Гибридный поиск с фильтрами для B2B-баз знаний
Узнайте, как гибридный поиск с фильтрами помогает B2B-базам знаний оставаться точными, сочетая ключевые слова, эмбеддинги и правила tenant без утечек.
Содержание
Почему поиск ломается в общих базах знаний
Общие базы знаний обычно ломаются предсказуемо и довольно буднично. Один поисковый блок должен одновременно обслуживать много аккаунтов, команд и уровней доступа. Именно здесь и начинаются проблемы.
Первая проблема — перетекание данных между аккаунтами. Пользователь ищет вопрос по биллингу, пункт договора или инструкцию по настройке, а система показывает документ из чужого аккаунта, потому что записи слишком похожи. В B2B-продукте это не мелкий баг. Один неверный результат может раскрыть приватные заметки, цены или внутренние рабочие документы.
Вторая проблема — несовпадение формулировок. Люди не ищут теми же словами, которыми писали авторы. Клиент вводит «как добавить вход через Google», а в документе написано «настроить SAML identity provider». Точное совпадение слов не находит такой вопрос, даже если ответ уже есть.
Потом AI-слой может сделать все еще хуже. Если retrieval игнорирует корпоративные права доступа, модель может прочитать документ, который пользователь не может открыть, и все равно процитировать его. Ответ выглядит уверенно. Пользователь переходит по ссылке и получает ошибку доступа. Это очень быстро вызывает ощущение халатности.
Простой пример из поддержки показывает, почему это важно. У одного аккаунта есть внутренняя заметка о неудачных повторных списаниях. У другого — публичная статья о том, как обновить платежные данные. Если поисковый стек смешивает tenant или откладывает фильтрацию до уровня интерфейса, ассистент может ответить по заметке другого аккаунта. Текст выглядит уместным, но он все равно неверный.
Именно поэтому одного только лексического поиска недостаточно, как недостаточно и одного лишь векторного поиска. Лексический поиск ловит точные фразы. Эмбеддинги ловят разговорный язык и близкий смысл. Tenant-aware retrieval держит оба метода в рамках реального доступа пользователя.
Доверие рушится быстрее, чем ожидает большинство команд. Люди обычно прощают медленный ответ. Но они не прощают ответ, который раскрывает данные, ссылается на скрытый контент или уводит в неправильную сторону. После этого агенты поддержки начинают все проверять вручную, а клиенты перестают пользоваться поиском, если у них нет другого выбора.
Цена плохого поиска по B2B-базе знаний выше, чем несколько пропущенных документов. Он приучает пользователей к мысли, что система не понимает, что принадлежит им, а что нет.
Что на практике означает гибридный поиск
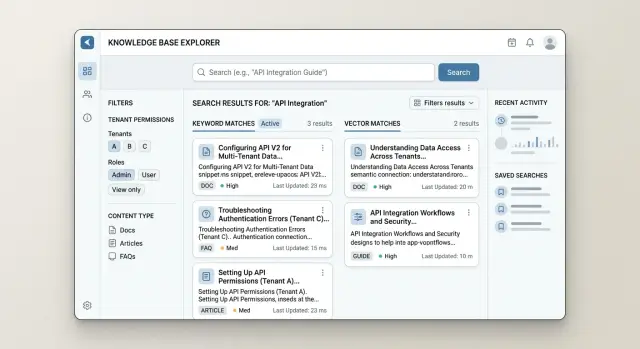
Хорошая система поиска по B2B-базе знаний делает две вещи одновременно. Она находит точные слова, которые ввел человек, и находит документы с тем же смыслом, даже если формулировка другая. Это и есть гибридный поиск с жесткими фильтрами.
Лексический поиск отвечает за точные совпадения. Если сотрудник поддержки вводит код ошибки, название флага функции или SKU продукта, поиск по словам обычно работает лучше всего. Такие запросы точные, и пользователь ожидает, что в топе будет результат с тем же текстом, который он ввел.
Эмбеддинги закрывают другую половину задачи. Люди редко ищут теми же словами, что и в документации. Пользователь может написать «не могу пригласить нового сотрудника», а в документе будет «сбой при добавлении участника команды». Векторный поиск способен связать эти идеи, даже если слова не совпадают буквально.
