Производительность CSV-экспорта без замедления живого трафика
Узнайте, как спланировать батчи, снапшоты, очереди и срок хранения скачиваний, чтобы CSV-экспорт не замедлял заказы и админские задачи.
Содержание
Что идёт не так при большом экспорте
CSV-экспорты начинают создавать проблемы, когда один запрос пытается сделать всё сразу. Приложение запрашивает у базы огромный набор строк, превращает их в файл и держит веб-запрос открытым до завершения работы. Звучит просто. Но на загруженной системе это тормозит всё остальное.
Объём — первая проблема. Когда экспорт тянет слишком много строк за раз, базе приходится сортировать, джойнить и отправлять большое количество данных одновременно. CPU растёт, память увеличивается, а чтения с диска всплескивают. Если приложение ещё и форматирует файл построчно, в работу включается сервер приложений.
Вторая проблема — конкуренция. Экспорты не работают в одиночку. Они конкурируют с запросами оформления заказа, поиском, обновлением дашбордов и административной работой. Команда продаж может нажать «Экспорт» в тот момент, когда клиенты оформляют заказы. Пользователи не заботятся о том, что идёт отчёт — они замечают, что страницы, которые раньше грузились за полсекунды, теперь тянутся три секунды.
Третья проблема — согласованность. Если записи меняются во время экспорта, файл может смешать старые и новые данные. В одной строке — прежний статус заказа, в следующей — уже обновлённый, и итоги перестают сходиться. Службе поддержки приходится объяснять, почему CSV не совпадает с тем, что видел пользователь в продукте.
Крупные экспорты также могут держать локи дольше, чем ожидалось, заполнять кеши данными отчётов, которые никто не будет переиспользовать, и поднимать использование диска настолько, что это влияет на всё остальное. Поэтому экспортам нужен свой путь. Рассматривайте их как фоновые задачи, а не обычные запросы страниц.
Решите, какие экспорты требуют специальной обработки
Не каждый экспорт требует одинакового потока. Файл на 500 строк обычно можно собрать сразу. Снимок всей истории на 8 миллионов строк не должен бить по базе так же, особенно в часы пик.
Начните с дешёвой оценки количества строк до того, как строить файл. Вам не всегда нужно идеальное число — оценка часто достаточно, чтобы решить, оставлять запрос inline или отправлять в очередь.
Это разделение важнее, чем большинство последующих оптимизаций. Небольшие экспорты должны выглядеть мгновенно. Большие — уходить в фон, где они могут завершиться, не блокируя страницу.
Простое правило работает хорошо. Запускайте экспорт немедленно, если результат небольшой и запрос лёгкий. Отправляйте его в очередь, когда количество строк, диапазон дат или число джойнов превышают ваш предел. Полные выгрузки истории по умолчанию делайте асинхронными. Дайте админам и внутренним инструментам те же лимиты, что и всем остальным, иначе они станут главным источником нагрузки.
Плановые отчёты тоже нуждаются в отдельной полосе. Они предсказуемы — их можно запускать в часы покоя и переиспользовать файл, когда несколько человек хотят один и тот же отчёт. Ручные экспорты ведут себя иначе: они обычно приходят пачками, сразу после изменения фильтров или выбора большого диапазона дат.
Выберите одно значение отсечки и задокументируйте его простым языком. Например: всё до 25,000 строк выполняется сразу, всё больше — уходит в очередь. Точное число зависит от вашей системы, но правило должно быть легко запоминаемым для команды и понятным для пользователей.
Если бухгалтер экспортирует транзакции за прошлую неделю, приложение может вернуть файл сразу. Если запрошены семь лет по всем аккаунтам — поставьте задачу в очередь, уведомьте пользователя, когда файл готов, и держите живой трафик в стороне.
