Доменные события без event sourcing для реальных систем
Узнайте, как доменные события без event sourcing позволяют запускать письма, задачи и синхронизации на основе реальных бизнес‑фактов, сохраняя существующую базу данных.
Содержание
Почему командам нужны доменные события
Большинство бизнес‑действий не заканчиваются одной записью в базе. Клиент оплачивает счет, создает аккаунт или меняет тариф — и системе внезапно нужно сделать ещё работу: отправить квитанцию, обновить биллинг, обновить дашборд, уведомить поддержку и записать аудит.
Если всё это выполняется в одном запросе, мелкие проблемы превращаются в сбои, заметные пользователю. Медленный почтовый провайдер может задержать оплату, тяжёлый отчётный запрос — замедлить API. Одна сломанная интеграция может сделать действие «провалившимся», хотя основное изменение данных прошло корректно.
Большинство команд хочет проще: сначала сохранить бизнес‑изменение, а затем позволить сопутствующей работе идти своей дорогой.
Для этого и нужны доменные события. Они фиксируют факт на языке предметной области: "счет оплачен", "аккаунт активирован", "подписка отменена". Событие — это не письмо, не вебхук и не обновление отчёта. Это факт, на который эти действия реагируют.
Это разделение важно в повседневной работе. Когда поддержка спрашивает, что произошло, команда видит ясную запись вместо догадок по логам. Если downstream‑воркер падёт, систему можно повторно попытать выполнить сопутствующие задачи без просьбы к пользователю повторить исходное действие. Если другая команда захочет тот же факт позже, она подпишется на событие вместо добавления кода в основную транзакцию.
Именно поэтому доменные события без event sourcing подходят для многих реальных систем. Вы сохраняете обычные таблицы и обычные записи. Не нужно перестраивать хранилище вокруг лога событий. Публикуйте бизнес‑факты, чтобы другие части системы могли реагировать после завершения основной транзакции.
Хорошее событие даёт остальной системе понятное утверждение, которому можно доверять. «Платёж получен» ясно. «Выполнять пост‑платёжные задачи» — нет. Первое говорит, что случилось. Второе смешивает факт и работу и обычно ведёт к жёсткой связанности.
Разделите это как можно раньше — запросы будут быстрее, отказы будут локализованы, и систему станет проще понимать, когда продакшн шумит.
Что считается бизнес‑фактом
Доменное событие должно говорить о том, что действительно произошло в бизнесе, а не о том, что именно изменила база данных. Это звучит мелочно, но меняет всё. OrderPaid — факт. OrderRowUpdated — только деталь хранения.
Когда команды трактуют обновления таблиц как события, downstream‑действия быстро портятся. Другой сервис не поймёт, важно ли изменение, окончательно ли оно или это часть внутренней чистки. Бизнес‑факт даёт остальной системе то, во что можно верить и на что можно реагировать.
Хорошие имена событий звучат как простая фраза, которую люди скажут на встрече. Если поддержка, финансы или ops могут прочитать имя и понять, о чём речь, вы обычно близки к идеалу. InvoiceIssued, SubscriptionCanceled, PasswordResetRequested — понятно. UserStatusChanged — расплывчато. RecordPatched — ещё хуже.
Каждое событие должно нести один факт. Упакуйте несколько вещей в одно сообщение — и потребители начнут угадывать, какая часть важна. Так простые потоки становятся хрупкими. OrderPaidAndPacked экономит один вызов публикации, но создаёт путаницу, если платёж прошёл, а упаковка — нет.
Простой тест помогает: скажите событие коротким предложением в прошедшем времени. Проверьте, поймёт ли это нетехнический человек. Убедитесь, что оно описывает бизнес‑смысл, а не запись в таблице, и что другой сервис может отреагировать, не зная вашей схемы. Если в событии больше одного факта — разделите.
Различие видно на маленьком примере заказа. Если клиент платит, событие не payments.updated, потому что в таблице payments поменялась строка. Факт — OrderPaid или PaymentCaptured, в зависимости от того, что важно бизнесу. Логистика, почта и отчёты могут реагировать на это без чтения вашей внутренней модели.
Вот почему доменные события без event sourcing остаются практичными. Вы сохраняете привычную модель данных, но публикуете факты, соответствующие реальным бизнес‑моментам. Если модель хранения изменится, факт может оставаться прежним — и в этом ценность события.
