C++ против памяти в управляемой среде выполнения: когда контроль снижает затраты
C++ против памяти в управляемой среде выполнения становится важным, когда лишние выделения, рост кучи и паузы повышают стоимость. Разберитесь, какие нагрузки оправдывают более низкоуровневый контроль.
Содержание
Почему этот выбор меняет реальные расходы
Разница между C++ и памятью в управляемой среде выполнения быстро становится заметной, когда сервис делает много мелкой, повторяющейся работы. Если каждый запрос создает лишние временные объекты, среде выполнения нужно больше места в куче, чтобы успевать за нагрузкой. В итоге потребление памяти оказывается выше, чем можно было бы ожидать только по бизнес-логике.
Высокое потребление памяти — это не просто техническая деталь. В облаке RAM стоит денег каждый час, а всплески памяти часто заставляют брать инстанс большего размера. Сервис, который в C++ спокойно помещается в 2 ГБ, в управляемой среде выполнения может потребовать 4 или 8 ГБ, когда в дело вступают лишние выделения памяти, рост кучи и запас по безопасности.
Счет снова растет под нагрузкой. Когда трафик резко увеличивается, управляемая среда выполнения может расширять кучу, чтобы не заниматься постоянной очисткой. Это какое-то время поддерживает пропускную способность, но одновременно повышает стоимость одного запроса, потому что вы платите за память, которая нужна, чтобы поглощать лишние выделения, а не делать полезную работу.
Паузы делают проблему хуже для загруженных сервисов. Паузы сборки мусора могут длиться всего несколько миллисекунд, но для API с высоким трафиком этого достаточно, чтобы образовалась очередь, выросла хвостовая задержка и начались повторы запросов. Повторы создают еще больше работы, еще больше выделений и еще сильнее давят на ту же систему. В бенчмарке это может выглядеть нестрашно, а в продакшене — болезненно.
C++ меняет расклад, потому что разработчики могут сами контролировать, когда и как выделяется память. Они могут переиспользовать буферы, держать объекты в стеке, использовать пулы для горячих участков и сократить обращение к куче. Такой контроль требует большей аккуратности, но в системах с низкой задержкой он часто снижает и потребление RAM, и джиттер.
Простой пример делает это особенно наглядным. Представьте API, который разбирает JSON, добавляет несколько проверок и возвращает компактный ответ 20 000 раз в секунду. Если среда выполнения выделяет много краткоживущих объектов на каждый запрос, память растет, а очистка начинает мешать времени ответа. Если тот же путь переиспользует память и избегает лишней активности в куче, сервис может уместиться на меньшем числе машин и держать более стабильную задержку. Именно здесь выбор перестает быть академическим и начинает влиять на ежемесячный счет.
Что на самом деле показывает профиль памяти
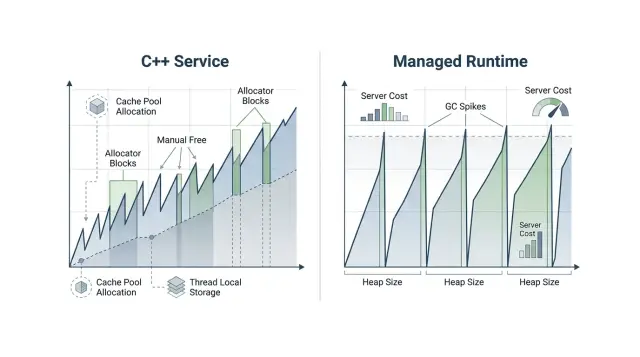
Профиль памяти — это временная шкала, а не одно число RAM. Если смотреть только на среднее потребление, можно не заметить именно тот рисунок, который и раздувает расходы. Этот рисунок показывает, выходит ли процесс на стабильный уровень или продолжает создавать давление по мере роста трафика.
Первое, что нужно проверить, — это рост кучи со временем. В здоровом сервисе память растет, выравнивается и остается в узком диапазоне. Если линия продолжает ползти вверх, у вас может быть утечка, слишком большой кэш или запросные объекты, которые живут дольше, чем вы думаете.
