Экран сопоставления при импорте данных, чтобы сократить работу по индивидуальным импортам
Экран сопоставления при импорте данных позволяет клиентам привязывать колонки, находить ошибки по строкам и исправлять плохие данные до того, как ваша команда начнёт писать одноразовые скрипты.
Содержание
Почему импорты так часто превращаются в отдельную работу
Большинство ошибок при импорте проявляются задолго до того, как ваш код вообще вступит в дело. Клиенты присылают файлы, где одно и то же обозначается по‑разному: "Email", "Work Email", "Primary email" или пустой заголовок, который кто‑то забыл назвать. Если продукт ожидает одну фиксированную структуру, каждая таблица становится частным случаем.
Тогда импорты перестают быть обычной функцией и превращаются в работу поддержки. Клиент загружает CSV, получает расплывчатую ошибку и просит помощи. Служба поддержки обычно видит, что файл не в порядке, но не может переназначить колонки или исправить правила на уровне строк внутри продукта — проблема уходит к инженерии.
Команды также обнаруживают плохие данные слишком поздно. Валидация запускается после начала импорта или после того, как часть строк уже попала в базу. Один неверный формат даты, одно отсутствующее обязательное поле или название страны там, где нужен код страны — и рушатся сотни строк одновременно. Теперь команда не просто импортирует — она чинит частичный провал.
Инженеры часто отвечают быстрым патчем. Кто‑то пишет скрипт, чтобы переименовать колонки, обрезать пробелы, разделить полные имена или пропустить сломанные строки. Это работает для одного клиента и одного файла. Потом приходит следующий файл с теми же полями в другом порядке, с чуть другими названиями или с лишней колонкой — и скрипт ломается снова.
Экран сопоставления останавливает этот цикл заранее. Пользователи могут сопоставить колонки, увидеть проблемы в предпросмотре и исправить строки до того, как импорт затронет живые данные. Без этого шага ваш продукт учит клиентов просить исключения, а команда платит за ту же проблему временем поддержки, временем инженеров и рискованными ручными правками.
Что нужно хорошему экрану импорта
Полезный экран уменьшаeт путаницу ещё до первой записанной строки. Пользователь должен сразу видеть, какие поля обязательны, а какие можно оставить пустыми. Если "Email" обязателен, а "Company phone" — опционален, скажите это рядом с полем. Не ждите до последнего шага.
Имена полей важнее, чем многие команды предполагают. Клиенты думают не терминами базы данных, а теми заголовками, которые они уже используют в таблицах. Если они знают поле как "SKU" или "Customer ID", используйте этот язык на экране. Внутренние названия вроде "external_ref" или "account_identifier" замедляют людей и приводят к ошибочным сопоставлениям.
Пользователи должны иметь возможность пропускать ненужные колонки. Реальные файлы беспорядочны: в них есть заметки, старые флаги, пустые разделители и комментарии, которые никогда не должны попасть в систему. Если экран подталкивает к сопоставлению всего подряд, люди начнут угадывать — так появляются плохие импорты.
Повторная работа должна оставаться в прошлом. Когда поставщик присылает одну и ту же таблицу каждую неделю, пользователям не нужно каждый раз строить сопоставление заново. Сохранённые шаблоны ускоряют повторные загрузки и сокращают многие запросы на кастомные скрипты импорта.
Пара мелких деталей делает весь поток удобнее. Покажите образцы значений под каждой распознанной колонкой, чтобы пользователь отличал похожие поля. Держите ярлыки простыми. Сделайте опцию пропуска очевидной. Сохраните спокойный вид страницы.
Когда пользователи видят обязательные поля, сопоставляют колонки понятными названиями, игнорируют мусор и повторно используют шаблоны, многие «специальные» запросы на импорт не доходят до инженеров.
Как должен работать поток сопоставления
Экран должен начинать помогать сразу после загрузки файла. Считайте заголовки немедленно и предлагайте соответствия, вместо того чтобы заставлять всё сопоставлять вручную. Если в файле есть заголовки типа "SKU", "Item Name" или "Cost", приложение должно предложить ближайшие поля и позволить пользователю их подправить.