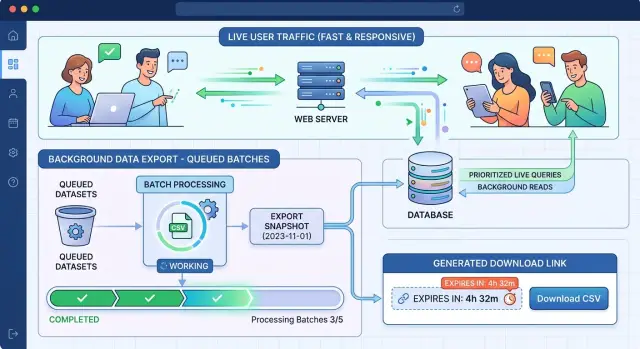
Постройте поток экспорта пошагово
Хороший поток экспорта сокращает время запроса страницы и выводит тяжёлую работу из браузерного раунда.
Начните с сохранения запроса точно так, как его сделал пользователь. Сохраните фильтры, порядок сортировки, выбранные колонки, часовой пояс и ID пользователя. Когда пользователь вернётся позже, вы сможете восстановить тот же файл, а не гадать, что он хотел.
Затем создайте запись задачи экспорта. Держите её простой: кто запросил, сохранённые фильтры, текущий статус, местоположение или временное имя файла, метки времени начала, завершения и истечения.
После этого передайте задачу воркеру. Воркер должен читать данные фиксированными батчами — часто по 1,000 или 5,000 строк за раз в зависимости от размера таблицы и стоимости запроса. Маленькие стабильные чтения обычно работают лучше, чем один гигантский запрос, который удерживает ресурсы слишком долго.
По мере завершения каждого батча записывайте его прямо во временный файл. Не держите весь CSV в памяти. Один раз запишите заголовок, затем добавляйте строки батч за батчем до готовности файла. Если задача падает на половине пути — пометьте её как failed и удалите частичный файл.
Пользовательский опыт при таком подходе значительно лучше. Менеджер поддержки, который экспортирует все заказы за последние 90 дней, должен видеть понятный статус: queued, running или ready — а не вкладку, зависшую на две минуты.
Когда последний батч завершён, пометьте задачу как ready, сохраните окончательный размер файла и количество строк, и покажите возможность скачивания в UI. Простого обновления статуса обычно достаточно. Страница остаётся быстрой, экспорт продолжается, и пользователь знает, что происходит.
Используйте снапшоты, чтобы файл был стабильным
Экспорт должен соответствовать состоянию данных в момент клика «Экспорт», а не изменениям следующих десяти минут. Без стабильного представления строки могут сдвигаться между батчами: записи пропускаются, дублируются или попадают не в ту страницу.
Сохраните время отсечки при создании задачи. Каждый батч должен использовать этот же cutoff, а не текущее время старта батча. На практике это часто означает фильтр вроде "created before cutoff_time" плюс фиксированный порядок сортировки, обычно по уникальному ID.
Это важнее многих оптимизаций запроса. Все воркеры получают одинаковый взгляд на набор результатов, даже если приложение продолжает принимать записи.
Если СУБД поддерживает snapshot reads или транзакции уровня repeatable read — используйте их для экспортов. Истинный снапшот исключит поздние вставки, обновления и удаления из файла. Результат останется согласованным от первой до последней строки.
Если полный снапшот слишком дорог, читайте с реплики, когда это возможно. Это снизит нагрузку на основную базу. Но даже в этом случае сохраняйте cutoff: реплика без фиксированного cut‑off всё ещё может смещаться между батчами.
Пейджинг требует особой аккуратности. Offset-пагинация — простой путь потерять или дублировать строки при долгом экспорте. Курсорная батчинг с фиксированным порядком безопаснее: выбирайте строки, где ID больше последнего увиденного, сохраняя исходный cutoff-фильтр.
На загруженных приложениях этот баг может долго прятаться. Потом один большой экспорт попадает в пик записи — и файл уже не соответствует ожиданиям пользователя. Заморозка набора результатов в момент старта задачи предотвращает этот беспорядок.
Ставьте экспорты в очередь, чтобы пользователи не ждали на странице
Если большой экспорт выполняется внутри веб-запроса, пользователь ждёт, приложение держит соединения открытыми, и все остальные платят за это. Очередь решает проблему.
