CTO-блокнот: один реестр для систем, владельцев и расходов
CTO-блокнот помогает держать в одном месте системы, владельцев, типовые сбои и регулярные расходы, чтобы команда меньше гадала и быстрее решала обычные проблемы.
Содержание
Почему эта проблема возвращается снова и снова
Маленькие компании редко решают специально потерять контроль над своими системами. Это происходит понемногу. Один человек настраивает мониторинг, другой покупает SaaS-инструмент, третий добавляет задачу бэкапа, и всё это так и не попадает в один общий реестр. Спустя несколько месяцев команда по-прежнему работает на том же стеке, но никто не видит полную картину.
Потом что-то ломается в самый неудобный момент. Срабатывает алерт по базе данных, но человек, который его настраивал, уже ушёл. Не проходит платёж за старый сервис, и никто не понимает, нужен ли он вообще. Ломается вход в систему, и команда тратит два часа только на то, чтобы выяснить, какой поставщик за это отвечает, прежде чем кто-то сможет начать чинить проблему.
Вот это повторяющееся «разобраться сначала» и есть настоящая налоговая надбавка. Команды снова и снова задают одни и те же вопросы: для чего нужна эта система? Кто за неё отвечает? Что ломается первым? Сколько это стоит каждый месяц? Без живого реестра люди раз за разом решают одну и ту же загадку.
Отсутствие владельцев делает медленные проблемы ещё хуже. Если никто явно не отвечает за бэкапы, продления, правила доступа или отслеживание ошибок, эти задачи постепенно превращаются в инциденты. Хуже и отсутствие истории. Когда команда не записывает прошлые сбои, она забывает странные детали, которые в следующий раз сэкономили бы время: ограничение по частоте запросов, проблему с расписанием cron или тот сервер, у которого раз в несколько недель заканчивается диск.
Это быстро становится дорогим даже для маленькой команды. Вы платите простоями, дублированием работы, неожиданными счетами и стрессом. И ещё платите плохими решениями, потому что люди приводят в порядок то, что видят, и игнорируют то, о чём просто забыли.
Проблема возвращается снова и снова, потому что работа кажется маленькой — ровно до того момента, когда уже нет.
Что должно быть в блокноте
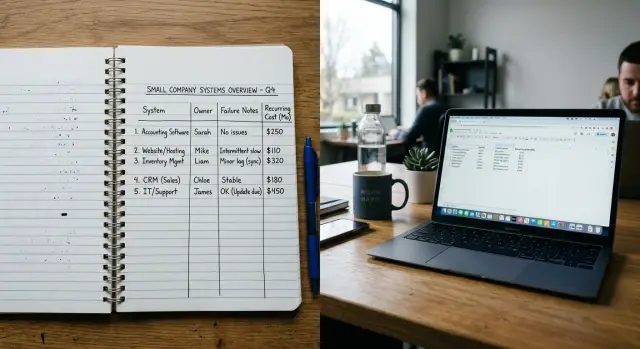
Хороший CTO-блокнот — это короткий рабочий реестр, а не огромная вики. Каждая запись должна отвечать напарнику на простые вопросы: что это за система, кто за неё отвечает, как она обычно ломается и сколько стоит её поддержка.
Начните со всего, от чего зависит компания, а не только с продуктового кода. Включите SaaS-инструменты, облачные аккаунты, поставщиков, внутренние сервисы, запланированные задачи, домены, сертификаты, бэкапы, аналитику, платёжные инструменты и тот странный скрипт, о котором помнит только один человек.
Большинству команд подойдут одни и те же базовые поля для каждой записи:
- название системы и короткая цель
- основной владелец и запасной владелец
- поставщик или внутренний источник
- типичные признаки сбоя и первые проверки
- ежемесячная стоимость, дата продления и кто оплачивает
Основным владельцем должен быть не тот, кто когда-то всё это настроил, а тот, кто реально может принять решение. Запасной владелец не менее важен. Люди уходят в отпуск, меняют роль или увольняются, и именно тогда видно, насколько слабым было владение.
Ноты о сбоях держите практичными. «Почта сломалась» — слишком расплывчато. «Письма для сброса пароля перестали отправляться; сначала проверьте DNS-записи, лимит отправки и недавние изменения в конфигурации» — это уже даёт человеку точку входа за две минуты.
