Паттерны чтения Postgres, которые стоит вынести в отдельный сервис
Паттерны чтения в Postgres могут замедлять основное приложение, когда отчёты, поиск или массовое извлечение нагружают систему. Узнайте, когда имеет смысл вынести чтения в отдельный сервис.
Содержание
Почему основное приложение начинает тормозить
База данных продукта не различает, приходит ли запрос от входа в систему, оформления заказа, панели клиента, сохранённого отчёта или страницы поиска. Все они конкурируют за одно и то же время CPU, память, чтения диска, пространство кеша и слоты подключений. Поначалу общий пул кажется достаточным. По мере роста использования один «шумный» путь чтения может отобрать ресурсы у экранов, которыми люди пользуются каждый день.
Обычные экранные страницы обычно задают небольшие предсказуемые вопросы. Пользователь открывает один аккаунт, один счёт или один заказ. Postgres отвечает быстро, когда индексы подходят под эти запросы и нужные строки остаются «тёплыми» в памяти.
Отчёты ведут себя совсем иначе. Один отчёт может просканировать полгода заказов, отсортировать большой результат, сгруппировать его по регионам и посчитать итоги для каждой команды. Такой одиночный запрос может выполняться достаточно долго, чтобы вытеснить полезные данные из кеша, сильно нагрузить диск и удерживать рабочий процесс базы данных, пока обычные запросы приложения выстраиваются в очередь.
Трафик поиска часто создаёт ту же проблему, даже когда страница выглядит просто. Пара дополнительных фильтров, диапазон дат и частичное совпадение текста способны превратить один запрос поиска клиента в широкий проход по большой таблице. Ежедневные экраны приложения могут трогать 10–20 строк. Страницы поиска или извлечения могут просканировать тысячи строк, прежде чем вернуть одну страницу результатов.
Боль проявляется в местах, которые кажутся не связанными. Клиент нажимает «Войти» и ждёт две лишние секунды. Оформление заказа замирает на мгновение. Экран поддержки истекает по таймауту. Команда может не сразу найти источник, потому что само приложение почти не изменилось. Один тяжёлый чтений может заполнить пул подключений, занять память для сортировок и агрегаций или создать такое давление на диск, что простые запросы начинают тормозить.
Вот почему паттерны чтения в Postgres имеют такое значение. Пользователи первыми ощущают задержки, обычно в самых обычных действиях. К тому времени, когда команда видит явный всплеск нагрузки базы данных, основной путь продукта уже стал хуже.
Какие шаблоны чтения вредят в первую очередь
Первым начинают мешать те чтения, которые просматривают много данных, сортируют большие наборы результатов или многократно задают базе один и тот же вопрос.
Большие отчёты — частый источник проблем. Ежемесячный отчёт по выручке или сводка использования часто группируют данные за недели или месяцы, затем сортируют и агрегируют их в одном тяжёлом запросе. Это может казаться нормальным, когда таблица содержит тысячи строк, но совсем иначе — когда миллионы, и тот же отчёт запускают в рабочее время.
Страницы поиска тоже становятся дорогими быстрее, чем команды ожидают. Страница с фильтрами по дате, статусу, владельцу, региону, тегам и пользовательской сортировкой ставит Postgres перед жёстким выбором. Для пользователя форма поиска выглядит просто. База данных видит много возможных путей, множество проверок индексов и иногда большую сортировку после фильтрации.
Панели мониторинга — ещё одна ранняя проблема, особенно когда каждая перезагрузка соединяет несколько больших таблиц. Один график может быть дешёвым. Пять графиков, обновляющихся каждую минуту, — нет. Если каждый виджет запрашивает свежие числа с отдельными join и count, панель начинает конкурировать с основным потоком продукта.
Задания извлечения часто кажутся безобидными, потому что выполняются в фоне. Они перестают быть безобидными, когда вытаскивают широкие записи для AI-подсказок, CSV-экспортов, синхронизации с партнёрами или внутренних пайплайнов. Чтение больших JSON-блобов, длинных текстовых полей и множества колонок давит на память, диск и сеть. Приложение всё ещё может быстро писать, но пользовательские чтения начинают ждать.
Есть и более тихая проблема: фоновые процессы, которые весь день перечитывают одни и те же данные. Подумайте о воркере синхронизации, который проверяет один и тот же набор клиентов каждые несколько минут, или о задаче, которая заново собирает почти идентичные полезные нагрузки. Каждый запрос кажется небольшим. В сумме нагрузка велика.
