Единая инфраструктура для клиентских продуктов без хаоса инструментов
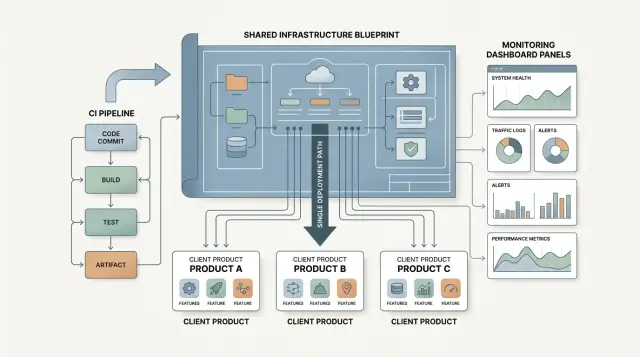
Постройте общую инфраструктуру для клиентских продуктов: одна CI-настройка, один стек мониторинга и один путь развертывания, чтобы сократить время запуска и дрейф конфигурации.
Содержание
Почему команды приходят к хаосу инструментов
Большинство команд не выбирают хаос специально. Он вырастает по одному проекту за раз.
Приходит новый клиент. Кто-то берет хостинг репозитория, который уже знает. Кто-то другой хочет другую CI-систему. Третий пока оставляет старый скрипт деплоя «временно», потому что он уже работает. Это временное решение остается, потом к следующему проекту добавляется еще один вариант.
Скоро это начинает дорого обходиться. Первый релиз занимает больше времени, потому что у каждого репозитория свои скрипты, секреты, правила веток и шаги развертывания. Любой, кто работает сразу с несколькими продуктами, особенно fractional CTO, может потерять часы только на то, чтобы понять, как одно приложение попадает в продакшн и почему другое до сих пор зависит от ручной команды.
Мониторинг дрейфует так же. Один продукт отправляет алерты в Slack. Другой использует email. Третий создает задачи, на которые после рабочего дня никто не смотрит. Когда что-то ломается, команда тратит время на поиск уведомления, потом разбирается, кто за него отвечает, и только после этого начинает исправление.
Ни одно из этих различий по отдельности не выглядит серьезным. Вместе они создают постоянный поток поддержки. Люди отвечают на одни и те же вопросы по настройке, переписывают одну и ту же документацию и чинят разовые скрипты, которые понятны только для одного клиента.
Общая база решает это заранее. Новые продукты стартуют с понятного пути для CI, мониторинга и развертывания. Команды по-прежнему могут делать исключения, но перестают снова и снова открывать тот же спор об инструментах при каждом новом проекте.
Что должно быть общим для каждого продукта
Большинству команд не нужна одна и та же кодовая база. Им нужны одни и те же правила работы.
Когда у каждого клиентского продукта своя структура репозитория, свои шаги выпуска и свой способ доступа, путаница появляется очень быстро. Через несколько месяцев никто уже не помнит, какое приложение разворачивается при merge, какое требует ручного тега, а где вообще смотреть ошибки. Общая часть должна ощущаться скучной и знакомой.
Хорошая база обычно включает одинаковую структуру репозитория, правила работы с ветками, этапы CI, путь релиза и подход к секретам. Инженер должен открыть любой проект и сразу найти код, файлы инфраструктуры, тесты и документацию, не блуждая по папкам. Все должны понимать, что идет в main, что требует проверки и что запускает релиз. Сборка, тестирование и выпуск должны происходить в одном и том же порядке каждый раз.
Это не значит, что все приложения должны выглядеть одинаково. Мобильное приложение и backend-сервис всегда будут отличаться. Цель — единообразие в доставке. Если одному продукту нужны дополнительные проверки безопасности или более длинный набор тестов, добавьте их поверх стандартного потока, а не заменяйте его.
Мониторинг должен работать по тому же принципу. Логи, отслеживание ошибок и проверки доступности должны находиться там, где одна команда может видеть их вместе. Когда срабатывает алерт, никто не должен спрашивать, какой дашборд использует клиент. Все уже должны знать, куда смотреть.
Контроль доступа вызывает столько же проблем, сколько и код. Заранее решите, кто может читать логи, кто может делать деплой, кто может менять секреты и как вы удаляете доступ, когда работа заканчивается. Команды, которые пропускают этот шаг, обычно исправляют его после первого неприятного сюрприза.
