Дизайн доставки вебхуков для мгновенной синхронизации клиентов
Дизайн доставки вебхуков влияет на повторы, порядок событий и видимость ошибок. Установите правила заранее, чтобы баги синхронизации не превратились в работу поддержки.
Содержание
Почему мгновенная синхронизация в реальности даёт сбои
Клиенты называют что-то «мгновенным», когда другая система обновляется раньше, чем они успевают обновить страницу. На практике они замечают лаг уже через несколько секунд. Пять секунд кажутся сломанными, когда платёж подтверждён, счёт мест изменился или статус заказа поменялся.
Большинство сбоев вебхуков не начинаются с плохого кода. Они начинаются с обычного сетевого поведения. Приёмник отвечает слишком долго, возвращает ошибку или завершается после того, как отправитель перестал ждать. Поэтому команды должны продумать правила доставки до запуска, а не после первой волны обращений в поддержку.
Один медленный endpoint может причинить больше вреда, чем ожидают. Если все события идут через одну общую очередь, таймаут одного клиента может задержать всё, что за ним. Тогда у одного аккаунта проблема, а у многих других складывается впечатление, что их данные устарели, хотя их системы работают нормально.
Таймауты особенно коварны, потому что они могут скрыть успешную запись. Отправитель может перестать ждать через 10 секунд, пометить попытку как неудачную и запланировать повтор. Система клиента может завершить запись на 11-й секунде. Теперь то же обновление может прийти дважды, и обе стороны честно скажут, что обработали его правильно.
Отсутствующие обновления создают другой вид беспорядка. Когда статус подписки, состояние счёта или права пользователя не синхронизируются, клиенты редко предполагают, что событие потеряли. Они открывают тикет, просят ручную правку и начинают внимательнее следить за каждым изменением.
Нагрузка на поддержку быстро накапливается. Кто-то проверяет логи вручную, кто-то проигрывает событие, кто-то объясняет несоответствие клиенту, и кто-то ещё начинает думать, не страдают ли другие аккаунты от той же проблемы. С точки зрения клиента это не выглядит как проблема доставки — это выглядит как ненадёжный продукт.
Небольшие задержки нормальны. Скрытые задержки превращают фоновую синхронизацию в работу по сопровождению аккаунтов. Если вы не выберете правила повторов, поведение очереди и видимость ошибок заранее, команда поддержки будет принимать эти решения позже, по одному тикету за раз.
Решите, что означает «мгновенно»
Большинство команд говорят «мгновенно», когда на самом деле имеют в виду «достаточно быстро, чтобы клиенты не заметили». Задайте числовое значение до релиза. Без него каждая небольшая задержка превращается в спор о том, работает ли система.
Установите нормальную цель доставки в секундах. Для многих бизнес-процессов 3–10 секунд ощущаются достаточно мгновенно. Если платёж, регистрация или изменение подписки доходят до другой системы в этом окне, большинство пользователей доверит синхронизации.
Потом задайте второе число: максимально допустимую задержку, после которой продукт показывает предупреждение. Это число обычно значительно больше. Вы можете стремиться доставлять большинство событий за 5 секунд, но показывать предупреждение, если синхронизация всё ещё в ожидании через 60 секунд.
Эти числа решают разные задачи. Первое направляет инженеров. Второе защищает пользовательский опыт.
Пользователям нужна информация, а не тишина. Нужна простая модель:
- Queued: ваше приложение приняло изменение и отправит его
- Sent: endpoint принял вебхук
- Failed: доставка остановилась и требует внимания
Это важно, потому что успех в приложении и успех синхронизации — не одно и то же. Клиент может обновить подписку в вашем приложении, и это обновление может успешно сохраниться в вашей БД, в то время как вебхук ещё ждёт в очереди или падает на стороне приёмника. Если вы показываете только «сохранено», люди предполагают, что другая система уже получила изменение.
Отсюда и начинается путаница. Продажи видят один план, биллинг — другой, и менеджеры по аккаунтам объясняют задержку, которую никто не видел.
Лучший подход прост. Подтвердите действие в приложении сразу, затем рядом покажите статус синхронизации. «Подписка обновлена» и «Синхронизация ожидает» могут сосуществовать без противоречий. Эта маленькая деталь предотвращает массу лишних переписок позже.
