Превью-приложения GitLab без Kubernetes для тестирования веток
Превью-приложения GitLab без Kubernetes позволяют product и QA открывать реальные сборки веток, заранее проверять изменения и удалять старые экземпляры с помощью cleanup jobs.
Содержание
Почему общая staging-среда создает проблемы
Один общий staging-сайт сначала кажется простым. Есть одно место для деплоя, один URL для всех и одна среда для команды. Потом в нее в один и тот же день попадают две ветки, и начинается путаница.
Общий staging смешивает изменения, которые никогда не должны были жить вместе. Один разработчик меняет оформление корзины, другой — настройки аккаунта, а QA в итоге тестирует все сразу. Когда появляется баг, никто не понимает, какая ветка его вызвала. Команда тратит время на разбор коммитов вместо того, чтобы проверять само изменение.
Это еще и очень обычным образом замедляет QA: люди стоят в очереди. Если staging может держать только одну ветку за раз, каждый деплой превращается в маленькие переговоры. Кто-то говорит: «Не трогайте staging, я тестирую». Кто-то отвечает: «Мне нужно всего пять минут». И эти пять минут копятся весь день.
У продуктовых команд возникает другая проблема. Они часто смотрят не ту сборку и не замечают этого. Дизайнер просит показать ветку A, открывает staging, а ветка B уже ее заменила. Обратная связь получается грязной, потому что комментарии больше не совпадают с тем, что разработчик выкатил.
Вопросы всегда одни и те же: это новая ошибка или старая? QA тестировал последнюю ветку или более ранний деплой? Product одобрил правильную версию? Не сломало ли это что-то еще после ревью?
Общий staging превращает простые вопросы в гадание, потому что среда все время меняется. Даже если все действуют с лучшими намерениями, приложение меняется прямо под ногами.
Небольшой пример делает это очевидным. Представьте команду с тремя активными ветками: изменение цены, исправление логина и новый шаг онбординга. Утром QA тестирует ветку с ценами. К обеду на staging уже лежит исправление логина. Во второй половине дня product проверяет там онбординг. К концу дня каждый видел разное приложение, но все говорят так, будто тестировали одно и то же.
Именно поэтому превью-приложения так помогают. У каждой ветки есть своя временная копия, поэтому QA и product могут проверять именно ту ветку, которая им нужна.
Как работают окружения GitLab без Kubernetes
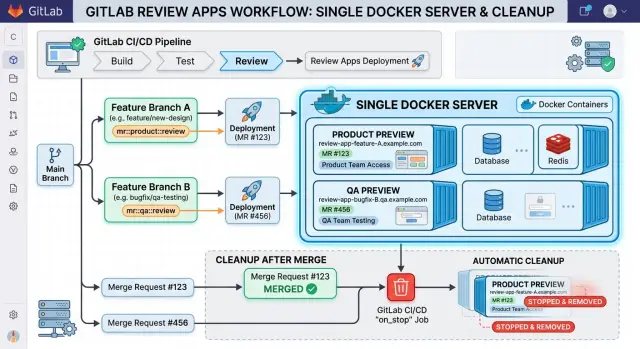
Не нужен кластер, чтобы дать каждой ветке свою тестируемую версию. Превью-приложения GitLab без Kubernetes — это всего лишь CI-задачи, временные окружения и Docker-хост, который по запросу запускает контейнеры.
Когда кто-то открывает или обновляет merge request, GitLab может запустить pipeline-задачу для этой ветки. Задача собирает образ приложения, подбирает уникальное имя для превью и запускает на вашем сервере контейнер для этой ветки.
Потом GitLab записывает этот запущенный экземпляр как окружение. В merge request команда видит понятную кнопку или URL для превью, так что product и QA могут открыть ветку без просьбы к разработчику деплоить ее вручную.
Базовый процесс
Простая схема обычно выглядит так:
- GitLab обнаруживает pipeline merge request.
