ConnectRPC vs gRPC-web vs REST для браузерных клиентов
Сравнение ConnectRPC, gRPC-web и REST помогает командам выбрать путь для браузерного API, оценивая proxy-настройку, поддержку инструментов, обработку ошибок и компромиссы backend-а.
Содержание
Почему browser API быстро становятся запутанными
Браузеры выглядят как обычные клиенты, но у них более строгие сетевые правила. Backend-сервисы могут общаться друг с другом через native gRPC по HTTP/2. Браузеры обычно не могут. Именно на этом разрыве и начинает иметь значение выбор подхода.
Один backend часто должен обслуживать web-приложение, mobile-приложение, внутренние инструменты и иногда партнёрские интеграции. Каждый клиент хочет понятный контракт, но у каждого свои ожидания по payloads, auth, caching и сообщениям об ошибках.
Typed clients помогают. Автодополнение ловит лишние ошибки, а общие схемы держат команды в одном ритме. Но многим командам не нужен дополнительный proxy или слой преобразования только ради поддержки браузера. То, что выглядит элегантно на схеме, в реальности превращается в большее число настроек, более сложную локальную отладку и больше мест, где могут сломаться headers или cookies.
Небольшие различия в протоколах влияют и на повседневную работу. Если запрос не прошёл, сможет ли frontend-разработчик прочитать его в network tab? Если ответ нужно кешировать, поймут ли его обычные web-инструменты? Если вы добавите одно поле, примут ли его все клиенты без изменений на gateway?
В первый день это редко кажется срочным. Срочно становится тогда, когда один backend должен одновременно поддерживать web, mobile и внешних пользователей. Протокол влияет не только на производительность. Он влияет и на то, насколько легко систему проверять, тестировать и менять.
Что означает каждый вариант
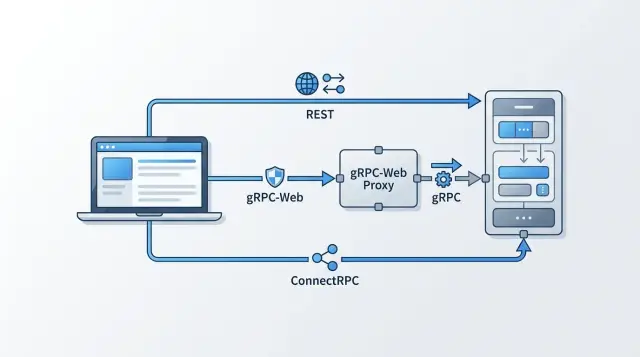
Для browser client разница довольно проста: как frontend отправляет запросы, что именно идёт по сети и сколько настроек должна поддерживать команда.
REST использует стандартные HTTP-маршруты вроде GET /users/42 или POST /orders, обычно с JSON. Большинство разработчиков и так умеют смотреть такие запросы, мокать их и объяснять их не-техническим коллегам.
gRPC-web сохраняет RPC-модель. Клиент вызывает методы сервиса вместо ручного построения маршрутов, и это хорошо подходит, если backend уже опирается на protobuf-схемы и сгенерированные клиенты. Компромисс в том, что браузер не может говорить на обычном gRPC напрямую, поэтому gRPC-web зависит от адаптации, совместимой с браузером.
ConnectRPC тоже сохраняет RPC-модель, но намного лучше ложится на обычный web-transport. Браузер может вызывать методы по обычному HTTP, не притворяясь полноценным gRPC-клиентом. На практике это часто означает меньше трения для web-приложений при той же структуре, которая нравится командам в RPC API.
Представьте превью счёта. REST может вызвать /api/invoices/123/preview и вернуть JSON. gRPC-web может вызвать InvoiceService.GetPreview с типами protobuf, сгенерированными заранее. ConnectRPC может использовать ту же форму метода, но поверх транспорта, который в браузере ощущается естественнее.
