Cloudflare R2 против S3 для растущего хранилища файлов продукта
Cloudflare R2 против S3 для хранения файлов продукта: сравните стоимость исходящего трафика, поддержку инструментов и объём миграции до переноса растущего бакета.
Содержание
Почему этот выбор позже становится дорогим
Создать бакет легко. Перенести его через шесть месяцев — нет.
К этому моменту ваше приложение, возможно, хранит URL файлов в базе данных, правила кэша зависят от одного провайдера, а фоновые задачи предполагают один набор API-особенностей. Скопировать файлы — обычно самая простая часть. Сложнее всё, что вокруг них: подписанные URL, правила доступа, кеширование CDN, политики жизненного цикла, логи, резервные копии и маленькие скрипты, которые никто не хочет трогать. Если клиенты уже каждый день полагаются на эти файлы, на время переезда вам, возможно, придётся держать старый и новый бакеты параллельно. Такое перекрытие может сначала поднять расходы, прежде чем оно что-то сэкономит.
Одна только цена хранения почти никогда не решает исход. Низкая цена за ГБ хорошо выглядит на странице с тарифами, но многие команды тратят больше на передачу данных, запросы и время разработчиков, чем на само хранение. Одна неделя работы инженера может съесть месяцы небольшой экономии на хранении.
Расходы на исходящий трафик тоже растут быстрее, чем многие ожидают. Ежемесячный счёт обычно скачет, когда пользователи снова и снова скачивают одни и те же файлы, когда крупные файлы вроде видео или ZIP-архивов часто покидают хранилище, когда объекты раздаются сразу в нескольких регионах или когда другие системы продолжают читать объекты для резервных копий, аналитики или AI-задач. Частные файлы с подписанными URL тоже могут добавлять шума, особенно если эти ссылки часто обновляются.
Именно поэтому Cloudflare R2 против S3 — это не только вопрос цены хранения. Это вопрос поведения продукта. Вам нужно понимать, как файлы проходят через приложение, кто их читает, как часто они меняются и какие инструменты трогают их после загрузки.
Команде с небольшими приватными вложениями может быть важнее всего поддержка SDK и уже существующая AWS-схема. Продукту, который раздаёт много публичных скачиваний, куда важнее исходящий трафик. Даже если обе команды хранят одинаковое число терабайт, у них будут совершенно разные формы затрат.
Если выбирать только по странице сравнения вендоров, можно упустить ту часть, которая обычно и становится дорогой позже. Выбирайте по реальному использованию, трафику и тому объёму миграции, который придётся сделать вашей команде.
Что на самом деле меняется между R2 и S3
И R2, и S3 хранят файлы как объекты внутри бакетов. Ваше приложение по-прежнему загружает файл, даёт ему имя, добавляет метаданные и потом читает его обратно. На бумаге это выглядит как простая замена.
Проблемы начинаются на уровне API вокруг хранилища. R2 совместим с S3, но совместимость не означает полную идентичность. Некоторые приложения работают после смены настроек. Другие ломаются в мелких, раздражающих местах, потому что код рассчитывал на поведение, характерное именно для AWS.
Один из типичных примеров — то, как приложение общается с хранилищем. Если код использует AWS SDK только для простых операций чтения и записи, перенос может остаться небольшим. Если же он зависит от паттернов AWS IAM, bucket policies, логики регионов, событийной интеграции или других сервисов AWS вокруг S3, объём работы быстро растёт.
Подписанные URL часто первыми показывают несоответствие. Обе службы поддерживают временные ссылки для загрузки и скачивания, но endpoints, настройка подписи и ожидания клиента могут отличаться. Если фронтенд ждёт один формат URL, а бэкенд подписывает другой, пользователи перестают видеть файлы и начинают получать ошибки при загрузке.
Мультичастичные загрузки тоже важны. Для крупных файлов обычно используют multipart-логику ради скорости и более надёжных повторов. Это может работать и дальше, но команды часто натыкаются на пограничные случаи в лимитах частей, проверке контрольных сумм, логике повторов или очистке заброшенных загрузок. Такие ошибки не остаются внутри слоя хранения. Они превращаются в обращения в поддержку и странные счета.
Правила жизненного цикла, версионирование и удаление требуют такого же внимания. Перенос может изменить то, как истекают старые объекты, как сохраняются перезаписанные файлы или как ведут себя задачи очистки. Это важнее, чем кажется. Если ваше приложение создаёт временные экспорты, снимки отчётов или превью, небольшое расхождение в хранении может оставить устаревшие файлы или удалить данные раньше времени.
