Федерация моделей при стартап‑бюджете: простая настройка
Федерация моделей при стартап‑бюджете лучше всего работает, когда всё просто: выберите одну модель по умолчанию, одну резервную и одну локальную опцию вначале.
Содержание
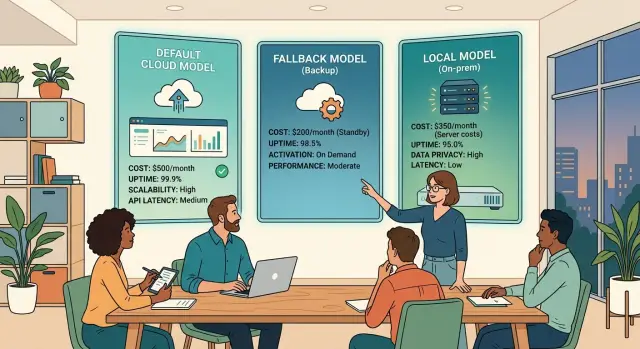
Почему небольшие команды строят слишком сложные стеки\n\nНебольшие команды часто добавляют модели слишком рано, потому что выбор кажется прогрессом. Стек с пятью провайдерами, кастомными правилами маршрутизации и задачно-специфическими подсказками выглядит впечатляюще на диаграмме. В повседневной работе это обычно создаёт больше подвижных частей, чем стартап может поддерживать.\n\nКаждый новый провайдер приносит реальные накладные расходы. Вы платите ещё один счёт, изучаете ещё одно API, следите за новыми лимитами и храните ещё один поток логов. Когда что-то ломается, команде приходится отвечать на базовый вопрос трудным путём: виновата ли модель, подсказка, контекст или маршрутизатор?\n\nЭта работа по поддержке быстро растёт. Одна модель может падать в длинных диалогах, другая плохо форматировать JSON, а третья меняет тон после изменения подсказки. По отдельности эти проблемы не кажутся большими, но вместе они могут съедать часы каждую неделю.\n\nКоманды также используют маршрутизацию, чтобы скрыть проблемы процессов. Если подсказка расплывчата, шаг извлечения даёт слабый контекст или задача разделена плохо, умная маршрутизация это не исправит. Она просто делает систему менее прозрачной и более сложной для ремонта.\n\nНебольшая SaaS-команда может потратить дни, сравнивая четыре модели для написания ответов в поддержку, а затем обнаружить, что большинство плохих ответов были вызваны устаревшей документацией. Дополнительные тесты кажутся продуктивными, но они не решают настоящую проблему. Лучше бы помогла работа с исходными материалами.\n\nБолее простая настройка даёт чище сигналы. С одной моделью по умолчанию вы понимаете, как выглядит нормальная производительность. С одной резервной моделью вы видите, редки ли сбои или это знак того, что основная модель не подходит. Одна локальная модель покрывает приватные данные, дешёвые пакетные задачи или офлайн-эксперименты, не превращая весь стек в хаос.\n\nИменно поэтому при стартап-бюджете стоит начать с простого стека моделей. Чёткие подсказки и короткий список моделей дают данные, которым можно доверять. Если одна модель уже справляется с большинством запросов, добавление трёх обычно даёт три дополнительных места для отладки, в то время как команда должна выпускать продукт.\n\n## Стартовый набор из трёх моделей\n\nБольшинство небольших команд добиваются лучшего результата с тремя моделями, чем с десятью. Одна модель решает почти всю пользовательскую нагрузку. Один резерв подключается, когда первая модель падает. Одна локальная модель берёт дешёвые повторяющиеся задачи, которые не требуют платного API.\n\nЭтого достаточно для раннего AI-стека. Он остаётся простым для отладки, предсказуемым по цене и лёгким для объяснения.\n\nПолезное разделение с первого дня:\n\n- Модель по умолчанию отвечает за ответы клиентам, сводки, рекламные тексты продукта и обычные чат‑сценарии.\n- Резервная модель запускается только когда у модели по умолчанию истёк таймаут, сработали ограничения по запросам или произошла критическая ошибка.\n- Локальная модель обрабатывает повторяющуюся работу: тегирование тикетов, очистку текста, извлечение полей или приведение контента к фиксированному формату.\n\nЭто разделение важно, потому что разные задачи ломаются по-разному. Ассистент, ориентированный на пользователя, нуждается в стабильном качестве и предсказуемом тоне. Резервная модель важна больше в плане совместимости, чем личности. Локальная модель должна быть дешёвой и быстрой, даже если её стиль письма прост.\n\nДержите правила простыми. Сначала обращайтесь к модели по умолчанию. Если запрос не выполнен по понятной технической причине, отправьте тот же запрос в резерв. Не используйте резервную модель для каждой мелкой жалобы на качество — иначе расходы и поведение быстро поползут вразброс.\n\nЛокальная модель не должна отвечать за ответы с высокой степенью риска. Она плохо подходит для переговоров по продажам, юридических формулировок или всего, что клиент воспринимает как окончательный текст. Зато отлично подходит для фоновой работы. Небольшая SaaS-команда может использовать её для сортировки тикетов по темам, удаления чувствительных данных перед хранением и генерации коротких внутренних сводок для команды поддержки.