Частота выделений часто важнее, чем общий объем RAM. Два сервиса могут держаться на уровне 1,5 ГБ и при этом вести себя очень по-разному. Один может создавать небольшой набор объектов и переиспользовать их. Другой — каждую минуту создавать и выбрасывать миллионы краткоживущих объектов. Такой churn увеличивает нагрузку на CPU, сильнее давит на аллокатор или сборщик мусора и поднимает стоимость одного запроса.
Пиковая и стабильная память тоже рассказывают разные истории. Стабильная память влияет на обычные операционные расходы. Пик памяти определяет, за какой размер машины вам придется платить. Сервис, который в спокойном режиме держит 2 ГБ, но во время всплесков трафика подпрыгивает до 8 ГБ, может заставить взять заметно более крупный инстанс, даже если пик длится всего несколько секунд.
Паузы меняют пользовательский опыт еще до того, как средняя задержка покажет проблему. В управляемой среде выполнения паузы сборки мусора часто сначала видны в хвосте распределения, а не в среднем значении. На дашборде может быть все хорошо, а 99-й перцентиль при циклах очистки прыгнет с 40 мс до 300 мс. В системах с низкой задержкой это важнее среднего.
C++ не получает здесь автоматического преимущества. Он избегает пауз сборки мусора, но плохие шаблоны выделения все равно вредят. Частые мелкие выделения могут усиливать блокировки в аллокаторе, фрагментировать память и вызывать больше page fault. Профиль помогает понять, выигрывает ли C++ за счет хорошего переиспользования памяти, а не просто потому, что он не использует GC.
Еще важно отдельно смотреть на запуск и на длительную работу. Управляемые среды выполнения часто тратят первые минуты на прогрев кэшей, компиляцию горячих путей и расширение кучи. Долго работающие сервисы после этого могут выглядеть нормально. Но короткоживущие воркеры могут вообще не успеть выйти на стабильный режим. Честное сравнение C++ и управляемой среды выполнения по памяти должно рассматривать первую минуту и шестой час как два разных случая.
Когда вы читаете профиль именно так, вы перестаете спрашивать: «Сколько RAM он использует?» — и начинаете задавать более полезные вопросы. Как быстро он выделяет память, когда происходят пики и что случается с задержкой, когда память занята?
Где C++ вырывается вперед
C++ вырывается вперед, когда сервис создает огромное число краткоживущих объектов и почти сразу их отпускает. Разбор запросов, маршрутизация сообщений, прием телеметрии и scoring в реальном времени часто работают именно так. В этих случаях лишние выделения памяти — это не мелочь. Они напрямую меняют стоимость одного запроса.
Управляемая среда выполнения тоже может справиться с такой задачей, но ей все равно приходится платить за дополнительную метаинформацию об объектах, более тяжелые структуры указателей и паузы сборки мусора. C++ дает команде более жесткий контроль. Можно использовать пулы или arenas для временных данных, очищать их одним действием и сильно сократить нагрузку на аллокатор.
Не менее важны и фиксированные структуры данных. Плотный struct или плоский массив держит память в узких рамках и делает доступ проще. Граф из отдельных объектов в куче обычно занимает больше места и затрагивает больше строк кэша. Добавьте по 50 лишних байт к каждому живому элементу и умножьте это на 4 миллиона элементов — и вы получите примерно 200 МБ дополнительной памяти, еще до учета фрагментации.
Жесткие требования к задержке делают этот разрыв еще заметнее. Если сервис обязан держать p99 ниже 5 мс, редкая пауза все равно будет мешать. Средняя задержка может выглядеть нормально, а пользователи все равно будут замечать случайные медленные ответы. В системах с низкой задержкой обычно важнее хвост, чем среднее, и C++ дает больше контроля над этим хвостом.
Экономия растет, когда несколько воркеров делят один сервер. Если каждый воркер тратит лишние 150 МБ, то 24 воркера сжигают 3,6 ГБ только на накладные расходы памяти. Это может заставить брать инстанс большего размера или снизить плотность воркеров. В сравнениях C++ и памяти в управляемой среде выполнения именно здесь счет чаще всего начинает заметно меняться.