Модель хранения остаётся знакомой. Операционные детали — не всегда.
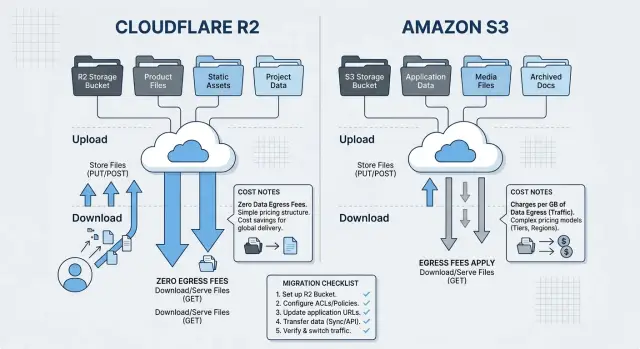
Как egress влияет на ежемесячный счёт
От одного хранения обычно больно не становится. Больно становится от скачиваний.
Бакет с умеренным счётом за хранение может быстро подорожать, как только файлы начинают покидать провайдера весь день. Обычно этот исходящий трафик идёт из нескольких мест: скачивания клиентами в веб- или мобильном приложении, промахи CDN-кэша, которые тянут файлы из бакета, экспорты, отправляемые клиентам или партнёрам, воркеры, которые уменьшают изображения или сканируют файлы, а также резервные или синхронизационные задачи, копирующие объекты куда-то ещё.
Скачивания пользователей и чтение внутренними сервисами на счёте выглядят одинаково, но ведут себя по-разному. Пользовательский трафик часто резко растёт после запуска, кампании или новой функции. Внутренние чтения тише и их легче не заметить. Фоновый воркер, который вытягивает один и тот же объект тысячи раз в день, может стоить дороже, чем все ваши клиенты вместе.
Поэтому разделяйте трафик по путям, а не только по общему числу ГБ. Если ваше приложение раздаёт файлы через CDN, большинство пользователей может вообще не обращаться к бакету напрямую. Если задачи обработки работают в другом облаке или регионе, эти чтения могут превращаться в стабильный поток исходящего трафика даже тогда, когда пользовательский трафик выглядит обычным.
Именно здесь математика часто меняется. R2 убирает плату за egress при выходе данных из бакета, поэтому занятая файловая схема с большим количеством скачиваний может быстро стать заметно дешевле. S3 всё ещё может выглядеть нормально, когда в бакете много данных, но пользователи скачивают мало, или когда большинство чтений остаётся рядом с сервисами AWS и не создаёт большого исходящего трафика.
Простой контраст всё объясняет. Архивный бакет, в котором лежит 15 ТБ старых отчётов и который отдаёт 300 ГБ в месяц, обычно живёт или умирает за счёт цены хранения, числа запросов и удобства инструментов. Бакет с 5 ТБ файлов приложения, но с 25 ТБ исходящего трафика в месяц, — это в первую очередь проблема трафика. Во втором случае egress может определять весь счёт.
Команды часто упускают это, потому что сначала сравнивают тарифы на хранение. Лучше посмотреть на разбивку трафика за 30 дней: скачивания клиентов, origin pulls CDN и чтение между сервисами. После этого более дешёвый вариант обычно перестаёт быть угадыванием.
Проверьте инструменты до перехода
Большинство миграций хранилища ломаются не в самом бакете, а в склейке между системами. У R2 и S3 API достаточно похожий, поэтому команды часто думают, что их инструменты просто продолжат работать. Некоторые действительно продолжат. Некоторые сломаются тихо и неприятно.
Проверьте все места, где команда читает, пишет, копирует, подписывает, сканирует, уменьшает или анализирует файлы. Слой хранения — это редко только основное приложение. Это ещё и cron-задачи, разовые админ-скрипты, резервные операции и маленькие воркеры, к которым год никто не прикасался.
Короткая проверка обычно находит проблемы в четырёх местах:
- Вызовы SDK внутри приложения, фоновых задач и мобильных бэкендов
- CLI-скрипты, используемые в CI, cron и рабочих сценариях поддержки
- Потоки предподписанных загрузок и скачиваний, включая настройки CORS
- Воркеры обработки изображений, видео, PDF и проверки на вирусы
К подписанным URL нужно отнестись особенно внимательно. Перенос бакета может изменить правила endpoint-ов, заголовки или детали подписи. Если клиенты загружают большие файлы прямо из браузера, проверьте весь путь на реальных размерах файлов, а не на маленьком тестовом образце. То же самое сделайте для скачивания, особенно если приложение задаёт собственные имена файлов или короткие сроки действия.
