DDD-lite для событийно-ориентированных систем с чёткой ответственностью
Узнайте, как DDD-lite для событийно-ориентированных систем сохраняет команды, события и политики простыми и легко принадлежащими — чтобы команды не получали запутанную фоновую логику.
Содержание
Почему ответственность размывается
Ответственность размывается, когда событие превращается в открытую инвайтацию. Одно событие срабатывает — и внезапно любой фоновый воркер может на него отреагировать. Сначала это кажется аккуратным. Потом модель начинает разбегаться.
Команда добавляет один полезный обработчик на событие, затем ещё один, потому что он вроде бы безобиден. После регистрации клиента одна задача отправляет приветственное письмо. Позже другая задача создаёт триал, ещё одна обновляет отчёты продаж, а ещё одна снимает плату за настройку у некоторых клиентов. Никакой грязной схемы никто не планировал. Это выросло шаг за шагом.
Проблема начинается, когда эти задачи перестают делать простую последующую работу и начинают принимать бизнес-решения. Обработчик, который должен был только уведомлять пользователя, теперь решает, нужно ли выставлять счёт. Другой решает, считать ли счёт активным для финансов. Отчётный воркер копирует одно и то же правило, потому что оригинальная логика живёт глубоко в очереди. Правило больше не имеет одного ясного владельца.
Это недоразумение распространяется быстро. Продукт думает, что правило за биллингом. Биллинг думает, что правило за саппортом, потому что саппорт просил письмо. Аналитика добавляет ту же проверку в отчёты, чтобы числа сходились. Потом два обработчика принимают одно и то же решение немного по-разному, и баги появляются в местах, которые вроде бы не связаны.
Фоновая обработка делает это трудноуловимым, потому что логика сидит в стороне. Имена вроде UserUpdatedHandler или OrderEventConsumer скрывают многое. Если один обработчик отправляет письма, снимает деньги с карт и обновляет отчёты, он владеет слишком многим. Когда что-то ломается, команде приходится читать логи и историю очередей просто чтобы ответить на базовый вопрос: кто решил, что это должно случиться?
Этот вопрос обычно и есть предупреждающий сигнал. Если никто не может указать одно место и сказать «это часть бизнеса владеет этим правилом», поток событий уже размывает ответственность.
Начните с команд
Когда приложение с большим количеством событий становится грязным, первое исправление чаще всего простое: назовите действие так, как его действительно просит человек. Команда должна читаться как явная просьба от роли в бизнесе. ApproveExpense подходит. RunExpensePipeline — нет. Одна формулировка говорит, что хочет бизнес. Другая говорит, как это сейчас делает код.
Каждая команда должна нести одно бизнес-решение. Если вы упакуете несколько выборов в один запрос, ответственность снова начнёт размываться. CreateAccountAndSendWelcomeOfferAndAssignPlan скрывает слишком много. Разделите до тех пор, пока один человек не сможет объяснить, зачем нужна команда, не рассказывая весь процесс.
Запишите, кто может выдать команду и когда. Это звучит мелко, но предотвращает много путаницы позже. Менеджер по продажам может выдавать ApplyDiscount только до оплаты. Завхоз может выдавать ReleaseShipment только после резерва склада. Эти правила должны жить рядом с командой, потому что они решают, имеет ли запрос смысл.
Хорошая команда также проходит тест простым предложением: «Когда [роль] нуждается в [результате], она может выдать [команду], если [условие].» Например: «Когда агент поддержки должен закрыть дубликат тикета, он может вызвать MergeTicket, если оба тикета принадлежат одному и тому же клиенту.» Это даёт актёра, действие и границу в одной строке.
Быстрый тест-запах помогает. Имя должно начинаться с бизнес-глагола, а не с технической задачи. За ним должно стоять одно решение. Одна роль должна иметь право его просить. И вы должны уметь сформулировать условие простым языком.
Это делает больше, чем просто упорядочивает имена. Это чертит чёткую грань между запросом и работой, которая может произойти позже. Как только эта грань ясна, очереди, ретраи и обработчики перестают выглядеть как место, где живёт бизнес-владение. Владение начинается там, где начинается запрос.
Держите каждое правило у правильного владельца
Команды часто переносят бизнес-решения в обработчики, потому что обработчики кажутся удобными. В этом и кроется скользкая дорожка. Обработчик просыпается позже, на другой машине, с меньшим контекстом, чем часть системы, которая приняла первоначальный запрос. Он должен реагировать на решение, а не принимать первичное.
