Cloudflare tunnels против публичного ingress для внутренних приложений
Cloudflare tunnels против public ingress для внутренних приложений: сравните уровень открытости, аудит логов, нагрузку на поддержку и удобство, прежде чем выставлять ещё один админский инструмент в интернет.
Содержание
Почему этот выбор важен для внутренних приложений
Внутренние приложения редко выглядят эффектно, но часто управляют самыми болезненными частями бизнеса. Админ-панель может менять цены, одобрять возвраты, смотреть данные клиентов, сбрасывать пароли или запускать деплой. Ошибка в таком месте наносит гораздо больше вреда, чем сломанная маркетинговая страница.
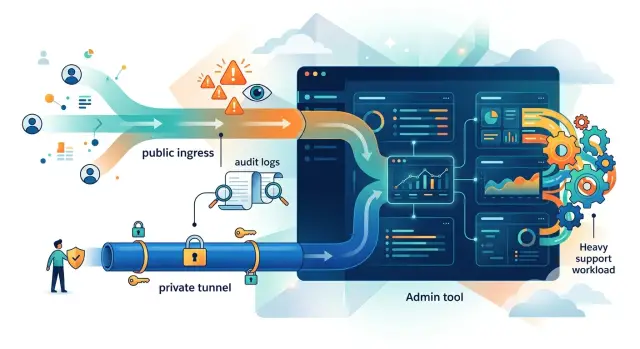
Именно поэтому важен путь доступа. Когда вы сравниваете Cloudflare tunnels и public ingress, вы выбираете не просто сетевую схему. Вы решаете, кто вообще увидит приложение, сколько лишнего трафика до него доберётся и сколько уборки команде придётся делать потом.
Разница быстро становится заметной, если внутренний экран оказывается в открытом интернете. Боты весь день ищут доступные админские маршруты. Они пробуют распространённые имена пользователей, слабые пароли, старые пути и устаревшие закладки. Даже если внутрь никто не попадает, логи забиваются мусором, оповещения становятся шумнее, а реальные проблемы сложнее заметить.
Приватный путь доступа убирает большую часть этого шума ещё до того, как он появится. Если посторонние не могут дойти до страницы входа, они не смогут её атаковать, скрапить или бесконечно проверять. Это убирает много мелких проблем ещё до того, как они станут тикетами в поддержку.
Удалённая работа делает этот выбор ещё практичнее. Сотрудники переключаются между сетями, ездят в поездки, забывают шаги VPN, теряют сохранённые настройки и просят помочь за пять минут до релиза. Если доступ кажется хрупким, нагрузка на поддержку растёт каждую неделю.
Обычно повторяется один и тот же плохой сценарий. Люди не могут открыть приложение из дома или в дороге, админы ослабляют правила, чтобы просто всё заработало, и в итоге приложение становится и легче атаковать, и сложнее поддерживать. Более удачная схема делает приложение труднее найти, проще открыть нужным людям и удобнее проверять позже. Для внутренних инструментов этот баланс важнее, чем для большинства публичных страниц, потому что внутри находятся рычаги, которые влияют на деньги, данные и доступ.
Что меняется при public ingress
Как только вы размещаете внутреннее приложение на публичном DNS-имени и открываете порт, в него начинает стучаться случайный трафик. Часть этого трафика — безобидное сканирование. Часть пытается старые пароли, известные пути или типовые admin-адреса. Даже маленький инструмент с десятью пользователями замечают, потому что боты ищут весь интернет, а не только известные сайты.
WAF и rate limits всё равно полезны. Их нужно использовать. Но они не делают приложение снова приватным. Страница входа, поток сессии и обработка ошибок всё равно остаются открыты для интернета. Одно слабое правило, один пропущенный патч или один шумный endpoint могут привлечь внимание откуда угодно.
Работа поддержки меняется почти сразу. Когда сотрудник говорит: «Я не могу войти», команде нужно отделять реальную проблему пользователя от фонового шума. Заблокированные аккаунты, срабатывания rate limit, странные IP-адреса и ложные оповещения начинают смешиваться. Простая проблема доступа решается дольше, потому что в логах слишком много трафика, не связанного с вашими сотрудниками.
Больше всего лишней работы создают страницы входа. Кто-то должен следить за всплесками неудачных логинов, повторными попытками пароля и доступом в нерабочее время. Кто-то ещё должен решать, указывает ли оповещение на атаку, сломанный клиент или пользователя, который десять раз подряд ввёл один и тот же пароль. Для небольшой команды эта фоновая работа быстро накапливается.