На практике не нужно выбирать что-то одно. Обычно используют оба метода и объединяют результаты в один ранжированный список. Простая модель ранжирования часто бывает достаточной, если она сочетает несколько понятных сигналов: лексический балл за точные термины, векторный балл за семантическое сходство, свежесть документа и небольшие бонусы за заголовки, FAQ или одобренные источники.
Фильтры — это не приятное дополнение. Это правила. Если документ принадлежит tenant A, пользователи из tenant B не должны получать его вообще, даже если он оказался внизу списка. То же самое касается роли, тарифа, региона и контента только для внутреннего использования. Когда фильтры срабатывают до финального ранжирования, система оценивает только документы, которые пользователь вправе читать.
Порядок здесь важнее, чем кажется многим командам. Если сначала ранжировать, а фильтровать потом, модель может потерять сильных разрешенных кандидатов и перейти к слабым. Хуже того, система ответов может процитировать или пересказать текст из документа, к которому вообще не должна была прикасаться.
Представьте двух клиентов в одном и том же портале поддержки, но с разными условиями договора и разными модулями продукта. Лексический поиск может найти правильную статью по биллингу, потому что она точно совпадает с термином из договора. Эмбеддинги могут найти инструкцию с другой формулировкой. Tenant- и role-фильтры удерживают оба результата в рамках допустимого доступа пользователя, а ранжирование решает, что окажется наверху.
Начните с модели данных
Если модель данных устроена неаккуратно, поиск ломается еще до того, как начинается ранжирование. Извлечение не может соблюдать правила, которых вы не сохранили, и не может угадать недостающие метаданные позже.
Назначьте каждому документу tenant ID. Дайте тот же tenant ID и каждому чанку. Не рассчитывайте на родительский файл во время запроса. Большинство B2B-систем ищут по чанкам, а не по целым документам, поэтому у каждого чанка должно быть достаточно информации, чтобы ответить на один простой вопрос: может ли этот пользователь его видеть?
То же самое касается ролей и групп. Выберите один формат и используйте его везде. Если один источник хранит роли как "admin", а другой — как "Admin,", у вас появятся утечки или ложные пропуски. Если один коннектор пишет данные через запятую, а другой — массивами, фильтры очень быстро станут хрупкими. Простая согласованность лучше, чем умное сопоставление.
Обычно достаточно небольшого набора полей: tenant_id, document_id, chunk_id, roles_allowed, groups_allowed, source_type, product_area, language и updated_at.
Когда вы делите документы на чанки, копируйте исходные метаданные в каждый чанк. Не копируйте только заголовок. Копируйте поля доступа, тип документа, метку продукта или команды и все остальное, что нужно для поиска. Если чанк 17 потеряет метаданные, он может обойти правила или исчезнуть там, где должен был совпасть.
Держите жесткие правила доступа отдельно от подсказок для ранжирования. Правила доступа отвечают только да или нет. Подсказки для ранжирования сортируют уже разрешенные результаты. Свежесть, тип документа и область продукта могут улучшить релевантность, но они никогда не должны расширять доступ.
Пример из поддержки хорошо это показывает. Допустим, одна компания хранит внутренний billing runbook и публичную инструкцию по настройке. В обоих документах есть упоминания invoice retries. Финансовый пользователь этого tenant увидит оба. Обычный пользователь должен видеть только публичную инструкцию. Если в чанке хранится только семантический текст, а не данные о tenant, роли и группе, эмбеддинги могут подтянуть billing runbook в ответ. Это уже не ошибка ранжирования. Это ошибка модели данных.
Гибридный поиск работает лучше всего, когда индекс содержит те же факты о правах доступа, которым уже доверяет ваше приложение.
Встраивайте фильтры в retrieval, а не только в интерфейс
Если пользователь не может открыть документ, retriever тоже не должен его видеть. Скрывать результаты только в интерфейсе слишком поздно. К этому моменту система уже могла оценить запрещенные чанки, подтянуть их в контекст и дать модели ответить на основе данных, которые пользователь не должен читать.
