GitLab dependency proxy для более быстрых Docker-сборок в командах
GitLab dependency proxy помогает небольшим командам сократить сбои при pull Docker-образов, смягчить rate limits и ускорить повторные сборки без сложной настройки.
Содержание
Почему Docker-сборки тормозят и падают
Большинство проблем с Docker-сборками начинаются ещё до запуска вашего кода. Задаче сначала нужен базовый образ, и обычно этот образ берётся из публичного registry. Если этот pull зависает, весь pipeline ждёт.
Публичные registry начинают тормозить в самый неподходящий момент. Они также могут вводить rate limits для загруженных команд, возвращать временные ошибки или просто не отвечать вовремя. Сборка может упасть, даже если с Dockerfile всё в порядке.
С новыми раннерами GitLab CI это становится ещё заметнее. Многие команды используют краткоживущие раннеры, которые запускаются с нуля для каждой задачи или небольшой группы задач. Это удобно и аккуратно, но означает, что они начинают с пустым image cache и снова и снова скачивают одни и те же слои.
Один медленный базовый образ может задержать весь pipeline. Если несколько сервисов собираются на одном и том же образе, одна задержка при pull может одновременно заблокировать test jobs, review apps и release builds. Вы меняете три строки в коде приложения, а команда всё равно ждёт, пока загрузятся слои node, python или ubuntu.
Проблемы с cold cache легко не заметить, потому что они выглядят случайными. Один pipeline завершается за четыре минуты. Следующий занимает двенадцать, хотя в приложении никто ничего не менял. Разница часто проста: у одного раннера нужные слои уже были, а у другого — нет.
Небольшие команды чувствуют это особенно быстро. У них обычно меньше раннеров, меньше запасной мощности и нет человека, который весь день смотрит за CI. Когда публичный registry тормозит или срабатывают Docker pull limits, один человек может потерять 20 минут, а вся команда — полдня.
Проблема не только в скорости. Сбои registry делают сборки менее предсказуемыми, а непредсказуемым сборкам сложнее доверять. Команды начинают перезапускать задачи, гадать, что исправить, или без нужды откладывать релизы.
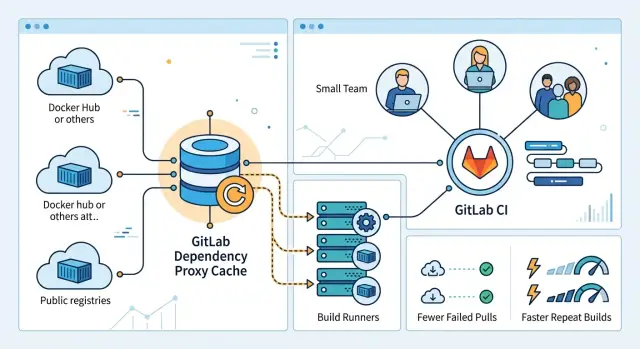
Когда Docker-сборки кажутся ненадёжными, узким местом часто оказывается не сам Docker. Проблема в доставке образов. Поэтому GitLab dependency proxy особенно важен для компактных команд, которые полагаются на чистые, autoscaled GitLab CI runners.
Что делает dependency proxy
GitLab dependency proxy хранит локальные копии контейнерных образов, которые ваши CI jobs обычно скачивают из публичных registry. Когда runner запрашивает базовый образ вроде node, python или alpine, GitLab один раз забирает его из Docker Hub или другого upstream-источника и сохраняет копию внутри GitLab.
После первого pull последующие задачи могут брать тот же образ из cache, а не обращаться к публичному registry снова. В этом и есть вся польза. Ваши раннеры перестают повторять одну и ту же загрузку, а сборки обычно становятся быстрее и менее хрупкими.
Без такого cache каждый раннер сам общается с Docker Hub. Если пять задач стартуют примерно одновременно, все пять могут отдельно скачать один и тот же образ. Это тратит время, создаёт лишний внешний трафик и приближает вас к Docker pull limits. С proxy GitLab становится обычным источником для общих образов, и раннеры намного реже обращаются к публичному registry.