Небольшая админ-панель — хороший пример. В приватной сети support в основном помогает с реальными проблемами сотрудников. При public ingress та же панель может получать сканы в 3 часа ночи, попытки входа из неизвестных регионов и шум в оповещениях, который забивает обычные тикеты. В этом часто и скрыта цена. Приложение может продолжать работать нормально, но команда начинает тратить больше времени на наблюдение, фильтрацию и объяснения, чем раньше.
Что меняется при использовании tunnel
Tunnel блокирует прямой интернет-трафик к origin приложения. Сервер не открывает публичный порт для инструмента, поэтому случайные сканы и фоновая проверка до него не добираются. Это сразу снижает случайную открытость, поэтому многие команды предпочитают tunnel для админских панелей, дашбордов и других внутренних инструментов.
Но это не делает приложение безопасным автоматически. Людям всё равно нужна нормальная проверка личности, прежде чем они попадут внутрь. Если поставить слабый логин перед внутренним инструментом, tunnel просто прячет входную дверь от улицы. Он не исправляет плохой контроль доступа, отсутствие MFA или слишком широкие общие аккаунты.
Именно в этом главный сдвиг в решении Cloudflare tunnels vs public ingress. Вместо публичной сетевой границы вы получаете приватный origin плюс identity-gate. Для многих команд это более удачная базовая схема, потому что посторонние не могут подключиться к серверу напрямую, даже если угадают hostname или найдут старую заметку с названием приложения.
Но есть и операционный компромисс. Внутри вашей среды работает tunnel agent, и этот агент становится ещё одной службой, за которой нужно следить. Его надо обновлять, перезапускать, если он завис, и проверять, заметил ли кто-то, когда он упал.
Команды часто забывают об этом, потому что само приложение при этом выглядит здоровым.
Из этого вырастает частый сценарий отказа. Приложение работает, база работает, и локальные пользователи внутри сети всё ещё могут его открыть. А удалённый доступ ломается, потому что connector tunnel перестал работать. В support накапливаются тикеты, потому что пользователи видят только один симптом: «Я не могу открыть инструмент».
Возьмём приложение для согласования финансовых операций. С tunnel сервер остаётся вне публичного интернета, а сотрудники входят через identity provider компании с MFA. Это сильный шаг. Но если tunnel agent падает после системного обновления, финансовая команда теряет удалённый доступ, хотя само приложение продолжает работать нормально.
Tunnel снижает внешнюю открытость, но добавляет зависимость. Относитесь к этой зависимости как к части приложения, а не как к чему-то невидимому и дополнительному.
Сравнивайте радиус ущерба до того, как сравнивать время настройки
Начинайте не с настройки, а с возможного ущерба. Команды часто в первую очередь смотрят на скорость и удобство. Но лучший вопрос проще: если одна сессия будет украдена, что именно сможет сделать этот человек, пока это не заметят?
Этот вопрос меняет дизайн. Дашборд только для чтения, который показывает отчёты, имеет гораздо меньший радиус ущерба, чем админ-панель, которая может удалять данные, менять секреты или править настройки продакшена. Если инструмент может менять живые системы, относитесь к нему как к панели управления, а не как к обычному внутреннему приложению.
Public ingress повышает ставки, потому что страница входа и поверхность приложения находятся на виду. Tunnel снижает открытость, но не делает плохую сессию безвредной. Если атакующий попадает в браузерную сессию с широкими правами, способ входа уже менее важен, чем те права, которые он получает.
Посмотрите внимательно, что находится за первым успешным логином. Проблемы быстро растут, если инструмент использует общие аккаунты, показывает сохранённые API-ключи или креды базы данных в интерфейсе, даёт одной админ-роле гораздо больше власти, чем требуется для одной задачи, или позволяет запускать действия в продакшене одним кликом без дополнительной проверки.
Права только на чтение и права на изменение не должны находиться за одной и той же слабой дверью. Разделяйте инструменты, которые только показывают данные, и те, которые меняют состояние. Многие команды пропускают этот шаг, потому что одна общая админ-панель кажется удобнее, но из-за неё любая проблема с support или утечка сессии превращается в более серьёзный инцидент.
Самые жёсткие проверки должны стоять перед экранами, которые причиняют больше всего вреда при злоупотреблении. Страницы, где можно удалять записи, менять биллинг, создавать пользователей, менять роли или трогать production secrets, заслуживают дополнительного трения. Второе подтверждение или step-up authentication в таких местах может остановить худшие сценарии.