Если продукт нуждается в почти мгновенных обновлениях в нескольких инструментах, решите это заранее. Чёткая цель по времени и видимый статус всегда лучше оптимистичных формулировок.
Выберите контракт доставки
Клиентам не важно, как устроена ваша шина событий. Им важено ясное обещание: что вы отправляете, что может повторяться и как понять, обработали ли это уже. Если это обещание расплывчато, в поддержке появятся дублирующиеся записи и странные смены статусов.
Для большинства продуктов по умолчанию подходит доставка хотя бы один раз (at-least-once). Скажите это прямо. Вебхук может прийти дважды, и повтор должен использовать тот же идентификатор события, что и первая попытка. Это даёт клиентам правило, вокруг которого можно строить логику, вместо угадываний по поведению.
Каждый запрос должен содержать несколько полей, которые не меняются при повторах: постоянный event ID, метка времени события, версия ресурса или номер последовательности и подпись запроса.
ID события позволяет клиенту безопасно дедуплицировать. Если их endpoint таймаутит после обработки вашего вебхука, вы повторите отправку, и они могут увидеть то же событие снова. Когда ID остаётся тем же, они могут сохранить его и игнорировать дубликат без догадок.
Метки времени и версии ресурса решают другую задачу. Вебхуки не всегда приходят в том порядке, в котором вы их отправляете. Если клиент получает версию 18 подписки, а через несколько секунд приходит версия 17, старое событие не должно перезаписать новое. Метка времени помогает при аудите. Номер версии даёт более ясное правило, какая версия побеждает.
Делайте полезную нагрузку маленькой и лёгкой для парсинга. Отправляйте тип события, ID ресурса, текущую версию и поля, которые приёмнику обычно нужны сразу. Не дублируйте все связанные объекты в каждом вебхуке. Большие полезные нагрузки чаще ломаются, дольше обрабатываются и усложняют изменения схемы.
Подписывайте каждый запрос. Клиентам нужен простой способ подтвердить, что вебхук пришёл от вас и что тело не изменили в пути. HMAC-подписи распространены: их легко проверять и легко менять, когда секреты меняются.
Хороший контракт доставки не скрывает сбои. Он даёт клиентам структуру, чтобы обрабатывать повторы, игнорировать устаревшие события и доверять источнику с первого дня.
Настройте правила повторов пошагово
Плохие правила повторов превращают небольшой сбой в дубли, разгневанных клиентов и тикеты поддержки. Если клиенты ждут мгновенной синхронизации, нужны быстрые первые повторы, затем более редкие и чёткая точка, где система останавливается.
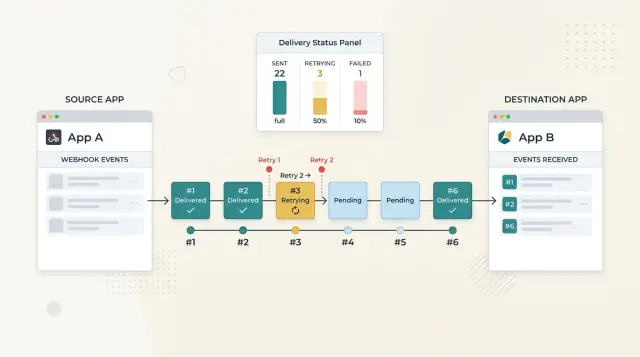
Начните с коротких задержек для ошибок, которые часто проходят сами. Таймаут, временный разрыв сети или кратковременная перегрузка приёмника могут исчезнуть за секунды. Первая повторная попытка должна быть быстрой, чтобы небольшой сбой не стал видимым рассинхроном.
Простой график часто хорошо работает: повтор через 10 секунд, затем 30 секунд, затем 2 минуты, затем 10 минут, затем 1 час. После этого замедлите повторы или остановите их в зависимости от типа события и того, насколько свежими должны быть данные. Обновление биллинга может быть важно и завтра, а событие о статусе набора символов — нет.
Большинству команд лучше иметь фиксированное окно повторов, например 24 часа, чем бесконечные повторы в фоне. Бесконечные повторы кажутся безопасными, но обычно просто скрывают сломанные интеграции.