Долго живущие сервисы тоже чаще выигрывают от C++, если footprint нужно держать ровным неделями или месяцами. Хорошо спроектированный pool может выйти на стабильный уровень и оставаться на нем. Команды, которые строят экономную инфраструктуру, вроде того подхода, которого часто придерживается Oleg Sotnikov, особенно ценят это: более ровный footprint означает меньше сюрпризов, ниже облачные расходы и больше места на том же железе.
Когда управляемая среда выполнения все равно выигрывает
C++ заслуживает своего места, когда контроль над памятью реально меняет счет или задержку. Но многие команды не живут в таком мире каждый день. Если приложение в основном исполняет бизнес-правила, ходит в базу данных и держит потребление памяти предсказуемым, управляемая среда выполнения часто дает лучшую отдачу.
Это особенно типично для продуктов, где правила меняются каждую неделю. Pricing engine, админ-панель или partner API могут тратить больше времени на разбор запросов, проверку прав и вызовы других сервисов, чем на работу с аллокатором. В такой схеме короткая пауза сборки мусора может почти не влиять на опыт пользователя. Если запрос и так занимает 120 мс из-за сети и базы данных, случайная пауза в 15 мс редко оказывается тем, что люди замечают.
Управляемая среда выполнения часто выглядит разумнее, когда:
- рабочий набор остается небольшим даже на пике нагрузки
- целевая задержка измеряется десятками или сотнями миллисекунд
- команда выпускает новую логику каждые несколько дней
- ошибки безопасности памяти обошлись бы дороже, чем несколько лишних серверов
Скорость разработки часто важнее, чем показывают многие графики памяти. Хорошие инструменты профилирования, более безопасные настройки по умолчанию и более простая отладка могут экономить дни работы. Для маленьких команд это особенно важно. Одна труднонаходимая ошибка памяти в C++ может перечеркнуть месяцы экономии от более жесткого контроля выделений.
Есть и финансовая сторона, о которой часто забывают. Если инженеры могут менять сервис вдвое быстрее, быстрее чинить баги и без боли вводить новых людей в проект, общая стоимость одного запроса все равно может оказаться ниже в управляемой среде выполнения. Чистая эффективность по памяти — это только одна строка в счете.
Oleg Sotnikov часто работает с небольшими компаниями, которым сначала нужна быстрая поставка продукта, а уже потом — абсолютный контроль над памятью. На этом этапе спор о C++ и памяти в управляемой среде выполнения обычно имеет простой ответ: держите потребление памяти умеренным, измеряйте паузы сборки мусора под реальной нагрузкой и переходите на C++ только тогда, когда профиль показывает реальную потерю.
Как провести честный тест
Честное сравнение начинается с одинаковой работы. Дайте обеим версиям тот же набор данных, тот же микс запросов и тот же рисунок всплесков. Если один сервис получает мелкие payloads, а другой — более тяжелые запросы, результат ничего не скажет вам о C++ и памяти в управляемой среде выполнения.
Сначала проверьте корректность, а уже потом меряйте скорость. Обе версии должны возвращать одинаковые поля, одинаковые коды статуса и одинаковое поведение при ошибках. Команды часто сравнивают C++ сервис с меньшим количеством проверок и управляемую версию, которая все еще делает полный разбор, логирование и повторы. Это сравнение двух разных продуктов, а не двух моделей памяти.
Держите настройку строгой и скучной:
- Запускайте обе версии на одном и том же типе сервера с одинаковыми ограничениями CPU и памяти.
- Сначала прогрейте каждый сервис, чтобы стартовые действия не исказили результат.
- Записывайте число выделений, общий объем выделенной памяти и пиковый RSS.
- Отслеживайте p50, p95 и p99 задержки при обычной нагрузке и коротких всплесках трафика.
- Переводите результаты в стоимость на сервер и стоимость одного запроса.