Странице нужно только создать запись задачи экспорта, сохранить фильтры и передать работу фоновому воркеру. Приложение может быстро ответить экрано́м статуса вместо того, чтобы держать запрос минутами.
Пользователям не нужно много подробностей. Четырёх статусов обычно достаточно:
- queued
- running
- ready
- failed
Эти метки сокращают вопросы в поддержку больше, чем команды ожидают. Если файл готов — покажите кнопку скачивания. Если он упал — коротко объясните причину и дайте возможность повторить.
Не позволяйте всем экспортам запускаться одновременно. Ограничьте число параллельных задач, глобально и по аккаунту при необходимости. Две или три воркер‑нить часто достаточно для тяжёлых экспортов, пока остальное приложение остаётся отзывчивым.
Retries тоже важны, но полные рестарты тратят время. Сохраняйте прогресс после каждого батча, чтобы воркер мог повторить небольшую неудачу — например, разрыв соединения с БД или временную ошибку хранилища — без перестройки всего файла с самого начала.
Отмена стоит добавить рано. Люди нажимают экспорт дважды, меняют фильтры или уходят со страницы. Позвольте отменять очередные задачи сразу, а запущенные — корректно останавливать после текущего батча.
Обычная запись задачи обычно хранит всё необходимое: тип экспорта, фильтры, текущий батч, путь к файлу, количество строк и сообщение об ошибке. Этого достаточно, чтобы UI оставался честным, а воркеры восстанавливались после мелких сбоев без догадок.
Батчьте работу, чтобы база могла дышать
Большой экспорт должен вести себя как капельный полив, а не пожарная струя. Запросить у базы всё сразу — значит заставить живой трафик конкурировать с экспортом за CPU, память и чтения диска.
Читайте данные маленькими предсказуемыми кусками. На практике это часто 1,000 или 5,000 строк за раз, записывайте их в CSV и переходите дальше. Предсказуемый батчинг держит память стабильной и упрощает восстановление после ошибок.
Порядок сортировки тоже важен. Используйте поле, по которому уже есть индекс, например автоинкрементный ID или проиндексированное created_at. Это даёт базе простой путь по таблице. Случайные сортировки и тяжёлый offset-пейджинг становятся медленнее по мере роста экспорта.
Держите размер батча стабильным на запуске. Многие команды начинают слишком рано подстраиваться. Выберите одно значение, протестируйте его под обычной нагрузкой и посмотрите, сколько времени занимает каждый батч.
Пара измерений скажет вам почти всё: время запроса на батч, загрузка CPU и чтения базы, время ожидания в очереди для обычных пользовательских запросов и общее время экспорта от первой строки до финального файла.
Если время запроса растёт, сначала уменьшите размер батча. Меньшие чтения обычно наносят меньше вреда, чем попытка пройтись огромным батчем. Если 5,000 строк за запрос начинают замедлять страницы в рабочие часы — опуститесь до 1,000 и протестируйте снова.
Короткие паузы между батчами могут помочь, но только когда базе нужна передышка. Пауза в 100–300 миллисекунд может сгладить нагрузку на занятой системе. На спокойной системе паузы только увеличивают время ожидания пользователя.
Здесь команды обычно выигрывают или проигрывают. Медленные стабильные чтения менее драматичны, но они позволяют приложению оставаться работоспособным, пока экспорт завершается в фоне.
Установите срок жизни загрузок и правила очистки
Файлы экспорта не должны жить вечно. Старые файлы тратят место, увеличивают риск приватности и вводят в заблуждение, когда люди качают отчёт, который уже не соответствует продукту.
Давайте каждому файлу короткую жизнь. Для многих продуктов достаточно 24 hours. Если в экспорте чувствительные данные клиентов — несколько часов надёжнее.
Храните время истечения вместе с записью задачи экспорта — рядом с путём к файлу, владельцем, временем создания и статусом. Тогда приложение решит, показывать ли кнопку скачивания или просить пользователя сгенерировать новый файл.