- Задача ревью собирает Docker-образ для этой ветки.
- Задача запускает контейнер превью со своим именем окружения.
- GitLab показывает URL окружения в merge request.
- Отдельная задача остановки позже удаляет превью.
Вот и вся модель. GitLab отслеживает состояние окружения, а Docker запускает приложение.
Имя окружения часто выглядит как review/feature-login или похоже на это. Так проще понять, какое превью относится к какой ветке, и проще связать задачу запуска с задачей остановки.
Задача остановки важнее, чем многие ожидают. Без нее старые контейнеры продолжают работать, порты остаются занятыми, а место на диске тихо исчезает под ненужными образами и volume. Хорошая задача остановки выключает контейнер, при необходимости удаляет его сеть и временные данные и помечает окружение как остановленное в GitLab.
Такой подход хорошо подходит небольшим командам, потому что он остается простым. Один хост, один pipeline, одно превью на ветку. Если вы уже используете Docker в продакшене или для внутренних инструментов, перейти к Docker review apps совсем несложно.
Что подготовить на Docker-хосте
Начните с одного Docker-хоста, который выдержит несколько сборок веток одновременно и не начнет тормозить. Превью-приложения живут недолго, но они все равно тянут образы, запускают сервисы, пишут логи и занимают диск. Если на хосте уже не хватает RAM или хранилища, product и QA будут тестировать случайные сбои вместо самой ветки.
Для GitLab preview apps without Kubernetes один чистый и спокойный сервер часто оказывается достаточным. Дайте ему предсказуемую настройку: Docker, reverse proxy, если нужны URL для веток, и место для логов и временных данных. По возможности держите хост отдельно от продакшена. Так вы избежите неловких сюрпризов, когда тестовая ветка съест память или заполнит диск.
Заранее выберите правило именования, еще до запуска первого review app. Обычно команды выбирают либо URL на основе ветки, либо фиксированный диапазон портов. Шаблон вроде review-<branch-slug> легко читается в GitLab и потом легко убирается. Если имена начинают расползаться, cleanup jobs что-то пропускают, а старые контейнеры накапливаются.
Секреты должны храниться вне образа. Поместите их в переменные GitLab CI, файлы окружения на уровне хоста или в другое хранилище секретов, которому вы уже доверяете. Не встраивайте API-ключи, пароли к базе данных или почтовые учетные данные прямо в образ контейнера. Образ должен оставаться переиспользуемым. Секреты должны меняться в зависимости от окружения.
Сразу решите, как каждое превью будет работать с данными и ограничениями. То есть нужно понять, откуда берется база данных, куда попадают загруженные файлы — во временный volume или в префикс object storage, как будут блокироваться или перенаправляться исходящие письма, сколько CPU и RAM может использовать одно превью и сколько превью может работать одновременно.
С базами данных будьте осторожны. Общая база выглядит удобно, но она быстро приводит к конфликтам между ветками, особенно когда кто-то меняет схему. Небольшая начальная база для каждого превью обычно безопаснее. Для файлов используйте временное хранилище. Для почты отправляйте письма в mailbox catcher или просто отключайте доставку.
Сразу задайте жесткие лимиты на хосте. Ограничьте память, CPU и рост диска. Одна шумная ветка не должна вытеснять шесть других. Если сделать это заранее, остальной процесс ревью останется скучным, а именно этого и хочется.
Соберите процесс ревью шаг за шагом
Начните с триггера pipeline. Запускайте деплой только по событиям merge request, а не на каждый push во все ветки подряд. Когда merge request открывается или получает новые коммиты, GitLab должен пересобирать review app и обновлять то же окружение ветки.