Эти показатели памяти важнее, чем многие команды ожидают. Управляемая среда выполнения может показывать хорошую среднюю задержку и при этом выделять заметно больше памяти на один запрос, а это увеличивает работу сборщика мусора и требования к размеру сервера. C++ может выглядеть лишь немного быстрее по p50, но при этом экономить достаточно памяти, чтобы на той же машине разместить больше трафика.
Смотрите на стоимость просто. Если сервис A обрабатывает 8 000 запросов в секунду на одном сервере, а сервис B — 6 000, делите стоимость сервера на реально выданные запросы, а не только на время бенчмарка. Затем добавьте запас по памяти. Если одной версии нужен сервер большего размера, чтобы избежать пауз или свопинга, это меняет счет даже тогда, когда медианная задержка выглядит близкой.
Если в среде выполнения есть сборка мусора, фиксируйте время пауз рядом с перцентилями задержки. Короткая пауза может почти не влиять на p50, но достаточно сильно ударить по p99 и заставить добавить реплики. Именно так лишние выделения памяти превращаются в реальные деньги.
Простой пример на загруженном API
Представьте order API, который весь день принимает JSON-пакеты. Каждый запрос разбирает позиции заказа, проверяет цены, создает несколько внутренних объектов и записывает результат в очередь или базу данных. Эти данные не должны жить долго. Большая их часть существует несколько миллисекунд и затем исчезает.
Профиль памяти такого сервиса часто показывает один и тот же рисунок: много мелких выделений, высокая скорость запросов и почти никакого долгосрочного состояния. Приложение занято, но не прожорливо по памяти в обычном смысле. Оно постоянно создает краткоживущие объекты и просит аллокатор их убирать.
В управляемой среде выполнения это может работать хорошо, пока трафик остается высоким часами. Среда выполнения часто расширяет кучу, чтобы не останавливаться на очистку слишком часто. Такой компромисс имеет смысл, но он меняет стоимость. RSS растет, сборка мусора работает на более крупной куче, и каждому воркеру нужен больший запас. При низкой нагрузке задержка обычно остается нормальной, а потом p95 и p99 начинают плавать, когда очистка срабатывает в неудачный момент.
Версия этого же API на C++ может пойти другим путем. Вместо того чтобы выделять новую память для каждого разобранного поля, она может переиспользовать буферы чтения, держать arena на уровне запроса и сбрасывать ее в конце запроса. Код делает больше работы заранее, но аллокатору приходится гораздо меньше трудиться на горячем пути.
Разница быстро видна на реальной машине. Допустим, управляемый сервис стабилизируется примерно на 1,5–2 ГБ для нескольких загруженных воркеров, потому что держит лишнее место в куче про запас. C++-версия, которая обслуживает тот же трафик, может оставаться ниже 800 МБ, потому что переиспользует память вместо того, чтобы раздуваться вокруг churn. На сервере с 16 ГБ это может означать шесть воркеров вместо трех или место для еще одного сервиса без покупки более крупной машины.
Вот где C++ и память в управляемой среде выполнения перестают быть спором о стиле. Если профиль говорит: «целый день краткоживущие объекты», контроль над выделениями может снизить стоимость одного запроса так, что это уже увидит финансовая команда.
Числа, которые доказывают, что разница реальна
C++ и память в управляемой среде выполнения перестают быть теорией, когда вы измеряете один и тот же путь запроса под одинаковой нагрузкой, а потом считаете стоимость результата. Профилирование памяти обычно показывает разницу в пяти местах: лишние выделения, объем копирования, resident memory, поведение кэша и стоимость одного запроса.
Честный прогон на загруженном API может выглядеть так. Эндпоинт делает простую работу: разбирает JSON, валидирует поля, обращается к кэшу, формирует ответ и пишет логи. Бизнес-логика не меняется. Меняются только язык реализации и runtime.
- В версии на C++ один запрос может завершаться с 20–40 выделениями памяти. В управляемой версии того же сценария их может быть 300–600, потому что накапливаются временные строки, коллекции, обертки и объекты сериализатора.
- Копирование буферов часто рассказывает ту же историю. Если C++ переиспользует буферы и пишет на месте, он может копировать 80 КБ на запрос. Управляемый путь, который пересобирает строки и массивы, может перемещать 700 КБ и больше.