Большинству команд достаточно простых правил. Сохраняйте expires_at при завершении задачи. Не предлагайте скачивание после этого времени. Запускайте периодическую очистку, чтобы удалять просроченные файлы. Либо удаляйте старые записи задач, либо помечайте их как истёкшие. Если файл устарел — генерируйте новый.
Запускайте очистку по расписанию, которое соответствует вашему трафику. Занятая система может чистить каждый час. Малым приложениям хватит раза в день. Важно — регулярность. Если очистка зависит от ручной работы, хранилище заполняется, и забытые файлы остаются месяцами.
Избегайте постоянных публичных URL для скачивания. Люди вставляют их в чаты, тикеты и открывают спустя долгое время. Короткоживущие ссылки, привязанные к задаче и пользователю, снижают этот риск.
Актуальность важнее объёма. Если кто-то экспортировал заказы утром, а пытается повторно скачать вечером, цифры уже могут быть неактуальны. В этом случае сообщите, что файл истёк или устарел, и сгенерируйте новый.
Хорошая очистка делает больше, чем экономит место. Она упрощает систему экспорта и не даёт старым файлам превратиться в ещё одну проблему для команды.
Простой пример из загруженного приложения
Полдень часто самое худшее время для экспорта полного года заказов. Менеджеру магазина нужен CSV для бухгалтерии, пока клиенты оформляют заказы и сотрудники ищут недавние покупки. Если файл строится внутри запроса страницы — всем становится заметно медленнее.
Лучший поток начинается с сохранения фильтров менеджера. Приложение сохраняет диапазон дат, состояния заказов, выбор магазина и колонки, затем создаёт задачу экспорта и ставит её в очередь. Менеджер быстро получает сообщение, что файл готовится, и может вернуться к работе, а не смотреть на спиннер.
Фоновый воркер делает тяжёлую часть. Он читает из снапшота базы, а не из меняющихся живых строк. Это важнее, чем многие команды ожидают. Если во время экспорта произойдёт возврат, отмена или правка адреса — файл по-прежнему отражает одно стабильное состояние.
Воркер читает по 5,000 строк за раз и дописывает каждый батч в CSV. Такой темп обычно достаточно щадящий для базы: память остаётся предсказуемой, длинные запросы реже, и приложение по‑прежнему обслуживает оформление заказов и поиск без сильных тормозов.
Так выглядит здоровый поток экспорта на практике. Пользователям всё равно, что за кнопкой стоит очередь, воркер и снапшот — им важно, чтобы экспорт завершился, а остальная часть приложения оставалась нормальной.
Когда файл готов — храните его ограниченное время и потом удаляйте автоматически. Это даёт менеджеру время скачать файл, не превращая старые экспорты в постоянный архив.
Ошибки, которые создают замедления
Самый быстрый способ навредить производительности — строить файл внутри веб-запроса. Один пользователь нажал Экспорт, приложение открывает долгий запрос к базе, форматирует тысячи строк, пишет файл и держит запрос открытым всё это время. Это занимает воркеры приложения и соединения с базой, в то время как остальные продолжают пользоваться продуктом.
Ещё одна распространённая ошибка — сканирование одной и той же таблицы заново на каждом шаге батча. Если каждый шаг стартует со свежего полного сканирования, база делает гораздо больше работы, чем нужно. Крупные экспорты тогда напрямую конкурируют с живым трафиком, и время ответа для остальных пользователей растёт.
Команды также попадают в беду, когда считают экспорты бесплатными и неограниченными. Если один человек может запустить десять экспортов подряд, и ещё двадцать пользователей сделают то же самое, очередь забьётся дублирующей работой. Ограничения по скорости, лимиты на пользователя и простая дедупликация решают многие проблемы.
Старые файлы создают тихую проблему. Если хранить все экспорты навсегда, хранение растёт, очистка усложняется, и люди продолжают скачивать устаревшие данные через недели. Большинству пользователей файл нужен один раз, а не как постоянный архив.