Отдельно проверьте обработку файлов. Воркер для изображений может зависеть от метаданных объекта, правил именования или момента наступления события. Конвейер документов может ожидать, что файл сначала появится в одном регионе, а потом запустит OCR или генерацию превью. Когда эти предположения меняются, сбой выглядит грязно: пропавшие миниатюры, зависшие конвертации или тикеты от пользователей, которые уверены, что файл загрузился нормально.
Не пропускайте скучные части. Резервные задачи, правила хранения, логи доступа, оповещения и отчёты по использованию помогают поймать ошибки раньше. Если на эти отчёты зависят финансы, поддержка или безопасность, убедитесь, что те же данные всё ещё приходят в формате, который им подходит.
Один практический тест полезнее длинной встречи: загрузите реальный файл, обработайте его, скачайте по подписанной ссылке, восстановите из бэкапа и проверьте логи. Если вся эта цепочка работает, перенос гораздо безопаснее.
Как оценить объём миграции
Объём миграции зависит не столько от общего числа терабайт, сколько от того, как приложение использует бакет каждый день. Бакет с 30 ТБ архивных файлов может быть простым для переноса. Бакет с 40 миллионами маленьких изображений, частыми обновлениями и истекающими подписанными скачиваниями — обычно нет.
Начните с простого инвентаря. Вам нужны реальный размер бакета, число объектов и примерное соотношение типов файлов. Изображения, видео, бэкапы, автоматически созданные отчёты и пользовательские загрузки ведут себя по-разному, особенно если одни файлы часто меняются, а другие — никогда.
Здесь помогает короткий чек-лист:
- Общий объём хранения
- Общее число объектов
- Средний и максимальный размер файлов
- Группы файлов по назначению, например загрузки, экспорты и бэкапы
- Текущие правила версионирования, хранения и удаления
Затем опишите все действия, которые трогают хранилище. Команды часто считают только загрузки и скачивания, а потом забывают про удаления, фоновые задачи, генерацию миниатюр, потоки предподписанных URL, multipart-загрузки и правила жизненного цикла. Если вы сравниваете Cloudflare R2 против S3, эта карта особенно важна, потому что бакет — это редко просто пассивное место для файлов.
Перед оценкой полной миграции запустите небольшой тест копирования. Возьмите выборку, похожую на продакшен, а не чистую демо-папку. Скопируйте её, проверьте контрольные суммы и откройте несколько файлов через приложение. Этот тест скажет больше, чем таблица. Он также выявит проблемы в именовании, пробелы в метаданных, ошибки в правах и устаревшие ссылки в базе данных.
Потом измерьте три времени: сколько займёт полная синхронизация, сколько понадобится на окно окончательного переключения и сколько займёт откат, если приложение начнёт читать не те файлы или пропустит новые загрузки. Именно эти цифры формируют реальный план, а не только скрипт миграции.
Простой пример помогает. Если приложение хранит изображения товаров и пользовательские экспорты, вам может понадобиться одна длинная фоновая синхронизация, а потом короткая пауза, во время которой вы останавливаете новые записи, копируете последние изменения, переключаете чтение на новый бакет и проверяете несколько живых путей. Если приложение пишет файлы весь день, этот план заморозки становится ещё важнее.
Запишите план заморозки простыми шагами. Укажите, кто останавливает запись, кто запускает финальную синхронизацию, кто проверяет контрольные суммы, кто тестирует приложение и что запускает откат. Хорошие планы на бумаге выглядят скучно. Обычно это хороший знак.
Реалистичный пример
Представьте SaaS-приложение для клиентской отчётности. Клиенты загружают логотипы, CSV-файлы, PDF и скриншоты. Приложение ещё и каждый день создаёт экспортные файлы, а команда поддержки отправляет ссылки на скачивание, когда клиенты просят старые отчёты или данные по аккаунту.
В бакете уже лежит 2,5 ТБ. Приложение добавляет около 120 ГБ новых файлов в неделю, в основном загрузки и созданные экспорты. Сначала это кажется управляемым, но важнее тут не размер, а характер трафика.