Именно здесь многие команды ошибаются. Они строят надежную проверку прав в приложении, а потом забывают, что у поиска есть свой путь. Лексический индекс, векторный индекс, reranker и генератор ответа должны использовать одни и те же правила.
Применяйте жесткие фильтры до оценки, когда это возможно. Tenant ID, аккаунт, регион, статус документа и группа доступа обычно легко проверяются и сразу отсекают большую часть плохих совпадений. Это дает сразу два преимущества: более безопасное извлечение и более чистое ранжирование, потому что оценщик сравнивает только те документы, которые пользователь может видеть.
В большинстве систем объект фильтра включает tenant или клиентский аккаунт, роль пользователя или принадлежность к группе, состояние документа — например, опубликован или архивирован, — а также область, такую как продукт, регион или рабочее пространство.
Поиск на уровне чанков добавляет еще одну ловушку. Многие системы хранят текст в чанках, но права доступа — на уровне родительского документа. Если фильтровать только чанки, можно не учесть правила, которые живут у родителя. Если фильтровать только родителей, устаревшие чанки все равно могут просочиться из старого индекса. Родитель и потомок должны каждый раз совпадать.
Оставляйте один и тот же объект фильтра на всем протяжении pipeline. Передавайте его в лексический поиск, векторный поиск, reranking и любой fallback search. Если вы используете query expansion или многошаговый retrieval, передавайте фильтр и туда. Одного пропущенного шага достаточно для утечки данных.
Тестирование должно включать запросы, которые почти совпадают с запрещенным контентом. Именно такие случаи находят реальные баги. Записывайте, почему система отвергла каждое совпадение: «не тот tenant», «архивный родительский документ» или «чанк не унаследовал доступ от родителя». Такой лог экономит часы, когда support спрашивает, почему результат не появился, и дает команде доказательство того, что права доступа сработали так, как задумано.
Соберите pipeline по шагам
У хорошего retrieval pipeline две задачи. Он должен находить самый релевантный текст и никогда не выходить за границы tenant или role. Если ломается хотя бы одна часть, ответ кажется неправильным, даже когда модель пишет гладкий текст.
В гибридном поиске порядок важен. Сначала применяйте правила доступа, держите набор кандидатов маленьким и передавайте в модель только разрешенный текст.
-
Начните с пользователя и запроса. Разберите вопрос, уберите очевидный шум и соберите фильтры из идентичности, tenant, роли, области продукта, статуса документа и языка. Часть фильтров может приходить из интерфейса, но большинство должно поступать из сессии или auth-слоя, чтобы пользователь не мог случайно изменить их.
-
Ищите только внутри разрешенного набора. Запустите лексический поиск по точным терминам, например названиям продуктов, ID тикетов, меткам политики и кодам ошибок. Одновременно запустите векторный поиск по смыслу, перефразированию и неаккуратному естественному языку. Оба поиска должны использовать одни и те же правила доступа.
-
Объедините наборы результатов в один ранжированный пул. Уберите дубли на уровне чанка или документа, а затем оставьте самые сильные кандидаты. Сначала хорошо работает простой метод: давайте лексическим совпадениям дополнительный вес за точные термины, а векторным совпадениям — право спасать релевантный контент, когда формулировка отличается.
-
Переранжируйте с коротким контекстом, который пользователь вправе видеть. Именно здесь команды часто делают плохой выбор. Они rerank-ят по сырым документам или включают скрытые поля, потому что так удобнее. Оставляйте вход reranker маленьким и чистым: заголовок, короткий фрагмент, метаданные и проверенные по доступу идентификаторы.
-
Генерируйте ответ только из одобренных фрагментов. Не отправляйте модели весь архив документов. Передавайте ограниченный набор чанков, просите цитаты или ссылки на фрагменты и говорите модели, что она должна признать незнание, если доказательств мало.
Этот pipeline нельзя назвать модным, но он хорошо работает. И это именно та практичная архитектура, на которой Oleg Sotnikov делает акцент в своей работе Fractional CTO: меньше движущихся частей, понятные правила доступа и достаточно observability, чтобы замечать плохое извлечение раньше пользователей.