С расходами нужен тот же уровень конкретики. Запишите обычные ежемесячные траты, годовые контракты, следующее продление, карту или владельца счёта и любой лимит использования, который может резко вырасти без предупреждения. Именно так регулярные расходы на софт перестают быть сюрпризом и становятся осознанным выбором.
Короткие записи выигрывают. Если страницу обновлять полчаса, никто не будет держать её в актуальном состоянии. Несколько понятных строк на систему лучше, чем идеальный документ, к которому никто не прикасается.
Начните с того, что у вас уже есть
Начните с систем, с которыми команда работает каждую неделю. Обычно это сначала продакшен, а не красивые идеи из плана. Если от этого зависит клиент, или ваша команда использует это для релиза, поддержки, оплаты или входа в систему, это должно быть в блокноте.
Большинство небольших команд в первую очередь забывают скучные вещи. Они помнят приложение и базу данных, а потом забывают про регистратора домена, DNS, почтовые аккаунты, платёжные инструменты, облачный хостинг, бэкапы и место, куда приходят счета. Часто именно эти системы стоят за самыми неприятными сбоями, потому что о них вспоминают только тогда, когда ломается доступ или заканчивается срок карты.
Простой первый проход должен охватывать клиентское приложение и админские инструменты, хостинг и облачные аккаунты, домены и DNS, почту, биллинг и платежи, аналитику, отслеживание ошибок, бэкапы и любые скрипты или cron-задачи, которые один человек тихо поддерживает.
Последняя группа важнее, чем кажется. Почти в каждой команде есть скрипт, который импортирует лиды, ротацией закрывает логи, продлевает сертификаты, чистит данные или отправляет отчёт в финансы. Если его понимает только один человек, относитесь к нему как к настоящей системе. Запишите, что он делает, где запускается и кто может его исправить.
Первую версию держите лёгкой. Не нужны диаграммы архитектуры, поток пакетов или все конфиги подряд. Добавьте название системы, назначение, владельца, место входа, дату продления, если она есть, ежемесячную стоимость, если она известна, и короткую заметку о том, что ломается при сбое.
Такой лёгкий подход работает, потому что он снижает порог входа. Люди быстрее заполняют простую страницу, чем идеальный шаблон. После пары циклов проверки блокнот становится достаточно полезным, чтобы отвечать на базовые вопросы за минуты, а не в утренней панике в понедельник.
Назначайте владельцев без лишней сложности
Блокнот работает, когда у каждой системы есть один понятный владелец. Это не значит, что один человек делает всё. Это значит, что один человек принимает решение, когда что-то ломается, когда инструменту нужна доработка или когда счёт выглядит неправильно.
Если два человека «делят» владение, никто не чувствует полной ответственности. Небольшие команды постоянно на этом спотыкаются. База данных вроде бы у инженерной команды, хостинг — у того, кто его когда-то настроил, а биллинг — у финансов до тех пор, пока не начинается сбой. Потом все под давлением задают одни и те же вопросы.
Правило должно быть простым: один основной владелец и один запасной.
Для каждой системы укажите основного владельца, запасного владельца, решения, которые основной владелец может принимать без согласований, и что команда должна делать, если оба недоступны.
Этот пункт важнее, чем ожидают многие команды. «Владелец: Сэм» — этого недостаточно. Запишите, что именно Сэм может решать. Например, Сэм может одобрять изменения в плагинах GitLab, ротировать секреты, увеличивать облачные расходы до определённой суммы или обращаться к поставщику за поддержкой. Это экономит время, потому что люди перестают гадать, где проходит граница.
Запасной владелец должен быть реальным, а не формальным. Если Приа — запасной владелец для продакшен-хостинга, у неё должен быть доступ, контекст и достаточно практики, чтобы справляться с типовыми проблемами. Имя без доступа — это просто украшение.
Нужен и запасной маршрут. Если оба владельца недоступны, запишите следующий шаг простыми словами. Возможно, команда пишет в конкретный ops-канал, звонит фаундеру или обращается к внешнему консультанту, который уже знает стек. Для маленькой компании это может быть fractional CTO, который быстро подключится и примет решение.