Будьте строги в выборе ответов, при которых повторять. Повторяйте, когда приёмник может восстановиться: таймауты, HTTP 429 и 5xx. Не повторяйте 4xx, такие как 400, 401, 403, 404 или 422, если только вы не знаете, что приёмник может исправить проблему без нового события. Повторы в таких случаях только создают шум.
Когда событие по-прежнему падает после окна повторов, переместите его из обычного потока в очередь для повторной отправки (replay queue). Это держит живой трафик чистым и даёт поддержке или операционному отделу безопасное место для инспекции, исправления и пересылки события. В очереди для повторов должны храниться полезная нагрузка, история ответов, число попыток и последнее сообщение об ошибке.
Одна мелочь экономит много боли: добавьте случайность в тайминги повторов. Если один endpoint клиента упал и вернулся, не хочется, чтобы десять тысяч повторных попыток ударили по нему в одну секунду.
Выбирайте правила порядка, которые устроят клиентов
Большинство команд хотят строгий порядок, пока не увидят, сколько это стоит. Если одно событие застрянет, все, что за ним, тоже ждёт. На бумаге это аккуратно, но клиенты обычно больше ценят видеть актуальное состояние, чем идеальную воспроизводимость всех изменений.
Лучший дефолт — сохранять порядок лишь там, где это важно. Отправляйте события в порядке по клиенту, по аккаунту или по записи (например, подписке, счёту или профилю пользователя). Это даёт предсказуемое поведение без превращения одного задержанного вебхука в пробку для всех арендаторов.
Не обещайте один глобальный порядок для всего трафика. Это дорого, хрупко и редко полезно. Если клиент A обновил профиль биллинга, клиент B не должен ждать, потому что какое-то не связанное событие всё ещё повторяется.
Когда порядок важен, добавляйте номер последовательности или версию в каждое событие для этой записи. Приёмник может сравнить то, что пришло, с тем, что у него уже есть. Если событие 42 пришло раньше 41, приёмник может немного подождать, запросить текущее состояние или принять 42 и проигнорировать 41, когда он наконец придёт.
Последний вариант часто самый простой. Новые версии должны заменять старые. Событие subscription.updated с версией 9 должно побеждать версию 8, даже если версия 8 приходит позже. Это правило сокращает количество проблем в поддержке, потому что устаревшие данные не перезаписывают свежие.
Скажите это прямо в документации и поведении продукта. Порядок применим только в пределах одной записи. Новые версии заменяют старые. Могут появляться дубликаты, и приёмники должны игнорировать повторы. После разрыва приёмник может получить текущее состояние вместо вечного ожидания.
Напишите этот контракт до релиза, а не внутри ответов поддержки после него. Когда интеграторы готовят решения под реальность, синхронизация ломается реже.
Покажите сбои до того, как о них услышит поддержка
Тихо падающий вебхук быстро создаёт работу для поддержки. Клиенты замечают пропуск синхронизации раньше, чем ваша команда, и кто-то должен копаться в логах, спрашивать детали endpoint и объяснять, что произошло, имея лишь часть истории.
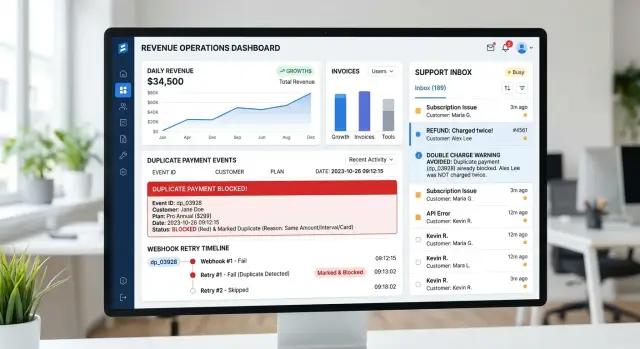
Нужна одна точка, которая делает проблемы доставки очевидными. Полезный лог доставки показывает каждое событие, когда вы его отправили, какой endpoint его получил, код ответа и будет ли попытка повторяться или остановится.
Что должна видеть поддержка и клиенты
Вид не должен быть причудливым. Для каждого endpoint клиента покажите последнее успешное доставление, самую последнюю ошибку, время следующей попытки и сколько попыток ещё в очереди.
