Дедлайны контекста Go для HTTP, gRPC и Postgres
Дедлайны контекста Go помогают ограничить время запроса для HTTP, gRPC и Postgres, чтобы медленные клиенты или зависимости не тормозили сервис.
Содержание
Почему медленные запросы накапливаются
Один медленный вызов к downstream-сервису может превратить здоровый сервис в комнату ожидания. Запрос, который должен завершиться за 120 мс, может зависнуть на 8 или 10 секунд, если один HTTP-вызов, метод gRPC или запрос к Postgres зависает.
Когда запросы завершаются быстро, Go быстро освобождает ресурсы. Обработчик возвращает ответ, goroutine перестает работать, сокет клиента закрывается, а соединение с БД возвращается в пул.
Зависшая зависимость меняет картину. goroutine продолжает ждать сетевой I/O. Сокет остается открытым. Соединение с БД может оставаться занятым. Сначала ничего не выглядит критично, но сервис начинает складывать полуготовые запросы друг на друга.
Отмененные клиентами запросы только усугубляют ситуацию. Пользователь закрывает вкладку браузера или мобильное приложение сдается через 2 секунды, а ваш сервер все еще может выполнять ту же работу в фоне. Если сигнал отмены не доходит до каждого шага, сервер продолжает обращаться к другим сервисам и ждать результат, который уже никому не нужен.
Именно так и начинаются накопления:
- goroutine зависают вместо того, чтобы обслуживать новые запросы
- исходящие сокеты остаются занятыми дольше, чем ожидалось
- соединения с БД заняты, поэтому новые запросы ждут в очереди
- ретраи и дублирующиеся запросы создают еще больше нагрузки
Быстрый путь запроса скрывает проблему, пока не вырастет трафик. При небольшой нагрузке один медленный вызов кажется безобидным. При стабильном потоке 50 медленных вызовов могут удержать 50 goroutine, десятки сокетов и большую часть пула базы данных. Тогда даже простые запросы начинают таймаутиться, потому что не успевают получить ресурсы.
Вот почему дедлайны context в Go так важны. Они не делают медленную зависимость быстрой, но не дают одному плохому вызову удерживать весь сервис в заложниках. Цель проста: если клиент ушел или запрос исчерпал свой бюджет времени, работа должна остановиться везде, а не только на краю.
Что делает дедлайн в Go
Context в Go передает сигнал остановки через ваш код. Он также может хранить дедлайн — точное время, когда работу нужно прекратить. Именно так дедлайны context в Go не дают одному медленному шагу держать весь запрос открытым.
Таймаут — это просто более короткий способ задать время остановки. Если вы говорите «остановиться через 200 миллисекунд», Go под капотом превращает это в дедлайн. Отмена означает, что вы останавливаетесь раньше по другой причине, например когда клиент отключился, сервер завершает работу или предыдущий шаг уже завершился с ошибкой.
context.WithTimeout подходит, когда вы знаете бюджет как длительность от текущего момента. Обработчик может дать исходящему HTTP-вызову 300 миллисекунд, независимо от того, когда начался запрос. context.WithDeadline подходит, если у вас уже есть точное время окончания и вы хотите, чтобы каждый дочерний вызов его уважал.
Держите один родительский context для каждого входящего запроса. В HTTP-обработчике это обычно r.Context(). В gRPC это request context, который дает сервер. Каждый downstream-вызов должен происходить от этого родителя, а не от context.Background().
Если в середине вы переключаетесь на context.Background(), цепочка рвется. Пользователь может уйти, сервер может завершиться по таймауту, но ваш запрос к базе данных или удаленный вызов все равно продолжит работать. Так медленные клиенты накапливаются и тратят память, время worker’ов и соединения.
Когда работа больше не нужна, останавливайтесь быстро. Проверяйте ctx.Done() в циклах, перед ретраями и перед началом дорогой работы. Если context уже завершен, сразу возвращайте ctx.Err().
На практике это обычно одно из двух значений:
context.DeadlineExceeded, когда время вышлоcontext.Canceled, когда кто-то остановил работу раньше
Быстрый возврат важнее, чем многие команды думают. Если вкладка браузера закрылась, нет смысла продолжать рендерить отчет, ждать gRPC или выполнять запрос Postgres ради ответа, который никто не прочитает.
Составьте один бюджет запроса от края
Начинайте отсчет в публичном обработчике. Если запросу на краю дали 2 секунды, каждая функция ниже должна делить этот же лимит. Не позволяйте helper-ам по пути создавать новые таймауты. Запрос, который должен умереть за 2 секунды, может незаметно жить гораздо дольше, если каждый слой сбрасывает таймер.