Ещё это даёт команде одно стабильное место для получения общих образов. Это полезнее, чем многим кажется. Shared runners, self-hosted runners и новые машины все обращаются к одному и тому же адресу GitLab, поэтому сборки ведут себя более одинаково в разных средах.
Если у upstream registry выдался неудачный час, cache может смягчить удар. Задачи всё ещё смогут брать образы, которые GitLab уже сохранил, даже если публичный registry медленный или нестабильный. Это не решает все сбои и не может закэшировать образ, который ещё никто не запрашивал. Но оно заметно снижает зависимость от внешних registry.
Проще всего представить это так: dependency proxy стоит между вашими раннерами и публичными registry образов. Он в основном нужен для базовых образов, которые pipeline используют каждый день, а не для образов, которые ваша команда сама собирает и публикует. Для небольших команд одно это изменение часто сокращает время ожидания и делает повторные сборки гораздо менее случайными.
Когда он помогает сильнее всего
GitLab dependency proxy особенно полезен, когда команда чаще начинает с нуля, чем кажется. Обычно это происходит с shared runners или краткоживущими раннерами. Они запускаются, выполняют задачу и исчезают с пустым локальным cache. Следующий pipeline снова скачивает те же слои, даже если ничего не изменилось.
Такой сценарий быстро становится дорогим. Команда может собирать пять сервисов в день, и все они основаны на одном и том же образе node, python или alpine. Без proxy каждый раннер снова идёт в публичный registry и повторяет ту же загрузку. С proxy перед ними GitLab хранит ближайшую копию, и раннеры берут образы оттуда.
Это особенно помогает, когда несколько проектов используют один и тот же базовый образ. Один проект прогревает cache, а следующий получает от этого пользу. Небольшие команды часто этого не замечают, потому что каждый репозиторий выглядит отдельным, но трафик образов обычно однообразный и повторяющийся.
Обычно разницу легче всего заметить, когда раннеры shared или часто пересоздаются, когда несколько pipeline каждый день тянут одни и те же базовые образы, когда Docker Hub rate limits останавливают задачи в случайные моменты или когда сбой в public registry тормозит работу сразу в нескольких репозиториях.
Rate limits — самая очевидная боль. Нет ничего раздражающего сильнее, чем сборка, которая падает только потому, что в этот день было слишком много pull-запросов. С кодом всё может быть в порядке, но pipeline всё равно останавливается. Proxy не отменяет все правила Docker Hub, но он сокращает количество обращений к Docker Hub на старте.
Сбои registry — вторая большая проблема. Если ваши сборки зависят от внешнего сервиса при каждом новом раннере, один сбой может заморозить сразу несколько проектов. С прогретым proxy cache многие задачи продолжают двигаться, потому что им больше не нужно забирать каждый слой из публичного источника.
Для небольших команд это особенно важно, потому что они сразу ощущают перебои. Если один заблокированный build может задержать релиз, то даже экономия 20–40 секунд на задачу и несколько случайных сбоев в неделю уже оправдывают такую настройку.
Включите его в GitLab
Начинайте на уровне группы, а не внутри одного проекта. GitLab dependency proxy привязан к группе, которой принадлежит проект, поэтому если репозиторий находится не в той группе, cache окажется не там, где нужно.
Сначала проверьте, что ваша GitLab-настройка поддерживает эту функцию. На GitLab.com посмотрите, входит ли она в тариф вашей группы. На self-hosted-инстансе администратору, возможно, придётся разрешить её, прежде чем кто-то в группе сможет включить proxy.
Настройка простая: откройте группу, в которой находится проект, найдите настройку dependency proxy, включите её и запомните prefix образа, который GitLab показывает для pull-запросов.
Это занимает минуту. А вот шаг, который обычно пропускают, — доступ.
Вашим раннерам нужны учётные данные, которые позволяют pull через proxy. Если ваши задачи уже проходят аутентификацию в registry через встроенный CI job token, возможно, всё уже в порядке. Если нет, создайте deploy token или другой групповой credential с нужными правами на registry и сохраните его в CI variables, чтобы все раннеры использовали один и тот же логин.