Краткое сводное представление также должно группировать ошибки по endpoint и по аккаунту. Повторяющиеся коды ответа, например 401, 404 или 500, должны выделяться. Также должны выделяться endpoints с растущей очередью повторов или без недавних успешных доставок.
Эти паттерны экономят время, потому что указывают на реальную проблему сразу. Если один клиент сменил учётные данные, вы увидите кластер 401. Если endpoint упал, вы увидите, что повторы скапливаются в рамках одного аккаунта, вместо того чтобы гоняться за рандомными пропавшими обновлениями.
Команде также нужны алерты до того, как очередь превратится в бедлам. Оповещайте о росте бэклога повторов, высокой частоте ошибок на одном endpoint или отсутствии успешных доставок по многим аккаунтам. Для небольшой команды это особенно важно: одна скрытая проблема с вебхуками может съесть целую неделю на уборку.
Поддержке не должен быть нужен инженер для каждого исправления. Дайте им безопасное действие «повторить» для одного события или короткого временного диапазона с понятными ограничениями. Если клиент починил endpoint пять минут назад, поддержка должна суметь переслать пропущенные события и подтвердить, что доставка прошла успешно.
Сохраняйте историю повторов тоже видимой. Если поддержка повторила десять событий и восемь прошли успешно, все сразу увидят прогресс. Если они снова падают с тем же кодом, следующий шаг очевиден, а разговор с клиентом остаётся коротким.
Вот реальная цель видимости неудачных вебхуков: уменьшить догадки, сократить цепочки в поддержке и не дать рутинным проблемам доставки превратиться в работу по сопровождению аккаунтов.
Простой пример с обновлениями подписки
Клиент повышает тариф с Basic до Pro в вашем приложении в 10:03. Приложение сначала сохраняет новый план, поэтому база данных остаётся источником правды даже если все downstream-вызовы упадут.
Сразу после этого система создаёт одно событие, например subscription.updated, с event ID и номером версии для этого клиента. Это даёт одну ясную запись о том, что изменилось, когда и какие системы ещё должны получить обновление.
Биллинг получает событие первым и возвращает 200 OK за несколько секунд. CRM — нет. Он таймаутит.
Это не должно откатывать апгрейд или замораживать всю очередь. Клиент уже сменил план, и биллинг уже принял обновление. У CRM просто проблема с доставкой.
Разумный поток прост. Приложение помечает биллинг как доставленный. CRM помечается как неудача на попытке 1. Планируется следующая попытка для CRM, например через минуту. Тем временем несвязанные события продолжают двигаться.
Если тот же клиент что-то изменит до восстановления CRM, у вас есть два безопасных варианта. Можно обеспечить порядок по клиенту только для CRM, или можно включить номер версии и позволить CRM игнорировать старые события, если пришла новая версия. Большинство команд предпочитает второй вариант, потому что он избегает пробок.
Допустим, клиент добавляет места в 10:05. Биллинг получает это новое событие сразу. CRM всё ещё не обработал апгрейд плана, но это не должно навсегда блокировать обновление мест. Когда CRM вернётся, он применит самую новую версию и пропустит устаревшие повторы.
Поддержке тоже нужен ясный вид проблемы. Когда клиент спрашивает: «Почему в моём CRM до сих пор старый план?», поддержке не должно приходиться копаться в логах.
Они должны видеть одну строку с event ID, аккаунтом клиента, статусом назначения, последней ошибкой, числом попыток и временем следующей попытки. Запись вроде «CRM timeout, retry in 47 seconds» экономит реальное время и не даёт проблеме прыгать между командами.
Ошибки, которые создают работу для менеджеров аккаунтов
Команды поддержки расплачиваются за ошибки доставки долго после того, как код вышел в прод. Слабая настройка превращает небольшие задержки синхронизации в запросы на возврат денег, гневные письма и ручные правки аккаунтов.
Первая проблема — формулировки. Если вы говорите клиентам, что изменение происходит в реальном времени, они ожидают увидеть его сейчас, а не через 20 секунд и не после трёх попыток. Если ваша система обычно обновляет быстро, но иногда занимает минуту, скажите это прямо. Чёткое время лучше громкого обещания.