Простое правило помогает: чтения, которые смотрят глубоко в историю, комбинируют много условий или вытаскивают больше колонок, чем нужно для одной страницы, часто оказываются первыми кандидатами на вынос. Им не обязательно нужна новая база данных в первый же день, но они требуют внимания до того, как окажутся на том же пути, что и вход, оформление заказа, сообщения или любое другое действие, где пользователи ждут мгновенного отклика.
Признаки того, что стоит разделить чтения
Занятая база данных редко ломается сразу. Чаще несколько страниц становятся хуже каждую неделю, в то время как остальная часть приложения ещё кажется нормальной. Один ранний признак: самые медленные запросы продолжают замедляться даже в обычные дни, когда кол-во заказов, регистраций или API-трафика не выросло. Это обычно означает, что чтения конкурируют с основным потоком продукта.
Временные закономерности многое говорят. Если количество подключений растёт в 9:00 каждое утро, в конце месяца или всякий раз при запуске планового экспорта, значит отдельная нагрузка чтения попадает на тот же Postgres в одно и то же время. Приложение может оставаться онлайн, но база данных тратит больше времени на обслуживание панелей, экспортов и фильтрованных таблиц вместо действий пользователей, которые двигают продукт.
Сравните экраны, насыщенные чтением, с действиями записи. Если сохранение формы всё ещё быстрое, но страницы аналитики, результаты поиска или админ-таблицы занимают несколько секунд, пользователи уже наблюдают разрыв. Этот разрыв часто показывает, какие паттерны чтения больше не должны лежать на том же пути, что оформление заказа, регистрация или обновления транзакций.
Большие запросы оставляют и другие следы. Отчёт, который раньше завершался за 2 секунды, теперь идёт 8, затем 15, затем 30 при той же нагрузке. Скоро проблема — не один медленный запрос, а три-четыре его копии, накапливающиеся, удерживающие подключения и заставляющие ждать несвязанные запросы.
Поддержка обычно слышит об этом раньше, чем графики станут плохими. Люди редко пишут «ваши отчёты загружают приложение». Они говорят «панель медлит каждый послеобед» или «экспорты всё тормозят». Если жалобы собираются вокруг окон отчётности или массовых задач извлечения, обратите внимание.
Разделение имеет смысл, когда шаблон повторяется: медленные страницы совпадают по расписанию, экраны с большим чтением деградируют сильнее, чем действия записи, большие запросы накладываются, а поддержка может назвать и экран, и временной промежуток. В этот момент тонкая оптимизация может выиграть время, но не изменит характер трафика. Часть продукта выросла в самостоятельную службу, и основное приложение должно перестать нести её на том же пути чтения.
Простой пример для SaaS
Небольшая SaaS-компания продаёт ПО оптовикам. Каждое утро в 9:00 команда продаж экспортирует большой CSV с заказами, счетами, возвратами и статусом оплат за предыдущий месяц. Через несколько минут клиенты заходят в систему, открывают панель и проверяют свежие числа.
Оба потока читают одни и те же таблицы Postgres. Экспорт запрашивает много сразу: соединяет заказы со счетами, фильтрует по дате, сортирует большие наборы результатов и сканирует гораздо больше строк, чем нужно панели. Панель кажется легче, но ей всё равно нужны последние заказы, неоплаченные счета, итоги по аккаунту и несколько графиков.
На бумаге оба — только чтение. На практике они не равны. CSV-экспорт делает работу, которая вытесняет полезные страницы из кеша и удерживает подключения слишком долго. К моменту прихода клиентов база данных уже утомлена.
Команда может сначала заметить это в мелочах. Вход медлит. Графики панели загружаются частями. Поддержка говорит, что приложение «какое-то странное» каждое утро. Инженеры смотрят на серверы приложений, ничего явного не видят и тратят день на поиск не там.
Чистый первый шаг — вынести путь экспорта до того, как трогать панель клиента. Пусть основное приложение продолжает читать и писать в основную базу. Перенесите экспорт в отдельный сервис или запустите его с реплики для чтения. Команда продаж обычно смирится с небольшим отставанием в обмен на то, чтобы не замедлять остальную часть продукта.
Это не решает все будущие проблемы с базой. Но это решает ту, которая в данный момент мешает пользователям. Для первой выноски этого обычно достаточно.