Этот раздел блокнота должен оставаться скучным. Если новый сотрудник понимает схему владения за две минуты, значит, вы всё сделали правильно.
Записывайте сбои так, чтобы ими действительно могли пользоваться
CTO-блокнот доказывает свою ценность в обычный вторник, когда что-то ломается. Людям не нужна теория отказов. Им нужна короткая заметка, которую можно пробежать глазами за 30 секунд.
Описывайте каждую проблему простыми словами. Пишите «клиенты не могут войти» или «платёжные письма перестали уходить», а не ярлыки вроде «деградация auth» или «инцидент с почтовым сервисом». Читателем может быть фаундер, руководитель поддержки или разработчик, который не создавал эту часть системы.
В каждой записи о сбое должны быть ответы на четыре вопроса:
- Что люди замечают первым?
- Какие три проверки экономят больше всего времени?
- Что обычно является причиной?
- Когда нужно эскалировать проблему?
Первые признаки помогают рано понять, что именно происходит. Хорошая заметка выглядит так: «панель тормозит», «новые регистрации перестали появляться» или «поддержка видит жалобы на двойное списание». Такие подсказки полезнее, чем расплывчатая фраза о том, что сервис нестабилен.
Первые проверки держите короткими и практичными. Если отчёты перестали обновляться, проверьте, не изменился ли после недавнего деплоя worker, не зависла ли очередь и есть ли свободное место на диске базы данных. Трёх проверок достаточно. Длинный чек-лист только тормозит.
Записывайте ту причину, с которой сталкиваетесь чаще всего, а не каждый редкий крайний случай. Возможно, background worker падает после неудачного деплоя. Возможно, истёк ключ стороннего API. Возможно, один cron-задача тихо остановилась. Люди быстрее чинят проблемы, когда знают типичного виновника.
Задайте чёткую точку эскалации. Не оставляйте людей в догадках. Эскалируйте, если платёжный путь не работает больше 10 минут, если данные клиента выглядят неверно или если после первых трёх проверок никто не может подтвердить причину.
Именно это делает tracking сбоев полезным: меньше паники, меньше случайных догадок и быстрее передача ответственности.
Отслеживайте регулярные расходы до того, как они вас удивят
Небольшие команды редко перерасходуют деньги из-за одной большой ошибки. Деньги утекают через двадцать маленьких подписок, годовые продления, о которых никто не помнит, и облачные сервисы, которые тихо растут каждый месяц. К тому моменту, когда финансы задают вопрос по счёту, продление уже произошло.
Соберите все регулярные расходы в одном месте. В CTO-блокноте одна простая таблица работает лучше, чем разбросанные квитанции, цепочки писем и наполовину обновлённая таблица в чужой папке. Если сервис снова спишет деньги в следующем месяце или году, ему место в списке.
Сложный формат не нужен. Каждый раз нужны одни и те же поля: название инструмента, сумма, период оплаты, дата продления и человек, который утверждает расход. Последнее важно сильнее, чем многие думают. Когда за счёт никто не отвечает, никто и не проверяет, есть ли в нём смысл.
| Инструмент или сервис | Сумма | Период | Дата продления | Кто утверждает | Статус |
|---|---|---|---|---|---|
| Отслеживание ошибок | $240 | Ежемесячно | 1-е число каждого месяца | Head of engineering | Активен |
| Инструмент для дизайна | $1,200 | Ежегодно | 14 окт | Product lead | Проверить использование |
| Staging server | $180 | Ежемесячно | 12-е число каждого месяца | CTO | Кандидат на отключение |
| CRM add-on | $600 | Ежегодно | 2 ноя | Sales lead | Цена выросла |
Колонка со статусом реально экономит деньги. Отмечайте инструменты, которыми уже никто не пользуется, аккаунты бывших подрядчиков, дублирующие сервисы и всё, что существует «на всякий случай». У большинства компаний есть хотя бы несколько подписок, от которых не зависит ни один текущий процесс.
Даты продления требуют большего, чем просто напоминание в день списания. Ставьте точку проверки за 30 дней до ежегодных планов и хотя бы за 7 дней до ежемесячных. Это даёт время задать простые вопросы: выросло ли использование? Поднял ли поставщик цену? Нужен ли нам всё ещё этот уровень тарифа?