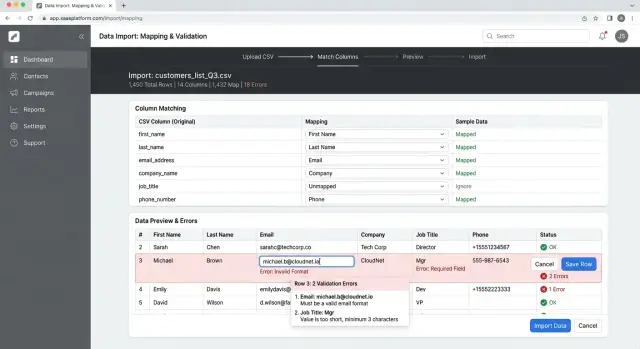
Размещайте исходную колонку и целевое поле рядом друг с другом. Пользователь должен принять предложение, изменить его или пропустить колонку. Обязательные поля должны выделяться, а недостающие — отмечаться сразу. Если в файле нет названия товара или цены, скажите об этом до того, как пользователь пойдёт дальше.
Предпросмотр важен. После сопоставления колонок покажите несколько реальных строк с уже сопоставленными полями, а не в исходном порядке таблицы. Люди быстрее находят ошибки, когда видят, что "Cost" попало в "Retail price" или колонка дат стала обычным текстом.
Лист поставщика это показывает наглядно. Представьте файл с колонками "Product", "UPC", "Qty" и "Cost USD". Приложение может предложить Product name, Barcode, Stock quantity и Price. Если "Qty" по ошибке сопоставили с Price, предпросмотр сразу выдаст эту ошибку.
Поток должен также блокировать плохие импорты на раннем этапе. Если не хватает обязательного поля, если две исходные колонки сопоставляются с одной целью или если тип колонки не подходит — покажите это до импорта. Короткие сообщения работают лучше: "Price отсутствует" или "Barcode содержит слишком длинный текст."
Завершите простым шагом подтверждения. Покажите выбранные сопоставления, пропущенные колонки, количество строк и предупреждения в одном месте. Когда пользователь нажмёт импорт, он должен быть уверен в результате.
Как показывать ошибки до импорта
Хороший импортёр ловит очевидные проблемы до того, как начнёт читать каждую строку. Начните с проверки файла: принимайте правильный тип, отклоняйте слишком большие файлы и сразу показывайте количество строк, чтобы пользователь убедился, что загрузил нужный файл.
Затем просканируйте данные и отметьте строки, требующие внимания. Большинство сбоев вызывают одни и те же мелкие проблемы: пустые обязательные поля, неверные даты, сломанные форматы email, числа как текст или значения вне допустимого списка.
Не сваливайте все проблемы в один большой красный блок. Группируйте повторяющиеся ошибки. Если 214 строк не имеют "SKU", скажите это один раз и дайте открыть список. Люди исправляют шаблоны гораздо быстрее, когда видят, что одна и та же ошибка повторяется во многих строках.
Номера строк важнее красивых формулировок. Показывайте точный номер строки из загруженного файла, а не внутренний номер записи. Если пользователь откроет таблицу и увидит, что строка 118 сломана, он должен найти строку 118 без догадок.
Отделяйте блокирующие ошибки от предупреждений. Ошибки должны останавливать импорт, потому что строке нельзя доверять. Предупреждения можно пропустить, но их стоит просмотреть. Чистые строки должны идти дальше без лишнего шума, а простой суммарный счётчик покажет масштаб проблемы сразу.
Небольшая таблица предпросмотра очень помогает. Покажите несколько плохих строк, исходное значение и короткую подсказку, что исправить. "Дата должна быть в формате YYYY-MM-DD" — этого обычно достаточно. Длинные объяснения замедляют.
Если поставщик загрузил CSV на 12 000 строк и в 600 строках стоит "N/A" в колонке цены, пользователю должен быть показан сгруппированный блок ошибки, номера затронутых строк и пример этих строк. Это экономит время поддержки и избавляет от ещё одного скрипта очистки для файла, который пользователь мог исправить сам.
Как пользователи должны править плохие строки
Люди бросают попытки импорта, когда каждая плохая строка отправляет их обратно в Excel. Если приложение находит проблему, оно должно позволить исправить её прямо там.
Самый быстрый шаблон напоминает таблицу. Пользователь кликает по плохой ячейке, вводит новое значение и видит обновлённую строку, не открывая отдельную форму для каждой правки. Небольшие исправления должны занимать секунды.
Когда та же самая проблема встречается в десятках строк, по‑одной править утомительно. Помогают массовые действия. Пользователь должен иметь возможность заменить "N/A" на пустое, поменять "US" на "United States" или применить один формат даты ко всем выбранным строкам. Это экономит много бессмысленной работы.