Практичная последовательность простая. Соберите образ для ветки и дайте ему понятный тег, например slug ветки плюс короткий SHA коммита. Отправьте или сохраните этот образ там, откуда Docker-хост сможет его забрать. Затем запустите или обновите приложение на review-сервере с помощью Docker Compose или обычного Docker, используя отдельное для ветки имя проекта или контейнера. Потом сообщите GitLab имя окружения и адрес ветки, чтобы люди могли открыть его из merge request. И наконец, добавьте соответствующую задачу остановки и auto-stop time, чтобы старые превью не висели неделями.
Тег образа важнее, чем кажется многим командам. Если все тегировать как latest, люди теряют понимание того, что именно они тестируют. Тег вроде review-feature-login-a1b2c3d делает ветку очевидной и дает удобную точку отката, если деплой сломается.
Для запуска лучше не усложнять. Docker Compose часто хватает, потому что он может создать контейнер, сеть и именованные volume одной командой. Обычный Docker тоже подойдет, если приложение маленькое. Цель — стабильность: каждая ветка должна запускаться одинаково, а новый коммит должен заменять старое приложение, а не создавать вторую копию.
GitLab также должен понимать, что это настоящее окружение. Укажите имя окружения вроде review/feature-login и зарегистрируйте адрес ветки. Тогда product и QA смогут открыть точную сборку, привязанную к merge request, а не какой-то общий staging-сервер, который изменился час назад.
Задача остановки завершает цикл. Привяжите ее к закрытию и слиянию merge request и добавьте тайм-аут на один или два дня для веток, которые люди забыли. Эта задача должна останавливать контейнеры, удалять Compose-проект или набор контейнеров и стирать временные volume, если приложение их создавало. Пропустите очистку — и использование диска быстро вырастет, имена контейнеров начнут конфликтовать, а старые review apps запутают всех.
Дайте каждой ветке свой адрес и свои данные
Сырые имена веток плохо подходят для имен окружений. Они могут быть длинными, часто содержат слэши и в самый неподходящий момент ломают hostname. Обычно чище использовать вместо этого ID merge request, например review-482. Оставляйте тот же ID в имени контейнера, имени базы данных и задаче очистки.
Одно это решение убирает много шума. Product, QA и разработчики говорят об одном и том же превью одним коротким названием, а GitLab environments становится легко просматривать.
Каждому превью нужен свой адрес. Субдомен обычно удобнее, чем случайные порты, потому что людям не нужно смотреть в таблицу. mr-482.preview.example.com запомнить проще, чем :41082, хотя отдельный порт для review тоже подойдет, если вы хотите максимально простую схему на одном Docker-хосте.
Адрес должен указывать только на одну ветку. Если два merge request используют один URL, люди начинают тестировать не то и сообщать об ошибках, которых уже нет.
Изоляция данных не менее важна, чем URL. Если review app пишет в общие staging-данные, один тест может испортить следующий. Для всего, что выходит за рамки только чтения, дайте каждому превью свою маленькую временную базу и назовите ее тем же ID merge request.
Делайте это минимальным. Большинству веток не нужна полноценная копия продакшена. Небольшого Postgres-контейнера с чистой схемой достаточно для отправки форм, сценариев аккаунта и изменений в админке. Когда merge request закрывается, удаляйте приложение и базу вместе.
Наполняйте только теми записями, которые реально использует QA. Несколько пользователей, одна активная подписка, одна просроченная подписка, пара заказов и, возможно, один неудобный крайний случай обычно закрывают большую часть тестирования ветки. Загрузка огромного дампа замедляет запуск, тратит диск и делает каждое review app тяжелее, чем нужно.
Если merge request 482 меняет логику оформления заказа, поднимите review-482, подключите db-review-482, опубликуйте его на mr-482.preview.example.com и добавьте две карточки товара и трех тестовых пользователей. QA сможет оформлять заказы и повторять ошибки, не затрагивая чужую работу.
Отключайте все, что говорит с внешним миром. Review apps не должны отправлять настоящие письма, списывать деньги, создавать счета или запускать живые webhooks. Переведите отправку почты в режим логирования, используйте sandbox-настройки платежей и направляйте webhook-цели в локальный mock либо отключайте их для preview-сред.