Именно здесь часто помогает внешнее техническое руководство. Олег Сотников работает с компаниями, которым нужен один стабильный подход к поставке на нескольких продуктах, а не новая настройка каждый раз. Задача обычно проста на бумаге: один раз задать правила, сохранить их понятными и дать каждому новому продукту начинать с чистой базы.
Выберите небольшой стандартный стек
Стандартный стек должен быть скучным в хорошем смысле. Если команда уже знает инструменты, она быстрее выпускает продукт, раньше исправляет проблемы и тратит меньше времени на споры о настройке. Это важнее, чем выбирать самый новый вариант.
Одинаковый подход экономит время. Когда каждое приложение стартует с одной и той же системой контроля версий, CI, мониторингом и путем деплоя, первая неделя проходит спокойно, а не хаотично.
Большинству команд достаточно одной системы контроля версий, одной CI-службы, одного трекера ошибок и одного места для логов, метрик и проверки доступности. Это не значит, что каждому клиенту нужен один и тот же runtime или один и тот же облачный аккаунт. Это значит, что команда каждый раз использует одни и те же привычки. Разработчики знают, где находятся пайплайны, где появляются алерты и где смотреть, если деплой не удался.
Компактный стек может использовать GitLab для контроля версий и CI, Sentry для ошибок и Grafana с Prometheus для дашбордов. Конкретные инструменты важны меньше, чем дисциплина вокруг них. Выберите небольшой набор, используйте его везде и сопротивляйтесь желанию постоянно добавлять новые инструменты.
Держите исключения редкими и записанными
Большинство расползания инструментов начинается с одного безобидного исключения. Клиент предпочитает другой хостинг репозитория. Один инженер хочет другой CI-сервис. Новое приложение получает отдельный инструмент мониторинга, потому что он был в шаблоне. Через шесть месяцев никто уже не помнит, где что находится.
Запишите несколько случаев, когда команда может отступить от стандарта. Для этого могут быть нужны юридические или комплаенс-требования. У клиента может уже быть внутренний системный инструмент, который вы обязаны использовать. Старый продукт может иметь необычную нагрузку, runtime или риски миграции, из-за которых стандартизация пока невыгодна.
Если исключение не связано с реальным ограничением, говорите нет. Это звучит жестко, но защищает скорость поставки. Небольшой стандартный стек дает каждому новому проекту стабильную основу, а значит, поддержку, найм и передачу дел легче держать под контролем.
Стройте базу шаг за шагом
Начните с работы, которую команда повторяет на каждом клиентском продукте. Не начинайте с инструментов. Начинайте с рутины.
Запишите, что происходит от первого коммита в репозитории до первого продакшн-релиза. Создайте репозиторий. Добавьте проверки. Настройте окружения. Подключите логи. Добавьте алерты. Разверните приложение. Проверьте, что оно здорово. Эта простая схема показывает, куда уходит время и какие части должны попасть в общую базу.
Затем превратите повторяющиеся шаги в скрипты, шаблоны и короткие чек-листы. Это важнее, чем многие ожидают. Если люди по-прежнему копируют команды из старого чата или забытой вики-страницы, процесс еще не стал стандартом. Поместите команды в скрипты. Поместите конфиг в шаблоны. Если каждому проекту нужны линтинг, тесты, шаг сборки и одна команда деплоя, сделайте так, чтобы это работало в первый день.
Стартовый репозиторий должен быть простым и удобным. Новая команда должна клонировать его, заменить несколько значений и сразу получить рабочий пайплайн. Добавьте базовые проверки CI, примеры переменных окружения, один путь развертывания и короткий README, в котором написано только то, что нужно человеку в первый час.
Не откладывайте мониторинг до появления трафика. Добавьте дашборды и алерты до первого релиза, даже если они пока базовые. Следите за статусом деплоя, количеством ошибок, временем ответа и доступностью. Простой алерт, который ловит сломанный релиз через пять минут, экономит больше времени, чем красивый дашборд, добавленный через три месяца.
Сначала проверьте весь путь на чем-то маленьком. Внутреннего админ-инструмента достаточно. Если репозиторий, CI-процесс, мониторинг и деплой работают там, они гораздо надежнее выдержат приход платного клиента. Первый сухой прогон обычно выявляет отсутствующие секреты, неясные скрипты и шум от алертов. Лучше исправить это один раз, чем заново находить те же проблемы в каждом новом проекте.
Задайте правила для исключений
Стандартный стек работает только тогда, когда люди ему доверяют. Это доверие ломается, когда команды чувствуют себя в ловушке и начинают добавлять сторонние инструменты без понятных правил.