Эти подходы не исключают друг друга. Один backend может поддерживать больше одного, если команда закладывает это заранее. Публичный API может остаться REST, потому что партнёры ожидают JSON, а внутренняя dashboard-команда компании использует ConnectRPC для typed calls и общих схем.
Где важен proxy
Требования к proxy часто решают этот выбор быстрее, чем подробности протокола.
У REST обычно самый короткий путь. Если CORS, cookies, headers и TLS настроены правильно, браузер может вызывать endpoint по обычному HTTP, а пограничный слой в основном просто проксирует трафик.
gRPC-web часто добавляет ещё один слой. Поскольку браузеры не говорят на native gRPC так же, как backend-сервисы, команды обычно ставят Envoy или похожий proxy перед приложением. Он преобразует запросы и ответы в то, с чем браузер умеет работать.
ConnectRPC находится посередине. Он работает в формате, удобном для браузера, поверх HTTP/1.1 или HTTP/2, поэтому командам часто не нужен отдельный слой преобразования gRPC-web только ради того, чтобы использовать RPC во frontend. Reverse proxy для TLS termination, проверок auth, rate limits или маршрутизации всё равно может остаться. Разница проще: с REST и часто с ConnectRPC edge-слой может вести себя как обычный web proxy. С gRPC-web ему, возможно, ещё придётся мостить детали протокола.
Этот дополнительный мост — это реальная работа. Кому-то нужно писать конфигурацию, обновлять сертификаты, читать логи, разбирать проблемы с headers и следить, чтобы деплойменты были синхронны. Когда запросы ломаются, команда теперь проверяет браузерные инструменты, логи приложения и логи proxy, а не просто два места.
Вот почему важна лёгкая инфраструктура. Oleg Sotnikov часто разбирает такие компромиссы в своей Fractional CTO работе на oleg.is: убирает слои, которые добавляют операционные расходы, но мало что дают продукту.
Полезный прямой вопрос такой: хотите ли вы, чтобы browser client зависел от протокольного моста? Если нет, REST и ConnectRPC обычно сокращают путь. Если Envoy у вас уже есть по другим причинам и команда хорошо его знает, gRPC-web всё ещё может подойти.
Как инструменты ощущаются каждый день
Большинство команд застревают не на теории протоколов. Они застревают на повторяющихся задачах: протестировать endpoint, прочитать ошибку, замокать ответ и помочь новому коллеге запустить приложение.
REST по-прежнему остаётся самым простым вариантом для разовых задач. Его можно вызвать через curl, посмотреть в DevTools, вставить JSON в mock server и идти дальше. Его же проще объяснить QA, product или support, когда им нужно проверить один запрос.
gRPC-web сразу ощущается тяжелее. Он лучше всего работает там, где команда уверенно пользуется generated clients, protobuf-файлами и более строгим рабочим процессом. Это может быть хорошим компромиссом, если protobuf уже определяет backend, но для простого browser debugging он менее удобен. Frontend-разработчик не может просто ввести URL, отправить JSON и разобраться, что происходит.
ConnectRPC даёт полезную середину. У вас остаются protobuf-контракты и typed clients, но браузерный опыт ближе к обычным web-вызовам. Запросы проще анализировать, а инструменты кажутся менее чужими разработчикам, которые в основном работают с web-приложениями.
Небольшие команды обычно замечают разницу в обычных задачах. Можно ли проверить один endpoint, не запуская всё приложение? Можно ли прочитать запрос в DevTools, не декодируя что-то незнакомое? Можно ли создать локальные mocks для работы над UI и обновить generated code одной повторяемой командой? Поймёт ли новый сотрудник настройку за один день?
Привычки команды важнее моды. Если backend-команда уже живёт в protobuf и generation, gRPC-web или ConnectRPC могут казаться естественными. Если frontend-команда опирается на ручной просмотр, быстрые mocks и лёгкую отладку, REST обычно помогает двигаться быстрее.