\n\nЕсли вы начнёте с чётких границ, позже можно добавить маршрутизацию без глобального ремонта. Если же начать с умной маршрутизации, обычно придётся неделями гоняться за краевыми случаями, которых простой трёхмодельный набор бы избежал.\n\n## Как выбрать модель по умолчанию\n\nВыберите модель, которая справляется с большей частью повседневной работы с наименьшими трениями. Лучший балл в бенчмарке редко важен, если вашей команде в основном нужны чистые сводки, черновики для поддержки, помощь с кодом или структурированное извлечение.\n\nМодель по умолчанию важнее логики маршрутизации, потому что на неё ложится основная нагрузка, она формирует расходы и задаёт ритм для всех, кто пользуется продуктом.\n\nНачните с главной задачи. Если пользователи в основном задают вопросы по документам, тестируйте модель на запросах в стиле retrieval. Если продукт пишет письма, спецификации или ответы в поддержку, проверьте именно эти рабочие примеры. Модель может выглядеть здорово на публичных графиках, но не соответствовать тону, формату или точности, которые нужны вашему продукту.\n\nИспользуйте 20 реальных подсказок из вашего продукта. Возьмите их из тикетов поддержки, действий пользователей, внутренних рабочих процессов или провалившихся краевых случаев. Оставьте набор намеренно «грязным». Реальный трафик включает расплывчатые запросы, отсутствующий контекст и странное форматирование.\n\nПростая оценочная таблица работает хорошо. Проверьте, следует ли модель инструкциям с первого раза, даёт ли ответ, который корректен или достаточно близок к использованию, отвечает ли достаточно быстро для рабочего процесса, укладывается ли в бюджет и соблюдает ли требуемый формат вывода.\n\nПодчинение инструкциям важнее, чем многие команды ожидают. Если модель игнорирует правила формата, добавляет лишний текст или пропускает очевидные ограничения, команда будет тратить больше времени на очистку ответов, чем на разработку функций. Немного более слабая модель, которая выполняет подсказки, может быть лучшим выбором по умолчанию.\n\nЦена и ограничения по скорости могут разрушить удачный выбор. Дешевая цена за токен не поможет, если провайдер ограничивает запросы в часы пик. Медленные ответы тоже добавляют скрытые издержки. Если агент поддержки ждёт ещё три секунды на каждый черновик, инструмент воспринимается хуже, даже если ответы хороши.\n\nПрактичный подход — прогнать те же 20 подсказок через двух–трёх кандидатов и выбрать «скучного» победителя. Обычно это модель с минимальным количеством сюрпризов, стабильной скоростью и чистым форматированием, а не та, у которой самый эффектный демо‑ролик.\n\nВыберите одну модель для основной нагрузки, затем наблюдайте за ней неделю. Если она справляется примерно с 80 процентами запросов без ручной доработки, вы, вероятно, выбрали правильно. Если команда постоянно добавляет патчи к подсказкам, чтобы заставить её вести себя, поменяйте модель раньше.\n\n## Когда резервная модель оправдывает своё место\n\nРезервная модель начинает окупаться, когда сбой причиняет больше вреда, чем небольшое падение качества вывода. Если ваше приложение пишет ответы клиентам, сортирует тикеты или питает внутреннего ассистента, «мертвый» запрос часто стоит дороже, чем менее отточенный ответ.\n\nТри случая обычно оправдывают переключение: таймауты, критические ошибки и сбои провайдера. Вы не можете предотвратить эти события полностью, поэтому нужна спокойная стратегия на случай их возникновения.\n\nДержите эту стратегию простыей. Ваша модель по умолчанию и резервная модель должны использовать подсказки как можно ближе по структуре, тону и формату вывода. Если первая модель возвращает JSON с фиксированными полями, попросите резервную вернуть тот же JSON. Если одна подсказка просит "ответ в простом тексте", а другая требует таблицу, переключение сломает не только аптайм.\n\nНебольшое падение качества часто приемлемо. Стабильная работа обычно важнее идеальной формулировки. Клиент скорее получит годный ответ за восемь секунд, чем будет смотреть на спиннер и ничего не получить.