Короткого ежемесячного ревью достаточно. Просмотрите таблицу, отметьте скачки цен и попросите каждого, кто утверждает расход, подтвердить трату. Привычка скучная, и именно поэтому она работает.
Собирать всё по шагам
Выберите одно место и придерживайтесь его. Блокнот ломается, когда часть заметок живёт в чате, часть — в старых документах, а остальное — в голове у одного человека. Используйте инструмент, который команда уже открывает каждую неделю, даже если он совсем простой.
Держите шаблон небольшим. Если страница выглядит как форма, люди будут её избегать. Для старта достаточно одной страницы на систему. Запишите, что делает система, кто за неё отвечает, как она чаще всего ломается, сколько стоит каждый месяц и где находится вход, панель или алерты.
Этого достаточно, чтобы блокнот был полезен уже в первый день.
Не пытайтесь задокументировать всё сразу. Заполните первые десять систем на этой неделе. Начните с тех, чей сбой навредит сильнее всего или чей текущий владелец завтра возьмёт выходной. Для многих небольших команд это основное приложение, хостинг, домен и DNS, почта, платежи, бэкапы, аналитика, отслеживание ошибок, support inbox и кодовый репозиторий.
Затем попросите каждого владельца потратить 10–15 минут на проверку своих записей. Держите ревью узким. Нужно исправить неверные названия, пропущенные шаги, старые стоимости и расплывчатые заметки о сбоях. Если на одну страницу уходит час, шаблон слишком тяжёлый.
После этого введите простую ежемесячную привычку. Поставьте в календарь 15 минут. Обновляйте расходы, имена владельцев и любые новые сбои, которые удивили команду. Этот маленький ритм важнее, чем идеальный первый черновик.
Если вы работаете с fractional CTO, этот общий реестр быстро сокращает лишнюю работу. Люди перестают задавать одни и те же вопросы о настройке, а новые проблемы решаются с контекстом, а не наугад.
Простой пример маленькой команды
Команда из семи человек делала клиентский портал, небольшой API, фоновые задачи и несколько платных инструментов. У них были хорошие продуктовые инженеры, но не было platform engineer. Фаундер вёл облачный биллинг, один разработчик при необходимости управлял деплоями, а все остальные знали достаточно, чтобы справляться в обычной работе.
Эта схема работала, пока в воскресный вечер не сломался вход в систему. Истёк auth secret после поспешного изменения, сделанного два месяца назад. Алерты приходили на старый ящик, который никто не проверял. Один инженер пытался починить приложение, другой искал старые сообщения в чате, а фаундер копался в менеджерах паролей, чтобы понять, у кого ещё остался admin access. Сбой длился три часа, в основном потому, что за систему никто явно не отвечал.
После этого они сделали блокнот в общем документе. Ничего особенного. Для каждой системы они записали, что она делает, кто за неё отвечает, как она обычно ломается и сколько стоит каждый месяц.
Они начали с инструментов, которыми пользовались каждую неделю: хостинг, база данных, auth, доставка писем, отслеживание ошибок и бэкапы. Для auth они назвали одного инженера основным владельцем и одного — запасным. Указали место входа в админку, даты продления и первые проверки, которые нужно сделать, если пользователи не могут войти. Для доставки писем отметили, кто может обновлять DNS-записи. Для отслеживания ошибок записали, куда идут алерты и кто оплачивает счёт.
Изменение было скромным, но быстро окупилось. Через две недели фоновые задачи замедлились, потому что на worker закончился диск. На этот раз никто не гадал. Команда открыла блокнот, посмотрела на владельца, проверила указанную причину сбоя и исправила проблему примерно за 20 минут.
Ещё более заметной была другая польза. Люди перестали задавать одни и те же вопросы в чате. Кто отвечает за бэкапы? Какая карта оплачивает базу данных? Кто может менять DNS? Блокнот закрыл эти базовые вопросы, и команда вернулась к выпуску продукта.
Ошибки, из-за которых блокнот бесполезен
Блокнот перестаёт помогать в тот момент, когда превращается в домашнее задание. Если человеку нужно десять минут, чтобы найти один ответ, он перестанет его открывать.