Повторная проверка должна происходить сразу после изменения значения. Если пользователь исправил email, дату или обязательное поле, состояние ошибки для этой строки должно очиститься сразу или показать следующую проблему. Ждать полного запуска импорта делает экран медленным и неуверенным.
Держите исходное значение видимым рядом с отредактированным. Людям нужен контекст, особенно при работе с файлами поставщиков или старыми выгрузками с грязными данными. Даже маленькая пометка "оригинал" помогает избежать превращения одной ошибки в другую.
Показывайте прогресс: сколько строк ещё с ошибками, сколько готово к импорту, и давайте фильтры по неверным строкам или переход к следующей проблеме. Пользователь не должен гадать, почти ли он закончил или только на середине пути.
Импорты часто занимают больше времени, чем ожидают, поэтому сохраняйте прогресс автоматически. Храните сопоставления, правки строк и отклонённые предупреждения, чтобы пользователь мог уйти и вернуться позже. Если кто‑то потратил 20 минут на чистку файла и потерял эту работу после закрытия вкладки, в следующий раз он опять попросит ручную помощь.
Файл поставщика делает ценность очевидной. Десять строк имеют неправильный SKU, 60 строк используют неверный налоговый код, и три строки не имеют цены. Встроенные правки исправляют SKU, одна массовая операция правит налоговый код, а система повторно проверяет строки по мере изменений. Это гораздо дешевле, чем просить инженеров написать ещё один одноразовый скрипт.
Что сохранять для повторных импортов
Система должна запоминать больше, чем последний файл. Если клиент загружает один и тот же отчёт каждую неделю, ему не нужно снова сопоставлять 18 колонок. Сохраняйте сопоставления по клиенту, аккаунту или рабочей области, чтобы каждая команда видела свою настройку.
Это особенно важно, когда два клиента используют одно и то же название колонки в разных смыслах. Одна команда может считать "Code" SKU, другая — внутренним ID. Раздельные сохранённые шаблоны предотвращают тихие ошибки и уменьшают запросы в поддержку.
Правила валидации должны храниться в одном месте, а не внутри каждого шаблона импорта. Если цена должна быть числом, email — уникальным, а обязательное поле не может быть пустым, держите эти правила в общем наборе правил, который используют все импорты. Тогда вы обновляете правило один раз — и все сохранённые шаблоны следуют ему.
История импорта полезна больше, чем думают команды. Каждая загрузка должна фиксировать имя файла, дату, пользователя, использованное сопоставление, количество строк, прошедших и не прошедших проверку, и короткое резюме ошибок. Когда кто‑то говорит: "В прошлом месяце этот импорт работал", ваша команда может посмотреть, что изменилось, вместо того чтобы догадываться.
Пользователь должен иметь возможность повторно запустить сохранённый шаблон с новым файлом. Это убирает много работы по кастомным скриптам. Поставщик присылает свежий CSV, пользователь выбирает сохранённый шаблон, проверяет новые ошибки и снова импортирует за минуту или две.
Ещё одна мелочь: сохраните пример оригинальных названий колонок вместе с шаблоном. Если в следующем файле "Phone" переименовали в "Mobile Number", система может предупредить пользователя до старта импорта. Эта проверка ловит дрейф формата на ранней стадии.
Простой пример на листе поставщика
Представьте маленький магазин, добавляющий нового поставщика. Поставщик присылает CSV с заголовками, которые не совпадают с системой магазина. Вместо "SKU" в файле написано "Item code". Колонка с ценой тоже в беспорядке: в некоторых строках 12,50, в других 12.50. У некоторых товаров вообще нет категории.
Хороший поток импорта исправит большую часть этого до того, как кто‑то попросит инженеров о помощи. Пользователь сопоставляет "Item code" с SKU, связывает колонку цены с Price и подключает остальные колонки к нужным полям. Предпросмотр реальных строк облегчает проверку: если первые пять строк выглядят неправильно, значит сопоставление неверно.
Затем экран валидирует файл до импорта. Он увидит пустые ячейки категории, отметит ценовые значения, которые не удаётся прочитать, и покажет точные строки с проблемами. Это важно: пользователю не нужен расплывчатый "импорт не удался" — он видит, что строка 18 без категории, строка 42 с битой ценой, а строка 57 с двумя проблемами.
Исправление происходит в том же потоке. Пользователь может задать категорию по умолчанию для пустых ячеек, скорректировать пару неверных цен и заново запустить проверку. Если система может безопасно конвертировать десятичные в формате с запятой и с точкой, она должна сделать это один раз и показать результат в предпросмотре. Если значение остаётся непонятным — строка остаётся заблокированной до правки пользователя.