Простой пример из B2B-поддержки
Финансовый менеджер открывает ассистент поддержки и пишет: «Как выгрузить счета за прошлый месяц?». Ей нужен CSV для бухгалтерии, но она не знает точную метку продукта, которая использована в документации.
Слой поиска должен поймать и точный термин, и намерение запроса. Лексический поиск подхватывает фразу «invoice export» из руководства по продукту. Векторный поиск добавляет связанные страницы с другой формулировкой, например «billing download» или «download monthly charges».
Именно здесь гибридный поиск и показывает свою ценность. В общей B2B-базе знаний лучший по баллам документ не всегда безопасно показывать.
Представьте, что у другого клиента есть админское руководство под названием «Invoice export for enterprise tenants». Оно звучит уместно, и формулировка может совпадать очень хорошо. Но это руководство принадлежит другому tenant и описывает настройки, которые эта финансовая менеджерка даже не видит.
Если система фильтрует после извлечения, ассистент уже успеет прочитать не тот документ, прежде чем отбросит его. Это создает плохие ответы и, в худшем случае, утечки прав доступа. Фильтр должен работать внутри retrieval, чтобы модель вообще не видела контент из чужого tenant.
Поток должен оставаться простым. Ищите по точным словам продукта, например «invoice export». Ищите по близкому смыслу, например «billing download». Применяйте tenant- и role-фильтры до финального ранжирования. Собирайте ответ только из документов, которые пользователь может открыть.
Теперь ответ остается узким и правильным. Он может сослаться на billing guide, FAQ для финансов и короткую заметку про CSV export. Но он не сослется на админское руководство другого клиента, потому что этот документ так и не попал в набор кандидатов.
Пользователь получает короткий ответ: куда нажать, какой формат файла ожидать и есть ли ограничения по роли, связанные с его аккаунтом. Если с текущими правами он не может выгружать счета, ассистент должен сказать это прямо, а не гадать. Такой ответ кажется скучным, и это хороший признак. В B2B-поддержке скучный ответ обычно значит точный.
Ошибки, которые приводят к неверным или небезопасным ответам
Самый быстрый способ сломать поиск — считать права доступа чем-то второстепенным. Если система сначала ищет по всему индексу, а фильтрует потом, она уже успела коснуться контента, который пользователь никогда не должен видеть. Это может просочиться в ранжирование, фрагменты, краткие ответы и кэшированные подсказки, даже если финальный экран скрывает сырой документ.
В общей B2B-базе знаний это еще хуже. Два клиента могут задать один и тот же вопрос, но у одного есть доступ к приватному runbook, а у другого — нет. Если tenant-правила срабатывают после retrieval, ответ может взять факты из чужого tenant и звучать правильно, одновременно раскрывая приватные детали.
Хранить tenant-данные только на файле — еще одна частая ошибка. Retrieval не читает целые файлы. Он читает чанки. Если у чанка нет tenant ID, роли, типа документа и остальных правил доступа, такие чанки трудно надежно отфильтровать. Один плохой чанк может обойти правильный.
Дизайн кэша тоже приводит к тихим утечкам. Команды часто кэшируют эмбеддинги, результаты поиска или финальные ответы, чтобы экономить время и деньги. Это нормально, пока кэшированные результаты не начинают переходить между сессиями. Тогда пользователь из Company A получает быстрый ответ, построенный на документах Company B. Такой баг легко пропустить в тестах, потому что ответ все равно выглядит нормальным.
Слишком свободные названия метаданных тоже создают проблемы. Один сервис пишет tenant_id, другой — accountId, третий использует org. Теперь часть фильтров работает, часть пропускает ошибки, и никто этого не замечает, пока support не спросит, почему клиент увидел неправильную политику. Выберите одну схему и применяйте ее везде.
Последняя ошибка — слишком рано доверять лучшему результату. Retrieval может вернуть чанк с сильным семантическим совпадением, но с неправильным уровнем доступа. Прежде чем модель напишет хотя бы одно предложение, проверьте, что каждый процитированный чанк по-прежнему проходит проверку доступа для этого пользователя и этой сессии.
