GitLab merge trains vs protected branches на практике
Merge trains и protected branches в GitLab: сравните время ожидания, ребейзы и уверенность в релизе, чтобы выбрать более простую схему правил для команды.
Содержание
Почему этот выбор тормозит поставку
Команды обычно чувствуют эту проблему раньше, чем могут назвать её словами. Изменение уже одобрили, CI прошёл, никто не возражает, но оно всё равно стоит на месте. Запускается ещё один pipeline. Ещё одна ветка обгоняет его. Кто-то просит сделать ребейз. К тому моменту, как код доходит до main, команда уже потратила больше сил на ожидание, чем на саму работу.
Именно поэтому выбор между merge trains и protected branches важнее, чем кажется. На бумаге оба варианта выглядят как меры безопасности. На практике они определяют, как быстро одобренная работа движется дальше, как часто разработчикам приходится возвращаться к одной и той же ветке и насколько команда доверяет каждому релизу.
Когда поставка замедляется, многие команды пытаются добавить ещё больше правил ревью. Два approval превращаются в три. Добавляется отдельный ответственный для критичных путей. Накручиваются дополнительные status checks. Иногда это помогает. Но часто это лишь маскирует проблему процесса. Если работа ждёт потому, что ветки постоянно устаревают, или потому, что CI занимает 40 минут, ещё одно правило не уберёт узкое место. Оно просто сделает очередь длиннее.
Обычно цена проявляется в трёх местах:
- Время в очереди — одобренный код ждёт за другими уже одобренными изменениями.
- Лишние ребейзы — люди снова и снова обновляют ветки только ради правил ветки.
- Риск релиза — команда мержит код с меньшей уверенностью в том, как он работает вместе.
Protected branches в основном контролируют, кто может пушить, кто может мержить и какие проверки должны пройти. Это защитные ограждения. Merge trains делают другое. Они управляют порядком изменений и проверяют объединённый результат ещё до того, как main двинется дальше.
Поэтому вопрос не в том, какая схема выглядит строже. Вопрос в том, какая из них защищает main, не замедляя каждый merge.
Для загруженной команды разница очень ощутима. Это может означать, что пять небольших изменений попадут в ветку до обеда, или что те же пять изменений весь день будут метаться между approvals, ребейзами и истёкшими pipeline.
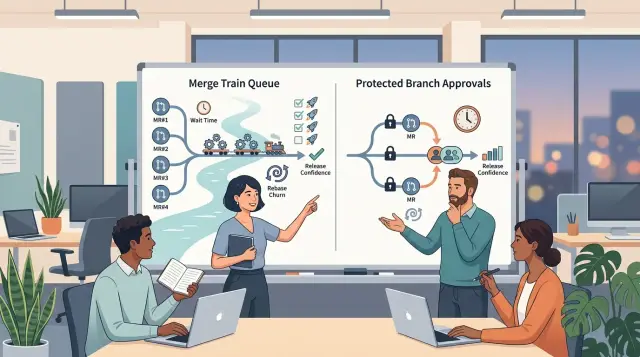
Что merge trains меняют в повседневной работе
Merge train превращает мерджи в очередь. После approval merge request не попадает сразу в целевую ветку. GitLab ставит его в линию и проверяет в том порядке, в котором люди в неё вошли.
Этот порядок важнее, чем многие ожидают. GitLab тестирует каждое изменение так, как будто все ранее одобренные изменения уже вмержены, поэтому pipeline отражает состояние ветки, которое вы вот-вот получите, а не состояние часовой давности.
Обычный ежедневный поток простой. Разработчик получает approval, GitLab добавляет merge request в train, CI запускается с учётом изменений, которые уже стоят впереди в очереди, и GitLab мержит элементы по порядку, если проверки успешны. Если один элемент падает, остальные ждут или запускаются заново.
Это быстро меняет привычки команды. Люди перестают соревноваться, кто успеет вмержить раньше другого. Они видят меньше сюрпризов в последний момент, потому что train ловит много конфликтов и проблем в объединённых тестах ещё до того, как код попадёт в ветку. Для загруженной продуктовой команды это сильно сокращает шумные моменты в духе «почему main только что сломался?».
Но есть и компромисс: ожидание становится заметнее. Ветка, которая раньше принимала одобренные изменения сразу, теперь заставляет людей стоять в очереди за чужой работой. В спокойные часы это почти не чувствуется. В загруженные часы даже небольшие merge requests могут накапливаться, если каждому нужен полный pipeline.