Когда event sourcing — лишний инструмент
Event sourcing имеет смысл, когда лог событий — это тот самый источник правды, и вы хотите восстанавливать состояние из него. Многие команды в этом не нуждаются. Им нужен надёжный способ сообщить другим частям системы, что произошло что‑то важное, например «заказ оплачен» или «аккаунт одобрен», чтобы последующие задания могли отреагировать.
Если ваша текущая база уже хранит состояние, которому команда доверяет — оставьте её. Приложение сейчас читает из неё, поддержка проверяет её, финансы экспортируют данные из неё. Заменить это event store’ом — означает сменить источник правды и стиль интеграции одновременно. Это большой шаг, когда цель чаще всего гораздо скромнее.
Большинство команд, рассматривающих доменные события без event sourcing, хотят последующие действия, а не новую модель хранения. Им нужно отправить квитанцию, уведомить логистику, обновить CRM или запустить задачу биллинга после успешного бизнес‑изменения. Для этого ваши существующие таблицы могут остаться на месте.
Стоимость event sourcing — не только запись событий. Нужно перестроить чтения, решить, как воспроизводить историю, обрабатывать старые версии событий и тестировать много крайних случаев. Если система уже живёт, эта работа ляжет на все пути создания и обновления сразу. Малые команды обычно быстро чувствуют эту цену.
Обычная база данных плюс бизнес‑события часто лучше подходят. Сохраните состояние, которому вы уже доверяете, а затем опубликуйте событие в той же транзакции, часто используя паттерн transactional outbox. Downstream‑части слушают факты, которые уже истинны в базе.
Возьмём заказную систему. Когда платёж успешен, строка заказа меняется на "paid". Эта запись остаётся корпоративным источником правды. Событие нужно, чтобы почта, исполнение и отчётность могли сделать свою работу. Если одна из этих шагов позже провалится, данные заказа останутся корректными, и вы сможете повторить сопутствующую работу, не споря о том, что является истиной.
Выбирайте event sourcing, когда сама история должна управлять всей системой. Пропустите его, если вам в основном нужны надёжные downstream‑действия и изменение вписывается в текущую систему.
Как работает поток шаг за шагом
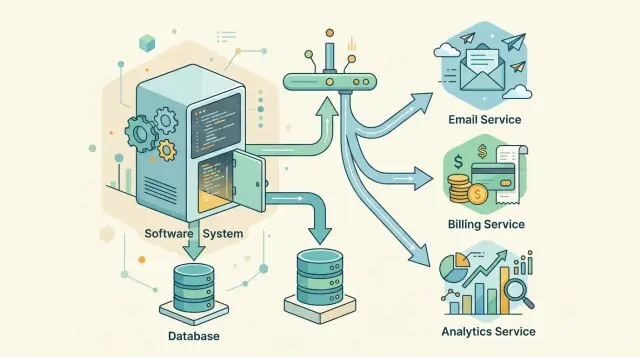
Самый безопасный вариант начинается с записи в базу, которой вы уже доверяете. Если заказ меняет статус с "pending" на "paid", ваше приложение сохраняет это изменение в обычной транзакции. Вы не перестраиваете хранение и не перестраиваете приложение вокруг лога событий.
Затем в ту же транзакцию вставляется ещё одна строка в таблицу outbox. Эта строка — бизнес‑событие, например OrderPaid, с ID заказа, отметкой времени и небольшой порцией данных, нужной другим частям. Важно записывать заказ и outbox‑запись вместе: если одно прошло, то и другое — тоже.
Обычный поток выглядит так:
- Запрос обновляет основную запись в базе приложения.
- Тот же коммит добавляет запись в outbox с формулировкой на языке бизнеса.
- Фоновый воркер опрашивает outbox и публикует непереданные события в очередь или брокеру.
- Другие сервисы обрабатывают событие позже, в своём темпе, а воркер помечает outbox‑строку как отправленную.
Многие команды запускают воркер каждую секунду или чаще. Он может читать строки по порядку, публиковать небольшой батч и затем ставить время отправки или статус. Даже на одной базе это устраняет большинство проблем с потерей событий.