Смешанные стили API тоже работают, но бесплатно они не даются. Документация расползается, примеры расходятся, а онбординг занимает больше времени, потому что новым разработчикам приходится изучать и транспорт, и внутренние правила команды. Один backend может поддерживать больше одного стиля, особенно в компактном Go и TypeScript-стеке, но каждый дополнительный стиль добавляет ещё одну mental model. Обычно эта цена видна не в первый день, а на второй неделе.
Как ошибки попадают в браузер
Именно на обработке ошибок многие browser API становятся запутанными.
REST по умолчанию самый неровный. Один endpoint возвращает { "error": "invalid email" }, другой отправляет { "message": "unauthorized" }, а третий отвечает plain text и 500. REST может быть аккуратным, но только если команда определит единый формат ошибок и будет строго его придерживаться.
gRPC-web на бумаге более единообразен. Он использует gRPC status codes вроде invalid_argument, unauthenticated и resource_exhausted, а дополнительные детали может передавать в trailers. Между сервисами это работает хорошо, но браузеру не всегда удобно показывать детали из trailers. Frontend-команды часто пишут адаптеры только для того, чтобы превратить детали транспорта в простые сообщения для интерфейса.
ConnectRPC сохраняет RPC-модель, но отправляет ошибки в форме, с которой browser client работает проще. У вас по-прежнему есть status codes и машинно-читаемые детали, но опыт ближе к обычной web-работе. Это особенно важно, когда одна команда отвечает и за backend, и за frontend.
Когда все endpoint-ы падают в одном и том же формате, код браузера становится гораздо меньше. Один helper может превращать ответы сервера в ошибки полей, редиректы на login, сообщения о повторной попытке и support-логи. Без этого каждая страница начинает жить со своим набором исключений.
Перед запуском проверяйте реальные ошибки, а не только успешные сценарии. Попробуйте форму с несколькими ошибками валидации. Дайте сессии истечь. Упритесь в rate limit. Создайте конфликт, когда два пользователя редактируют одну запись. Спровоцируйте внутреннюю ошибку и убедитесь, что пользователь видит безопасное сообщение и request ID.
Разница быстро становится очевидной. Если регистрация, биллинг и обновление профиля возвращают ошибки в одном общем формате, UI может обрабатывать их одинаково везде. Если каждый endpoint говорит на своём диалекте, frontend превращается в glue code.
Простой способ выбрать
Смотрите на клиентов, которые появятся в ближайший год, а не только на тех, что уже есть. Dashboard только для браузера — это один выбор, а продукт, который скоро добавит mobile apps, партнёрские интеграции и внутренние сервисы, — совсем другой.
Для многих команд лучший старт — это тот вариант, который лучше всего ложится на текущий stack и не требует лишней механики. Если в вашей среде уже комфортно живёт proxy, gRPC-web будет менее болезненным. Если такого слоя у вас ещё нет, добавлять его только ради браузерного трафика часто ощущается как сантехника, за которой потом придётся постоянно присматривать.
Генерация кода — ещё один честный фильтр. Некоторым командам нравятся строгие generated clients, потому что они раньше ловят ошибки. Другие быстро устают, как только в workflow появляются дополнительные build steps, generated files в review и настройка редактора. Если у команды мало терпения к этому, REST обычно ощущается легче. Если же вам нужны typed contracts без лишнего трения в браузере, ConnectRPC часто становится лучшей серединой.
Практическое правило может быть таким:
- Выбирайте REST, когда важнее всего лёгкая отладка, минимальная настройка и привычность для браузера.
- Выбирайте ConnectRPC, когда нужны typed RPC-вызовы в браузере без того, чтобы proxy-настройка стала центром проекта.
- Выбирайте gRPC-web, когда у вас уже есть gRPC за proxy и команда довольна protobuf-first workflow.
Не принимайте решение только по документации. Сначала соберите один реальный endpoint. Пусть он делает что-то обычное: создаёт аккаунт, получает данные dashboard или отправляет форму с ошибками валидации. Потом проверьте, как браузер получает успех, ошибки авторизации и ошибки по полям.