Ещё одна распространённая ошибка — бесконечные повторы без уведомления. Звучит безопасно, но скрывает сломанные интеграции днями. Клиент обновляет биллинг, доступ не меняется, а ваша система продолжает пытаться в фоне, пока менеджер по аккаунту получает первое обращение. Ограничьте повторы, пометьте доставку как провал и покажите это там, где работает ваша команда.
Строгий порядок тоже создаёт проблемы. Команды часто решают, что всё должно прийти в идеальной последовательности, и загоняют весь трафик в одну заблокированную очередь. Это может замедлить всё, когда одно плохое событие застрянет в начале. Большинство клиентов живёт с более простым правилом: события для одного объекта должны быть в порядке, но несвязанные объекты не должны ждать.
Скрытые ошибки тратят больше всего человеческого времени. Если ваша команда видит лишь «delivery failed», ей всё равно придётся копаться в логах, догадываться и просить инженеров о помощи. Показывайте сырые коды ответа, тело ответа, число попыток и время следующей попытки. Это уже сэкономит часы.
Небольшой пример делает это очевидным. Клиент апгрейдит подписку, но endpoint возвращает 500 в течение десяти минут. Если система безшумно продолжает пытаться, продажи видят апгрейд, продукт всё ещё показывает старый план, и кто-то из аккаунт-менеджеров объясняет несоответствие вручную.
Несколько базовых вещей предотвратят этот беспорядок: инструменты повторной отправки для одного события или диапазона дат, тесты для повторов и обработки дубликатов, видимая очередь неудачных событий, отсортированная по клиенту, и статусные заметки: pending, delivered, retrying или dead.
Запускайте с этими базами — иначе менеджеры аккаунтов станут системой «на случай непредвиденных ситуаций». Это дорого, медленно и обычно можно избежать.
Быстрая проверка перед запуском
Системы вебхуков должны выдерживать жёсткие тесты, а не аккуратные демо. Непосредственно перед запуском задача проста: намеренно ломайте поток и убедитесь, что поведение при сбое остаётся понятным для пользователей и вашей команды.
Начните с одного endpoint клиента. Заставьте его вернуть 500, затем таймаут, затем слишком медленный ответ. Проверьте, что расписание повторов следует заданным правилам, каждая попытка записывается, и приложение не показывает синхронизацию как завершённую, пока доставка всё ещё падает.
Далее отправьте одно и то же событие дважды с тем же event ID. Приёмник должен проигнорировать вторую копию или обработать её безопасно. Если один дубликат может создать второй счёт, восстановить отменённый план или отправить два письма, у вас ждёт дорогая проблема поддержки.
Затем протестируйте порядок намеренно, а не на удачу. Доставьте версию 3 раньше версии 2 и проверьте итоговое состояние. Если старый полезный груз может перезаписать более новый, пользователи увидят, как записи откатываются назад, и перестанут доверять синхронизации.
Теперь проверьте видимость. Откройте вид клиента и вид поддержки во время этих сбоев. Пользователь должен увидеть простой статус: pending, failed или retrying, плюс когда была последняя попытка. Поддержка должна видеть больше деталей: event ID, код ответа, число попыток и время следующей попытки.
Ещё один тест важнее, чем команды ожидают: повторная отправка одного неудачного события. Не перезапускайте целую пачку из-за одной поломки. Вам нужен чистый способ повторить один элемент, сохранить аудит и подтвердить, что повтор не создаёт дублей и не меняет порядок новых обновлений.
Эти проверки займут меньше времени, чем один грязный тикет в поддержке. Если какой-то тест проваливается — исправьте до релиза. Небольшие проблемы с доставкой редко остаются маленькими, когда менеджеры аккаунтов начинают объяснять их вручную.
Что делать дальше
Одностраничная спецификация стоит недели переписок в Slack и догадок. Запишите правила доставки, лимиты повторов, политику порядка, таймауты и состояния ошибок на одной странице, чтобы инженеры, поддержка и команды по работе с клиентами использовали одни и те же ответы.
Держите страницу простой. Если событие может прийти дважды — скажите это. Если порядок держится только по объекту — запишите. Если вы прекращаете повторы после заданного окна — сделайте отсечку очевидной.