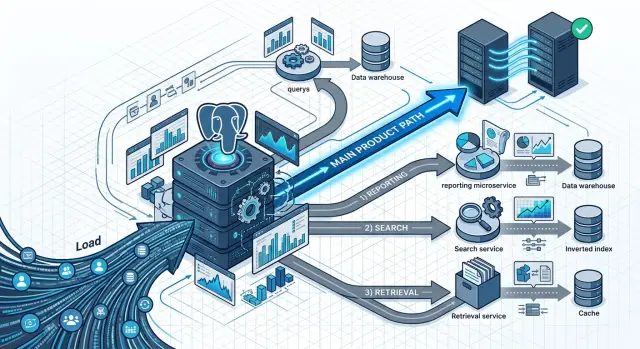
Как выбирать, что выносить первым
Если несколько путей чтения делят один кластер Postgres, не начинайте с самого громкого конечного пункта только потому, что он пугает. Начните с пути чтения, который дорог, раздражает наименьшее число пользователей и может безопасно показывать данные, отстающие на несколько секунд или минут.
Запишите всЁ крупные пути чтения простым языком. Думайте в терминах действий пользователя, а не таблиц: загрузки панели, CSV-экспорты, админ-отчёты, поиск продукта или фоновые задания извлечения контекста для писем или фич AI. Для каждого укажите, как часто он запускается, сколько строк трогает и что произойдёт, если ответ будет немного устаревшим.
Большинство команд приходят к одному порядку. Держите основной поток продукта рядом с основной базой. В начало списка на вынос ставьте отчёты и экспорты. Рассмотрите поиск рано, если он уже ведёт себя иначе, чем обычные запросы приложения. Переносите пакетные задания, если они много сканируют и работают вне цикла запрос-ответ.
Биллинг-отчёт, который сканирует два миллиона строк каждый час, — лучшее первое разделение, чем страница профиля клиента, которая читает двадцать строк и должна загрузиться мгновенно. Отчёт тяжёлый, но пользователь может подождать. Страница профиля лёгкая, но каждая задержка ощущается болезненно.
Выберите одну границу для первого шага. Это может быть API отчётов, сервис поиска или воркер извлечения. Одна чёткая граница проще тестировать, объяснять и откатывать. Если вы сначала вынесете отчёты, остальная часть приложения сможет работать как прежде.
Для первого шага держите записи в одном месте. Пусть основное приложение продолжает писать в первичную базу, а новый сервис читает из реплики или другого хранилища для чтения. Это избегает кучи проблем с конфликтами, пропущенными обновлениями и трудноотслеживаемыми багами.
Измерьте до изменений. Зафиксируйте время ответа затронутых конечных точек, загрузку CPU базы, количество медленных запросов, давление на пул подключений и объём чтений. Сравните те же метрики после изменений. Первая выноска должна чувствоваться скучно: меньше всплесков на первичной базе, стабильнее задержки приложения и никакого неожиданного поведения для пользователей.
Как выносить без драм
Начните с одного пути чтения, который уже вызывает трение, например панели продаж, поиска по продуктам или истории аккаунта. Не переносите три вещи сразу. Один узкий кейс легче измерить, протестировать и откатить.
Самый безопасный ход — сохранить старую форму API. Если старый эндпоинт возвращал id заказа, имя клиента, сумму и статус, новый сервис должен возвращать те же поля в том же порядке и с теми же значениями по умолчанию. Код приложения остаётся спокойным, и вы узнаете, помогло ли изменение хранилища, вместо того чтобы отлаживать изменения в ответе.
Затем направьте этот сервис на хранилище, подходящее для задачи. Для отчётов обычно подходит реплика для чтения. Поиск часто лучше в поисковом индексе. Тяжёлые страницы lookup иногда выигрывают от небольшого хранилища для чтения, в котором хранятся только нужные таблицы и соединения.
Используйте feature-flag, продублируйте один путь запроса за ним и кормите этот путь из нового источника. Сохраняйте контракт ответа неизменным. Запишите правила свежести простым языком, например «данные панели могут отставать на 60 секунд» или «поиск обновляется в пределах 5 минут». Затем пустите небольшой процент трафика на новый путь и сравните строки, счёты и время ответа. Держите переключатель для быстрого отката, чтобы вернуть весь трафик за секунды.