\n\nПростой пример проясняет идею. Допустим, небольшая SaaS‑команда использует одну модель для классификации входящих тикетов. Они дают модели по умолчанию 10 секунд. Если она таймаутится или возвращает критическую ошибку, приложение отправляет ту же подсказку в более дешёвую резервную модель и помечает результат как "fallback". Эта метка позволяет команде позже просмотреть такие случаи, не останавливая рабочий поток.\n\nЭто компромисс не всегда приемлем. Если задача касается юридических текстов, финансов или чувствительных сообщений клиентам, более низкое качество может создать риск. В таких случаях стоит повторить попытку один раз или отправить задачу человеку.\n\nЛогируйте каждое переключение. Отслеживайте, когда оно произошло, какой провайдер упал, сколько длилось восстановление и прошёл ли вывод резервной модели проверку. Через неделю–две начинают проявляться закономерности. Если переключения растут в одно и то же время каждый день, вероятно, проблема в лимитах запросов, а не в модели.\n\n## Где локальная модель имеет смысл\n\nЛокальная модель окупается, когда задача повторяющаяся, дешевая и приватная. Она лучше всего подходит для работ, где требуется стабильный вывод, а не блестящие ответы.\n\nХорошие первые сценарии — простые внутренние рабочие процессы: тегирование тикетов, классификация лидов, краткие пакетные сводки заметок встреч или извлечение тем из большого массива отзывов клиентов. Эти задачи часто выполняются пакетно, и расходы на API быстро накапливаются, тогда как небольшая локальная модель справляется достаточно хорошо.\n\nИспользуйте её для текста, который остаётся внутри компании и не требует первоклассной письменности или глубокого рассуждения. Если сводка только помогает команде сортировать, искать или маршрутизировать работу, локальная модель обычно достаточна. Если же вывод идёт напрямую клиентам, держите работу на более мощной хостинговой модели.\n\nПриватность — ещё одна причина запускать модель локально. Некоторым командам нормально отправлять рутинный текст в API. Другие работают с внутренними заметками, логами поддержки или черновиками, которые предпочитают держать в‑доме. Локальная настройка даёт такую опцию без принуждения всех задач на локальное железо.\n\nЕсть и компромиссы. Локальные модели требуют настройки, мониторинга и внимания к производительности. Если команда делает лишь несколько запросов в день, экономия вряд ли оправдает усилия. Они имеют смысл, когда задача частая, предсказуемая и легко оценивается.\n\n## Простой план развёртывания\n\nНачните с одного рабочего процесса, который уже имеет реальный объём. Выберите что‑то, что команда выполняет ежедневно, а не редкий краевой случай. Ответы поддержки, квалификация лидов, сводки тикетов и черновики спецификаций — хорошие стартовые точки, потому что они генерируют достаточно запросов, чтобы быстро показать стоимость и паттерны сбоев.\n\nИспользуйте один шаблон подсказки и один формат вывода для этого рабочего процесса. Пусть они будут скучными. Если модель должна возвращать JSON, пусть возвращает один и тот же JSON каждый раз. Если задача требует короткого ответа, задайте чёткий лимит длины. Большинство команд создают хаос, тестируя одновременно три стиля подсказок, а потом винят модель.\n\nУстановите несколько базовых правил перед тем, как пустить реальный трафик. Дайте модели по умолчанию понятный таймаут. Повторите запрос один раз при кратковременных сетевых или провайдерских ошибках. Отправляйте запрос в резерв только когда первый вызов таймаутится, падает или ломает формат вывода. Маршрутизируйте на локальную модель только задачи, которые вы уже знаете, что она умеет выполнять хорошо.\n\nЭтого достаточно, чтобы стартовать. На первом этапе не нужна умная маршрутизация. Нужны стабильное поведение, предсказуемый счёт и способ видеть, когда настройка ломается.\n\nКаждую неделю проверяйте три показателя: стоимость, задержку и процент успеха. Стоимость показывает, имеет ли смысл рабочий процесс. Задержка — будут ли пользователи ждать. Процент успеха — пригоден ли вывод без доработки. Сведите эти числа в простую таблицу и просматривайте в один и тот же день каждую неделю.\n\nДобавляйте правила маршрутизации только после того, как увидите один и тот же паттерн несколько раз. Возможно, длинные документы всегда требуют резервной модели. Возможно, короткие задачи хорошо идут на локальной модели. Возможно, модель по умолчанию обрабатывает 90 процентов запросов, а остальные пока можно отложить. Эти паттерны должны прийти из трафика, а не из догадок.