Осторожный первый выпуск держите небольшим. Начните с нескольких endpoint клиентов, которые ведут себя по-разному, а не с чистого тестового сервера. Прогоняйте реалистичные события через весь поток, включая повторы и обработку дублей. Наблюдайте, как часто endpoints таймаутят, отклоняют полезную нагрузку или обрабатывают события не по порядку. Потом проговорите логи ошибок с командой поддержки до более широкого запуска, чтобы они знали, что клиенты могут спросить.
После этого исправьте две–три наиболее частые ошибки, прежде чем увеличивать трафик. Это сэкономит много работы по сопровождению позже. Команда поддержки, которая видит историю повторов, последний код ответа, время следующей попытки и конечное состояние ошибки, сможет быстро ответить на большинство вопросов. Без этого вида каждое пропущенное обновление превращается в сессию отладки.
Полезно запланировать короткий обзор после пилота. Посмотрите реальные неудачные доставки, а не только сводные дашборды. Если несколько клиентов испытывают проблемы с валидацией подписи или медленной обработкой, возможно, проблема в документации или форме полезной нагрузки.
Если хотите внешний аудит, Oleg Sotnikov на oleg.is работает со стартапами и малыми компаниями по архитектуре, инфраструктуре и AI-first инженерии в качестве Fractional CTO. Короткий обзор вашего дизайна вебхуков, видимости ошибок и плана развёртывания может обойтись значительно дешевле, чем устранение последствий после того, как клиенты перестанут доверять синхронизации.
Часто задаваемые вопросы
How fast should a webhook feel to users?
Большинство команд должны целиться на видимую доставку примерно за 3–10 секунд. Установите также второе число, например 60 секунд, — момент, когда продукт перестанет молчать и покажет, что синхронизация всё ещё ожидает или провалилась.
Should I promise instant sync?
Нет. Не обещайте «мгновенно». Лучше укажите ясный временной интервал, вместо слов вроде instant или real time, если задержки возможны. Пользователи легче воспримут небольшую задержку, чем нарушение абсолютного обещания.
What delivery guarantee should I use?
Для большинства систем вебхуков подходит гарантия at-least-once. Это значит, что одно и то же событие может быть отправлено повторно, поэтому приёмник должен уметь обнаруживать и безопасно игнорировать дубликаты.
What fields should every webhook include?
Отправляйте стабильный event ID, метку времени, версию ресурса или номер последовательности и подпись запроса. Эти поля позволяют приёмнику проверить отправителя, отбросить дубликаты и не дать старым обновлениям перезаписать новые данные.
When should I retry a failed webhook?
Повторяйте часто сначала, затем реже. Простой шаблон: 10 секунд, 30 секунд, 2 минуты, 10 минут и 1 час работает для многих бизнес-событий. Фиксированное окно повторов, например 24 часа, не даёт интеграциям падать бесконечно в фоне.
Should I retry 4xx responses?
Обычно нет. Повторяйте при таймаутах, 429 и 5xx, потому что приёмник может восстановиться. 400, 401, 403, 404 и 422 обычно означают неправильный или недействительный запрос — их не стоит повторять, если вы не уверены, что приёмник сможет исправить проблему без нового события.
Do I need strict ordering for all events?
Практически никогда. Сохраняйте порядок только там, где это важно: по клиенту или по записи. Позвольте более новым версиям побеждать старые — это предотвратит пробки из-за одного застрявшего события.
How should I show sync status in the product?
Показывайте отдельно успех в приложении и статус синхронизации. Хороший набор статусов: queued, sent, retrying, failed. Пока другой сервис не подтвердит приём, не говорите пользователю только «сохранено» — показывайте и состояние синхронизации.
What should support see when delivery fails?
Дайте службе поддержки единый обзор с event ID, аккаунтом клиента, назначением, кодом ответа, последней ошибкой, числом попыток и временем следующей попытки. Добавьте безопасную функцию повтора для одного события или короткого диапазона, чтобы поддержка могла решать обычные проблемы без помощи инженеров.
What should I test before launch?
Ломайте поток намеренно: верните 500, заставьте таймаут, замедлите ответ, отправьте дубликат с тем же event ID и пришлите версию 3 до версии 2. Проверьте, что повторы следуют правилам, устаревшие данные не перезаписывают новые, повторная отправка одного события работает, и и пользователи, и поддержка видят, что произошло.