Первый тест лучше делать небольшим. Не меняйте все образы сразу во всех pipeline. Возьмите один образ, который команда тянет постоянно, например alpine, python или node, и сначала пропустите через proxy только его.
Небольшая команда может проверить это на одной загруженной задаче, которая запускается при каждом merge request. Если эта задача обычно берёт node:20 из Docker Hub, замените эту ссылку на путь группового proxy, запустите pipeline дважды и сравните шаг pull. Первый запуск заполнит cache. Второй покажет, могут ли раннеры чисто брать образ из GitLab, а не идти снова в публичный registry.
Если первый образ работает, расширяйте постепенно. Сначала возьмите базовые образы, которые встречаются в нескольких проектах, а потом переходите к более редким. Такой порядок даёт самый быстрый эффект и помогает раньше заметить ошибки авторизации, пока они не разошлись по всем Docker-задачам.
Обновите Docker-задачи
После включения GitLab dependency proxy прирост скорости появится только тогда, когда задачи перестанут брать образы напрямую из публичных registry. На практике это означает изменение путей к образам в .gitlab-ci.yml и в любом скрипте, где выполняется docker pull. Если задача всё ещё смотрит в Docker Hub, она всё равно будет ловить pull limits и случайные замедления.
Сначала проверьте три места: image, в котором запускается задача, все services, которые она поднимает, и любые ручные команды pull внутри скрипта. Эти ссылки должны использовать путь proxy вместо публичного пути к образу. Одной пропущенной строки достаточно, чтобы часть pipeline осталась cold.
Небольшие команды часто получают лучший результат, когда перестают использовать разные базовые образы в каждом репозитории. Выберите короткий общий набор и придерживайтесь его. Если веб-приложение, worker и API используют одни и те же несколько образов, GitLab CI runners чаще повторно используют cache слоёв.
Например, если два проекта собираются на одном и том же образе node и упаковываются в один и тот же образ alpine, второй pipeline обычно стартует из более тёплого cache. Первый запуск наполняет proxy. Следующий запуск — уже настоящий тест.
Не храните данные для входа в registry в репозитории. Сохраняйте имена пользователей, пароли и токены в masked CI variables, а затем выполняйте вход уже в ходе job. Так секреты не попадут в merge requests, и вам не придётся мучительно вращать учётные данные в закоммиченных файлах. Protected variables также помогают ограничить, кто может использовать production credentials.
Быстрой проверки достаточно. Запустите один pipeline после изменения пути, запустите тот же pipeline ещё раз без изменений образа, сравните время pull в логах задачи и убедитесь, что все pull теперь идут через proxy path.
Второй запуск должен заметно ускориться, если cache работает. Если этого не произошло, обычно случилось одно из двух: задача всё ещё берёт образ напрямую из публичного registry, или у команды слишком много тегов образов, и cache hit rate получается низким. Теги вроде latest часто только ухудшают ситуацию. Фиксированные версии менее эффектны, но cache с ними работает лучше.
Простой пример небольшой команды
Представьте команду из трёх человек, которая одновременно делает два продукта. Один разработчик отвечает за API, второй работает над web app, а третий чинит баги, выпускает релизы и закрывает то, что сломалось ночью. Это обычная маленькая команда: без лишней церемонии, без большого запаса времени и почти без терпения к медленному CI.
Оба проекта используют одни и те же базовые образы. API стартует с Node на Alpine. Web app тоже. На бумаге это должно хорошо кэшироваться. На практике их GitLab CI runners часто начинают понедельник с пустым image cache, поэтому первая волна pipeline снова пытается скачать те же слои.
Именно там и появляется боль. Запускается pipeline API. Через минуту стартует pipeline web app. Ещё через мгновение в очередь попадает hotfix-ветка. Все три задачи идут в публичный registry за одними и теми же слоями Node и Alpine. Если Docker Hub отвечает медленно, вся очередь растягивается. Если срабатывают pull limits, одна задача может упасть, хотя с кодом всё в порядке.