Для каждого правила задайте прямой вопрос: кто в бизнесе может сказать «да» или «нет»? Если правило про возврат денег — его решает домен возвратов. Если про доставку — доставка. Владелец должен получить команду, проверить правило и либо отклонить запрос, либо зафиксировать изменение.
Простой тест помогает: если два обработчика могут принять одно и то же решение, на самом деле никто им не владеет. Это обычно приводит к состязаниям, дублирующим проверкам и странному коду для исправления позже.
Поток должен идти в таком порядке. Сначала отправьте команду владельцу. Затем дайте этому владельцу загрузить нужные данные и принять решение. Потом сохраните изменение состояния. Только после этого следует выпустить событие, например RefundApproved или OrderReleased. Событие сообщает остальной системе о том, что уже случилось, а не о том, что может произойти.
Остальные части могут отреагировать после этого. Бухгалтерия может записать проводки. Уведомления могут отправить письмо. Аналитика может посчитать результат. Ни одна из этих частей не должна решать, был ли возврат разрешён изначально.
Если у последующего шага есть своё правило, дайте этому шагу своего владельца и свою команду. После RefundApproved платежи могут получить SendRefundToGateway. Платежи могут принять или отклонить эту команду по правилам шлюза, но они не должны заново пересматривать, заслужил ли клиент возврат. Это решение уже принадлежит другому месту.
Команды просят владельца решить. События фиксируют уже совершённые факты. Политики могут слушать и запускать дальнейшую работу, но они должны оставаться в стороне от первичных бизнес-решений. Держите эту границу острой — и фоновая обработка перестанет казаться загадочной.
Используйте политики для последующей работы
Политики работают лучше, когда они реагируют на факты, которые уже произошли. Обычно это значит, что политика слушает событие вроде PaymentCaptured или AccountApproved. Она не должна просыпаться потому, что таймер решил, что что-то может быть готово, или потому, что cron просканировал таблицу и сделал допущения.
Это правило сохраняет чистоту владения. Команда, которая владеет событием, говорит: «это случилось». Политика читает этот факт и решает, нужно ли другой области действовать. Если работа пересекает границу, политика должна отправить новую команду следующему владельцу вместо того, чтобы полезть и менять данные сама.
Пример по биллингу конкретизирует идею. Когда биллинг выпускает PaymentCaptured, политика может сказать инвойсингу выполнить CreateInvoice. Биллинг всё ещё владеет фактом платежа. Инвойсинг владеет правилами инвойса. Политика лишь соединяет два шага.
Хорошая политика решает процессные вопросы, которые не относятся к самому бизнес-правилу: когда запускать следующую команду, сколько ждать перед повторной попыткой, сколько попыток разрешено и что делать, если зависимый сервис упал. Это держит тайминги и доставку в одном месте, а не разбросанными по обработчикам, контроллерам и джобам базы.
Политики всё равно нуждаются в пределах. Они не должны скрывать настоящее решение. Если бизнес должен решить, можно ли отправлять заказ, это правило принадлежит команде или агрегату, который владеет доставкой. Политика может заметить OrderPaid и отправить PrepareShipment, но не должна тихо решать право на отгрузку по набору побочных проверок.
Это разделение кажется небольшим, но спасает от многих проблем. Многие системы со множеством событий постепенно дрейфуют, потому что фоновые скрипты начинают вести себя как владельцы. Как только это случается, никто не знает, где живёт решение, и даже небольшие изменения превращаются в поиск по коду. Политики должны координировать последующую работу, а не становиться второй бизнес-моделью.
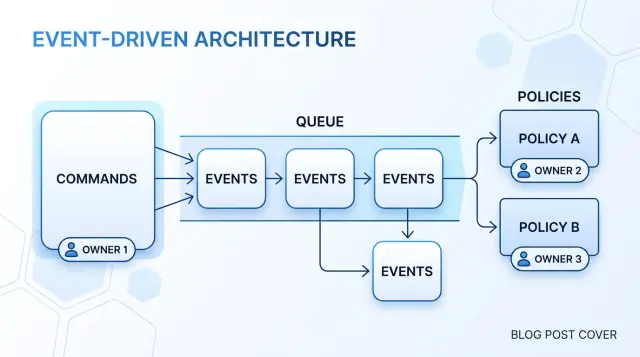
Прокладывайте поток шаг за шагом
Когда процесс проходит через API, очереди, cron и воркеры, люди перестают видеть, кто принял бизнес-решение. Решение простое: нарисуйте одну простую цепочку и заполните её слева направо.
Начните с команды. Команда — это запрос от одного актёра к одному владельцу. Она должна звучать как решение, которое кто-то хочет, чтобы владелец принял, например «approve payout» или «cancel subscription». Если фраза звучит как запись в логе или техническая задача, перепишите её так, чтобы бизнес-владелец мог её претендовать.