Большинство пользователей делает с этими файлами три вещи. Они открывают превью внутри приложения, скачивают полные экспорты в конце месяца и делятся ссылками с коллегами. Поддержка добавляет ещё трафика, потому что каждый тикет в духе «пришлите мне этот файл ещё раз» создаёт ещё одно скачивание.
Если приложение в основном работает на AWS, оставаться на S3 всё ещё может иметь смысл. Команда, возможно, уже использует события S3, политики IAM, правила lifecycle и резервные задачи, построенные вокруг стека AWS. В таком случае стоимость хранения — лишь часть счёта. Сэкономленное время разработчиков может перевесить ежемесячную экономию от переезда.
Если исходящий трафик высокий, R2 начинает выглядеть лучше. Допустим, приложение хранит 2,5 ТБ, но каждый месяц отправляет наружу 12 ТБ через экспорты, превью и общие ссылки. Вот где egress начинает больно бить по бюджету. В решении Cloudflare R2 против S3 тяжёлые публичные скачивания часто подталкивают расчёты в сторону R2 быстрее, чем люди ожидают.
Часто наименее рискованный вариант — гибридная схема. Оставьте файлы в S3, если они кормят AWS-задачи, приватную обработку или уже существующие правила комплаенса. Перенесите публичные скачивания, клиентские экспорты или общие ресурсы в R2, если именно они создают основную часть счёта за трафик.
Обычно у команд остаются три реальных варианта:
- Оставаться на S3, если интеграции с AWS экономят время разработчиков каждую неделю.
- Перейти на R2, если клиентские скачивания создают большую часть ежемесячного трафика.
- Разделить хранение, если один бакет выполняет две разные задачи, и дорогая только одна из них.
Одна деталь часто сбивает команды с толку: превью легко игнорировать, потому что каждый запрос маленький. Но тысячи открытий превью на дашбордах, экранах поддержки и общих страницах быстро накапливаются. Перенос бакета окупается быстрее, когда трафик широкий и повторяющийся, а не только когда систему покидают несколько больших экспортов.
Если ваше приложение похоже на это, спрашивайте не только, где лежат файлы. Спрашивайте, кто их скачивает, как часто и какие части приложения сломаются, если изменится API хранилища.
Ошибки, которые команды допускают при переносе бакета
Большинство команд начинают с цены хранения и на этом останавливаются. Так они упускают ту стоимость, которая действительно растёт: трафик. Бакет, полный изображений товаров, бэкапов, экспортов или пользовательских загрузок, может выглядеть дешёвым в покое, а потом резко дорожать, когда приложения, пользователи и фоновые задачи начинают тянуть файлы весь день.
Ещё одна частая ошибка — считать, что S3-compatible означает «то же самое». Обычно это значит «достаточно похоже» для базовых чтений и записей. Это не значит, что каждое правило lifecycle, поток событий, паттерн IAM, пограничный случай с подписанным URL, админ-скрипт или поведение multipart-загрузки совпадут с тем, что вы уже используете. Небольшие расхождения быстро становятся раздражающими, когда прячутся внутри биллинговых задач, задач очистки или support-инструментов, к которым год никто не прикасался.
Поведение при удалении заслуживает отдельного теста. Команды часто сначала копируют данные, а очистку откладывают на потом. Потом выясняется, что правила хранения, срок жизни объектов, версионирование или скрипты массового удаления ведут себя не так, как ожидалось. Из-за этого могут остаться сиротские файлы или, что хуже, удалиться файлы, которые ещё нужны.
Короткий план тестирования ловит большую часть проблем:
- Несколько раз загрузите, перезапишите и удалите один и тот же файл.
- Запустите задачи lifecycle и хранения на маленьком тестовом бакете.
- Проверяйте контрольные суммы после передачи, а не только количество объектов.
- Протестируйте старые админ-скрипты и разовые инструменты обслуживания.
- Запишите шаг отката до переключения в продакшене.
Контрольные суммы и шаги отката кажутся скучными, но отказ от них стоит дорого. Количество объектов может совпадать, а содержимое файлов — нет. План отката тоже не должен сводиться к «переключим обратно». Оставьте старый бакет живым, заморозьте рискованные записи на время переключения и заранее решите, кто может запускать откат.
Один небольшой пример говорит о многом. Команда переносит клиентские экспорты за выходные. В понедельник приложение работает, но ночная задача очистки падает, потому что она зависит от старого скрипта с предположениями, специфичными для AWS. К пятнице хранилище разрастается, устаревшие файлы копятся, а поддержка начинает слышать, что удалённые экспорты всё ещё видны в дашбордах. Кажется, что перенос завершён. Но это не так.