Некоторые исключения разумны. У клиента может уже быть подписанный договор с поставщиком. Команда безопасности может потребовать определенный путь логирования. Старое приложение может зависеть от способа деплоя, который вы не можете заменить в этом месяце. Это нормальные случаи.
Важно, как команды подают запрос. Пусть он будет коротким и конкретным. «Стандартный CI не может запустить наш шаг подписи мобильного приложения» — этого достаточно. «Нам просто нравится этот инструмент больше» — обычно нет.
Хороший запрос отвечает на четыре вопроса: какую проблему создает стандартный путь, какой инструмент или процесс команда хочет вместо него, кто будет отвечать за это каждую неделю и какие дополнительные расходы или риски это добавит.
Соглашайтесь на исключения только тогда, когда стандарт мешает реальной работе. Если команда может решить проблему небольшой доработкой стандартного пайплайна, настройки мониторинга или пути деплоя, оставляйте стандартный вариант. Каждый дополнительный инструмент добавляет еще одно место, которое нужно проверять во время аварии.
Ответственность — это место, где большинство команд ошибается. В тот момент, когда вы разрешаете еще один сервис, назначьте одного человека, который отвечает за обновления, доступ, оплату, алерты и последующую очистку. Если никто не отвечает, команда забудет про него, пока не сломается релиз или не придет счет.
Храните каждое исключение в одном общем журнале. Достаточно короткой записи: дата, причина, владелец, затронутый продукт и дата пересмотра. Потом пересматривайте старые исключения каждый квартал. Некоторые появились только потому, что сроки были слишком жесткими. Другие остаются просто потому, что никто не спросил, нужны ли они до сих пор.
Одно исключение — это нормально. Пять неуправляемых исключений снова приводят к тому же хаосу.
Пример: одно агентство, три клиентских приложения
Представьте небольшое агентство, которое поддерживает три очень разных продукта. У одного клиента есть сайт-визитка, который меняется два раза в месяц. Другой ведет SaaS-приложение с ежедневными исправлениями и еженедельными релизами. Третий использует внутренний портал с более редкими выпусками и более строгими правилами доступа.
Продукты не делят код и не выходят в один и тот же день. Но команда дает всем трем один и тот же путь поставки. В каждом репозитории идут одинаковые стадии CI в одном и том же порядке: проверки, тесты, сборка, preview, одобрение продакшна. Названия остаются одинаковыми во всех проектах, так что никому не нужно останавливаться и расшифровывать нестандартную настройку.
Именно это и должна делать общая база. Она убирает скучные решения, не заставляя все приложения становиться одинаковыми.
Когда что-то ломается, агентству тоже не приходится гадать. Алерты используют один формат и каждый раз одни и те же несколько полей: название продукта, окружение, серьезность, последнее изменение и первое место, куда нужно смотреть. Дашборды устроены так же. Сверху — доступность, затем количество ошибок, время ответа, фоновые задачи и статус деплоя. Новый разработчик может открыть любое приложение и увидеть ту же карту.
Онбординг становится намного короче, потому что команда переиспользует базу, а не спорит об инструментах заново. Для нового клиента они создают репозиторий из шаблона, добавляют окружения и секреты, подключают мониторинг и правила алертов и включают стандартный путь деплоя. При этом у приложения остается свой график релизов. Сайт-визитка может публиковаться во вторник. SaaS-приложение может выкатывать срочный фикс в пятницу вечером. Внутренний портал может ждать ежемесячного окна утверждения. Общая инфраструктура не убирает эту свободу. Она просто сокращает время, которое уходит на соединение инструментов.
Именно это часто в первую очередь исправляет fractional CTO, потому что кастомный CI, кастомные алерты и кастомные скрипты деплоя съедают часы, почти ничего не давая взамен.
Ошибки, которые создают дрейф
Дрейф редко начинается с большого решения. Он начинается с обходных путей, которые кажутся безвредными для одного клиента, одного релиза или одного позднего пятничного деплоя.
Самый быстрый способ создать проблемы — скопировать старый пайплайн и вручную его править. Это кажется быстрым. На практике каждая копия получает мелкие изменения, забытые флаги и разные имена задач. Вскоре никто уже не знает, какой пайплайн актуален, а простые исправления занимают часы, потому что каждое клиентское приложение ведет себя немного по-своему.