Затем опишите изменение состояния, которое подтверждает успех команды. Многие команды прыгают сразу к событиям. Это вызывает проблемы позже. Сначала скажите, что изменилось в модели: выплата стала утверждённой, подписка — отменённой, возврат — в состоянии pending review. Если вы не можете назвать изменение состояния одной короткой фразой, команда всё ещё смутна.
После этого зафиксируйте событие, которое объявляет об изменении. Событие — не запрос и не план. Это факт о том, что уже произошло. PayoutApproved означает, что владелец принял решение и сохранил результат. Это различие важно, когда появляются ретраи, задержки и дублированная доставка.
Теперь добавьте политики, но только там, где другой владелец должен отреагировать. Контекст биллинга может отреагировать на SubscriptionCanceled и остановить будущие выставления счетов. Контекст доступа может отреагировать и убрать премиум-функции. Это — последующие действия. Они не являются исходным решением. Если тот же владелец по-прежнему решает вопрос, держите правило в потоке команд, а не выталкивайте его в другой обработчик.
Остановитесь, когда каждое решение найдёт один ясный дом. Вы должны уметь указать на каждый шаг и ответить на три вопроса: кто решил, что изменилось и кто только отреагировал потом. Если фоновый воркер реагирует на событие и тихо принимает новое бизнес-решение, карта не закончена.
Хороший поток читается в одном предложении: пользователь отправил команду, этот владелец изменил состояние, событие это объявило, и другие владельцы отреагировали. Если это предложение звучит запутанно, ответственность всё ещё прячется где-то.
Простой пример с возвратом
Потоки возвратов быстро пачкаются, когда каждый обработчик событий начинает принимать бизнес-решения. Чище держать одну команду и одну часть системы в ответе за решение по возврату, даже если несколько фоновых задач отреагируют позже.
Представьте агента поддержки, который помогает клиенту и получает запрос вернуть деньги по заказу. Поддержка не должна решать, разрешён ли возврат. Поддержка отправляет команду RefundOrder с ID заказа и причиной. Эта команда говорит: «Пожалуйста, оцените этот запрос». Она не говорит: «Верните деньги сейчас, потому что поддержка нажала кнопку».
Биллинг владеет правилами возврата, поэтому биллинг обрабатывает команду. Он проверяет статус заказа, дату платежа, прошлые попытки возврата и другие правила бизнеса. Затем биллинг принимает решение. Если запрос соответствует правилам, биллинг фиксирует RefundApproved. Если нет — фиксирует RefundRejected.
Эта линия ответственности важна. Часть системы, которая знает правила, должна принять решение один раз. Остальные части могут отреагировать, но не должны тихо переоткрывать то же самое решение.
Чистый поток короткий:
- Поддержка отправляет
RefundOrder. - Биллинг оценивает правила возврата.
- Биллинг выпускает
RefundApprovedилиRefundRejected. - Политики реагируют на результат и запускают последующие действия.
Добавим проверку на фрод. Политика фрода слушает RefundApproved. Если случай выглядит подозрительно — например карта менялась три раза за неделю или заказ пришёл из отмеченного региона — политика отправляет новую команду вроде ReviewApprovedRefund. Это отличается от изменения решения по возврату. Политика фрода владеет проверкой фрода. Биллинг по-прежнему владеет правом на возврат.
Почтовая политика может реагировать аналогично. Она слушает RefundApproved и RefundRejected и отправляет клиенту соответствующее уведомление. Почтовая политика ничего не решает — она сообщает клиенту о том, что биллинг уже решил.
Здесь многие команды спотыкаются. Они позволяют воркеру фрода прямо отклонять возвраты или позволяют обработчику почты догадываться о решении по неполным данным. Тогда никто не может сказать, кто владеет правилом. Держите команду у того, кто решает, событие как запись решения, а политики — для последующей работы.
Ошибки, которые размывают ответственность
Ответственность мутнеет, когда фоновые скрипты начинают принимать бизнес-решения. Обычно это происходит постепенно. Обработчик растёт, воркер получает одну лишнюю проверку, а отчётный скрипт начинает поправлять данные, потому что так удобнее.
Одна распространённая проблема начинается с единственного обработчика события, который вызывает пять сервисов подряд. Обработчик OrderPaid проверяет фрод, резервирует склад, обновляет доставку, отправляет письма и пишет в бухгалтерию. Это выглядит эффективно неделю-две. Затем один сервис таймаутит, другой ретраит, и никто не может сказать, какая часть на самом деле владеет решением о продвижении заказа.