Сбоящие задачи тоже требуют внимания. Когда задача падает на полпути и система слепо ретраит её, можно получить несколько копий одного и того же экспорта, работающих одновременно. Это тратит CPU, время базы и место на диске. Даём каждой задаче явный статус, отслеживаем повторы и блокируем дублирующие запуски, если предыдущая задача не отменена и не помечена как failed.
Несколько признаков обычно появляются до того, как станет плохо:
- запросы на экспорт держатся открытыми минутами
- нагрузка на чтение базы растёт в часы пик
- пользователи создают один и тот же экспорт несколько раз
- хранилище заполняется старыми CSV-файлами
- упавшие задачи постоянно возвращаются без ясной причины
Если эти проблемы знакомы — исправляйте их рано. Код экспорта выглядит безвредно, пока не начнёт работать при реальной нагрузке.
Быстрая проверка перед выпуском
Экспорт может вести себя нормально в тихой тестовой среде и ломаться под реальной нагрузкой. Тестируйте его в условиях обычного трафика, когда приложение обрабатывает обычные запросы, фоновые задачи и привычный набор чтений/записей. Если экспорт работает только когда система спокойна — он не готов.
Используйте самый большой реальный набор данных, а не маленькую выборку, которая заканчивается за пару секунд. Файл на 5,000 строк мало что скажет о поведении при 500,000 или 5 million. Если данные в продакшне сильно различаются по клиентам — протестируйте на самой большой учётной записи, которую можно безопасно скопировать в непроизводственную среду.
Отслеживайте небольшой набор чисел при каждом тесте: общее время экспорта, время ожидания в очереди, нагрузку на базу в каждом батче, итоговый размер файла и процент успешных запусков при повторных прогонках.
Эти числа покажут, где боль. Долгое общее время может быть допустимо, если очередь коротка и живые запросы остаются быстрыми. Короткий экспорт — всё ещё проблема, если он создаёт пики CPU, держит локи или отодвигает другие задачи.
Сделайте одну скучную проверку, которую команды часто пропускают: убедитесь, что очистка и истечение действительно работают. Сгенерируйте файлы, дождитесь истечения и подтвердите, что приложение удаляет и ссылку на скачивание, и сам файл. Старые экспорты накапливаются быстрее, чем команды думают — особенно когда пользователи повторно пробуют упавшие задачи.
Службе поддержки тоже нужен понятный экран для каждой задачи экспорта. Они должны видеть, кто запустил задачу, когда она стартовала, queued ли она или running, какой у файла размер и почему задача упала. Один такой экран экономит много догадок, когда кто-то говорит: "Мой экспорт не пришёл."
Следующие шаги для вашей команды
Начните с одного экспорта. Выберите отчёт, который сегодня создаёт наибольшую нагрузку на базу, а не тот, который проще восстановить. Один болезненный экспорт быстро даст реальные числа, и эти числа упростят дальнейшие решения.
Прежде чем добавлять новые типы экспортов, решите, какие должны завершаться сразу, а какие могут идти в фон. Команды часто тянут с этим решением — в итоге получают мешанину медленных страниц, таймаутов и тикетов от пользователей, которые думают, что приложение сломано.
Держите план простым. Назовите отчёт, который создаёт наибольшую нагрузку. Пометьте каждый экспорт как instant или queued. Установите лимиты очереди, чтобы несколько тяжёлых задач не выдавили всё остальное. Определите, когда файлы истекают и когда запускается очистка.
Запишите эти правила простым языком. Продукт, поддержка и инженерия должны понимать, что происходит при клике на Экспорт, как долго файл доступен и когда система просит пользователя попробовать снова позже.
Если трафик продолжит расти — возьмите дизайн‑ревью до того, как путь экспорта превратится в ежедневную проблему. Исправить поток на ранней стадии гораздо дешевле, чем разбирать медленное приложение, когда пользователи начинают чувствовать его каждый день.
Если вашей команде нужен второй взгляд, Oleg Sotnikov at oleg.is консультирует стартапы и небольшие компании по архитектуре, инфраструктуре и AI‑ориентированной разработке. Короткий обзор вашего потока экспорта часто достаточно, чтобы поймать дорогие ошибки до их появления в продакшене.