Быстрые проверки перед решением
Таблицы с тарифами могут слишком рано подтолкнуть команду к переезду. Три месяца реальных данных по бакету дают гораздо лучший ответ, чем оценка за выходные. Посмотрите на общий рост хранилища, на скорость накопления новых файлов и на то, продолжают ли старые файлы часто скачивать.
Поведение скачиваний важно не меньше, чем размер хранения. Если пользователи загружают файлы и почти никогда не открывают их снова, egress может почти не влиять на счёт. Если клиенты каждый день скачивают отчёты, видео, экспорты или общие ресурсы, разрыв между Cloudflare R2 против S3 может быстро стать большим.
Короткий чек-лист помогает принять честное решение:
- Сравните размер бакета по месяцам за последние три месяца. Вам нужен темп роста, а не только сегодняшняя цифра.
- Посчитайте чтения файлов, общие ссылки и скачивания клиентами. Внутренние задачи тоже важны, особенно если они снова и снова тянут одни и те же файлы.
- Выпишите все инструменты, которые предполагают поведение S3. Бэкапы, media-задачи, подписанные URL, правила IAM, задачи lifecycle и интеграции вендоров — всё это добавляет работы.
- Задайте лимит риска на переключение до старта. Одни команды выдерживают период двойной записи и аккуратный откат. Другим нужен простой перенос почти без простоя.
- Сопоставьте экономию с ценой миграции. Если перенос экономит $150 в месяц, но требует недели работы инженеров, возможно, лучше подождать.
Сторонние зависимости часто решают всё. Перенос хранилища кажется простым, пока не ломается один экспорт биллинга, один обработчик изображений или один сценарий клиента, потому что он ждёт поведения, специфичного для S3. Это не значит, что от переезда нужно отказываться. Это значит, что совместимость нужно посчитать до того, как вы пообещаете дату.
Сроки важнее, чем многие команды готовы признать. Если бакет всё ещё маленький, экономия может быть реальной, но слишком небольшой, чтобы оправдать текущие неудобства. Если продукт уже раздаёт большие скачивания в масштабе, переезд может окупиться быстро. Выбирайте вариант, который соответствует текущему использованию, готовности команды рисковать и росту на ближайшие шесть месяцев.
Что делать дальше
Неделя реальных цифр расскажет вам больше, чем ещё один месяц споров. Прежде чем выбирать между Cloudflare R2 и S3, измерьте, что ваш бакет на самом деле делает в продакшене: сколько объектов вы записываете, как часто пользователи их читают, сколько данных уходит из хранилища и когда происходят всплески трафика.
Измеряйте полную неделю, а не один загруженный день. Если у вашего продукта есть паттерны по будням, скачивания на выходных, бэкапы или пакетные задачи, короткая выборка может ввести в заблуждение. Делайте измерение простым и одинаковым, чтобы можно было сравнить варианты без догадок.
После этого положите на одну страницу три плана:
- План остаться: оставить текущий бакет, убрать лишнее и оценить расходы на ближайшие 6–12 месяцев.
- План переезда: перенести полностью, включая время инженеров, время на тесты и временный период двойного хранения.
- Гибридный план: оставить часть файлов на месте и перенести только тот трафик, который создаёт основную часть счёта за полосу.
Такое сравнение обычно делает решение яснее. Команды часто зацикливаются на цене хранения за ГБ и пропускают более крупные затраты на скачивания, изменения в приложении, поведение кэша или время эксплуатации. Гибридная схема иногда выглядит менее элегантно на бумаге, но на практике бывает дешевле и безопаснее.
Не трогайте продакшен-данные, пока план переключения не записан. Решите, кто копирует данные, как вы проверяете количество объектов и контрольные суммы, когда замораживаете запись, как делаете откат и что считается успехом в первые 24 часа. Если никто не владеет этими шагами, миграция начнёт расползаться, а пользователи найдут ошибки за вас.
Если компромиссы всё ещё выглядят запутанно, возьмите второе мнение до переезда. Oleg Sotnikov на oleg.is работает со стартапами и малым бизнесом как Fractional CTO, помогая командам пересматривать архитектурные решения, сокращать облачные расходы и избегать миграций, которые стоят дороже, чем экономят.
Небольшая проверка сейчас может сэкономить недели переделок позже.