Этот тест ошибок важнее, чем многие ожидают. Сразу выберите один общий формат ошибок и сделайте его скучным. Браузер должен каждый раз понимать, где искать сообщение, код и ошибки по полям. Если такой контракт уже кажется неудобным на первом endpoint-е, после пятидесятого он станет только хуже.
Много переделок появляется из-за того, что стандарт пытаются зафиксировать слишком рано. Соберите один реальный поток, посмотрите, где frontend путается, а потом уже фиксируйте решение.
Реальный пример на одном backend
Типичный SaaS-сценарий: один backend, три типа клиентов и три набора ожиданий.
Customer-facing React dashboard хочет typed requests, быстрые ответы и ошибки, которые выглядят одинаково на каждом экране. Внутренний admin tool хочет почти того же, потому что команде, которая обрабатывает refunds, изменения аккаунтов или support tickets, тоже нужны предсказуемые ответы. Партнёрские команды обычно хотят что-то проще: обычный JSON, который можно быстро проверить в Postman или небольшим скриптом.
Представьте backend, который в одном codebase обслуживает billing, настройки аккаунта, usage reports и user management. Команде не нужны отдельные сервисы только ради того, чтобы угодить разным клиентам. Это обычно создаёт дублирование auth-правил, повторяющуюся валидацию и больше мест, где прячутся баги.
Практичное разделение часто выглядит так: ConnectRPC для React dashboard, ConnectRPC для внутреннего admin tool и REST для партнёрского доступа.
Так web-приложения получают generated types и более чистый client code. Если запрос не проходит, frontend видит стабильный формат ошибки вместо того, чтобы гадать, вернул ли сервер строку, JSON-объект или мало полезный status code. Ошибка платежа, истёкшая сессия и ошибка валидации должны запускать правильное сообщение в интерфейсе без custom parsing в пяти разных местах.
Партнёров волнуют другие вещи. Они часто тестируют API до того, как решат его использовать, и REST делает это просто. Можно отправить JSON, посмотреть ответ и двигаться дальше. Для внешнего доступа простота часто побеждает.
Именно поэтому многие команды оставляют REST для внешних потребителей и используют ConnectRPC для browser apps. При этом под капотом у них по-прежнему одна и та же бизнес-логика. Сервер один раз проверяет auth, валидирует одни и те же поля и вызывает одни и те же сервисы. Меняется только транспорт.
gRPC-web тоже может подойти, в основном если у команды уже есть proxy и protobuf-heavy setup. Если Envoy уже входит в stack и всем привычны protobuf tools, добавление gRPC-web может казаться естественным. Если нет, он часто добавляет ещё одну движущуюся часть, не решая проблему, с которой уже справились бы ConnectRPC или REST.
Итог простой: один backend, один набор правил и API-стили, подобранные под людей, которые ими пользуются.
Ошибки, из-за которых потом приходится переделывать
Команды часто воспринимают это как мелкую деталь клиента. На деле это обычно влияет на deployment, frontend-код и работу support месяцами.
Одна частая ошибка — сначала выбрать gRPC-web, а позже понять, что кому-то всё равно нужно поддерживать proxy-слой. Звучит несложно, пока proxy не начинает трогать каждый релиз. Если никто не владеет Envoy, nginx или другим gateway, проблемы с конфигурацией быстро накапливаются. Команда может тратить больше времени на заголовки, маршрутизацию и локальную настройку, чем на выпуск фич.
Другая ошибка — когда REST и RPC-endpoint-ы сообщают о сбоях совершенно по-разному. Один маршрут отправляет plain JSON с HTTP status codes. Другой возвращает gRPC-style error object. Тогда browser app нужно отдельное поведение для ошибок авторизации, ошибок форм, повторных попыток и toast-сообщений. Эта работа расползается по коду.
Поддержка браузера создаёт похожие сюрпризы. Поддержка gRPC на backend не означает поддержку браузера. Браузер думает о fetch, CORS, auth headers, cookies и поведении timeout-ов. Команды часто доказывают, что backend работает, с помощью серверных инструментов, а реальные проблемы всплывают только когда они запускают настоящий browser flow.