Сравнивайте результаты, прежде чем праздновать. В течение недели логируйте несоответствия, пропавшие строки и странности в сортировке. Некоторые паттерны чтения Postgres тихо проваливаются после выноса, потому что новый источник по‑другому обрабатывает null, полнотекстовый поиск или часовые пояса.
Спокойная миграция выглядит скучно со стороны. Это хорошо. Малые обратимые шаги всегда лучше большого переписывания, особенно когда основной путь продукта уже медлит.
Ошибки, которые усугубляют проблемы
Команды обычно попадают в беду, когда выносят слишком многое сразу. Отчёты, поиск и извлечения могут выглядеть шумными в Postgres, но они ломаются по-разному и не требуют одинакового решения.
Если вы переместите все три в одном спринте, у вас появятся три новые системы для отладки. Когда числа пойдут неверно, поиск станет устаревшим, а панели замедлятся, никто не поймёт, какое изменение это вызвало.
Ещё одна распространённая ошибка — переносить записи вместе с чтениями в первый же день. Это превращает простое разделение трафика в проблему владения данными. Сервис чтения должен начинаться как скучная копия или проекция, а не как второй источник правды.
Небольшая SaaS-команда может вынести поиск продукта в отдельный сервис из‑за wildcard-запросов, которые нагружают основную базу. Это разумно. Но перенос правок продукта, обновлений инвентаря и админ-отчётов туда же одновременно превращает безопасное изменение в неделю откатов.
Команды также спотыкаются о свежесть данных. Агентам поддержки нужно знать, живой ли отчёт, отстаёт ли он на пять минут или обновляется каждый час. Если никто не устанавливает правило, пользователи видят «баги», которые на самом деле — ожидаемая задержка, и поддержка тратит время зря.
Ещё ошибка — переписывать все запросы, вместо того чтобы исправлять худший путь первым. Это тянет время и добавляет риск. Если два запроса на панели создают большую часть боли, сначала вынесите их и оставьте остальное.
Новый сервис тоже нуждается в тех же ограничениях, что и старый путь. Команды забывают про правила доступа, процессы очистки и мониторинг, потому что первой целью является скорость. В результате приватный отчёт может пробросить неправильные строки, старые данные накапливаются, или никто не замечает, что отставание синхронизации выросло с 30 секунд до 20 минут.
Более безопасный первый шаг намеренно скучный: держите записи в основном приложении, вынесите один паттерн чтения первым, определите правило свежести, скопируйте проверки авторизации, задачи очистки и оповещения до запуска.
Быстрые проверки до и после выноса
Многие паттерны чтения Postgres можно безопасно вынести только если у основного приложения остаётся один очевидный владелец записей. Сначала держите записи в продуктовом потоке. Новый сервис может читать из реплики, индекса или кеша, но не должен становиться источником правды.
Это правило делает ошибки маленькими. Если сервис отчётов упадёт, пользователи всё ещё смогут создавать заказы, сохранять настройки и завершать обычные действия в основном приложении.
До выноса
Задайте несколько простых вопросов перед тем, как перенаправлять трафик с основной базы.
- Обрабатывает ли основное приложение все записи и все действия пользователей, которым нужны свежие данные?
- Может ли новый путь чтения отставать на секунды или минуты без нарушения пользовательских сценариев?
- Измеряете ли вы время запросов, длину очереди и уровень ошибок на старом и новом путях?
- Можете ли вы быстро выключить разделение флагом, переключателем конфигурации или простым изменением маршрутизации?
- Знает ли каждая команда, какие экраны нуждаются в свежих данных, а какие могут показывать задержанные данные?
Командам также нужна общая терминология. Если продукт говорит «вживую», а инженерия имеет в виду «обновляется каждую минуту», путаница превратится в тикеты поддержки.
После выноса
Сначала наблюдайте за основным путём, а не за новым сервисом. Вы хотите увидеть снижение нагрузки на первичную базу, сокращение времени ожидания для действий пользователей и меньше медленных запросов в пиковые часы. Если эти показатели не улучшились, вынос не решил реальную проблему.
Затем следите за новым путём отдельно. Отслеживайте отставание реплики, всплески таймаутов, задержки индекса поиска и лавины повторных попыток. Сервис чтения может выглядеть здоровым, при этом пользователи всё ещё видеть устаревшие результаты или частично обновлённые отчёты.
Запустите один простой тест, понятный всем командам: измените запись в приложении и проверьте, когда это изменение появится на каждом экране. Запишите результат. «Поиск обновляется за 10 секунд» — ясно. «Обычно довольно быстро» — нет.