Оставьте небольшой запас на завершающую работу. Запись ответа, отправка логов и закрытие ресурсов тоже занимают время. Если полный бюджет — 2 000 мс, разумно оставить 150–250 мс в резерве.
Простой пример распределения может выглядеть так:
- 2 000 мс всего от обработчика
- 700 мс на один HTTP-вызов
- 500 мс на один gRPC-вызов
- 400 мс на Postgres
- 200 мс в резерве
Цифры будут отличаться от сервиса к сервису, но одно правило не меняется: дочерние операции получают меньше времени, чем родитель, и никогда больше. С дедлайнами context в Go родительский запрос говорит каждому downstream-вызову, сколько времени осталось.
Передавайте ctx через аргументы функций до самого низа. func loadAccount(ctx context.Context, id string) легко читать и трудно использовать неправильно. Глобальное состояние заставляет забывать о дедлайнах, а скрытое состояние запроса быстро создает путаницу.
Проверяйте оставшийся бюджет перед началом дополнительной работы. Если осталось только 80 мс, пропустите необязательные обогащения, побочную работу «как будто в фоне» или второй вызов к зависимости, который, скорее всего, не успеет завершиться. Лучше быстро вернуть меньший результат, чем протолкнуть весь запрос за пределы лимита.
Логируйте оставшееся время в точках разветвления запроса. Например, делайте это перед запросом в БД, перед HTTP-вызовом и перед любым fan-out. Эти цифры показывают, реалистичен ли ваш бюджет. Они также быстро выявляют одну распространенную проблему: ранний медленный вызов может съесть почти весь бюджет и оставить последующим шагам нулевые шансы на успех.
Передавайте дедлайны в HTTP-вызовы
Исходящий HTTP-вызов должен использовать тот же clock, что и входящий запрос. Если у handler-а осталось 800 мс, следующая служба не должна случайно получить 30 секунд.
Создавайте запрос через http.NewRequestWithContext. Это связывает поиск DNS, подключение, отправку запроса, ожидание заголовков и чтение body с бюджетом запроса.
transport := &http.Transport{
ResponseHeaderTimeout: 500 * time.Millisecond,
DialContext: (&net.Dialer{
Timeout: 200 * time.Millisecond,
}).DialContext,
TLSHandshakeTimeout: 200 * time.Millisecond,
}
client := &http.Client{
Transport: transport,
}
req, err := http.NewRequestWithContext(ctx, http.MethodGet, upstreamURL, nil)
if err != nil {
return err
}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
Этот разделение важно. Context задает общий бюджет. Таймауты transport-а не дают вызову зависнуть на одном сетевом этапе, например при медленном подключении или если сервер принимает сокет, но не отправляет заголовки.
http.Client.Timeout часто создает проблемы, когда вы уже используете context. Он оборачивает весь обмен своим собственным таймером, который может сработать в момент, отличный от вашего бюджета запроса. Из-за этого ошибки сложнее читать, и response body может оборваться, даже если у context еще есть время. В большинстве сервисов лучше дать context управлять end-to-end дедлайном, а для сетевых фаз использовать настройки transport.
Отмена клиентом и замедление upstream — это не одна и та же ошибка. Если браузер или вызывающая сторона ушли, r.Context() отменяется. Сразу останавливайте работу и не делайте ретрай. Если ваш upstream-вызов таймаутится, пока клиент еще подключен, это обычно означает, что зависимость медленная. Логируйте такие случаи отдельно. Они указывают на разные проблемы.
Всегда закрывайте response body, даже если статус-код 500 или вы собираетесь игнорировать body. Если пропустить Close, idle-соединения не вернутся в пул, и небольшие утечки превратятся в давление на соединения под нагрузкой. Так одна плохая зависимость начинает тянуть вниз весь сервис.
Передавайте дедлайны через gRPC
Когда gRPC-обработчик получает запрос, часы уже запущены. Считайте дедлайн из входящего context и относитесь к нему как к общему бюджету на все, что ваш handler делает дальше.
Если вы вызываете другой gRPC-сервис, передавайте тот же ctx вниз. Это не дает одной плохой зависимости растянуть запрос за пределы лимита клиента. Кроме того, дедлайны context в Go работают одинаково через границы сервисов, а не останавливаются на первом хопе.
Создание нового таймаута для каждого downstream-вызова — частая ошибка. Запрос, который должен умереть через 800 мс, может незаметно жить 800 мс на каждый retry и на каждую зависимость. Так медленные клиенты и накапливаются. Ретраи должны укладываться в исходный бюджет.