Генерация кода создаёт более медленную, но не менее неприятную переделку. Если никто не знает, как регенерировать clients, этим перестают заниматься. Вскоре frontend работает со старыми типами, кто-то вручную правит generated files, и каждое API-изменение кажется больше, чем есть на самом деле.
Пара проверок предотвращает большую часть проблем. Назначьте владельца proxy до выбора gRPC-web. Держите error shapes и названия полей близкими между REST и RPC. Проверяйте запросы в реальном браузере рано, а не только через backend tools. Вместе проверяйте CORS, auth headers, cookies и timeout-ы. И сделайте так, чтобы генерация clients запускалась одной повторяемой командой, доступной всей команде.
Небольшие команды чувствуют эти ошибки первыми. Один лишний proxy, один странный формат ошибки или один хрупкий шаг генерации кода могут превратить простой backend в ежедневную нагрузку.
Короткие проверки перед окончательным решением
Неподходящий browser path дорогим становится медленно. Неделя на настройку может превратиться в месяцы мелких обходных решений, если каждому новому экрану нужна особая обработка.
Прежде чем остановиться на подходе, ответьте на несколько простых вопросов. Может ли браузер обращаться к сервису напрямую, или вам нужен proxy, который кто-то должен разворачивать, мониторить и отлаживать? Когда запрос ломается, сможет ли разработчик открыть DevTools и разобраться менее чем за минуту? Может ли один backend вернуть формат, который нужен каждому клиенту, без разнесения одной и той же бизнес-логики по нескольким сервисам? Если в следующем месяце вы добавите поле, смогут ли старые экраны безопасно его игнорировать? Сможет ли support-сотрудник прочитать распространённые сообщения об ошибках и подсказать пользователю следующий шаг?
Если два варианта всё ещё кажутся равными, выбирайте тот, при котором сбои будут скучными. Люди могут жить с ошибкой. Им тяжело жить с сообщением «что-то пошло не так» без понимания почему.
Простой пример это хорошо показывает. Допустим, один backend обслуживает внутренний admin screen, публичное web-приложение и mobile app. REST часто кажется самым простым в первый день, потому что его понимают все браузерные инструменты. ConnectRPC часто оказывается посередине, когда нужны typed RPC-вызовы в браузере без отдельного gRPC-web proxy. gRPC-web тоже может хорошо работать, но маленькой команде стоит спросить, окупается ли этот дополнительный элемент.
Изменения полей наносят больше вреда, чем ожидают команды. Добавляйте новые поля так, чтобы старые экраны могли их игнорировать, держите error shapes стабильными и пишите короткие support notes простым языком. Если support может сопоставить code ошибки с действием пользователя, он решает больше случаев без привлечения инженера в каждый тикет.
Что делать дальше
Для этого решения не нужен rewrite. Начните с одного browser-facing endpoint, который уже важен: данные аккаунта, результаты поиска или summary dashboard. Оставьте backend прежним и сначала выпустите этот endpoint в одном стиле. Добавляйте второй стиль только если команде всё ещё нужны доказательства из реального кода, а не мнения.
Такой небольшой тест расскажет больше, чем длинный спор. Одного endpoint-а достаточно, чтобы увидеть, где на самом деле возникает трение. Это будет видно в setup сборки, поведении браузера и форме client code.
Пока тестируете, отслеживайте несколько конкретных вещей: сколько proxy-работы пришлось добавить или поддерживать, насколько читаемым остался browser client code, насколько легко было понимать ошибки в UI и логах, и сколько custom mapping понадобилось frontend-у для retries и сообщений.
Цифры помогают. Если один вариант добавляет 20 минут к каждому локальному запуску, это реальная цена. Если другой даёт более чистые ошибки, но требует дополнительный proxy в каждой среде, тоже запишите это.