Сравните это со стандартным откатом: без хорошего UX импорта CSV кто‑то пишет парсер под поставщика. Месяц спустя другой поставщик присылает чуть отличающийся файл — и цикл повторяется.
Когда пользователи могут сопоставлять колонки, просматривать ошибки и править строки сами, инженеры тратят меньше времени на чистку таблиц и больше — на продукт.
Ошибки, которые создают ещё больше скриптов
Когда инструменты импорта настроены неправильно, поддержка получает тикеты, инженеры — примеры CSV, и временные исправления превращаются в код, которым никто не хочет владеть. UI должен поглощать большую часть этой боли.
Одна распространённая ошибка — требовать точных имён колонок. Реальные файлы редко совпадают с вашими системными названиями. Люди экспортируют из старых систем, переименовывают заголовки или добавляют пробелы. Если ваш импортёр принимает только "first_name" и отвергает "First Name", команда будет постоянно дописывать правила парсинга вручную.
Ещё одна ошибка — откладывать проверки на финальный клик. Пользователь сопоставляет десять колонок, запускает импорт и только тогда узнаёт, что 84 строки без ID и 19 дат в неверном формате. Это ощущается как сломанный процесс. Показывайте ошибки строк в предпросмотре рядом с данными, до запуска импорта.
Даты требуют особого внимания. Команды часто говорят: "Мы почистим их потом", и в результате пишут грязную логику для "03/04/24", "3-4-2024" и "April 3". Выберите формат, сообщите его пользователям и отмечайте всё остальное рано. Поздняя очистка кажется простой, пока два клиента не начнут понимать одну и ту же дату по‑разному.
Самая дорогая ошибка — заставлять пользователя начинать заново из‑за одной плохой строки. Если строка 212 упала, пользователь должен исправить строку 212, а не заново маппить весь файл. Сохраняйте сопоставления, прогресс и дайте возможность повторно запустить только изменённые строки.
Если ваш импортёр постоянно создаёт скриптовую работу, признаки обычно очевидны:
- поддержка просит инженеров "просто пропатчить этот файл"
- у инженеров папки, полные примеров CSV от клиентов
- те же псевдонимы заголовков добавляются вручную
- команды правят даты и телефоны в коде после загрузки
- одна плохая строка блокирует весь импорт
Эта модель быстро становится привычкой. Клиент присылает странную таблицу, кто‑то патчит парсером, и теперь этот странный формат часть продукта навсегда. Обычно это проблема дизайна продукта, а не парсинга.
Краткий чеклист перед релизом
Проведите один сухой тест с человеком, который никогда не видел ваш инструмент. Дайте ему реальный файл, молчите и наблюдайте, где он останавливается. Если на первом импорте человеку нужна помощь, ваша команда будет снова и снова помогать тем же способом.
Фича должна позволять пользователю восстановиться после ошибок без перезапуска всего процесса. Это и отличает настоящую продуктовую функцию от скрытой задачи сервисной команды.
Новичок должен суметь загрузить файл, сопоставить колонки, просмотреть проблемы и закончить импорт в одиночку. Обязательные поля должны выделяться сразу. Предпросмотр должен ясно разделять строки, которые пройдут импорт, и те, что упадут, с количественными показателями и понятными причинами. Пользователь должен иметь возможность исправить партию плохих строк внутри приложения, а названия полей — быть понятными нетехническому человеку. "Customer email" — ясно. "contact_email_primary" — нет.
Поддержка — полезный тест. Попросите сотрудника поддержки или продаж объяснить поток вслух за минуту. Если нужен длинный сценарий, значит экран слишком мудрёный или использует странные термины.
Ещё один тест помогает: попробуйте грязную таблицу. Поменяйте заголовки местами, оставьте пустые ячейки, добавьте лишние колонки и смешанные форматы дат. Чистые файлы делают любой поток хорошим. Плохие файлы покажут, действительно ли предпросмотр и валидация убирают одноразовую работу или просто перекладывают её на поддержку.
Что делать дальше
Не пытайтесь охватить все форматы импорта в первой версии. Выберите две задачи импорта, которые клиенты используют чаще всего, и доведите их до ума. Во многих продуктах это лист поставщика и экспорт из старой системы.
Тестируйте на грязных файлах. Чистый образец скрывает реальные проблемы. Посидьте с несколькими пользователями, пока они сопоставляют колонки, читают предпросмотр и исправляют строки. Обычно вы быстро увидите одни и те же проблемы: непонятные имена полей, смешанные форматы дат, дубликаты записей и обязательные колонки, которые пользователи замечают только в конце.