Разрыв между «сохранено» и «опубликовано» — нормален и полезен. Почта, биллинг, индексирование поиска и логирование аудита не должны тормозить исходное действие пользователя. Если заказ оплачен — сохрани это сначала. Отправь квитанцию немного позже.
Отказы всё равно случаются, поэтому outbox нужно ретраить. Воркер может потерять сеть, брокер отклонить сообщение или consumer быть недоступен десять минут. Ничто из этого не должно менять исходную запись заказа. Воркер повторяет отправку до подтверждения, а потребители должны безопасно обрабатывать дубликаты, проверяя event ID или другой надёжный идентификатор.
Это практическая форма доменных событий без event sourcing. Вы сохраняете модель данных, которая уже управляет бизнесом, публикуете бизнес‑события для downstream‑действий и позволяете каждой части реагировать без общей хрупкой транзакции.
Выбирайте события, которым другие смогут доверять
Хорошие события описывают то, что уже произошло и важно для других частей системы. OrderPaid подходит. PaymentCheckStarted обычно — нет. Другие команды могут действовать на основании «оплачен», «отправлен», «возвращён» или «подписка отменена», потому что эти моменты значимы для поддержки, финансов и операций.
Доверие начинается с общего смысла. Если один сервис называет «paid», когда карта только авторизована, а другой считает это как списание денег, баги появятся быстро. Дайте каждому событию короткое определение на простом языке и укажите команду, ответственной за эту семантику. Если billing владеет InvoicePaid, все знают, кто решает спорные случаи.
Событие должно содержать достаточно деталей для downstream‑действий, но не заставлять всех делать лишние запросы. Большинство событий нуждаются в стабильном ID события, ID бизнес‑записи как order_id, времени события, сумме и валюте, если были деньги, и схеме или версии события.
Версионирование стоит добавить с первого дня. Возможно, вам не понадобится версия 2 месяцами, но будущему себе вы будете благодарны. Старайтесь эволюционировать события, добавляя поля, а не меняя значение существующего поля.
Держите приватные данные в стороне, если они действительно не нужны. Сервис логистики не нуждается в деталях карты. Для возврата может хватить ID заказа, ID платежа, суммы и причины, но не полного профайла клиента. Меньше данных — меньше рисков, меньше проблем с комплаенсом и меньше споров.
Небольшой пример: при capture платежа опубликуйте событие с order ID, payment ID, суммой, валютой, временем capture и версией. Не включайте внутренние пометки по fraud или raw payload от платёжного шлюза. Склад проигнорирует ненужное, финансы зарегиструют своё, аналитика посчитает без догадок.
Если имя события может запутать агента поддержки в пятницу вечером — переименуйте его до релиза.
Простой пример заказа
Представьте обычный онлайн‑заказ. Клиент вводит данные карты, платёж провайдер подтверждает списание, и checkout меняет заказ с "pending" на "paid".
Это изменение статуса — бизнес‑факт. Checkout обновляет строку заказа и в той же транзакции записывает OrderPaid в таблицу outbox. Это паттерн transactional outbox: база изменения и событие остаются синхронизированы.
Так выглядят доменные события без event sourcing в форме, которую большинство команд может быстро запустить. Вы оставляете обычные таблицы, но публикуете бизнес‑события, которым другие части системы могут доверять.
Событие не нуждается в полной истории заказа. Ему достаточно фактов, на которые другие части могут опереться: order ID, customer ID, сумма оплаты, валюта и время оплаты.
Фоновый воркер читает outbox и публикует событие. После этого другие части системы реагируют в своём темпе, а не в рамках одной большой транзакции.
Сервис рассылки отправляет письмо. Он не спрашивает у checkout, произошло ли списание «наверное». Он видит OrderPaid, отправляет квитанцию и ретраит, если почтовый провайдер даёт сбой.
Склад создаёт задачу на упаковку. Ему не нужно знать, какой платёжный шлюз обрабатывал карту или что происходило на странице checkout. Ему нужен один понятный факт: клиент заплатил — можно упаковывать.
Финансы записывают выручку в своём процессе. Такое разделение помогает больше, чем кажется: финансы часто имеют отдельные правила, отчёты и сроки, поэтому им не место в коде checkout.