Самая частая проблема — размер. Команды начинают с простого списка систем и владельцев, а потом добавляют страницы, крайние случаи, старые планы и скопированные заметки по настройке, пока всё не начинает напоминать огромную вики. Маленькой компании не нужен музей всех технических мыслей подряд. Ей нужен короткий рабочий реестр, который быстро отвечает на простые вопросы: что это, кто отвечает, что ломается и сколько это стоит?
Язык тоже может всё испортить. Если каждая запись звучит как внутренняя инженерная записка, половина компании автоматически вылетает из процесса. Пишите для человека, которого в 7:30 утра втянули в проблему и которому нужен минимум с первого прочтения. «Платежи падают, если перестаёт работать card webhook» лучше, чем плотный абзац, набитый названиями инструментов и внутренним жаргоном.
Расходы часто отслеживают самым слабым способом: счёт вроде бы есть, но конкретного владельца у него нет. Так старые подписки и висят месяцами. У каждого регулярного инструмента или сервиса должно быть одно имя рядом. Когда облачный счёт резко растёт или лицензия продлевается, кто-то должен понимать почему, не устраивая детектив.
Ещё одна типичная ошибка — ждать чистых и идеальных данных, прежде чем что-то записывать. Обычно это значит, что не записывается ничего. Неполный, но существующий блокнот лучше идеального, который живёт только в чьей-то голове.
Есть и ещё одна ловушка. Один человек становится единственным редактором. Потом обновления накапливаются, детали устаревают, и блокнот тихо умирает, когда этому человеку становится некогда или он уходит.
Несколько правил помогают сохранить его полезным:
- держите записи короткими
- пишите простыми словами
- назначайте одного владельца на систему и на расход
- обновляйте заметки по ходу работы, а не «потом»
- дайте людям, которые ближе всего к системе, редактировать свою запись
Если небольшая команда может ответить на вопросы «кто за это отвечает, что ломается первым и сколько мы за это платим» меньше чем за две минуты, блокнот делает свою работу.
Короткое ежемесячное ревью
Ежемесячное ревью не требует долгого совещания. Для большинства небольших команд достаточно 20–30 минут, если один человек открыл блокнот, поделился экраном и проходит по нему строка за строкой.
Эта привычка работает, потому что мелкие изменения быстро накапливаются. Команда добавила один мониторинговый инструмент, подрядчик взял на себя сервис, инцидент вскрыл слабый план бэкапов, и через два месяца никто уже не помнит, что именно изменилось.
Используйте один и тот же короткий проход каждый месяц. Добавьте все системы, которыми команда начала пользоваться с прошлого ревью, с названием, назначением, владельцем, местом входа и ежемесячной стоимостью, если она есть. Проверьте каждого владельца, потому что смена ролей происходит тихо, а блокнот устаревает быстрее, чем люди ожидают. Возьмите один недавний инцидент и обновите заметки, пока детали ещё свежи. Запишите, что сломалось, как команда это заметила и каким был первый фикс. Проверьте продления, которые наступят в ближайшие 30–60 дней, потому что именно там чаще всего проскакивают регулярные расходы на софт. И наконец, назначьте одного человека, который очистит устаревшие записи до следующего ревью. Если за уборку никто не отвечает, старые заметки остаются навсегда.
Держите планку простой. Короткая и верная запись лучше идеальной страницы, которую никто не обновляет.
Одно простое правило помогает не расплыться: если инструмент может сломать клиентскую работу, стоить денег каждый месяц или будить кого-то ночью, ему место в блокноте.
Если вы работаете с fractional CTO или внешним советником, такое ревью становится ещё полезнее. Они быстро заметят пробелы, но только если блокнот соответствует реальности.
Что делать дальше
Выберите одного человека и дайте ему сделать первый проход. Не ждите идеального владельца или большого проекта по чистке. Основатель, техлид, ops-менеджер или финансовый лидер вполне могут начать блокнот, если умеют задавать базовые вопросы и добирать недостающие детали.
Забронируйте один час на этой неделе. Откройте обычный документ или таблицу и разберите, за что компания уже платит и от чего зависит. Укажите название системы, кто ею пользуется, что сломается при сбое и ежемесячную стоимость, если вы её знаете. Даже если заполните только десять строк, этого уже достаточно, чтобы начать.