Именно поэтому merge trains и protected branches так сильно отличаются в реальной жизни. Protected branches в основном контролируют, кто может мержить и по каким правилам. Merge trains меняют ритм дня. Они добавляют порядок, более реалистичный CI и большую уверенность ближе к моменту мерджа, но при этом делают время ожидания частью поставки.
Что на самом деле контролируют protected branches
Protected branch — это gate на целевой ветке, а не система управления трафиком для изменений, которые ждут мерджа. Он говорит GitLab, кто может менять эту ветку и что должно произойти до того, как merge пройдёт.
На практике protected branches обычно блокируют несколько вещей: прямые pushes в ветку, force-push, который переписывает историю, мерджи без достаточного количества approvals и мерджи, если обязательные проверки не прошли. Они также могут ограничивать, кто имеет право обходить эти правила.
Это важно, потому что снижает количество ненужного ущерба. Один поспешный direct push может сломать default branch для всех. Protected branch уменьшает этот риск, заставляя изменения проходить одним и тем же путём.
Approvals и status checks делают основную ежедневную работу. GitLab может требовать одного или нескольких reviewers, успешный pipeline, закрытые обсуждения и approval от code owner перед мерджем. Эти правила дают команде понятный минимальный порог качества.
Проблема начинается, когда команда добавляет всё больше и больше gates каждый раз, когда что-то пошло не так один раз. Простое исправление, которое должно занимать десять минут, в итоге может ждать двух approvals, длинный pipeline, проверку на устаревшую ветку и ручной шаг релиза. Ветка остаётся безопасной, но сам мердж начинает ощущаться тяжёлым.
Вот почему protected branches создают дисциплину, но не поток. Они контролируют права и политику. Они не определяют порядок мерджа и не предотвращают столкновение двух корректных merge requests, если оба нацелены на одну и ту же ветку.
Если три разработчика открыли merge requests одновременно, одна только защита ветки не уберёт проблему с таймингом. Один request вмержился, ветка сдвинулась, а два других могут потребовать ребейз или ещё один прогон pipeline. Время ожидания растёт, хотя каждое правило сработало ровно так, как было задумано.
Protected branches хорошо отвечают на один вопрос: «Можно ли пропустить это изменение в ветку?» Они не отвечают на следующий: «Какой самый безболезненный способ провести несколько безопасных изменений подряд?» Именно на этот пробел и начинают смотреть команды, когда приходят к merge trains.
Откуда на самом деле берётся ожидание
Ожидание не начинается в CI. Оно начинается в тот момент, когда merge request уже одобрен, а потом стоит позади какой-то другой зависимости: другого мерджа, другого pipeline или другого ребейза.
С одними protected branches путь от approval до merge на бумаге выглядит коротким. Если ветка актуальна, а pipeline зелёный, merge происходит быстро. Проблема в том, что такая схема часто прячет задержку в ручной работе. Кому-то нужно сделать ребейз, заново запустить проверки и следить, не изменился ли target branch ещё раз до нажатия кнопки merge.
С merge trains задержку легче увидеть. После approval merge request встаёт в очередь. GitLab тестирует результат в порядке мерджа, поэтому ветку обычно не приходится постоянно обновлять вручную. Это часто сокращает лишнюю работу, но добавляет явное время ожидания, когда несколько одобренных изменений ждут своей очереди.
Более честное сравнение — не «что быстрее?», а «какая часть ожидания — это реальное время тестов, а какая просто простой?».
Реальное время тестов — это когда runner'ы собирают проект, проверяют его и запускают проверки перед релизом. Простой — это всё остальное: ожидание более ранних элементов в очереди, ожидание общего runner'а, ожидание разработчика, который должен сделать ребейз, или ожидание нового pipeline после того, как изменилась базовая ветка.
Во многих командах именно простой — основная проблема. Pipeline на 12 минут ощущается медленным, но три неудачных ребейза легко превращают это в 45 минут между approval и merge. Merge trains заменяют часть этого хаотичного ожидания более понятной очередью. Protected branches могут быть быстрее, если команда маленькая и мерджей немного.
Размер команды быстро меняет расчёт. В команде из двух-трёх активных разработчиков часто достаточно protected branches и короткого pipeline. В команде из десяти человек, которые целый день вмерживают изменения, будет ощущаться каждое обновление ветки. Чем длиннее pipeline, тем дороже каждый перезапуск. Именно здесь merge trains часто начинают приносить пользу.