Хорошо работает простой тест. Представьте, что подрядчик на десять минут оставил ноутбук без присмотра. Если эта сессия может возвращать платежи, удалять пользователей и менять production config, радиус ущерба у вас слишком велик. Исправьте это в первую очередь, и остальное решение о доступе станет намного проще.
Аудит и работа поддержки
Правила доступа разваливаются, когда никто не записал, кому именно нужно приложение. Начните с имён или ролей, затем отметьте, откуда они подключаются и как часто пользуются инструментом. Разработчик, который открывает админ-инструмент дважды в месяц, создаёт совсем другой риск и другую нагрузку на поддержку, чем руководитель поддержки, который пользуется им весь день из дома и из офиса.
Короткая карта доступа помогает больше, чем кажется. Если инструмент нужен только шести сотрудникам, обычно лучше подходит более жёсткий путь доступа. Если 80 подрядчикам нужен редкий доступ из разных мест, поток входа и процесс восстановления становятся не менее важны, чем сама модель безопасности.
Вопрос аудита простой: что вы будете знать после того, как что-то пойдёт не так? Нужны логи, которые показывают, кто вошёл, когда вошёл, откуда пришёл и какой gate его пропустил. Если путь доступа не может связать действие с реальной личностью пользователя, разбор быстро становится тяжёлым.
До того как выбирать что-то одно, запишите минимальный набор записей, который вам нужен: реальная личность вместо общего пароля, временные метки для попыток входа и успешного доступа, данные источника, например IP или устройство, и достаточную историю событий, чтобы позже разбирать подозрительную активность. Это важно в обычных проверках, но ещё важнее при инциденте. Если кто-то меняет настройки биллинга или выгружает данные клиентов, команде не стоит тратить полдня на сбор логов из трёх систем.
Нагрузка на поддержку — вторая половина решения. Public ingress часто создаёт тикеты из-за сброса паролей, бот-трафика, сертификатов и пользователей, которые попали не на тот экран. Доступ через tunnel может снизить открытость, но создаёт свои тикеты, если identity-этап неудобен или мешает тем, кто часто ездит.
Представьте внутреннюю финансовую панель, которой пользуются восемь человек. Семеро открывают её из одной и той же страны каждую неделю. Один использует её в поездках. В таком случае сильная проверка личности с чистыми логами доступа обычно экономит время в целом, даже если путешествующему пользователю иногда нужна помощь. Публичная точка входа может выглядеть проще в первый день, но позже она часто создаёт больше работы для поддержки.
Как выбрать для одного приложения
Начните с задачи, которую приложение выполняет каждый день. Внутренний дашборд, через который сотрудники смотрят цифры, не требует такой же открытости, как партнёрский портал или клиентский API. Роль приложения должна определять выбор, а не привычка.
Потом запишите самое плохое действие, которое может совершить вошедший пользователь. Может ли он сбросить данные клиентов, одобрить платежи, удалить записи или получить доступ к production-системам? Если да, относитесь к приложению как к панели управления. Дайте ему настолько маленькое отверстие, насколько это возможно без потери работы.
Список пользователей быстро меняет ответ. Сотрудники на управляемых ноутбуках — один случай. Подрядчики на личных устройствах — другой. Клиенты — совсем третья история, потому что им нужна схема, которая работает без ваших внутренних правил identity и без лишних шагов поддержки. Инструмент, которым пользуются пять сотрудников, может жить за более жёсткими правилами доступа, чем инструмент для сотен внешних пользователей.
Практичная проверка сводится к нескольким вопросам:
- Кому нужен доступ каждую неделю и с каких устройств?
- Какой самый плохой ущерб может нанести один аккаунт?
- Нужен ли приложению только браузерный доступ или ещё и API-доступ?
- Можно ли потом проверить входы и действия?
- Кто быстро чинит доступ, если логин ломается в загруженный день?
Выбирайте минимальную открытость, которая всё ещё подходит для обычной работы. Если людям нужен только браузерный доступ и вы хотите поставить identity-checks перед приложением, tunnel обычно оставляет поверхность меньше. Если приложение должно принимать прямой входящий трафик от внешних систем, public ingress может быть необходим. В этом случае закручивайте защиту максимально жёстко.