Так branch testing остается безопасным. Люди могут кликать как настоящие пользователи, записывать данные и ломать все, не забивая чужие ящики, не трогая тестовые карты и не будя другую систему среди ночи.
Настройте cleanup jobs, которые действительно очищают
Review app помогает только тогда, когда он вовремя исчезает. Если старые превью живут днями, они съедают диск, оставляют старые данные веток и быстро превращают Docker-хост в беспорядок.
Начните с auto-stop time в GitLab environments. Выберите короткий промежуток, который подходит вашему рабочему ритму. Для многих команд достаточно одного-трех дней. Если ветке все еще нужен ревью, кто-то может снова открыть или заново развернуть ее.
Задача остановки должна удалять все, что создала ветка, а не только контейнер. Команды часто удаляют контейнер приложения и забывают про остальное. Вот так хосты и заполняются, даже когда «ничего не запущено».
Удаляйте все это одной задачей:
- контейнер приложения
- volume ветки или volume базы данных
- custom Docker network
- временные build-файлы, скопированные на хост
- branch-specific proxy config или запись DNS
Если вы используете Nginx или другой reverse proxy, удаляйте соответствующее правило, когда окружение останавливается. Если для каждой ветки создаются DNS-записи, удаляйте и их. Иначе product или QA могут открыть старый субдомен и решить, что превью все еще соответствует последней ветке.
Очистку образов лучше вынести в отдельное расписание. Не привязывайте тяжелую зачистку image к каждой остановке ветки, потому что это может замедлить активную работу. Запускайте плановую задачу раз в день или несколько раз в неделю, чтобы удалять неиспользуемые образы, остановленные контейнеры и dangling build cache. Так Docker review apps не захватят сервер.
Допустим, ветка checkout-copy-fix сливается во вторник. К среде задача остановки должна удалить ее контейнер, убрать временный volume, стереть proxy-файл, перезагрузить proxy и записать результат. Никаких хвостов. Никаких догадок.
Не скрывайте ошибки очистки. Если удаление volume не удалось или сломалась перезагрузка proxy, запишите это в логи и покажите в выводе job GitLab. Сбой cleanup job — это не мелочь. Одна-две ошибки могут оставить достаточно мусора, чтобы сломать следующий деплой.
Проверяйте usage диска тоже по расписанию. Когда хост достигает 80% или 90%, реагируйте заранее. Очистка лучше всего работает как регулярное обслуживание, а не как спасение в выходные.
Простой цикл ревью для product и QA
Общий staging-сервер может превратить одну маленькую функцию в проблему для всей команды. Превью-приложения исправляют это, давая каждой ветке свою временную копию продукта, чтобы люди могли тестировать одно изменение, не мешая чужой работе.
Представьте, что product manager открывает merge request с новым сценарием регистрации. Pipeline запускается, собирает ветку и поднимает Docker review app на хосте. Через несколько минут GitLab добавляет адрес окружения в merge request, и команда может открыть настоящие экраны в браузере.
Это важно, потому что product и QA не нужно гадать по скриншотам или читать комментарии в коде. Они могут пройти форму регистрации, попробовать слабые пароли, проверить неправильные форматы email и посмотреть, что происходит, когда поле остается пустым. Если ветка также меняет текст, верстку или правила формы, все это видно в одном месте.
Обычный цикл ревью очень прост. Product проверяет новый сценарий и оставляет замечания в merge request. QA тестирует счастливый путь и сложные случаи, например дубликаты email или пустые поля. Разработчик исправляет проблемы и отправляет новый коммит. GitLab обновляет то же окружение вместо создания нового, и команда снова проверяет ветку по тому же адресу.
Использовать один и тот же URL превью полезнее, чем кажется. Комментарии остаются привязаны к одной работающей версии функции, и никому не нужно гадать, какую сборку QA проверял вчера. Это экономит время, особенно когда ветке нужно два-три небольших исправления, прежде чем она будет готова.