- Стабильный RSS важнее одного пика, но пики все равно стоят денег. Один сервис может держаться на уровне 600 МБ в C++ и 1,2 ГБ в управляемой среде выполнения, а затем подскакивать выше 2 ГБ во время пауз сборки мусора или всплесков трафика.
- Промахи кэша под нагрузкой превращают лишнюю память в задержку. Если C++-сервис держится примерно на 6% промахов last-level cache, а управляемый доходит до 15%, p99 обычно следует за этим.
- Счет — это то, с чем никто не спорит. Если более тяжелому runtime нужны еще два сервера по 8 ГБ, чтобы держать запас, это может добавить примерно $800–$1 500 в месяц. На 100 миллионах запросов это уже $8–$15 сверху на миллион запросов.
Эти числа особенно важны в системах с низкой задержкой, высоконагруженных API и задачах, которые работают весь день. Небольшое приложение с легким трафиком может никогда не окупить дополнительные инженерные усилия.
Oleg часто формулирует это практично: если поведение памяти заставляет вас покупать больше машин, терпеть более длинный хвост или раньше ограничивать трафик, выбор runtime уже изменил unit economics. Вот тогда разница реальна, а не академична.
Ошибки, которые искажают сравнение
Плохие сравнения обычно возникают из-за тестового стенда, а не из-за языка. Люди быстро запускают бенчмарк, смотрят на один график и решают, что C++ дешевле или что управляемая среда выполнения «достаточно быстрая». И то и другое может быть неверно.
Первая ловушка простая: одна сторона запускается в debug-сборке, а другая — в release. Это делает результат бесполезным. Debug-сборка C++ может выглядеть гораздо хуже, чем должна, а прогретая управляемая среда с полной оптимизацией — лучше, чем тот код, который вы реально отправите в продакшен. Тестируйте production-сборки обеих версий.
Еще одна частая ошибка — менять модель данных, делая вид, что вы поменяли только язык. Если версия на C++ использует плоские массивы и плотные struct, а управляемая версия — упакованные объекты, дополнительные обертки и другую стратегию кэша, вы сравниваете два дизайна. Это все еще может быть честным продуктовым тестом, но это не чистый тест языка.
С цифрами задержки тоже часто обращаются неправильно. Средняя задержка скрывает то, что видит пользователь. Если паузы сборки мусора затрагивают только 1% запросов, среднее значение может выглядеть нормально, а p99 — ужасно. В системах с низкой задержкой важнее именно всплеск, а не среднее.
Тесты тоже часто заканчиваются слишком рано. Управляемым средам выполнения нужно время на прогрев, рост кучи и циклы сборки мусора. C++-сервисам тоже нужно время, чтобы кэши аллокатора, пулы соединений и шаблоны запросов стабилизировались. Если остановиться через несколько минут, можно измерить поведение на старте вместо реальной стоимости одного запроса.
Честное сравнение C++ и памяти в управляемой среде выполнения держит под контролем следующее:
- одна и та же нагрузка и один и тот же микс запросов
- по возможности одинаковые структуры данных
- одинаковый уровень оптимизации в финальных сборках
- достаточно времени работы, чтобы память вышла на стабильный режим
- p95 и p99 задержки, а не только среднее
Есть еще одна ошибка: делать вид, что инженерные затраты не существуют. C++ может снизить потребление памяти и убрать паузы сборки мусора, но тогда команда берет на себя ошибки жизненного цикла, выбор аллокатора и более сложные режимы отказа. Если переписывание экономит 30% RAM, но требует недель тонкой настройки и усложняет дежурства, дешевая на бумаге среда выполнения может обойтись дороже на практике.
Краткий чек-лист перед выбором
Профиль памяти может уберечь вас от очень дорогой догадки. Во многих командах CPU выглядит нормально, а рост памяти, лишние выделения и паузы сборки мусора поднимают расходы задолго до того, как процессоры становятся узким местом.