После релиза следите за работой, которая всё ещё попадает в поддержку и инженерам. Хороший поток сопоставления должен сократить одноразовые правки в коде. Если люди всё ещё присылают таблицы в поддержку по почте, или разработчики продолжают писать кастомные парсеры, значит поток ещё не готов.
Небольшая шкала полезна:
- процент успешных импортов с первого раза
- тикеты поддержки по неудачным импортам
- ручные правки строк, сделанные сотрудниками
- запросы на особую обработку или скриптовую работу
- время от загрузки до завершённого импорта
Эти метрики покажут, где трения. Если пользователи падают до сопоставления — слаб шаг загрузки. Если падают после предпросмотра — вероятно, сообщения валидации слишком расплывчаты. Если одни и те же сопоставления повторяются, сохраните их и упростите повторное использование.
Также стоит пересмотреть план на бэкенде до того, как патч‑скрипты накопятся. Многие команды постоянно добавляют логику импорта, пока код не становится хрупким и никто не хочет его править через полгода. Чаще правильнее улучшить поток сопоставления, сделать правила валидации понятнее и решить, какие случаи действительно должны решаться вручную.
Если работа по импорту постоянно превращается в кастомный код, с этим помогает обзор продуктовой и бэкенд‑части, которым занимается Oleg Sotnikov через oleg.is. Короткий ревью от Fractional CTO или советника может помочь заменить повторяющиеся патчи более чистым и предсказуемым потоком.
Часто задаваемые вопросы
Почему CSV‑импорты так часто превращаются в работу службы поддержки?
Потому что файлы редко соответствуют одному фиксированному шаблону. Клиенты используют разные заголовки, добавляют лишние колонки, оставляют пустые имена и смешивают форматы — из простого загрузчика получается разбор случая службой поддержки, а затем — правка инженерами.
Что пользователи должны увидеть первым на экране сопоставления?
Покажите обязательные поля, распознанные колонки и предложенные соответствия сразу. Пользователь должен увидеть, чего система ожидает, прежде чем угадывать, и заметить отсутствующие поля до записи данных в базу.
Нужно ли заставлять пользователей сопоставлять каждую колонку?
Нет. Позвольте пропускать колонки, которые не нужны. В реальных таблицах часто есть заметки, пустые разделители и старые флаги — принуждение к сопоставлению только побуждает пользователей записывать мусор в рабочие поля.
Когда должна происходить валидация?
Проверяйте до импорта, а не после того, как строки начали записываться. Проверьте тип файла, размер, обязательные поля, дублирующее сопоставление целей и очевидные проблемы формата как можно раньше, чтобы пользователи решали проблемы на этапе предпросмотра.
Что делает предпросмотр импорта действительно полезным?
Полезный предпросмотр показывает реальные строки с уже сопоставленными полями, а не только сырые колонки таблицы. Так быстро видно, если Qty попало в Price или дата стала обычным текстом.
Как приложение должно показывать ошибки импорта?
Группируйте повторяющиеся проблемы и указывайте точные номера строк файла. Разделяйте блокирующие ошибки и предупреждения, а затем показывайте несколько примеров строк с исходным значением и краткой подсказкой, что исправить.
Пусть пользователи исправляют плохие строки в приложении или возвращаются в Excel?
Пусть исправляют внутри приложения. Встроенные правки, массовая замена и моментальная повторная проверка экономят много времени и избавляют от возвратов в Excel для каждого правки.
Что нужно сохранять для повторных импортов?
Сохраняйте сопоставления по клиенту, аккаунту или рабочей области, а также историю импорта и пример оригинальных заголовков. Это ускоряет повторные загрузки и помогает заметить изменения заголовков до того, как они испортят импорт.
Когда всё ещё нужны скрипты для импорта?
Используйте код только для случаев, которые действительно выходят за рамки правил продукта. Если одна и та же просьба повторяется, лучше встроить её в поток сопоставления, предпросмотра или валидации, а не писать ещё один одноразовый парсер.
Что протестировать перед выпуском инструмента импорта?
Тестируйте на грязных реальных файлах, а не на чистых образцах. Наблюдайте, как новичок загружает файл, сопоставляет колонки, смотрит ошибки и сам завершает импорт. После релиза отслеживайте: успешные импорты с первого раза, тикеты поддержки и запросы на ручные правки.