Первая сессия лучше всего работает, если она остаётся маленькой:
- перечислите системы, которыми люди пользуются каждую неделю
- добавьте одного владельца для каждой системы
- отметьте по одному типичному сбою для каждой
- запишите регулярную стоимость или пометьте её как «неизвестно»
- назначьте следующий шаг через две недели
Потом используйте блокнот в следующем разборе инцидента, даже если он всё ещё выглядит черновиком. Когда перестаёт отправляться почта, падает деплой или появляется неожиданный счёт, обновите запись, пока детали свежие. Так забытый документ превращается в инструмент, которому доверяют.
Некоторым компаниям нужна внешняя структура, потому что у них нет времени проталкивать это самим. В таком случае fractional CTO или советник может посмотреть черновик, закрыть пробелы и задать простой ритм обновлений. Oleg Sotnikov на oleg.is делает именно такую работу со стартапами и небольшими командами, которым нужна более чёткая ответственность за системы, инфраструктурные решения и практичная AI-оптимизация операционки.
Завершите одним запланированным действием, а не большим планом. Поставьте в календарь 30-минутное ревью, назовите людей, которые должны прийти, и решите, какие пять систем вы завершите в первую очередь.
Часто задаваемые вопросы
Что такое CTO-блокнот?
Это общий рабочий реестр для систем, которыми пользуется компания. В каждой записи держите только главное: что делает система, кто за неё отвечает, как она ломается и сколько стоит. Если команда может найти эти базовые сведения меньше чем за две минуты, блокнот работает.
Что нужно документировать в первую очередь?
Начните с продакшена и инструментов, которыми команда пользуется каждую неделю. Это приложение, база данных, хостинг, домены, DNS, почта, платежи, бэкапы, аналитика, error tracking и кодовый репозиторий. Небольшие скрипты тоже стоит добавить, если один человек незаметно поддерживает их в рабочем состоянии.
Сколько деталей должно быть в каждой записи?
Держите всё очень лаконичным. Обычно хватает короткого описания, основного владельца, запасного владельца, места входа или панели управления, первых проверок, даты продления и ежемесячной стоимости. Если запись обновляется слишком долго, люди перестанут её обновлять.
Кто должен владеть каждой системой?
Назначьте одного основного владельца и одного запасного. Основной владелец должен принимать решения, а не просто помнить старую настройку. Запишите, что именно этот человек может утверждать, чтобы команда не тратила время на лишние вопросы во время инцидента.
Как писать заметки о сбоях так, чтобы ими реально пользовались?
Пишите простыми словами, что люди замечают первым, например «пользователи не могут войти» или «отчёты перестали обновляться». Затем добавьте три первых проверки, типичную причину и момент, когда нужно эскалировать проблему. Так у команды будет быстрое и понятное начало.
Нужно ли отслеживать и регулярные расходы?
Да, регулярные расходы стоит вести в том же реестре. Укажите сумму, период списания, дату продления и того, кто утверждает расходы. Так легче заметить неожиданные продления и понять, какие инструменты больше не нужны.
Где хранить CTO-блокнот?
Используйте одно общее место, которое команда уже открывает каждую неделю, например обычный документ, внутреннюю вики или простую таблицу. Важно, чтобы туда было легко вносить правки и легко искать. Переписки в чате и личные заметки только распыляют контекст и замедляют всех.
Как часто нужно пересматривать блокнот?
Для большинства небольших команд достаточно короткого ежемесячного ревью. Потратьте 20–30 минут на обновление владельцев, добавление новых систем, фиксацию недавних сбоев и проверку скорых продлений. Небольшие ежемесячные правки лучше большой чистки два раза в год.
Какие ошибки делают CTO-блокнот бесполезным?
Обычно блокнот портят двумя способами: делают его слишком большим или ждут идеальных данных. Держите записи короткими, пишите простыми словами и дайте людям, которые ближе всего к системе, обновлять свои заметки. Рабочий черновик, которым пользуются, лучше отполированного документа, который никто не открывает.
Может ли небольшая компания сделать это без platform-команды?
Да. Основатель, техлид, ops-менеджер или fractional CTO могут начать первый черновик за час. Для этого не нужны сложные инструменты или отдельная команда. Нужен один общий реестр, понятные владельцы и простой ритм обновлений.