Правила одобрения часто протекают в ретрай-воркеры тоже. Воркер ретрая должен повторять доставку или неудачные API-вызовы. Он не должен решать, что возврат теперь одобрен, потому что третья попытка сработала. Если логика одобрения живёт там, бизнес-правила зависят от тайминга, состояния очереди и порядка ошибок. Плохое место для политики.
Ещё одна ошибка — публикация событий до сохранения бизнес-изменения. Предположим, приложение выпускает RefundApproved, а затем запись в базу падает. Письмо уходит, бухгалтерия реагирует, поддержка видит возврат в логе, но в источнике правды заказ всё ещё показывает «pending». Теперь существует две истории одного и того же действия.
Нечёткие команды усугубляют ситуацию. ProcessOrder может значить почти всё: валидировать платёж, резервировать склад, упаковать товар или попросить менеджера об одобрении. Ясные команды заставляют владение быть явным. ApproveRefund и CapturePayment оставляют намного меньше пространства для домыслов.
Шаблоны, которые обычно создают проблемы, легко заметить. Один обработчик координирует много несвязанных вызовов. Ретрай-код содержит проверки одобрения. События выходят из системы до записи изменения состояния. Команды имеют широкие имена, скрывающие настоящий смысл. Отчётные или аналитические джобы меняют бизнес-состояние.
Последний случай причиняет больше вреда, чем команды ожидают. Отчётные задания должны описывать, что случилось, считать или пометить аномалию для ручной проверки. Они не должны переводить счёт в «оплачен» или закрывать заказ, потому что дашборд обнаружил рассогласование.
Если человек из бизнеса мог назвать правило, держите это правило рядом с командой, которая меняет состояние. Пусть фоновая обработка выполняет работу, которая уже решена, а не придумывает бизнес-поток сама по себе.
Быстрые проверки перед добавлением ещё одного обработчика
Когда система уже реагирует на множество событий, добавить ещё один обработчик кажется дешёвой опцией. Обычно это не так. Дополнительный обработчик часто означает дополнительное владение, риск таймингов и ещё одно место, где правило становится труднее найти.
Пауза и тест идеи перед кодингом полезны. Если ответ на любой из этих вопросов неясен, модель, вероятно, требует доработки.
Спросите, кто владеет правилом. Новый участник должен суметь указать одно место и сказать: «эта команда решает» или «эта политика реагирует после решения». Если два обработчика разделяют одно правило, никто им не владеет.
Спросите, почему политика запускает другую команду. «Потому что событие произошло» — слишком слабый ответ. Хороший ответ звучит скорее так: «после одобрения возврата финансы должны вернуть деньги» или «после просрочки выставления счёта система должна приостановить сервис».
Спросите, что произойдёт, если очередь будет медленной. Если система примет иное бизнес-решение только потому, что сообщение пришло на пять минут позже, правило находится не в том месте. Тайминг может задерживать последующую работу, но не должен менять само решение.
Спросите, безопасен ли replay. Вы должны иметь возможность проиграть события, чтобы восстановить состояние, не списав деньги второй раз, не отправив письмо повторно и не создав дубликат тикета.
Малый пример по биллингу делает это ясным. RefundApproved не должен сам по себе снимать деньги, отправлять почту, обновлять отчёты и уведомлять поддержку из четырёх отдельных обработчиков, которые каждый догадываются, что делать. Одна команда одобряет возврат. Политики затем запускают отдельные команды для возврата средств, письма клиенту и аудита. У каждой последующей команды есть причина существовать, и у каждой есть защита от дубликатов.
Если вы не можете объяснить владение в двух–трёх простых предложениях, не добавляйте обработчик пока. Переименуйте команду, разделите политику или переместите решение раньше. Такая уборка обычно экономит больше времени, чем экономия от нового обработчика в первый день.
Следующие шаги к более чистой модели
Возьмите один рабочий процесс, который создаёт наибольшую путаницу, и положите его на одну страницу. Используйте простые блоки или стикеры. Запишите команду, которая запускает работу, событие, которое фиксирует, что случилось, и каждую политику, которая реагирует после этого.
Эта простая картинка обычно быстро показывает настоящую проблему. Команда думает, что у неё автоматизация, но тяжёлые бизнес-решения живут внутри фоновых джобов с именами вроде processQueue или syncWorker. Когда это случается, никто не может сказать, кто владеет правилом, зачем оно существует и что должно поменяться, когда бизнес изменится.