Перед тем как менять правила, соберите данные за одну неделю по merge request'ам:
- время от approval до merge
- длительность pipeline на один merge request
- минуты, проведённые в очереди
- как часто разработчики делают ребейз или перезапускают pipeline
- сколько одобренных merge request'ов не успевают попасть в релиз в тот же день
Эта неделя расскажет больше, чем любой спор. Если основная задержка связана с перезапусками и дрейфом ветки, merge trains, скорее всего, помогут. Если большинство одобренных изменений мержится быстро и очередь почти пустая, более строгие правила ветки, вероятно, добавят лишнее трение.
Как выглядит лишняя работа с ребейзами
Rebase churn — это повторяющаяся работа по обновлению одного и того же merge request только ради того, чтобы он оставался пригодным к мерджу. Простой пример выглядит так: Мия открывает merge request в понедельник, во вторник вмерживаются ещё две ветки, а к среде GitLab говорит, что её ветка отстаёт от main. Она делает ребейз, снова пушит, снова ждёт CI и иногда исправляет конфликт, который вообще не связан с её фичей.
Один-два раза это кажется нормальным. Когда это происходит каждый день, время утекает маленькими, раздражающими кусками.
Цена ложится не только на автора. Reviewers тоже вынуждены возвращаться к работе. Ребейз может заново запустить pipeline, сбросить approvals или заставить людей ещё раз быстро просмотреть весь diff, чтобы проверить, не проскочило ли что-то странное. Даже если код почти не изменился, поток ревью ломается.
Именно поэтому сильнее всего страдают long-lived merge requests. Чем дольше открыта ветка, тем больше другой работы уходит вперёд неё. Небольшое исправление бага, которое спокойно вмержилось бы за два часа, через несколько дней может превратиться в три раунда ребейзов. Команды часто обвиняют разработчика, но ветка обычно оставалась открытой потому, что ревью, тестирование или изменение приоритетов замедлили процесс.
Protected branches часто перекладывают эту боль обратно на автора. Если ветка должна быть актуальной перед мерджем, автор делает ребейз и повторно запускает pipeline до тех пор, пока ветка не начнёт соответствовать правилу. Ветка остаётся чистой, но команда платит за эту чистоту лишними прерываниями.
Merge trains снимают часть этой нагрузки с автора. После approval GitLab может тестировать изменения по порядку очереди на основе самой свежей целевой ветки и элементов перед ними. Во многих случаях это сокращает ручные ребейзы, особенно в загруженных репозиториях. Полностью churn это не убирает. Если в ветке есть реальные конфликты или она слишком долго висит до approval, кому-то всё равно придётся её исправить. Но ежедневный шум обычно снижается, а reviewers меньше возвращаются к уже завершённой работе.
Как каждый вариант влияет на уверенность в релизе
Уверенность в релизе начинается с простого вопроса: какой именно путь кода тестируется pipeline'ом перед выпуском?
Это важнее, чем ещё один approval или более жёсткое ограничение прав. Protected branches дают контроль над процессом. Они решают, кто может пушить, кто может мержить и какие проверки должны пройти. Это помогает предотвратить небрежные изменения, но не всегда доказывает, что финальный код в целевой ветке — это тот же код, который только что был протестирован.
Этот разрыв легко не заметить. Два merge request'а могут пройти проверку по отдельности, а потом сломаться после объединения, потому что целевая ветка изменилась между запусками. Исправление для биллинга и уборка конфигурации могут казаться безопасными по отдельности, но итог после мерджа всё равно может не запуститься.
Merge trains повышают уверенность по-другому. Они тестируют результат очереди на merge, а не только исходную ветку. Это значит, что pipeline видит код гораздо ближе к тому, что реально получат пользователи. Возможно, придётся ждать дольше, но зелёный pipeline тогда значит больше, потому что он охватывает итоговое объединённое состояние.
Жёсткие правила ветки и очередные интеграционные тесты отвечают на разные вопросы. Правила спрашивают: «Следовала ли команда процессу?» Merge train testing спрашивает: «Работает ли этот конкретный набор изменений вместе?» Если сбои появляются уже после мерджа, второй вопрос обычно важнее.
Быстрый способ оценить компромисс:
- Если ваша default branch меняется быстро, проверка итогового merged result даёт больше уверенности.
- Если изменения часто затрагивают одни и те же файлы, одни лишь protected branches оставляют больше места для сюрпризов.
- Если pipeline нестабилен, merge trains тоже могут вводить в заблуждение, потому что случайные зелёные прогоны мало что доказывают.
- Если команда выпускает маленькие изолированные изменения и ветка остаётся спокойной, protected branches может быть достаточно.