Именно здесь GitLab preview apps without Kubernetes выглядят практично, а не модно. Команда получает реальное тестирование веток с Docker, обычным сервером и понятным рабочим процессом.
Когда команда сливает ветку, GitLab может автоматически остановить и удалить превью-приложение. Контейнер исчезает, временные данные пропадают, если вы так это спроектировали, а сервер получает обратно место на диске и порты. Следующая ветка стартует чисто.
Ошибки, которые тратят время и место на диске
Самый быстрый способ подорвать доверие к review apps — позволить веткам делить состояние. Если два превью пишут в одну базу данных, QA тестирует одно исправление, а product видит записи из другой ветки. Тогда никто уже не понимает, живет баг в коде или в оставшихся данных.
Дайте каждой ветке свою базу данных, префикс volume и имя контейнера. Даже небольшая временная база Postgres или отдельная схема для ветки лучше, чем одно общее хранилище на все превью. Изоляция занимает немного больше диска, но общие данные отнимают намного больше времени.
Конфликты портов создают другой вид хаоса. Жестко прописанные порты выглядят нормально, пока работает одна ветка, а потом следующая ломается, потому что порт 3000 или 5432 уже занят. В GitLab preview apps without Kubernetes reverse proxy с hostname на основе ветки обычно работает намного лучше, чем фиксированные host ports.
Команды также забывают про очистку. Ветка уже слита, а ее контейнеры, сети, образы и volume неделями остаются на Docker-хосте. Диск постепенно заполняется, а потом сборки начинают падать в самый неподходящий момент. Добавьте задачу остановки для каждого окружения и плановую задачу очистки как запасной вариант, потому что люди что-то упускают, а pipeline иногда ломается.
Секреты заслуживают того же внимания. Preview apps никогда не должны загружать продакшен-API-ключи, настоящие платежные данные или рабочие настройки почты. Используйте отдельный набор секретов с жесткими ограничениями. Если кто-то случайно откроет превью наружу, пусть это будет маленькая проблема, а не инцидент безопасности.
Плановые задачи создают побочные эффекты, которые легко пропустить. Review app может выглядеть безобидно в браузере, пока cron job в фоне отправляет письма, импортирует данные или вызывает внешние API. Одна ветка может завалить почтовый ящик или создать мусорные записи в другой системе, прежде чем это кто-то заметит.
Простая схема убирает большую часть этих проблем:
- Генерируйте имена из slug ветки или ID merge request для контейнеров, volume и баз данных.
- Пропускайте каждую ветку через один proxy вместо фиксированных портов хоста.
- Добавьте явную задачу остановки и ночную задачу prune.
- Используйте только secret для preview с низкими правами.
- Отключите cron jobs, workers, исходящую почту и webhooks, если они не нужны для теста.
Если review app легко создать, его должно быть так же легко удалить. Именно это делает тестирование веток чистым, а Docker-хост — пригодным для работы.
Быстрые проверки и следующие шаги
Превью-приложение полезно только тогда, когда ему можно доверять. Прежде чем команда начнет каждый день использовать GitLab preview apps without Kubernetes, проверьте процесс на одной свежей ветке и на одной ветке, которую только что слили.
Оставьте проверки простыми:
- Откройте превью в браузере на компьютере, затем уменьшите окно до размера телефона или проверьте на реальном телефоне. Ищите сломанные макеты, скрытые кнопки и медленную первую загрузку.
- Создайте одну тестовую запись, отредактируйте ее и удалите. Этот путь быстро ловит много проблем ветки, особенно плохие миграции, сломанные формы и отсутствующие права.
- Посмотрите на статус контейнера, свежие логи и использование диска на Docker-хосте.
- Слейте или закройте ветку и подтвердите, что задача остановки удаляет контейнер, сеть и все временные данные.