После теста выберите default и зафиксируйте его простым языком. Например: используйте REST для публичных browser APIs, используйте ConnectRPC для typed внутренних web-приложений, а gRPC-web оставьте только для случаев, когда текущий stack уже на нём завязан. Формулировка может отличаться, но новые сервисы должны ей следовать, если нет ясной причины не делать этого.
Один такой письменный default предотвращает тихий хаос. Без него каждый новый сервис начинает жить по своему паттерну, со своей формой ошибок и своими заметками по настройке. Команды обычно чувствуют это торможение спустя месяцы.
Если команда всё ещё разделилась, короткий внешний review может сэкономить много переделок. Oleg Sotnikov на oleg.is помогает стартапам и небольшим компаниям с backend architecture, infrastructure и AI-first workflows разработки, и такой выбор browser API действительно стоит закрыть заранее.
Часто задаваемые вопросы
Что выбрать первым для браузерного приложения?
Начните с REST, если вам нужна самая простая настройка и самая понятная отладка в браузере. Выберите ConnectRPC, если хотите typed RPC-вызовы в браузере без отдельного слоя преобразования. К gRPC-web стоит идти только тогда, когда у вас уже есть proxy вроде Envoy и команда уверенно работает с protobuf и сгенерированными клиентами.
Может ли браузер напрямую вызывать native gRPC?
Нет. Браузеры не говорят на native gRPC так же, как backend-сервисы. Поэтому для фронтенда используют REST, ConnectRPC или gRPC-web bridge.
Когда мне нужен proxy или слой преобразования?
REST обычно работает через обычный reverse proxy, если правильно настроены CORS, TLS и auth. ConnectRPC часто работает так же. gRPC-web обычно нужен proxy, который преобразует запросы и ответы для браузера.
ConnectRPC проще в использовании, чем gRPC-web?
Для многих команд — да. Он сохраняет RPC-модель и typed clients, но браузерный трафик ощущается ближе к обычным web-запросам. Из-за этого локальная настройка, просмотр запросов и отладка часто проще, чем у gRPC-web.
Почему многие команды всё ещё используют REST для публичных API?
Потому что REST остаётся простым для партнёров, QA и frontend-разработчиков: можно отправить JSON, прочитать ответ в DevTools и проверить маршрут обычными инструментами. Для публичных API это часто важнее, чем строгие RPC-вызовы методов.
Как лучше обрабатывать ошибки API в браузере?
Задайте один формат ошибок заранее и используйте его везде. Каждый ответ должен подсказывать браузеру, где искать сообщение, код и возможные ошибки по полям. Если формат стабилен, frontend намного проще обрабатывает ошибки авторизации, валидации и повторные попытки.
Можно ли одному backend-у отдавать и REST, и ConnectRPC?
Да, и многие команды так и делают. Частый вариант — ConnectRPC для внутренних web-приложений и REST для партнёров или внешнего доступа. Главное — оставить один набор бизнес-правил под капотом, чтобы не дублировать auth, валидацию и логику сервисов.
Генерация кода помогает или просто добавляет лишнюю работу?
Может помочь. Сгенерированные клиенты раньше находят ошибки, но добавляют команды, сгенерированные файлы и настройку редактора. Если команда перестаёт обновлять клиентов или начинает править сгенерированный код вручную, процесс быстро становится обузой.
Что стоит протестировать, прежде чем выбрать один подход?
Соберите один реальный browser flow и проверьте не только удачный сценарий. Посмотрите, что будет при истечении логина, ошибках валидации, лимитах, CORS, cookies, auth headers и как запрос выглядит в DevTools. Такой тест быстрее показывает, где именно возникает трение, чем долгий спор.
Когда gRPC-web всё ещё имеет смысл?
Лучше всего он подходит тогда, когда у вас уже есть gRPC за proxy и protobuf уже используется по всему стеку. В такой схеме gRPC-web может расширить тот же сервисный подход до браузера, не заставляя команду менять стиль API. Если proxy-слоя у вас ещё нет, лишняя деталь часто стоит дороже, чем даёт пользы.