Уверенность в релизе часто падает даже тогда, когда на бумаге все правила выглядят строгими. Это происходит, когда branch pipelines запускаются на более старой целевой ветке, когда обязательные jobs пропускаются на merge commits или когда reviewers одобряют код, который никто не тестировал в его финальном виде.
Если проблемы появляются уже после мерджа, дополнительные правила ревью обычно не помогают. Обычно помогает тестирование итогового результата слияния.
Простой пример из загруженной команды
Представьте девять разработчиков, которые работают над одним продуктом, а main меняется часто. Небольшие исправления попадают в ветку каждые 20–30 минут. К 9:30 утра уже три merge request'а одобрены и зелёные: у Анны — исправление биллинга, у Бена — чистка API, у Хлои — патч интерфейса.
С одними только protected branches правила выглядят строгими. Никто не может пушить прямо в main, CI должен пройти, и два reviewers должны одобрить изменения. Всё звучит безопасно, но утро всё равно становится беспорядочным.
Анна мержится первой в 9:35. Бен пытается вмержиться в 9:40, но его ветка уже отстаёт от main. GitLab просит его сделать ребейз. Он ребейзится, пушит снова и запускает ещё один pipeline. Команда также требует нового approval после свежих коммитов, поэтому reviewer должен посмотреть merge request ещё раз, хотя Бен всего лишь обновил ветку.
Пока Бен ждёт, с Хлоей происходит то же самое. Мердж Анны изменил main, затем ребейз Бена изменил hash его коммита. Теперь ребейзится Хлоя, снова запускает тесты и просит ещё одно одобрение. Ничего не сломано, но команда теряет время на повторные обновления ветки. Reviewers начинают просто машинально подтверждать ребейзы, потому что код они уже видели. Это снижает доверие, а не повышает его.
Здесь разница становится совсем конкретной. Protected branches контролируют, кто может мержить и какие правила должны пройти. Они не останавливают очередь от постоянного сдвига под ногами у всех.
Теперь возьмём те же три merge request'а и поставим их в merge train. Анна идёт первой, затем Бен, затем Хлоя. Бен и Хлоя ждут дольше в начале, потому что GitLab тестирует их по порядку на основе актуального состояния train. Никто не пытается срочно нажать merge раньше остальных. Никто не делает ручной ребейз только потому, что несколько минут назад вмержилось ещё одно одобренное изменение.
Train добавляет ожидание, и это может раздражать. Бен может ждать 25 минут вместо 5. Хлоя — 40. Но команда получает взамен полезную вещь: меньше сюрпризов в последний момент на main, меньше запросов на новые approvals и более ясный ответ на вопрос: «Что именно CI проверил перед тем, как это попало в production?»
На ветке, которая меняется всё утро, такой компромисс часто лучше, чем ещё одно правило ревью.
Как принять решение шаг за шагом
Добавить ещё одно правило ревью кажется безопасным, но чаще всего это лечит симптом, а не причину. Более удачный выбор начинается с простого понимания того, что именно тормозит команду сейчас.
Сформулируйте главную боль одной простой фразой. Пусть она будет конкретной. «Одобренные merge request'ы ждут по 6 часов до мерджа» — это полезно. «Наш процесс кажется запутанным» — нет.
Затем посмотрите на недавние merge request'ы и опирайтесь на цифры, а не на догадки:
- Измерьте время от финального approval до фактического мерджа для последних 15–20 merge request'ов.
- Посчитайте, сколько раз авторам приходилось делать ребейз уже после начала ревью.
- Посмотрите на упавшие релизы за последние две недели и задайте один прямой вопрос: они сломались потому, что отдельные изменения работали по отдельности, но не вместе?
Если проблема с объединением изменений встречается часто, merge trains могут помочь сильнее, чем более жёсткие protected branches. Если релизы падают потому, что тесты слабые, шаги деплоя ручные или approvals занимают слишком много времени, одна только защита веток мало что исправит.
Выбор становится гораздо менее абстрактным, когда смотреть на него так. Merge trains помогают, когда ветка меняется быстро и одобренная работа устаревает до мерджа. Protected branches помогают, когда команде нужны жёсткие ограничения на то, кто может мержить, когда это можно делать и какие проверки должны пройти сначала.
Небольшая команда обычно может начать с меньшего изменения. Если ребейзы накапливаются, а люди постоянно перепроверяют один и тот же код, сначала попробуйте merge trains. Если мерджи происходят слишком свободно, а релизы уходят без нужных проверок, сначала ужесточите правила protected branches.