Помогает простое правило работы: фильтруйте до ранжирования, когда это возможно, храните метаданные доступа в каждом чанке, ограничивайте кэши tenant и пользовательской сессией, используйте одну схему метаданных во всем стеке и еще раз проверяйте доступ перед генерацией ответа.
Команды, которые соблюдают эти правила, обычно избегают самых дорогих проблем: тихих утечек, уверенных неверных ответов и инцидентов в поддержке, на разбор которых уходят дни.
Быстрые проверки перед запуском
Поисковая система может отлично выглядеть в демо и все равно провалиться в первый же день. Финальный раунд тестирования должен быть про доверие. Возвращает ли система правильные документы и скрывает ли все, что пользователь не должен видеть?
Запустите один и тот же вопрос в двух tenant, которые должны получать разные ответы. Хорошо подходят запросы вроде «refund policy» или «SSO setup». Если оба пользователя видят одни и те же документы, у вас течет tenant-логика. Если ни один из них не видит ожидаемую страницу, фильтры могут быть слишком жесткими или подключенными не на том шаге.
Потом проверьте небрежный язык. Реальные люди не ищут аккуратно. Они вводят прозвища, сокращения, короткие запросы и опечатки вроде «logn» вместо «login». Лексический поиск может поймать опечатку, а эмбеддинги — смысл. Гибридный поиск должен справляться с обоими вариантами, не уходя в чужой tenant.
Открывайте топовые результаты по одному. Не останавливайтесь на первом совпадении. Запрещенные документы часто проскальзывают на позиции со второй по пятую, особенно когда векторный поиск считает страницу похожей, а корпоративные права доступа говорят «нет». Одного запрещенного результата в ранжировании достаточно, чтобы разрушить доверие.
Ваш предзапусковой прогон должен сравнить один запрос в двух tenant с разными правилами доступа, проверить псевдонимы и опечатки, искусственно создать случай, когда фильтры убирают все совпадающие документы, и сопоставить каждый фрагмент ответа с точным исходным чанкoм и правилом доступа.
Случай пустого результата требует особого внимания. Когда фильтры убрали все, система должна сказать это прямо. Она не должна гадать, тянуть публичный документ из другого tenant или позволять модели заполнять пробелы из памяти.
Еще одно окончательное правило должно быть видно и в логах, и в QA: каждый фрагмент ответа должен соответствовать разрешенному источнику. Если support спросит, почему ответ вообще появился, команда должна суметь показать чанк, ID документа, тег tenant и набор фильтров, которые его породили. Именно так поиск по B2B-базе знаний остается точным и безопасным при реальных правах доступа.
Что делать дальше
Начните с малого. Возьмите одну базу знаний, которая уже получает реальный трафик, обычно это документы поддержки или внутренние справочные материалы. Сначала добавьте только два жестких фильтра: tenant_id и состояние документа, например published или internal. Это даст чистую тестовую среду и сделает первую версию проще для отладки.
Прежде чем настраивать эмбеддинги или ранжирование, приведите в порядок метаданные. Исправьте отсутствующие tenant ID, устаревшие теги, дублирующиеся заголовки и смешанные состояния документов. Качество поиска часто ломается задолго до модели. Если метаданные беспорядочные, лексический и векторный поиск будут возвращать неверные вещи, только разными способами.
Подключите поддержку и продукт к одному и тому же разбору. Команды поддержки знают, какие вопросы задают пользователи, когда застряли. Команды продукта знают, какие документы только в черновике, привязаны к конкретному аккаунту или легко маркируются неправильно. Короткая проверка правил доступа может предотвратить недели тихих ошибок.
С первого дня отслеживайте небольшой набор метрик: неправильные ответы, которые цитируют не тот документ, пустые результаты по запросам, которые должны работать, медленные запросы после добавления фильтров, и ответы, которые выглядят правильными, но все равно нарушают права доступа.
Не ждите идеального бенчмарка. Читайте неудачные поисковые запросы каждую неделю и сортируйте их по причинам. Обычно вы снова и снова находите одни и те же проблемы: слабые метаданные, шумные чанки или фильтры, которые срабатывают слишком поздно в retrieval.