Если сервис почты упадёт на десять минут, заказ всё равно остаётся оплачен. Если очередь склада замедлится, финансы всё ещё могут учесть доход. Каждая часть делает своё, а checkout остаётся сфокусирован на продаже.
Одно доверенное событие может запустить несколько downstream‑действий без перекомпоновки модели хранения в стиле event sourcing.
Ошибки, разрушающие модель
С доменными событиями без event sourcing модель остаётся простой только если события честны. Большинство проблем начинается, когда команда публикует неверный факт или делает это в неверный момент.
Первая ошибка — отправить событие до завершения коммита. Если приложение эмитит OrderPaid, а транзакция откатывается, другие части системы могут всё равно отправить квитанцию, зарезервировать товар или уведомить клиента. Тогда событие говорит о том, чего не было. Паттерн transactional outbox решает это: событие сохраняется в той же транзакции, а доставляется уже после коммита.
Ещё одна ошибка — использовать расплывчатые имена вроде order_updated или customer_changed. Такие сообщения не имеют чёткого бизнес‑смысла. Подтверждение платежа, исправление адреса и удаление позиции — разные факты с разными последствиями. Если потребителям приходится заглядывать в базу, чтобы догадаться, что изменилось, событие не выполнило свою задачу.
Команды также ломают модель, упаковывая несколько фактов в одно событие. Большая полезная нагрузка с множеством опциональных полей выглядит гибкой, но перекладывает сложность на каждого потребителя. Одна команда прочитает это как «оплачен», другая — «готово к отправке», третья проигнорирует половину полей. Небольшие конкретные события обычно лучше, потому что каждое рассказывает одну историю.
Дубликаты доставки создают тихие баги, когда команды предполагают, что потребитель прочитает событие только один раз. Системы реальны: ретраи, рестарты воркеров, сетевые отказы. Потребитель должен корректно обработать повторное событие без двойного снятия денег или отправки двух писем. Event ID, записи для дедупликации или идемпотентные обработчики обычно решают эту проблему.
Изменения полей тоже вредят. Если одна команда переименует поле или поменяет его смысл без плана версий, старые потребители могут сломаться за ночь. Держите контракты событий стабильными. Добавляйте поля совместимым образом, оставляйте старые ещё некоторое время и версионируйте событие при серьёзных изменениях.
Простой тест‑запах: событие уходит только после успешного коммита, имя описывает один бизнес‑факт, полезная нагрузка рассказывает одну историю, потребители безопасно обрабатывают дубликаты, а старые потребители читают следующую версию. Если что‑то из этого ломается — downstream‑действия начнут расходиться с реальностью.
Быстрая проверка перед релизом
Небольшой ревью сейчас сэкономит массу проблем потом. С доменными событиями без event sourcing сложность редко в публикации первого события. Сложность — в том, чтобы другие части системы могли доверять ему, когда что‑то идёт не так.
Начните с имени события. Если кто‑то, кто не писал код, читает OrderPaid или InvoiceSent, он должен понять, что произошло, без просмотра кода. Если имя требует длинного объяснения — скорее всего оно смешивает бизнес‑факты и внутренние шаги.
Полезное событие выживает при сбое. Сохраните бизнес‑изменение и запись в outbox вместе, затем убедитесь, что вы можете опубликовать то же событие повторно, если воркер остановится на полпути. Многие команды думают, что задача выполнена, когда коммит в базе прошёл. На самом деле всё закончено, только когда downstream‑действие может произойти после рестарта.
Дубликаты — нормальная вещь. Сети и очереди падают, ретраи происходят. Потребители должны уметь сказать «я уже обработал это» и двигаться дальше. Обычно это означает проверку идемпотентности по event ID или бизнес‑идентификатору.
Трассируемость важнее, чем кажется. Выберите одно событие и проследите его от записи в базу, через outbox, паблишер, очередь или брокер, до потребителя и итогового действия. Если вы не можете проделать этот путь за несколько минут, продакшн‑дебаг будет медленным.
Делайте первый релиз узким. Внедрите одно событие и одного потребителя сначала. Протестируйте крах между сохранением и публикацией. Повторите событие и убедитесь, что ничего не ломается. Проверьте, что логи показывают один и тот же event ID от начала до конца. Малый объём заставляет принимать ясные решения и помогает выловить плохие имена, отсутствующие ID и баги ретраев до того, как они разойдутся по системе.