\n\nЕсли вы не можете объяснить развёртывание на одной странице, оно уже слишком сложное.\n\n## Реалистичный пример из жизни небольшой SaaS‑команды\n\nКоманда из шести человек получает около 60 писем и багрепортов в обычный рабочий день. Им не нужна сложная маршрутизация. Им нужны более быстрые ответы, меньше пропущенных инцидентов и меньше рутинной работы.\n\nИх модель по умолчанию работает на передовой. Она читает новые сообщения, пишет черновик ответа в тоне команды и сортирует каждый элемент по простым категориям: "billing", "bug", "feature request" или "account access". Она также помечает всё срочное — например, проблемы с оплатой или сообщения о недоступности сервиса — чтобы человек видел это в первую очередь.\n\nВ большинстве дней этого хватает. Один лидер поддержки просматривает черновики перед отправкой, правит слабую формулировку и держит короткий файл подсказок в актуальном состоянии. Через две недели команда замечает паттерн: модель даёт хорошие первые черновики для типичных вопросов, но становится расплывчатой, когда пользователи описывают сломанные рабочие процессы. Лидер поддержки добавляет две удачные примеры в подсказку, и качество ответов сразу улучшается.\n\nУ них также есть резервная модель наготове. Когда основной провайдер замедляется или у него сбой, новые тикеты автоматически попадают к бэкапу. Черновики получаются чуть менее отполированными, но почтовый ящик движется. Это важнее, чем идеальная формулировка, когда клиенты ждут.\n\nНочью локальная модель выполняет две рутинные задачи на дешёвом сервере. Она тегирует старые тикеты для отчётов, группирует почти дублирующиеся багрепорты, отмечает повторяющиеся жалобы после релиза и помечает вероятный спам или сообщения с низким сигналом. Этот локальный шаг экономит деньги, потому что для этих задач не нужна лучшая хостинговая модель — нужен стабильный дешёвый результат.\n\nК концу месяца у команды простая рабочая конфигурация: одна модель для ежедневной работы, одна на плохие дни и одна для фоновой очистки. Один человек всё ещё проверяет результаты — и это то, что многие команды пытаются пропустить, но не стоит. Простой цикл ревью ловит слабые подсказки на ранней стадии и держит систему полезной, а не шумной.\n\n## Ошибки, которые тратят время и деньги\n\nБольшинство команд сначала не сжигают деньги на цене моделей. Они тратят их на лишний выбор. Самый быстрый путь в тупик — добавить пять моделей, прежде чем одна реальная задача заработает от начала до конца.\n\nОбычная схема выглядит так: команда подключает несколько API, маркирует их по скорости или цене и строит правила маршрутизации в день запуска. Потом подсказка ломается, вывод уходит в сторону, и никто не понимает, откуда ошибка: от модели, подсказки или маршрутизатора. Одна модель по умолчанию, один резерв и одна локальная дают достаточно контраста, чтобы понять, что реально происходит.\n\nЛоги важнее догадок. Если маршрутизировать наугад, вы обычно отправляете дорогие запросы не туда и дешёвые — на задачи, которые они не потянут. Сначала фиксируйте простые факты: какая задача выполнялась, какая модель её обработала, сколько это заняло, сколько стоило и принял ли человек результат. Эта привычка экономит много денег.\n\nКоманды также теряют время, когда навязывают одну подсказку моделям, которые ведут себя очень по-разному. Подсказка, которая хорошо идёт на одной модели, может стать расплывчатой, слишком многословной или слишком строгой на другой. Держите задачу одинаковой, но при необходимости настраивайте подсказки под каждую модель. Если пропустить этот шаг, вы не сравниваете модели честно.\n\nБенчмарки тоже вводят в заблуждение. Модель может хорошо выглядеть в публичных тестах и при этом плохо справляться с вашими ответами в поддержку, сортировкой лидов или внутренними сводками. Реальные задачи побеждают таблицы лидеров каждый раз. Прогоните небольшой тестовый набор из вашей работы и оценивайте вывод простыми правилами «пройдена/не пройдена».\n\nСчёт часто удивляет команды, потому что они игнорируют бюджеты до тех пор, пока не придёт счёт за месяц. Установите жёсткие лимиты рано: дневной или недельный лимит расходов, макс. стоимость на задачу, оповещения о росте использования резервной модели и краткий обзор неудачных или повторных вызовов.