- Повторите тот же процесс еще на одной ветке. Если второй запуск оставляет хост чистым, схема, скорее всего, надежная.
Делайте проверку небольшой. Product и QA не нужен полный регрессионный прогон на каждой ветке. Им нужна достаточная уверенность, чтобы сказать: «Да, эта ветка ведет себя как заявленная функция» или «Нет, отправьте ее обратно».
Еще полезно неделю отслеживать два числа: сколько времени нужно, чтобы превью появилось, и сколько места на диске оставляют старые превью. Если одна ветка запускается за 90 секунд, а другая — за 12 минут, проблема обычно в сборке образа, шаге подготовки данных или задаче очистки.
Следующий шаг прост. Выберите одну активную функцию, прогоните процесс с реальными коллегами и исправьте шероховатости, которые всплывут в первые дни. Обычно именно тогда процесс тестирования веток перестает быть теорией и начинает приносить пользу.
Если вашей команде нужна помощь с аккуратной настройкой, Oleg Sotnikov на oleg.is работает со стартапами и небольшими компаниями по GitLab, Docker, CI/CD и компактной инфраструктуре. Такая внешняя проверка бывает полезна, когда вам нужны превью-приложения, которые остаются простыми, а не превращаются еще в одну систему, за которой надо присматривать.
Часто задаваемые вопросы
Почему одна общая staging-среда — это проблема?
Потому что общая staging-среда смешивает несвязанные изменения. QA, product и разработчики перестают смотреть на одну и ту же сборку, а отчеты об ошибках превращаются в угадайку.
Нужен ли мне Kubernetes, чтобы запускать GitLab preview apps?
Нет. GitLab может создавать превью-приложения с обычными CI-задачами, Docker-хостом и задачей остановки. Такая схема дает каждой merge request свою временную среду без кластера.
Что сначала настроить на Docker-хосте?
Сначала подготовьте отдельный Docker-хост с запасом RAM, CPU и диска для нескольких превью одновременно. Добавьте Docker, reverse proxy, если нужны субдомены, и отдельное место для логов и временных данных.
Как GitLab привязывает каждое превью к нужной ветке?
GitLab должен использовать по одному имени окружения на каждый merge request, например review/482, и обновлять это же окружение при каждом новом коммите. Так URL, имя контейнера и очистка будут привязаны к одной ветке.
Нужно ли каждому превью-приложению отдельную базу данных?
Да, большинству команд стоит дать каждому превью свою небольшую базу данных или схему. Общие данные быстро приводят к конфликтам, особенно когда одна ветка меняет таблицы или тестовые записи.
Как проще всего дать каждому превью-приложению свой URL?
Обычно проще всего использовать отдельный субдомен для каждого merge request, например mr-482.preview.example.com. Его легко запомнить, открыть из merge request и тестировать одну ветку без проверки портов.
Что должен удалять cleanup job?
Удаляйте все, что создала эта ветка. Остановите контейнер приложения, удалите временные volume или базу данных, уберите кастомные сети, очистите правила proxy и отметьте окружение как остановленное в GitLab.
Как долго должно быть доступно превью-приложение?
Для многих команд хорошо работает срок от одного до трех дней. Этого достаточно, чтобы product и QA успели проверить ветку, но старые превью не будут неделями висеть на сервере.
Какие ошибки чаще всего ломают preview apps?
Чаще всего команды спотыкаются о общие базы данных, фиксированные порты на хосте, забытый cleanup и живые секреты. Реальную почту, платежи, webhooks и cron jobs лучше отключать, если тесту они не нужны.
Когда небольшой команде стоит попросить помощи с такой настройкой?
Обращайтесь за внешней помощью, если превью долго запускаются, диск постоянно забивается, очистка падает или команда снова и снова тестирует не ту сборку. Короткий аудит GitLab, Docker, CI/CD и правил именования потом экономит много времени.


