения, назначьте одного человека следить за ошибками и задержками во время выката и приготовьте простые команды для отката заранее.
Какой практический план спасения перед тем, как платить за дополнительные регионы?
Неделю чистых данных: p95 задержки, время ожидания в очередях и уровень ошибок по часам. Затем исправьте крупнейшие узкие места в порядке приоритетности. Большинство команд получают заметное облегчение от кэширования повторных чтений, разделения очередей, выноса медленных внешних вызовов из запросов и репетиций отката — до того, как начнут делать мульти‑регион.