Дайте изменению две недели. Потом посмотрите на три числа: медианное время от approval до merge, количество ребейзов на один merge request и число релизных сбоев после мерджа. Если улучшилось только одно число, копайте дальше. Многие команды выясняют, что ожидание создавал не процесс ревью и не правила веток, а медленный CI.
И это важный момент. Если pipeline занимает 40 минут, никакая политика не сделает мерджи быстрыми.
Ошибки, которые делают неудобными оба варианта
Команды часто реагируют на запутанную очередь мерджей добавлением ещё одного правила approval. Это кажется безопасным, но обычно скрывает настоящую проблему. Если ревью уже занимают два часа, а pipeline — 40 минут, ещё одно approval не ускорит delivery.
Сначала измерьте задержку, а потом меняйте политику. Посмотрите на время, за которое ревью подхватывают, длительность CI, нестабильные jobs и то, как часто люди ребейзят одну и ту же ветку. Большинство команд ошибается, когда пропускает этот шаг.
Ещё одна распространённая ошибка — винить разработчиков в медленных мерджах, когда весь ущерб наносит дизайн pipeline. Если каждое изменение заново собирает одни и те же images, ждёт занятых runner'ов и прогоняет весь набор тестов, люди будут сидеть и ждать, как бы аккуратно они ни работали. Медленный не команда, а процесс.
Это часто всплывает в спорах о merge trains и protected branches. Команды обсуждают правила веток, хотя реальное узкое место — pipeline, который слишком долго работает для маленьких изменений.
Медленные end-to-end тесты полезны, когда риск действительно велик. Но они становятся тяжёлыми, если запускать их на каждую мелкую опечатку, обновление текста или крошечный рефакторинг. Загруженная команда платит за такое решение более длинными очередями, большим количеством ребейзов и большим числом устаревших веток.
Protected branches создают другую ошибку. Они могут запрещать прямые пуши и заставлять проходить ревью, но они не заменяют интеграционные тесты. Два чистых, одобренных изменения всё равно могут сломать друг друга после мерджа. Защита ветки контролирует, кто может мержить. Она не доказывает, что объединённый код работает.
Старые правила — это ещё один тихий налог. Команды продолжают держать старое число approvals, проверки ветки или правила именования задолго после того, как пропала исходная причина. Если никто не может объяснить правило одним предложением, его, скорее всего, стоит пересмотреть.
Помогает короткий аудит:
- Отслеживайте медианное время от готовности к ревью до мерджа.
- Считайте ребейзы на каждую ветку.
- Разделяйте нестабильные падения и реальные ошибки.
- Составьте список правил, которые люди обходят или на которые жалуются.
- Уберите одно устаревшее правило и сравните следующие две недели.
Боль обычно начинается тогда, когда команда накладывает правила поверх медленного CI и называет это уверенностью в релизе. Сначала приведите в порядок pipeline, а потом решайте, сколько контроля вам всё ещё нужно.
Быстрые проверки и следующие шаги
Прежде чем добавлять ещё одно правило ревью, проверьте, где ваша команда действительно теряет время. Одни команды простаивают в длинных очередях мерджей. Другие тратят те же часы на ребейзы, исправление конфликтов и повторные прогоны CI после каждого мелкого изменения на загруженной ветке. Понаблюдайте за обоими сценариями одну неделю. Более крупный источник задержки должен получить внимание первым.
Обычно это самый быстрый способ понять, какая схема лучше подходит вашей команде. Если время в очереди небольшое, но разработчики весь день делают ребейзы, merge trains могут помочь. Если ребейзы редки, но изменения простаивают в ожидании свободной мощности train, дополнительные правила только ещё сильнее замедлят поставку.
Затем посмотрите на pipeline. CI тестирует финальный слитый результат или только каждую ветку по отдельности? Если pipeline никогда не проверяет именно тот код, который попадёт в default branch, уверенность в релизе ниже, чем показывают зелёные галочки. Команды постоянно упускают это из виду и часто пытаются решить проблему дополнительными approvals вместо того, чтобы исправить путь тестирования.
Оставляйте только те правила, которые блокируют реальный сценарий сбоя. Если одно approval ловит рискованные изменения схемы, оставьте его. Если правило существует только потому, что никто не хочет его убрать, уберите его. Процесс имеет свойство разрастаться сам по себе, и каждому лишнему gate нужна причина.
Перед изменением схемы проверьте такие вещи:
- Измерьте время очереди и время ребейзов по недавним merge request'ам.