Хорошая уборка начинается с выноса решений из этих джобов. Если воркер решает, делать ли возврат, приостанавливать аккаунт, применять плату или отправлять предупреждение, переместите этот выбор ближе к команде или в именованную политику. Фоновая обработка должна выполнять то, что уже решено, а не выдумывать бизнес-поток сама по себе.
Имена важнее, чем большинство команд признают. Если ваше действие называется runBillingTask, оно скрывает суть. Если оно называется chargeMonthlySubscription или approveRefund, люди могут обсуждать правило на нормальном языке. В этом стиле самая большая польза: он делает владение видимым без необходимости большого редизайна.
Для первого шага обведите каждое место, где фоновый воркер принимает бизнес-решение. Переименуйте технические действия в реальные бизнес-действия. Проверьте, что каждое событие сообщает факт, а не инструкцию. Убедитесь, что у каждой политики есть одна ясная причина существовать.
Сделайте это для одного шумного процесса сначала. Возвраты, истечение триала, восстановление неудачных оплат и отмена заказов — хорошие кандидаты, потому что со временем они обычно собирают скрытые правила.
Если нужна внешняя проверка, Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами как Fractional CTO и советник. Он помогает распутать владение, потоки событий, инфраструктуру и AI-усиленные процессы разработки, не навязывая тяжёлого переработки.
Когда страница станет достаточно понятной, чтобы продуктовый менеджер, инженер и оператор прочитали её одинаково, вы почти у цели. Обычно тогда код тоже начинает упрощаться.
Часто задаваемые вопросы
В чём разница между командой и событием?
Команда просит одного владельца принять решение, например ApproveRefund. Событие сообщает факт, который уже случился, например RefundApproved.
Если их смешать, фоновый код начнёт вести себя как владелец, и правило станет трудно найти.
Как понять, кто должен владеть бизнес-правилом?
Спросите, кто в бизнесе может сказать «да» или «нет» для этого правила. Разместите команду там, пусть этот владелец проверит правило и сохранит изменение состояния до того, как что-то ещё отреагирует.
Если два обработчика могут принять одно и то же решение, владение уже размыто.
Когда стоит использовать политику?
Используйте политику после того, как событие подтвердит, что что-то уже произошло. Политика должна соединять одну область с другой, отправляя следующую команду.
Она не должна принимать первое бизнес-решение или менять данные сама только потому, что заметила событие.
Может ли фоновый обработчик принимать бизнес-решения?
Только если этот обработчик действительно владеет правилом и получил явную команду принять решение. Большинство фоновых обработчиков должны реагировать на завершённое решение, а не придумывать его позже.
Если задержка очереди меняет результат, правило находится не в том месте.
Почему команды вроде ProcessOrder — плохая идея?
Названия вроде ProcessOrder скрывают слишком много. Люди перестают понимать, валидирует ли код платёж, резервирует ли товар, отгружает ли или просит одобрения.
Понятное имя вынуждает иметь явного владельца и одно решение. Тогда баги проще отследить, а изменения — обсудить.
Могут ли cron-задания или таймеры запускать бизнес-действия?
Таймеры и cron подходят для планирования, повторных попыток и напоминаний. Не позволяйте им догадываться, должно ли происходить бизнес-действие.
Если таймер решает, можно ли отправлять заказ или одобрять возврат, значит реальное правило там, где ему не место.
Как замапить запутанный поток событий?
Начните с одного рабочего процесса и опишите его слева направо. Укажите команду, изменение состояния, событие и каждую политику, которая просит другого владельца действовать.
Если вы не можете сказать, кто решил, что изменилось и кто только отреагировал, поток всё ещё скрывает владение.
Что значит безопасный replay в системах с событиями?
Повторный проигрыш не должен делать второй платёж, не должен отправлять второе письмо или создавать дубликат тикета. Последующие команды должны иметь защиты, чтобы их можно было безопасно запустить снова.
Обычно это значит: фиксируйте факты в состоянии, а события используйте как отчёт о том, что уже случилось, а не как запросы.
Какие признаки того, что владение размывается?
Ищите обработчики, которые вызывают много сервисов, ретрай-воркеры с проверками одобрения и отчётные задания, меняющие бизнес-состояние. Эти места часто прячут правила в неправильной части системы.
Ещё один плохой знак: команда спрашивает «Кто решил, что это должно случиться?» и никто не может назвать одно место.
С чего начать, если система уже кажется запутанной?
Выберите самый шумный рабочий процесс — чаще всего возвраты, отмены или неудачные платежи. Переименуйте команды в понятные бизнес-термины и вынесите решения из общих воркеров.
Не нужен глобальный рефакторинг: один ясный поток часто задаёт стиль для остальной системы.