Хорошо работает простой подход:
- проверьте, есть ли у входящего context уже дедлайн
- передавайте этот же context в каждый downstream RPC
- делайте retry только если осталось достаточно времени на еще одну полезную попытку
- пропускайте fan-out вызовы, если остаток бюджета слишком мал
Последний пункт важнее, чем кажется. Если осталось только 20 мс, fan-out к трем сервисам, скорее всего, трижды провалится и только добавит шума в логи. Лучше вернуть частичный результат, использовать fallback или остановиться раньше. Быстрая и честная ошибка лучше, чем лишняя нагрузка.
Также стоит записывать результаты таймаутов так, чтобы их можно было быстро понять. codes.DeadlineExceeded означает, что время вышло. codes.Canceled обычно означает, что вызывающая сторона отказалась от запроса или родительский request закончился. Логируйте метод RPC, downstream-сервис и сколько времени оставалось на момент старта вызова. Так намного проще понять, проблема в вашем сервисе или где-то дальше по цепочке.
Простой пример: ваш API получает 1 секунду всего. Handler тратит 150 мс на auth, затем вызывает service с профилем и billing-сервис. Если вызов профиля занимает 700 мс, billing-сервис должен увидеть крошечный остаток бюджета и либо пропустить работу, либо быстро завершиться с ошибкой. Он не должен начинать с нового таймера на 1 секунду.
Останавливайте работу Postgres вовремя
Запрос, который истекает по таймауту через 2 секунды, не должен оставлять SQL-запрос в Postgres, который продолжает выполняться 30 секунд. Если это происходит, запрос все еще держит соединение, может удерживать locks и блокировать новые задачи позади себя. Так один медленный путь превращается в проблему пула.
Всегда используйте context-aware вызовы к базе: QueryContext, ExecContext и BeginTx с тем же ctx, который пришел из request. Так дедлайны context в Go доходят до слоя базы данных, а не заканчиваются на handler-е.
rows, err := db.QueryContext(ctx, q, args...)
_, err = db.ExecContext(ctx, stmt, args...)
tx, err := db.BeginTx(ctx, nil)
Когда context истекает, Postgres может остановить работу вместо того, чтобы завершать запрос, который уже никому не нужен. Это особенно важно во время всплесков нагрузки. Несколько зависших запросов могут съесть весь пул, и тогда даже быстрые запросы будут ждать свободное соединение.
Транзакции требуют отдельного внимания. Делайте их короткими. Внутри них выполняйте только минимально необходимую работу, а затем сразу делайте commit или rollback. Если вы открываете транзакцию, потом вызываете другой сервис, а затем возвращаетесь обновлять строки, вы увеличиваете шанс, что отмененный запрос дольше держит locks, чем нужно.
Server-side ограничения тоже помогают. statement timeout дает второй тормоз на случай, если приложение что-то пропустило. Многие команды ставят timeout по умолчанию для рискованных запросов или используют SET LOCAL statement_timeout внутри транзакции. Держите это ограничение немного ниже полного бюджета запроса или хотя бы близко к нему, чтобы база данных завершала работу быстро.
Во время тестирования смотрите не только на ошибки в логах. Проверяйте:
- активные соединения в пуле
- время ожидания свободного соединения
- количество отмененных запросов
- длительность транзакций под нагрузкой
Простой тест на медленный запрос многое покажет. Отправьте запросы, которые запускают задержанный query, отмените половину из них и посмотрите, восстановится ли пул за секунды или останется зажатым. Если он остается зажатым, в вашей цепочке таймаутов все еще есть пробел.
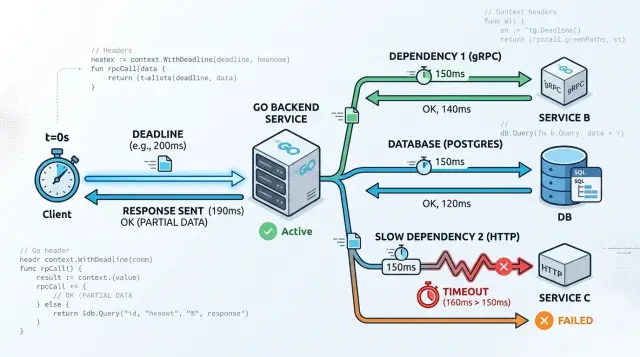
Простой пример потока запроса
Представьте endpoint API с названием /quote. Приходит один запрос, handler спрашивает pricing service через gRPC о последнем значении, а затем пишет короткую audit-запись в Postgres.