Еще одна частая ошибка — позволять каждому клиенту добавлять новый инструмент без проверки стоимости. Одно приложение хочет другой CI-сервис, другое — отдельный инструмент логирования, а третье — собственный скрипт деплоя. Счет растет, но еще дороже стоит внимание. Команде теперь нужно помнить несколько способов делать одну и ту же работу.
Пропуск staging вызывает такой же дрейф. Команды убирают его, когда сроки поджимают, а потом добавляют разовые меры безопасности прямо в продакшне, чтобы компенсировать это. После нескольких спешных запусков у каждого продукта появляется свой путь релиза. Staging обходится дешевле, чем сюрпризы в продакшне, особенно когда несколько клиентских приложений используют одних и тех же людей.
Секреты создают еще один медленный сбой. Если пароли, токены или заметки о доступе попадают в чат, документацию или старые тикеты, никто не может доверять единому источнику правды. Ротация становится сложной. Вывод сотрудников из доступа становится рискованным. Хранилище секретов работает только если команда считает его единственным местом для живых учетных данных.
Шумные алерты, возможно, самая вредная ошибка, потому что они приучают людей игнорировать систему. Если мониторинг весь день шлет ложные срабатывания, инженеры отключают каналы или фильтруют сообщения. Тогда реальный сбой выглядит как еще одно бесполезное уведомление. Плотный базовый стек с понятными правилами алертов работает лучше по простой причине: чем меньше инструментов, тем меньше мест, где может накапливаться шум.
Если вы видите пайплайны, исправленные вручную, пропущенный staging, разбросанные секреты и отключенные алерты, дрейф уже начался.
Быстрая проверка перед новым проектом
Общая настройка работает только тогда, когда базу легко запускать, легко ей доверять и легко объяснить. Если до старта в этом есть туман, команда очень быстро скатится к одноразовым скриптам и кастомным исправлениям.
Перед новым проектом не нужен долгий аудит. Короткая проверка уже находит большинство слабых мест.
Сначала проверьте репозиторий. Команда должна уметь создать новый проект из шаблона в первый день, и при этом структура папок, CI-файл, схема окружений и путь развертывания уже должны быть на месте.
Затем прогоните один путь для сборки, тестирования и деплоя. Порядок должен быть одинаковым для всех продуктов. Если у одного клиентского приложения тесты идут перед сборкой, у другого тестов нет, а третье разворачивается вручную, общая база уже начинает расползаться.
Поместите ошибки, логи и проверку доступности туда, где люди могут видеть их вместе. Никто не должен открывать три разных инструмента, чтобы ответить на один простой вопрос: приложение сейчас в порядке?
Назначьте одного владельца для базового стека. Общие системы быстро приходят в упадок, когда каждый может их менять, а убирать последствия некому.
Потом сделайте простую проверку реальностью: попросите новую команду пересказать настройку после десятиминутного объяснения. Если они не могут сказать, куда идет код, как происходят релизы и где появляются проблемы, настройка слишком мудреная.
Этот последний тест важнее, чем многие думают. Хорошая настройка — не та, где больше всего автоматизации. Это та, которую занятый разработчик может понять еще до обеда.
Если хотя бы два из этих пунктов не проходят проверку, исправьте базу до того, как добавите еще одно приложение. Новые проекты должны наследовать работающую систему, а не кучу исключений.
Что делать дальше
Начните с жесткого подсчета того, что ваша команда уже поддерживает. Многие считают, что у них одна CI-настройка и один мониторинг, а потом находят несколько инструментов алертов, несколько скриптов деплоя и запутанный набор разовых решений для секретов. Соберите все в одну таблицу: CI, логи, метрики, проверки доступности, способ деплоя, хостинг и кто знает, как работает каждая часть.
Потом сначала сокращайте, а уже потом добавляйте. Если два инструмента делают одно и то же, выберите один и уберите второй. Дубликаты каждую неделю отнимают внимание. Команда, которая проверяет и Datadog, и Grafana, или и GitHub Actions, и GitLab CI, платит за эту путаницу более медленной передачей дел и пропущенными алертами.
Сначала держите внедрение небольшим. Проведите аудит активных продуктов, отметьте дубликаты и мертвые инструменты, выберите один общий стандарт для CI, мониторинга и деплоя, а потом протестируйте эту базу на менее рискованном проекте, прежде чем раскатывать ее шире. Один чистый запуск дает больше понимания, чем шесть совещаний по планированию.