- Убедитесь, что CI проходит на объединённом результате до релиза.
- Уберите одно правило, которое больше не предотвращает конкретный сбой.
- Опишите одно правило для срочных исправлений с понятными владельцами и ограничениями на обход.
- Пересмотрите поток после следующей релизной недели или production-инцидента.
Это правило для срочных исправлений важнее, чем многие ожидают. Когда что-то ломается, люди всё равно будут делать исключения. Записанное правило делает исключение маленьким, быстрым и предсказуемым.
Если вашей команде нужен внешний разбор GitLab-потока, CI и рисков релиза, Oleg Sotnikov на oleg.is занимается такой работой как Fractional CTO и startup advisor. Он помогает небольшим и средним командам улучшать delivery, инфраструктуру и автоматизацию без лишнего процесса ради процесса.
Часто задаваемые вопросы
Когда лучше выбрать merge trains вместо protected branches?
Используйте merge trains, когда уже одобренная работа часто устаревает до мерджа. Они особенно помогают на загруженных ветках, где несколько человек мержат изменения в течение дня, а CI работает достаточно долго, чтобы ребейзы начали накапливаться.
Оставайтесь на одних protected branches, если команда небольшая, мерджи случаются редко, и одобренные изменения обычно доходят до ветки без дополнительных переделок.
Merge trains делают мерджи медленнее?
Обычно да, но в более понятной форме. Merge trains превращают скрытое ожидание в видимую очередь, потому что GitLab тестирует изменения по порядку до того, как двинуть main.
Часто это ожидание заменяет более хаотичную задержку из-за ручных ребейзов, повторных запусков pipeline и новых approvals после изменения ветки.
Почему одобренный код всё равно ждёт при protected branches?
Protected branches отвечают за то, кто может мержить и какие проверки должны пройти. Они не управляют порядком уже одобренных изменений, поэтому один мердж может сразу сделать следующую ветку устаревшей.
Из-за этого появляется простое ожидание после approval, даже когда все правила работают именно так, как задумано.
Merge trains уменьшают количество ребейзов?
Во многих командах да. После approval merge trains проверяют изменения с учётом самого свежего состояния очереди, поэтому авторам приходится реже вручную обновлять ветку.
Но они не убирают реальные конфликты. Если два изменения мешают друг другу, кому-то всё равно придётся исправить код.
Дают ли protected branches надёжную уверенность в релизе?
Не сами по себе. Protected branches запрещают прямые пуши, заставляют проходить ревью и требуют зелёных проверок, но при этом они всё ещё могут пропустить две по отдельности безопасные изменения, которые ломаются после объединения.
Если вам нужна большая уверенность перед релизом, тестируйте именно слитый результат, а не каждую ветку по отдельности.
Какая команда действительно выигрывает от merge trains?
Команде из двух или трёх разработчиков часто достаточно protected branches и короткого pipeline, чтобы всё оставалось простым. Проблемы обычно начинаются, когда в течение дня много людей мерджат изменения в одну и ту же ветку.
Если main меняется каждые 20–30 минут, merge trains начинают окупаться.
Стоит ли добавлять больше approvals, если `main` продолжает ломаться?
Нет. Дополнительные approvals помогают только тогда, когда проблема в качестве ревью или в ответственности за изменения. Если main ломается потому, что отдельные изменения не работают вместе, лишние approvals только добавляют ожидание.
Сначала исправьте путь тестирования, а потом оставьте только те правила, которые блокируют реальные сбои.
Что измерить перед изменением правил в GitLab?
Начните с трёх чисел: время от финального approval до мерджа, количество ребейзов на один merge request и число релизных сбоев после мерджа. Эти показатели покажут, где команда теряет время: в очереди, в churn веток или уже после релиза.
Одна неделя реальных данных лучше долгих споров.
Может ли медленный CI сделать неудобными оба варианта?
Абсолютно. Pipeline на 40 минут делает тяжёлым любой процесс мерджа. Если на каждый маленький change уходит полный набор тестов, люди будут ждать независимо от того, как настроены правила веток.
Сократите лишние jobs, почините нестабильные тесты и уменьшите ожидание runner'ов, прежде чем винить процесс.
Как нам обрабатывать срочные хотфиксы с такими правилами?
Напишите одно небольшое правило заранее. Укажите, кто может обойти обычный поток, когда это допустимо и какая проверка должна быть после того, как исправление уже вмержено.
Так исключение останется быстрым, но не превратит каждый инцидент в спор о процессе.