Правило: если вы не можете объяснить событие поддержке, продукту или другому инженеру в одном коротком предложении — не выпускайте. Чистые имена, воспроизведение после сбоя, безопасные к дубликатам потребители и прослеживаемый поток важнее, чем добавить ещё пять событий на этой неделе.
Следующие шаги для небольшого роллаута
Небольшой роллаут лучше всего, когда он сразу убирает какую‑то утомительную ручную работу. Выберите бизнес‑факт, который уже требует последующих действий, например invoice_paid или order_shipped. Если кто‑то до сих пор отправляет письма вручную, копирует данные в другой инструмент или проверяет статусную страницу утром — это сильный кандидат.
Держите первую версию простой. Одна команда выполняет обновление основной записи. В той же транзакции вы пишете одну строку в outbox. Воркер публикует эту строку, и один потребитель на неё реагирует. Этого достаточно, чтобы протестировать доменные события без event sourcing в реальной системе, не перестраивая модель хранения.
Добавьте мониторинг до того, как начнёте добавлять другие события. Молчаливые отказы вредят сильнее, чем заметные баги. Измеряйте лаг outbox, чтобы команда видела, как долго события ждут публикации. Считайте не только успешные отправки, но и ошибки и попытки повторной отправки. Храните сообщения в dead‑letter в одном месте, которое люди действительно проверяют. Настраивайте алерты на всплески ретраев — они часто появляются раньше, чем пользователи что‑то заметят.
Раннее правило именования сэкономит время. После второго‑третьего события зачистка становится дорогой. Используйте прошедшее время для фактов, держите полезную нагрузку маленькой и включайте устойчивые идентификаторы, которым другие сервисы могут доверять. Если одно событие называется user_registered, а другое — account_create_done, команда будет тратить время на споры о смысле вместо того, чтобы выпускать функциональность.
Также разделяйте команды (commands) и факты (events). ShipOrder говорит системе, что нужно сделать. order_shipped говорит, что это уже сделано. Если люди путают стороны команд и событий, проговорите их вместе до публикации новых сообщений.
Если команде нужна вторая пара глаз по границам событий, дизайну outbox или плану постепенного развёртывания, Oleg Sotnikov делает такую Fractional CTO работу для стартапов и небольших компаний через oleg.is. Это ревью, которое помогает на ранних этапах, когда изменить три события — дело пары часов, а не полная переделка позже.
Часто задаваемые вопросы
What is a domain event?
A domain event is a plain statement that a business action already happened, such as OrderPaid or SubscriptionCanceled. Other parts of the system react to that fact later instead of joining the original request.
Do I need event sourcing to use domain events?
No. Most teams keep their normal tables and publish business facts after the main write succeeds. Pick event sourcing only when you want the event log to be the source of truth and rebuild state from it.
Why not do all follow-up work in the same request?
Because one slow or broken dependency can turn a successful business change into a user-facing failure. Save the main change first, then let email, reporting, and other jobs run on their own path.
When should I publish the event?
Publish it only after the business change commits. The usual fix is a transactional outbox: write the record change and the outbox row in one transaction, then let a worker publish after commit.
What makes a good event name?
Use plain business language in past tense. InvoicePaid tells people what happened. Names like row_updated or user_changed force every consumer to guess.
What should the event payload include?
Keep it small but useful. Include a durable event ID, the business record ID, the event time, and any facts another service needs right away, like amount and currency. Leave out private or internal data unless a consumer truly needs it.
How do I handle duplicate events?
Assume retries will happen. Give each event a stable ID and make consumers check whether they already handled it before they send another email, charge again, or create the same task twice.
Can this work with a single database?
Yes. Many teams start with one app database, one outbox table, and one worker that publishes events every second or faster. That setup solves a lot of real problems without changing the storage model.
What mistakes break this pattern?
Teams usually get hurt when they publish before commit, use vague names, pack several facts into one event, or change fields with no version plan. Keep each event honest, small, and steady.
How should a small team roll this out first?
Start with one business fact that already creates manual follow-up work, like OrderPaid or InvoiceSent. Ship one producer and one consumer, test a crash between save and publish, and trace the same event ID from the database to the final action.