Держите откат простым. Если новый путь ведёт себя плохо, верните чтения на основное приложение, примите временную нагрузку и исправьте проблему без догадок. Небольшие команды делают это лучше, когда переключатель очевиден и есть ответственный за него.
Что делать дальше
Выберите один путь чтения, который раздражает пользователей или вашу команду каждую неделю. Может быть, отчёт, который даёт всплеск CPU в 9 утра, или эндпоинт поиска, который замедляет оформление заказа. Вынесите его первым. Маленькая победа учит больше, чем грандиозный план по переписыванию.
Прежде чем что-то менять, запишите три правила на одной странице: кто владеет новым сервисом, насколько свежими должны быть данные и что вы сделаете, если разделение вызовет ошибки или устаревшие результаты. Если команда не может ответить на эти пункты простым языком, дизайн ещё слишком размытый.
Сделайте первый шаг простым. Скопируйте один тяжёлый путь чтения в отдельный сервис. Кормите его из реплики, кеша или поискового индекса. Сравнивайте латентность и уровень ошибок в течение недели. Держите чистый путь отката на старый запрос.
Команды попадают в беду, когда добавляют слишком много сразу. Поисковый кластер, очередь, слой кеша и новые панели могут превратить одну проблему базы данных в четыре операционных задачи. Для большинства паттернов чтения Postgres достаточно одной изолированной выноски, чтобы проверить идею.
После первой выноски пересмотрите стоимость перед добавлением ещё одного сервиса. Проверьте облачные расходы, время инженеров, шум оповещений и то, как часто кто-то правит устаревшие данные. Если новая конфигурация спасает основной путь продукта, но пожирает команду, она слишком дорога.
Простое правило: каждая новая служба должна убирать реальную, конкретную боль. «Отчёты больше не замедляют приложение» — реальный результат. «Архитектура стала чище» обычно — нет.
Если команда хочет внешнего взгляда, Oleg at oleg.is работает как Fractional CTO и стартап-советник. Он помогает командам делать такие изменения с узкой областью сначала, чтобы основной продукт оставался стабильным, пока тяжёлый путь чтения выносится.
Сделано правильно, следующий шаг — маленький и спокойный. Один путь чтения уходит, приложению становится легче дышать, и команда остаётся в контроле системы.
Часто задаваемые вопросы
When should I stop running reports on the main Postgres database?
Start when reports, exports, or search pages slow down normal product actions like login, checkout, or simple dashboard loads. If the same slowdown shows up on a schedule and read-heavy screens get worse while writes still feel fine, you have a good reason to split.
Which read workloads usually cause trouble first?
Reports, filtered search, dashboards with many widgets, and background retrieval jobs usually hurt first. They scan more rows, sort more data, and hold connections longer than normal product screens.
Does search need its own service?
Split search when it touches far more rows than the page returns or when filters and partial text matching make response times jump. If search starts competing with checkout, login, or account pages, move it out before it drags the rest of the app down.
Should I move writes when I split reads?
No. Keep writes on the primary database for the first step. Let the new service read from a replica, cache, or search index so you avoid data ownership problems and messy rollback work.
What should I split first?
Pick the path that costs the database the most and annoys the fewest users if data lags a bit. Reports and exports often win because they run heavy queries and people can usually accept data that is a little behind.
How much lag is okay on a read replica?
Most teams start with seconds or a few minutes, not hours. Set one clear rule for each screen, such as dashboard data can lag by 60 seconds, and make sure support and product use the same wording.
How do I know the split actually helped?
Measure the main app first. Check response time on user actions, slow query count, database CPU, connection pressure, and error rate before and after the split. If those numbers stay flat, the move did not fix the real problem.
What mistakes create more pain during a split?
Avoid moving reporting, search, and retrieval at the same time. Also avoid changing the API response while you change the storage path. One narrow move with a feature flag and fast rollback gives you cleaner results and fewer surprises.
Can a small team do this without a big rewrite?
Yes, if you keep the first move small. Copy one heavy read path, keep the response shape the same, route a small slice of traffic, and watch for mismatches. You do not need a full rewrite to prove the idea.
What early warning sign should I watch for?
If support hears the same complaint at the same time every day, pay attention. Phrases like "exports make everything hang" or "the dashboard gets slow every afternoon" usually point to a read path that no longer belongs on the main database.