Проверьте скучные сценарии отказа ещё до запуска. Войдите с нового устройства. Попробуйте заблокированный аккаунт. Удалите подрядчика и убедитесь, что доступ исчез сразу. Проверьте, что логи показывают, кто вошёл, откуда и что сделал. Восстановление тоже важно. Если один потерянный телефон превращается в шесть тикетов в поддержку, схема слишком хрупкая.
Простой пример
Небольшая команда из пяти человек ведёт внутреннюю панель управления биллингом. Сотрудники из финансов открывают её раз в неделю, чтобы исправлять счета, проверять неудачные платежи и выгружать отчёты. Кто-то работает с офисных ноутбуков, кто-то входит из домашних сетей.
Если команда помещает эту панель за public ingress, настройка кажется простой. У всех один адрес, и не нужно ставить дополнительный клиент. Проблемы начинаются почти сразу.
Админские страницы в открытом интернете начинают сканировать почти моментально. Логи заполняются попытками входа, запросами на сброс пароля и случайными проверками. Даже если внутрь никто не попадает, команде всё равно приходится разбирать оповещения, отвечать на вопросы о доступе и отделять реальную проблему от фонового шума.
Для маленькой панели, которой пользуются раз в неделю, это слишком большая открытость. Инструменты для биллинга часто содержат данные клиентов, статус платежей и управление возвратами. Один слабый пароль или один пропущенный апдейт может превратить небольшое удобство в реальную проблему безопасности.
Tunnel меняет картину. Панель остаётся вне открытого интернета, а команда может поставить перед ней SSO. Сотрудники финансов входят через ту же систему идентификации, которой уже пользуются, а компания может ограничить доступ коротким списком людей и одобренных ноутбуков.
Это ещё и снижает нагрузку на support. Меньше случайных попыток входа — меньше шумных оповещений. Аудиторские записи тоже становятся чище, потому что большинство событий доступа принадлежат реальным сотрудникам, а не ботам, которые весь день бьют по открытой админке.
Команде всё равно нужен запасной вариант. Если tunnel ломается или identity provider падает, финансовому отделу может понадобиться срочный доступ для payroll или refunds. Обычно достаточно простого аварийного пути для одного технического владельца, offline break-glass аккаунта и ежемесячной проверки восстановления.
Для этой команды tunnel обычно оказывается лучшим выбором. Public ingress экономит немного времени в начале. Tunnel экономит больше времени потом и не даёт панели биллинга превратиться ещё в одну открытую админскую поверхность.
Ошибки, которые тихо повышают риск
Самые опасные ошибки настройки — маленькие и скучные. Они редко ломают всё в первый день, но создают лишние тикеты, запутанные правила доступа и больший ущерб, когда скомпрометирован один аккаунт или endpoint.
Одна частая ошибка — использовать одинаковую схему админского пути и для сотрудников, и для клиентов. Если публичное приложение и служебная консоль живут по знакомым маршрутам вроде /admin или /staff на одном и том же hostname, люди быстро делают неверные выводы. Сотрудники поддержки открывают не ту страницу, клиенты находят экраны, которые им видеть не следовало, и правила становится сложнее понимать.
Старые записи доступа создают более тихую проблему. Бывший подрядчик может всё ещё оставаться в allowlist, потому что никто не отвечает за очистку. Это выглядит безобидно, пока вам не нужно ответить на простой вопрос: кто ещё мог открывать этот инструмент в прошлом месяце? Если ответ нельзя дать за минуты, модель доступа уже слишком свободная.
IP-allowlist тоже плохо стареют. Они кажутся простыми, но домашний интернет меняется, мобильные сети переключаются, офисы используют VPN, а общие IP размывают, кто и что сделал. Команды в итоге либо расширяют список, чтобы перестали жаловаться, либо каждую неделю получают одно и то же сообщение: «Я не могу войти». Проверки на основе личности с понятными логами обычно вызывают меньше боли.
Логи игнорируют по той же причине, по которой игнорируют бэкапы. Ничего не кажется срочным, пока не наступит плохой день. Тогда команда обнаруживает, что сохраняла только логи соединений, но не действия пользователей, или хранила логи, которые никто не умеет искать. Audit logging полезен только тогда, когда его можно быстро найти и понять.
Самая неприятная ошибка — временный public access. Кто-то открывает админскую поверхность для демо подрядчику, срочного исправления или недели удалённой работы. Изменение работает, все двигаются дальше, а через шесть месяцев дверь всё ещё открыта. Вот здесь риск часто скачет от управляемого к ненужному.