Если вы выбираете между C++ и памятью в управляемой среде выполнения, спросите себя, что ломается первым под реальной нагрузкой. Этот ответ обычно важнее, чем личные предпочтения по языку.
- Сервис упирается в память раньше, чем в CPU? Если память заканчивается первой, более жесткий контроль над выделениями позволит упаковать больше работы в каждый воркер.
- Короткие паузы ломают целевую задержку? Для batch-задачи пауза может быть неважна. Для request path с бюджетом в 50 мс она может испортить хвост.
- Снизят ли меньшие воркеры стоимость хостинга заметно? Если уменьшение каждого инстанса с 2 ГБ до 512 МБ быстро меняет счет, когда у вас десятки или сотни таких экземпляров.
- Может ли команда без риска работать с правилами владения? C++ действительно может уменьшить waste, но только если код пишется и ревьюится аккуратно.
- Можно ли вынести горячий путь в небольшой C++-компонент, а остальное оставить на управляемом языке? Часто это самый практичный компромисс.
Простой пример помогает сориентироваться. Допустим, API большую часть времени тратит на разбор payloads, создание краткоживущих объектов и сериализацию ответов. Если управляемой версии нужны более крупные кучи, чтобы удержать паузы в рамках, каждый воркер может обходиться дороже. Небольшой C++-парсер или core для обработки запросов может сократить потребление памяти настолько, что на том же железе уместится больше воркеров.
Реальность команды важна не меньше, чем цифры бенчмарков. Если ваши инженеры редко работают с ручным управлением временем жизни объектов, дополнительный контроль может не окупиться. Если один эндпоинт формирует большую часть счета, точечное нативное переписывание часто лучше полного.
Именно к такому решению Oleg Sotnikov часто подталкивает команды в AI-first и startup-проектах: измерьте горячий путь, измените то, что действительно сжигает деньги, и не трогайте остальное.
Что делать дальше
Проведите еще одно измерение, когда трафик на пике, а не когда система спокойна. Профиль памяти, снятый в 14:00 в тихий день, может скрыть те самые всплески, из-за которых растет облачный счет или хвостовая задержка выходит за пределы лимита. Если можете, воспроизведите реальный производственный рисунок с рывками, прогретыми кэшами и тем же миксом запросов, который создают пользователи.
Не бросайтесь сразу в переписывание. Гибридная схема часто дает большую часть эффекта при гораздо меньшем риске. Оставьте control plane, админские сценарии или более медленную бизнес-логику в управляемой среде выполнения, а в C++ перенесите только горячий путь: разбор, сериализацию, matching, сжатие или любой цикл, который создает слишком много краткоживущих объектов.
Прежде чем менять язык, внимательно посмотрите на стратегию аллокатора и время жизни объектов. Многие команды винят runtime, хотя настоящая проблема — churn из-за мелких выделений, плохого pooling или объектов, которые живут на цикл дольше, чем нужно. В C++ это значит проверить arenas, пулы и правила владения. В управляемой среде выполнения — проверить скорость продвижения объектов, рост кучи и то, что удерживает объекты в памяти.
Практичный порядок действий такой:
- повторите бенчмарк на пиковом трафике
- изучите горячие точки выделения памяти, а не только время CPU
- попробуйте узкий гибридный шаг вместо полного переписывания
- сравните стоимость одного запроса после изменений, а не только сырой speed
Если ответ все еще выглядит неясным, позовите человека со стороны. Свежий архитектурный обзор часто замечает то, что внутренняя команда уже перестала замечать, потому что считает это нормой. Особенно это верно, когда оба варианта по отдельности выглядят «достаточно хорошими», но на масштабе создают очень разные расходы.
Именно такой разбор Oleg Sotnikov делает для startup и SMB-команд. Он может посмотреть на данные профилирования, системный дизайн и unit economics одновременно, а затем сказать, что логичнее: C++, управляемая среда выполнения или смешанный подход. Обычно это дешевле, чем месяцами ставить не на ту переписку.
Выберите один сервис, измерьте его честно и идите за тем, куда указывает профиль памяти. Обычно цифры довольно быстро снимают спор.