Гибридный поиск становится лучше, когда вы сначала подтягиваете скучные части. Чистые данные, простые фильтры, понятные правила, а уже потом изменения в ранжировании. Такой порядок экономит время.
Если нужен второй взгляд, Oleg Sotnikov как Fractional CTO разбирает такие системы. Его работа над AI-first software и retrieval-heavy системами описана на oleg.is, так что это практичная отправная точка, если вашей команде нужен более безопасный tenant-aware retrieval или более простая архитектура.
Часто задаваемые вопросы
Что означает гибридный поиск для B2B-базы знаний?
Гибридный поиск использует два подхода сразу. Лексический поиск находит точные слова, например коды ошибок или названия продуктов, а эмбеддинги находят страницы с тем же смыслом, даже если формулировки разные.
Такое сочетание хорошо работает в B2B-поддержке, потому что пользователи пишут простыми словами, а документы часто используют официальные названия продуктов.
Почему бы не использовать только векторный поиск?
Векторный поиск хорошо понимает смысл, но может пропускать точные строки, которые важны пользователю. Если кто-то ищет SKU, название политики или код ошибки, поиск по словам часто дает лучший результат.
Использование обоих методов помогает делать поиск полезным и для точных запросов, и для небрежного естественного языка.
Когда должны срабатывать фильтры tenant и роли?
Фильтры должны работать внутри retrieval, до ранжирования и до генерации ответа. Если фильтровать только в интерфейсе, система уже могла оценить или процитировать контент, который пользователь не должен видеть.
Именно так появляются неверные ответы и утечки данных, даже если на финальном экране исходный документ скрыт.
Какие метаданные должен содержать каждый чанк?
Храните метаданные доступа в каждом чанке, а не только в родительском документе. Как минимум сохраняйте tenant_id, статус документа и любые правила ролей или групп, которым уже доверяет приложение.
Также полезно держать поля вроде document_id, chunk_id, source_type, product_area, language и updated_at, чтобы у поиска и ранжирования был чистый контекст.
Почему права доступа на уровне чанков так важны?
Потому что поисковые системы обычно извлекают чанки, а не целые файлы. Если чанк потеряет данные о tenant или роли, он может попасть в результаты или, наоборот, исчезнуть там, где должен совпасть.
Копируйте те же факты о правах доступа из исходного документа в каждый чанк, чтобы каждый из них мог ответить на простой вопрос: может ли этот пользователь видеть этот текст?
Как не дать AI отвечать по скрытым документам?
Держите модель на коротком поводке. Передавайте только одобренные фрагменты, а не весь архив документов, и просите модель отвечать только на основе этих фрагментов.
Если доказательств мало, пусть она честно скажет, что не знает. Это гораздо безопаснее, чем позволять ей гадать по скрытому или не связанному контенту.
Что делать, если фильтры убрали все совпадения?
Скажите это прямо. Если фильтры убрали все подходящие документы, возвращайте понятный ответ без результатов, а не заполняйте пробел слабой догадкой.
Можно предложить сузить запрос или подсказать, что пользователю может понадобиться другая роль, но не подмешивайте контент за пределами его доступа.
Может ли кэш привести к утечке прав доступа?
Да. Если кэш результатов поиска или финальных ответов слишком широкий, он может переходить между сессиями. Тогда один клиент получит ответ, составленный на основе документов другого клиента.
Ограничивайте кэш tenant и пользовательской сессией и перепроверяйте доступ перед показом или повторным использованием.
Что нужно проверить перед запуском?
Проверьте один и тот же запрос в двух tenant, где должны быть разные результаты. Затем попробуйте опечатки, псевдонимы, короткие запросы и случаи, когда фильтры должны убрать все совпадения.
Открывайте не только первый результат. Запрещенные страницы часто появляются ниже, и одного плохого результата достаточно, чтобы сломать доверие.
С чего начать, если текущий поиск устроен беспорядочно?
Начните с одной живой базы знаний и сначала добавьте только пару жестких фильтров, например tenant_id и состояние документа. Затем очистите отсутствующие метаданные, устаревшие теги и смешанные имена полей, прежде чем настраивать ранжирование.
Большинство проблем поиска начинается в модели данных, а не в модели эмбеддингов.