Простое правило помогает: у каждого исключения должен быть владелец, срок действия и проверка. Если команда не может сказать, кто одобрил доступ, когда он должен закончиться и какие логи подтверждают его использование, нагрузка на поддержку начнёт расти задолго до взлома.
Быстрые проверки перед тем, как открывать приложение
Многие внутренние инструменты вообще не нуждаются в публичной доступности. Если приложением пользуются только сотрудники или подрядчики, начните с прямого вопроса: зачем вообще выставлять его в публичный интернет? Во многих случаях приватная сеть, VPN или tunnel с identity-checks дают тот же доступ, но с меньшим риском.
Следующий вопрос касается не удобства, а ущерба. Если один вошедший пользователь может одобрять возвраты, выгружать данные клиентов, сбрасывать пароли или менять роли, приложению с самого начала нужен более жёсткий доступ. Админ-панель, которая может трогать деньги, данные или права, не должна стоять за слабым логином и надеяться на удачу.
Ещё нужно подумать о доступности. Если слой доступа падает, смогут ли сотрудники продолжить срочную работу или остановится вся команда? Поддержка, которая не может попасть в свой внутренний инструмент два часа, создаст для бизнеса большую проблему, чем аккуратная схема безопасности на диаграмме.
Чаще всего ломается именно владение процессом. Кто-то должен патчить приложение, смотреть логи доступа, удалять старые аккаунты и отвечать на тикеты «Я не могу войти». Если за это никто не отвечает, нагрузка на поддержку быстро растёт.
Поэтому этот выбор — не только про сеть. Это ещё и решение про операционную работу. Команды, которым нужна компактная схема, обычно выигрывают, если ограничивают доступ, держат identity-checks жёсткими и назначают одного понятного владельца доступа и логов. В advisory-работе именно это часто первым делом проверяет Oleg Sotnikov, прежде чем админская поверхность выйдет в прод.
Что делать дальше для более безопасной схемы
Начните с малого. Возьмите один внутренний инструмент, которым часто пользуются и который может причинить реальный ущерб, если внутрь попадёт не тот человек. Для этого достаточно панели биллинга, экрана администрирования базы или панели управления staging. Не пытайтесь пересмотреть сразу всю среду. Когда команды пытаются чинить все админские поверхности за один заход, они теряют фокус.
Если вы всё ещё выбираете между Cloudflare tunnels и public ingress, принимайте следующее решение в виде короткого письменного правила, а не длинного архитектурного документа. У каждой админской поверхности должен быть простой набор правил доступа, который отвечает на четыре вопроса: кому нужен доступ, откуда можно подключаться, как подтверждается личность и какие логи вы храните.
Сделайте это правило достаточно коротким, чтобы support, security и engineering могли прочитать его меньше чем за минуту. Если кто-то не может объяснить путь доступа простыми словами, схема, скорее всего, слишком свободная.
Затем исправьте самый рискованный путь первым. Обычно это админский экран с самым слабым логином, самой широкой сетевой открытостью или самым скудным audit history. Для снижения риска не нужна большая миграция. Один более жёсткий путь лучше, чем пять незавершённых планов.
После изменения доступа понаблюдайте за последствиями неделю или две. Посмотрите на неудачные логины, запросы на доступ и тикеты в поддержку. Если количество обращений резко выросло, правило, возможно, слишком тяжело соблюдать. Если никто почти не заметил изменений, а логи стали чище, вероятно, вы выбрали правильный уровень трения.
Одна привычка очень помогает: каждый раз, когда вы открываете или сохраняете админскую поверхность, записывайте, кто это одобрил и зачем. Эта маленькая заметка экономит время позже, когда кто-то спрашивает, почему инструмент открыт, кто за него отвечает или нужно ли ему всё ещё удалённое подключение.
Некоторым командам нужна вторая точка зрения до того, как они что-то изменят. Oleg Sotnikov и oleg.is работают именно с такими задачами Fractional CTO и review инфраструктуры, особенно когда компании ужесточают внутренний доступ и уменьшают операционную нагрузку. Иногда короткий review быстрее, чем разбор месяцев случайных исключений.
Более безопасный доступ обычно рождается из нескольких скучных решений, которые чётко сформулированы и выполняются каждый день.
Часто задаваемые вопросы
Когда стоит выбрать tunnel вместо public ingress?