Весь запрос получает 800 мс. Внутри этого бюджета вызов pricing-service получает 300 мс, а SQL-запрос — 150 мс. В Go дочерние context не могут жить дольше родительского, поэтому каждый шаг остается в рамках одних и тех же часов.
func (s *Server) Quote(w http.ResponseWriter, r *http.Request) {
reqCtx, cancel := context.WithTimeout(r.Context(), 800*time.Millisecond)
defer cancel()
priceCtx, cancelPrice := context.WithTimeout(reqCtx, 300*time.Millisecond)
price, err := s.pricing.GetPrice(priceCtx, &pb.PriceRequest{})
cancelPrice()
if err != nil {
http.Error(w, "pricing service timed out", http.StatusGatewayTimeout)
return
}
dbCtx, cancelDB := context.WithTimeout(reqCtx, 150*time.Millisecond)
_, err = s.db.ExecContext(dbCtx, `insert into quote_audit(price) values($1)`, price.Value)
cancelDB()
if err != nil {
http.Error(w, "database write timed out", http.StatusServiceUnavailable)
return
}
}
В обычный день pricing service может ответить за 90 мс, а Postgres завершить работу за 40 мс. Весь запрос закончится заметно раньше бюджета в 800 мс.
Теперь изменим одно условие. Pricing service зависает на 2 секунды.
Handler не ждет 2 секунды. gRPC-вызов достигает дедлайна в 300 мс, Go отменяет context, и запрос возвращает 504 с простым сообщением вроде "pricing service timed out". У внешнего handler-а еще остается время, но он прекращает работу, потому что зависимость уже подвела.
Такое раннее завершение защищает остальную часть сервиса. Код даже не доходит до ExecContext, а значит, не берет соединение Postgres. Пул БД остается свободным для запросов, у которых еще есть шанс успешно завершиться.
Если запрос все-таки дошел до Postgres и запрос затянулся дольше 150 мс, ExecContext отменяет его вовремя. Запрос останавливается, соединение возвращается в пул, а handler возвращает понятную ошибку вместо того, чтобы висеть, пока не сдастся клиент.
Ошибки, которые ломают цепочки таймаутов
Большинство ошибок с таймаутами появляется из кода, который тихо обрезает исходный context пополам. Вы начинаете с бюджета в 2 секунды на краю, но один helper, один цикл ретраев или один универсальный wrapper ошибок превращают этот бюджет в угадайку.
Распространенная ошибка — создавать context.Background() внутри helper-а. Такой helper больше не знает, когда клиент сдался, поэтому его HTTP-вызов, gRPC-запрос или запрос Postgres могут продолжать работать еще долго после ухода пользователя. В Go дедлайны context работают только если каждый слой принимает ctx и передает ту же цепочку дальше.
Еще одна проблема — сбрасывать таймаут на каждом слое. Handler получает 2 секунды, затем сервис добавляет еще 2, потом слой базы добавляет еще 2. На бумаге у каждого вызова есть timeout. На практике весь запрос может тянуться намного дольше, чем вы хотели.
Ретраи тоже создают проблемы. Если ctx.Err() уже сообщает context deadline exceeded или context canceled, на этом нужно остановиться. Ретрай после окончания бюджета не спасает запрос. Он только добавляет еще работы системе, которая и так под нагрузкой.
Логи часто делают ситуацию хуже. Если каждый timeout превращается в общий 500, вы теряете причину сбоя. Вам нужны логи, в которых видно, что клиент отменил запрос, истек ваш собственный дедлайн или раньше всех таймаутнулась upstream-зависимость. Такая детализация сильно экономит время при отладке медленных путей.
Тесты часто пропускают именно то место, где прячутся баги. Многие команды тестируют happy path и пару медленных зависимостей, но никогда не проверяют отмененные клиентские соединения. Из-за этого остается слепая зона: браузер закрывается, телефон переключается между сетями или proxy сдается, а ваш сервис все еще держит базу занятым.
Небольшой чеклист помогает:
- Принимайте
ctxв каждом helper-е, который делает I/O - Создавайте более короткие дочерние дедлайны только когда это действительно нужно
- Проверяйте
ctx.Err()перед каждым retry - Логируйте ошибки timeout и cancel с реальной причиной
- Добавьте тесты, которые отменяют клиентский запрос в процессе выполнения
Если один медленный партнерский сервис все еще может держать ваши goroutine, DB-сессии или workers занятыми после ухода вызывающей стороны, значит цепочка таймаутов где-то сломана.
Быстрые проверки перед запуском
Большинство ошибок с таймаутами связано с одним пропавшим ctx, а не с самим значением таймаута. Сервис может проходить обычные тесты и все равно зависать, когда один downstream-вызов замедляется.