Для такой маленькой команды перерасход очевиден. Они не компилируют огромные бинарники и не гоняют гигантскую матрицу тестов. Они ждут повторных загрузок.
После того как они включают GitLab dependency proxy и переводят оба проекта на него, первый pipeline недели всё ещё делает первоначальную загрузку. Этот шаг никуда не исчезает. Но разница начинается сразу после этого. Следующие pipeline берут те же базовые слои из закэшированной копии внутри GitLab, а не снова спрашивают публичный registry.
Итог скучный, но в хорошем смысле. Поздние задачи перестают бороться за одни и те же загрузки образов. Сборка web app, которая раньше часто занимала восемь или девять минут, становится ближе к пяти. Задача API тоже сокращается на пару минут. И, что не менее важно, понедельник утром перестаёт казаться случайным.
Это не исправит каждую медленную сборку. Но это исправит одну упрямую проблему, которую многие команды терпят без причины: повторную загрузку одних и тех же базовых образов, когда два проекта строятся почти на одной и той же основе.
Ошибки, которые съедают cache
Большинство промахов cache связано с привычками, которые кажутся безобидными. Самая большая из них — использовать latest для базовых образов. Это выглядит просто, но скрывает изменения. Когда latest смещается, команда уже не понимает, замедлилась ли сборка из-за кода или из-за нового upstream-образа.
Закреплённый тег даёт гораздо больше повторного использования. Если вам нужны воспроизводимые сборки, фиксируйте digest. Тогда cache остаётся тёплым, пока вы сами не решите его обновить.
Слишком много одноразовых тегов создаёт другую проблему. Некоторые команды собирают или тянут образы с названиями веток, номерами задач или короткими commit SHA в каждом pipeline. Из-за этого каждый запуск выглядит уникальным, и proxy продолжает подтягивать слои, которые больше никому не понадобятся.
Более чистый подход — держать небольшой набор стабильных тегов базовых образов для общих задач, обновлять эти теги осознанно, а не на каждом commit, использовать уникальные теги для release artifacts, а не для общих баз сборки, и удалять старые шаблоны образов, которыми никто не пользуется.
Аутентификация тоже часто мешает. Если раннер не выполняет вход в GitLab dependency proxy, pull может завершиться ошибками, которые на первый взгляд не связаны с cache. Вы можете увидеть access denied, сообщения о rate limit или задачу, которая внезапно снова пытается брать образ из публичного registry.
Поэтому каждая задача, которая работает через proxy, должна сначала проходить вход, даже если вчера эта же задача работала. Небольшие команды часто упускают это из виду, потому что у одного раннера ещё старые учётные данные, а другой запускается с нуля и падает.
Хранилище — тихий убийца cache. Большие образы, которые вы используете редко, например стеки мобильных SDK или GPU toolchains, быстро съедают место на диске. Потом раннер удаляет полезные слои, чтобы освободить пространство, и ваши повседневные задачи снова становятся холодными.
Если только один pipeline использует огромный образ раз в неделю, не считайте его общим базовым образом. Вынесите его на отдельный раннер или ограничьте задачами, которым он действительно нужен. Команды, которые внимательно следят за дисковым пространством раннеров, обычно замечают это раньше. Те, кто этого не делает, потом удивляются, почему выигрыш в скорости исчез через несколько дней.
Скучное правило по тегам, надёжный шаг входа и немного дисциплины в хранении решают большую часть потерь cache.
Быстрые проверки после настройки
Зелёный pipeline ещё не доказывает, что всё работает хорошо. Команды часто включают GitLab dependency proxy, видят одну успешную сборку и думают, что задача теперь ходит через cache. Иногда это не так. Иногда тёплый раннер просто маскирует реальный результат.
Запустите один и тот же pipeline дважды без изменений. Сравнивайте не общее время job, а именно шаг загрузки образа. Если второй запуск почти не ускорился, задача может всё ещё тянуть образ прямо из публичного registry, либо образ меняется слишком часто и cache от него мало пользы.