\n\nТакая простая настройка легче чинится, потому что логи рассказывают понятную историю. Умная система, которую никто не может объяснить, обычно остаётся сломанной дольше.\n\n## Быстрая проверка перед добавлением новой маршрутизации\n\nЕсли модель по умолчанию всё ещё требует частого ручного вмешательства, дополнительная маршрутизация только скрывает проблему. Большинство запросов должны проходить через основную модель чисто: стабильные подсказки, предсказуемый вывод и лишь редкие человеческие правки.\n\nРезервная модель тоже должна переключаться без драм. Таймауты, лимиты или плохие ответы должны вызывать понятную передачу задачи. Пользователи не должны застревать в ожидании, пока приложение попробует три варианта подряд.\n\nЛокальная модель должна заслужить своё место просто: она должна экономить деньги на повторяющихся задачах. Хорошие примеры — тегирование, сводки фиксированного формата, черновая классификация или внутренняя очистка данных. Если локальная опция медленнее, сложнее в поддержке и решает лишь краевые случаи, это, вероятно, хобби‑проект, а не часть разумного стартап‑стека.\n\nПеред тем как добавлять маршрутизацию, проверьте пять вещей:\n\n- Модель по умолчанию обрабатывает примерно 80–90 процентов запросов без спасения.\n- Резервная модель работает по тому же контракту подсказок или очень близко к нему.\n- Локальная модель сокращает расходы на повторяющиеся задачи настолько, что оправдывает настройку и мониторинг.\n- Один человек отвечает за логи, ежемесячные расходы и обновления подсказок.\n- Сбои выявляются быстро в дашбордах или оповещениях, а не жалобами пользователей.\n\nЧетвёртый пункт важнее, чем многие думают. Если никто не отвечает за логи, бюджеты и изменения подсказок, логика маршрутизации за несколько недель превращается в хаос. Один инженер меняет подсказку, другой переставляет модель — и никто не понимает, почему во вторник выросло количество тикетов.\n\nНебольшая SaaS‑команда может держать это просто. Приложение отправляет почти всё на одну хостинговую модель, переключается на второго провайдера при сбоях и запускает локальную модель ночью для пакетных сводок. Этого достаточно для многих компаний.\n\nЕсли какой‑то из этих чеков проваливается, остановитесь и исправьте это прежде, чем добавлять новую маршрутизацию. Лучшие логи, более точные подсказки и аккуратный failover обычно экономят больше времени, чем сложные правила выбора модели.\n\n## Следующие шаги, которые сохранят стек управляемым\n\nКогда первая настройка заработает, зафиксируйте её на бумаге. Дайте каждой модели по одной чёткой обязанности, описанной одной строкой. Одна обрабатывает большинство подсказок, одна ловит сбои или лимиты, а локальная модель покрывает приватные или дешёвые задачи. Если у модели нет короткого описания на простом английском (или вашем языке), скорее всего, её не место в стеке.\n\nНа этой странице также отметьте три лимита: стоимость, скорость и допустимую частоту ошибок. Это удержит маленький стек моделей от превращения в гору исключений, к которым никто не захочет прикоснуться через месяц.\n\nДля большинства небольших команд достаточно ежемесячного обзора. Защитите месяц логов и ищите закономерности, а не краевые случаи. Какие запросы падали и почему? Какие подсказки были достаточно медленными, чтобы раздражать пользователей? Какой провайдер добавлял расходы без явной пользы? Какие задачи можно было бы перевести на локальную модель без потери качества?\n\nКоманды часто держат старых провайдеров долго после того, как они перестали приносить пользу. Удаляйте их, когда они больше не решают реальную проблему. Каждый лишний провайдер добавляет поддержку, мониторинг и ещё одно место, где поведение может измениться.\n\nЕсли команде нужна помощь в принятии таких решений, Oleg Sotnikov at oleg.is работает со стартапами и малыми бизнесами по вопросам lean AI‑ориентированных продуктовых и инфраструктурных решений. Цель проста: держать стек достаточно маленьким, чтобы понимать его, дешёвым в эксплуатации и надёжным для реальной работы.\n\nОбычно это лучший путь. Начните с одной модели по умолчанию, одной резервной и одной локальной. Пусть реальный трафик подскажет, что добавлять дальше.