Часто задаваемые вопросы
Почему большие CSV-экспорты замедляют приложение?
Большие экспорты вытаскивают много строк, держат веб-запрос открытым и заставляют базу данных конкурировать с обычными действиями пользователей — оформлением заказа, поиском и дашбордами. Это поднимает загрузку CPU, использование памяти и чтения диска в самый неподходящий момент.
Перенесите тяжёлые экспорты в фоновые задачи, чтобы страница возвращала ответ быстро, а файл собирался вне браузерного запроса.
Когда мне ставить экспорт в очередь вместо немедленного запуска?
Выполняйте экспорт сразу только когда результат маленький и запрос лёгкий. Отправляйте в очередь, когда число строк, диапазон дат или количество джойнов становятся большими.
Простое правило помогает. Например, всё, что больше 25,000 строк, отправляйте в очередь, а полные выгрузки истории всегда делайте асинхронными.
Какой самый простой безопасный поток экспорта?
Сначала сохраните точный запрос: фильтры, порядок сортировки, выбранные колонки, часовой пояс и ID пользователя. Создайте запись задачи экспорта, передайте её воркеру, и пусть воркер пишет CSV батчами во временный файл.
Когда воркер завершит работу, пометьте задачу как ready и покажите ссылку на скачивание в интерфейсе.
Как сохранить CSV консистентным при изменении данных?
Зафиксируйте момент времени (cutoff) в момент клика по «Экспорт». Каждый батч должен использовать этот же cutoff и тот же порядок сортировки.
Если СУБД поддерживает snapshot reads или repeatable read, используйте их — так поздние вставки и обновления не попадут в файл.
Почему стоит избегать offset-пагинации для больших экспортов?
Offset-пагинация может пропускать строки или дублировать их, если новые записи появляются во время длительного экспорта. Чем дальше идёт экспорт, тем хрупче становится offset.
Курсорная батчинг в фиксированном порядке работает надёжнее: читайте строки, где ID больше последнего увиденного, сохраняя исходный cutoff-фильтр.
Какой размер батча стоит выбрать в начале?
Начните с постоянного размера батча, например 1,000 или 5,000 строк. Это держит использование памяти предсказуемым и облегчает ретраи.
Если время отклика страниц растёт или запросы на батч замедляются, сначала уменьшите размер батча. Небольшие предсказуемые чтения обычно наносят меньше вреда, чем один большой запрос.
Стоит ли запускать экспорты с read replica?
Да, если реплика достаточно актуальна и ваш экспорт может допускать небольшую задержку репликации. Чтение с реплики снимет часть нагрузки с мастера.
Но всё равно фиксируйте cutoff. Одна только реплика не предотвратит сдвиг строк между батчами.
Какие статусы должны видеть пользователи?
Большинству продуктов хватает четырёх состояний: queued, running, ready и failed. Пользователям не нужна длинная техническая справка.
Показывайте кнопку скачивания, когда файл готов. Если задача провалилась — короткое объяснение и возможность повторить попытку.
Как долго хранить сгенерированные CSV-файлы?
Храните экспорт недолго, обычно 24 hours или меньше. Если в файле чувствительные данные — несколько часов безопаснее.
Сохраняйте expires_at, скрывайте скачивание после истечения и удаляйте файлы по расписанию, чтобы не накапливать хранение и риск приватности.
Что нужно протестировать перед тем, как запустить новую систему экспорта?
Частые ошибки: строить файл внутри веб-запроса, позволять слишком много параллельных экспортов, повторно пытаться задачу без учёта прогресса или хранить старые файлы навсегда. Дубликаты экспортов от одного пользователя тоже сильно нагружают систему.
Тестируйте на реальных данных в условиях обычного трафика. Отслеживайте время экспорта, время ожидания в очереди, нагрузку на базу, размер файла и то, действительно ли очистка удаляет устаревшие файлы.