Используйте tunnel, когда приложение предназначено для сотрудников, подрядчиков или небольшой одобренной группы, а сам инструмент может менять деньги, данные, пользователей или настройки продакшена. Он убирает origin из публичного интернета и отсеивает большую часть ботов ещё до начала.
Если приложению нужен прямой входящий трафик из внешних систем или от публичных пользователей, public ingress может подойти лучше. В таком случае держите поверхность небольшой и ставьте сильную проверку личности перед каждым чувствительным действием.
Делает ли tunnel внутреннее приложение безопасным сам по себе?
Нет. Tunnel скрывает origin от случайного интернет-трафика, но не исправляет слабые логины, общие аккаунты, отсутствие MFA или слишком широкие права админа.
Считайте tunnel только входными воротами, а не всей системой безопасности. Всё равно нужны надёжная проверка личности, узкие права и понятные логи.
Когда public ingress всё ещё имеет смысл?
Public ingress подходит приложениям, которым нужен прямой доступ извне, например клиентским кабинетам, партнёрским инструментам или API, к которым другие сервисы обращаются через интернет. Он также подходит, если tunnel создаёт слишком много неудобств для людей, которым нужен доступ.
Но даже в этом случае не относитесь к нему как к обычному сайту. Защитите логин, быстро ставьте патчи и добавляйте дополнительные проверки на экраны, которые меняют состояние.
Что обычно ломается в доступе через tunnel?
Чаще всего первым проблемным местом становится сам tunnel connector. Ваше приложение и база могут продолжать работать, а удалённые пользователи всё равно потеряют доступ, потому что connector остановился, завис или отстал после обновления.
Следите за connector как за частью приложения. Добавьте проверки состояния, оповещения и простой план перезапуска, чтобы support быстро понимал причину.
Как уменьшить радиус ущерба, если один аккаунт скомпрометирован?
Начните с разделения работы только на чтение и действий, которые меняют состояние. Украденная сессия причинит гораздо меньше вреда, если она может только смотреть отчёты и не может удалять данные, возвращать платежи или менять роли.
Затем добавьте больше трения там, где ущерб максимален. Step-up authentication, подтверждение для чувствительных действий и более узкие роли админа уменьшают последствия одной плохой сессии.
Какие audit logs мне действительно нужны для внутреннего админ-приложения?
Храните записи, которые связывают доступ с реальным человеком, а не с общим паролем. Нужны попытки входа, успешные логины, данные источника, например IP или устройство, и действия пользователя внутри приложения.
Важно ещё и то, чтобы кто-то мог быстро искать по этим логам. Они мало помогают, если команде нужно полдня, чтобы восстановить картину произошедшего.
Достаточно ли IP-allowlist для доступа сотрудников?
Обычно нет. Домашние IP меняются, мобильные сети переключаются, а офисы часто маршрутизируют трафик так, что становится сложно понять, кто и что делал. В итоге команды либо расширяют список, либо каждую неделю получают один и тот же тикет о доступе.
Доступ на основе личности с MFA и понятными логами пользователей работает лучше для большинства внутренних инструментов. IP-правила можно оставить как дополнительную проверку для небольшой доверенной группы.
Снизит ли tunnel количество тикетов в поддержку?
Обычно они действительно уменьшают количество обращений, потому что посторонние не доходят ни до страницы входа, ни до origin-сервера. Значит, меньше сканов, меньше фальшивых попыток входа и чище оповещения.
Но support никуда не исчезает. Вы просто меняете шум ботов на проблемы с identity и connector, поэтому сделайте вход простым и назначьте одного ответственного за него.
Что делать, если tunnel или SSO перестанет работать?
Настройте break-glass путь для одного доверенного технического владельца и проверяйте его каждый месяц. Держите этот путь узким, хорошо задокументированным и отдельным от повседневного доступа.
Если payroll, refunds или срочная поддержка зависят от приложения, не ждите аварии, чтобы разобраться. Запасной вариант помогает только тогда, когда команда уже попробовала его заранее.
Стоит ли звать внешнего эксперта перед тем, как открывать админ-инструмент?
Да, если приложение может работать с биллингом, данными клиентов, ролями пользователей, секретами или настройками продакшена. Короткий внешний review часто находит старые исключения, общие аккаунты, слабые следы аудита и аварийные пути, которые никто не проверял.
Если вам нужен практичный взгляд перед тем, как открыть ещё одну админскую поверхность, Oleg Sotnikov может оценить путь доступа, нагрузку на поддержку и план восстановления без превращения этого в длинный проект.