Несколько проверок помогают поймать большинство ошибок:
- Повторите один pipeline и запишите время pull для обоих запусков.
- Запустите свежий раннер или очистите локальные Docker-образы, затем внимательно посмотрите на первый pull.
- Прочитайте лог job и убедитесь, что путь к образу указывает на proxy path, а не на прямой путь Docker Hub.
- Наблюдайте за использованием proxy storage примерно неделю, прежде чем раскатывать его на все проекты.
Тест со свежим раннером важнее, чем многим кажется. Раннер с локальными слоями может сделать любую настройку быстрой на вид. Новый раннер показывает реальное поведение, которое получает ваша команда при autoscaling, после cleanup jobs или когда раннер выходит из строя и GitLab CI runners заменяют его.
Проверка логов проста, но её легко пропустить. Если в одной точке задача всё ещё ссылается на старый путь registry, одного этого достаточно, чтобы запустить rate limits или сломаться во время registry outage. Одного прямого pull хватит, чтобы сборка стала казаться ненадёжной.
Небольшая команда может быстро заметить разницу. Допустим, базовый образ занимает 25 секунд при первом запуске и 4 секунды при втором. Это хороший знак. Если оба запуска по-прежнему занимают около 25 секунд, остановитесь и проверьте путь к образу, прежде чем расширять rollout.
Не раскатывайте proxy сразу на все репозитории. Дайте ему неделю. Посмотрите, сколько места он занимает, какие образы остаются горячими и не скапливаются ли старые теги. Такое короткое ожидание помогает избежать грязной уборки позже и показывает, действительно ли более быстрые сборки реальны, а не просто удачное совпадение для одного раннера.
Что делать дальше
Начните с малого. Выберите один проект, а затем сначала переведите через GitLab dependency proxy одну семью базовых образов. Alpine, Debian, Node, Python или Docker-in-Docker — частые варианты. Один аккуратный тест расскажет больше, чем одновременная смена всех pipeline.
Запишите, какими образами команда должна делиться. Список должен быть коротким и скучным. Если пять разработчиков и три GitLab CI runners тянут одни и те же базовые образы, им место в этом списке. Странные разовые образы обычно туда не входят.
Для первого шага достаточно простого плана:
- выберите один активный репозиторий
- выберите один или два базовых образа, которые используются в большинстве задач
- обновите путь к образу в CI
- запустите несколько pipeline и сравните время pull
- сразу отметьте любые проблемы с авторизацией или тегами
После этого настройте правила очистки, пока cache не превратился в хаос. Решите, кто отвечает за proxy-настройки, как часто команда пересматривает старые теги образов и когда перестать фиксировать образы, которыми больше никто не пользуется. Вам не нужна тяжёлая политика. Короткой заметки в документации команды достаточно, если ей действительно следуют.
Также полезно договориться о правилах именования и тегов. Если половина команды закрепляет точные digest, а другая половина продолжает использовать latest, cache становится шумным и его труднее анализировать. Выберите один подход для общих образов и придерживайтесь его.
Дайте настройке неделю или две, а потом посмотрите на реальные результаты. Проверьте холодные старты pipeline, неудачные pull-запросы и то, как часто раннеры обращаются к удалённым registry. Если сборки всё ещё кажутся медленными, proxy может быть не главной проблемой. Большие образы, слабое кэширование слоёв или слишком много новых раннеров часто мешают сильнее, чем люди ожидают.
Небольшие команды обычно получают лучший результат от простого плана: общие базовые образы, единые теги и один человек, который следит за гигиеной CI. Этого достаточно, чтобы более быстрые Docker-сборки стали нормой, а не удачей.
Если ваша настройка GitLab, Docker и раннеров всё ещё кажется расточительной, Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами как Fractional CTO, по self-hosted GitLab и lean CI/CD-настройкам. Короткий внешний аудит может сэкономить много проб и ошибок.