Цель не в идеальной платформе. Цель — в базе, которую новая работа может унаследовать без споров. Если новому клиентскому приложению нужен CI, ответ уже должен существовать. Если нужны алерты, дашборды, правила деплоя и шаги отката, они должны начинаться с одного и того же шаблона каждый раз.
Простой пример хорошо это показывает. Допустим, ваше агентство начинает новый внутренний дашборд для клиента. Вместо того чтобы выбирать инструменты с нуля, вы клонируете стандартный репозиторий, включаете обычные проверки CI, отправляете ошибки в ту же систему отслеживания и разворачиваете через тот же путь, которому команда уже доверяет. Это может сэкономить дни в первый месяц и уберечь от странных пробелов позже.
Если нужен внешний взгляд, консультационная работа Олега Сотникова на oleg.is как раз сосредоточена на такой задаче: построить легкий стек поставки, уменьшить расползание инструментов и дать небольшой команде настройку, которую действительно можно поддерживать. Лучший результат — не более сложная система. А более спокойная.
Часто задаваемые вопросы
Почему проблема, если каждый клиентский продукт использует разные инструменты?
Потому что каждый дополнительный инструмент добавляет еще одно место, которое нужно проверять, объяснять и поддерживать. Смешанная настройка замедляет релизы, путает ответственность и превращает простые исправления в расследование по репозиториям, алертам, секретам и скриптам развертывания.
Что должно быть общим для каждого клиентского продукта?
Держите общую часть узкой и скучной: структура репозитория, правила работы с ветками, этапы CI, процесс релиза, работа с секретами, логи, отслеживание ошибок, проверки доступности и правила доступа. Само приложение может отличаться, но поставка должна быть знакомой во всех продуктах.
Насколько маленьким должен быть базовый стек?
Начните с меньшего набора, чем вам кажется нужным. Обычно хватает одного хостинга репозиториев, одной CI-системы, одного трекера ошибок и одного места для логов, метрик и проверки доступности. Если команда уже знает эти инструменты, она выпускает изменения быстрее и реже ошибается в настройке.
Когда исключение действительно оправдано?
Исключение имеет смысл только тогда, когда стандарт мешает реальной работе: из-за требований комплаенса, условий клиента или жесткого технического ограничения. Личные предпочтения не подходят. Спросите, кто будет отвечать за дополнительный инструмент, сколько он стоит и когда команда снова его пересмотрит.
Что должно быть в стартовом репозитории?
Добавьте в него все, что нужно в первый час работы. Включите обычную структуру папок, конфиг CI, шаги тестирования и сборки, примеры переменных окружения, один путь развертывания и короткий README. Команда должна клонировать его, изменить несколько значений и получить рабочий пайплайн без поиска старых заметок.
Нужно ли мониторить систему еще до запуска?
Да. Добавьте базовые дашборды и алерты до первого продакшн-релиза. Следите за статусом деплоя, количеством ошибок, временем ответа и доступностью заранее, чтобы команда быстро ловила сломанные релизы, а не гадала после жалоб пользователей.
Кто должен отвечать за общую инфраструктуру?
Назначьте одного владельца для общего стека. Этот человек поддерживает шаблоны в порядке, проверяет исключения, следит за расходами и удаляет старые инструменты, когда они больше не нужны. Без понятного владельца база быстро деградирует, и каждый новый проект снова начинает расходиться.
Как остановить расползание настройки со временем?
Запишите стандартный путь и превратите повторяющиеся шаги в скрипты и шаблоны. Пересматривайте исключения раз в квартал, храните их в одном общем журнале и говорите "нет" новым инструментам, если они не решают реальное ограничение. Дрейф начинается там, где команды держат одноразовые изменения в чате и памяти.
Как понять, что наша настройка уже слишком хаотична?
Если новый разработчик не может объяснить структуру репозитория, путь релиза и где смотреть мониторинг после короткого знакомства, настройка слишком усложнена. Другие тревожные признаки — правленные руками пайплайны, пропущенный staging, разбросанные секреты и алерты, которые люди отключают.
Что делать в первую очередь, если у нас уже слишком много инструментов?
Сначала проведите жесткий подсчет. Запишите все CI-сервисы, инструменты логирования, пути алертов, способы деплоя, хостинги и владельцев по всем активным продуктам. Потом уберите дубли, выберите один стандарт для каждой задачи и протестируйте эту базу на менее рискованном проекте, прежде чем раскатывать ее шире.