Проверьте это в staging с искусственной задержкой или в production под безопасным флагом. Вам нужно доказать, что одна зависшая зависимость не может удерживать весь сервис открытым.
- Начинайте один бюджет запроса на каждой публичной точке входа. Каждый HTTP-обработчик и метод gRPC должны начинаться с родительского context с дедлайном. Если у входящего запроса уже есть более короткий дедлайн, сохраняйте именно его.
- Передавайте тот же
ctxво все исходящие вызовы. Ваши HTTP-клиенты, gRPC-клиенты и запросы Postgres должны использовать его напрямую. Один helper, который подменяетcontext.Background(), может сломать цепочку. - Разделяйте в логах отмененные запросы и запросы, завершившиеся по таймауту.
context.Canceledобычно означает, что клиент ушел раньше.context.DeadlineExceededобычно означает, что ваш код, база данных или другой сервис заняли слишком много времени. - Следите за пулами, пока вы искусственно замедляете систему. Подержите запрос Postgres открытым, задержите HTTP-зависимость или замедлите gRPC-сервер. Количество соединений, время ожидания пула, goroutine и latency должны немного вырасти и затем стабилизироваться, а не продолжать расти.
- Настраивайте алерты до наступления saturation. Следите за rate таймаутов, ожиданием пула, ростом очередей и увеличением числа одновременно выполняющихся запросов до того, как CPU упирается в предел или сервис перестает отвечать.
Простой тест многое покажет. Заставьте одну зависимость спать 10 секунд, дайте запросу бюджет 2 секунды и отправляйте трафик несколько минут. Если дедлайны context в Go настроены правильно, вызывающие должны быстро получать ошибку, работа Postgres должна останавливаться, а сервис должен продолжать принимать новые запросы.
Если после такого теста остаются занятые соединения с базой, растет количество goroutine или в логах появляется стена одинаковых timeout-сообщений, исправьте это до запуска. Это ранние признаки того, что медленные клиенты начнут накапливаться под реальным трафиком.
Следующие шаги для вашего сервиса
Выберите один путь запроса, который особенно болезненно тормозит при нагрузке. Хорошая первая цель — обычно handler, который вызывает внешнее HTTP API, затем gRPC-сервис, а потом Postgres. Проследите весь бюджет таймаута от края до последнего запроса и запишите числа. Если клиент получает 2 секунды, каждый downstream-вызов должен получить меньшую долю этого времени.
Сделайте это для одного пути, прежде чем трогать весь кодbase. Команды часто пытаются добавить дедлайны context в Go сразу везде, а потом неделю гадают, какой timeout сработал первым. Один путь дает чистые данные и меньше сюрпризов.
Обычно лучше работает небольшой поэтапный rollout:
- Задайте один request budget на HTTP-краю и передавайте тот же context через каждый вызов.
- Добавьте тесты, которые имитируют медленный HTTP-зависимость, медленный gRPC-вызов и медленный SQL-запрос.
- Проверьте, что каждый слой останавливает работу раньше и возвращает понятную ошибку.
- Следите за логами, статистикой пула соединений и latency после каждого изменения.
Тесты важнее, чем многие ожидают. Цепочка таймаутов может выглядеть правильно в коде и все равно провалиться в production, потому что один helper использует context.Background(), у одного клиента свой более длинный timeout или один запрос игнорирует отмену, пока не дойдет до базы данных. Медленные тесты быстро это ловят.
Когда будете смотреть на результаты, обратите внимание на две вещи. Во-первых, снизилась ли tail latency, когда одна зависимость зависла? Во-вторых, освободил ли сервис ресурсы достаточно быстро? Время ожидания пула Postgres, открытые соединения, количество goroutine и шум ретраев вверх по цепочке обычно хорошо показывают картину.
Оставляйте логи простыми. Записывайте дедлайн запроса, оставшийся бюджет перед каждым исходящим вызовом и ошибку, которая вернулась. Этого часто достаточно, чтобы увидеть, куда исчезает время.
Если вашей команде нужен второй взгляд, Oleg Sotnikov предоставляет Fractional CTO support для Go-сервисов, инфраструктуры и AI-augmented engineering. Его опыт включает эксплуатацию production-систем с lean-инфраструктурой, высокой доступностью и практичной автоматизацией, поэтому такая настройка таймаутов хорошо вписывается в работу, которой он уже занимается.
Когда один горячий путь начинает хорошо работать под нагрузкой, перенесите тот же подход на следующий по важности путь. Обычно именно там и проявляется реальная польза.


