Человеческая проверка в федеративных потоках ИИ: где вмешаться
Узнайте, как организовать человеческую проверку в федеративных потоках ИИ в тех местах, где модели расходятся во мнениях, чтобы остановить ошибочные выводы до их распространения по инструментам и командам.
Содержание
Почему поздняя проверка не работает
Многие команды ставят человека в самый конец процесса. Кто‑то читает финальное сообщение, одобряет его и считает, что этого достаточно. В федеративных рабочих процессах ИИ это часто слишком поздно.
Федеративный поток состоит из нескольких шагов. Одна модель сортирует запрос, другая вытягивает данные, третья пишет ответ, а ещё одна обновляет запись или запускает действие. Если первый шаг пошёл неправильно, всё что идёт после может выглядеть аккуратно, но оставаться неверным.
Возьмём поддержку клиентов. В тикете написано: «Мне выставили двойной платёж, нужен возврат». Модель маршрутизации отправляет запрос в общий биллинг вместо срочного отдела платежей. Модель ответа пишет вежливый, но бесполезный ответ. Обновление CRM помечает дело как решённое. Когда человек проверяет финальный ответ, клиент уже ждал, запись неверна, и команде приходится переоткрывать кейс.
То же самое случается при маршрутизации документов. Если модель отправляет договор не в ту ветку согласования, люди комментируют не ту версию, сохраняют её в неправильную папку и пропускают дедлайн. Поздний ревьювер может заметить итоговую ошибку, но ему всё равно придётся убирать последствия.
С ценообразованием риск ещё выше. Если одна модель выбрала неправильный тариф клиента, следующий шаг может сгенерировать неверную цену, залогировать неправильную маржу и отправить неверные числа в отдел продаж. Одно плохое решение распространяется, потому что последующие шаги доверяют предыдущим.
Поэтому поздняя проверка обходится дороже простого исправления. Команды переделывают работу, которая уже прошла через систему. Клиенты получают смешанные сообщения. Внутренние записи перестают соответствовать реальности. Руководители тратят время на распутывание случаев вместо улучшения процесса.
Проверка работает лучше, когда её ставят до того, как плохие предположения превратятся в действия, записи и сообщения клиентам. Как только ошибка распространяется, финальное одобрение превращается в уборку мусора.
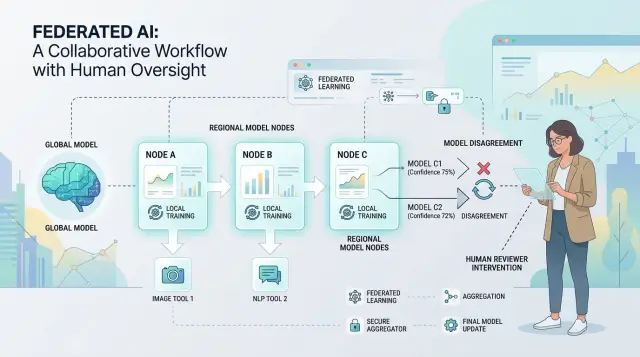
Как выглядит федеративный AI-поток
Федеративный поток — это цепочка небольших решений. Одна модель читает ввод, другая решает, куда его отправить, третья подготавливает ответ, а инструмент или движок правил проверяет, безопасно ли использовать результат. Вместо одной системы, выполняющей всё, несколько моделей и инструментов делят работу.
Такая схема распространена, потому что реальная работа требует не только генерации текста. Командам нужны маршрутизация, поиск данных, проверки и какое‑то финальное действие — отправка сообщения, создание тикета или обновление записи.
Простой поток обычно включает пять частей: ввод, маршрутизация, составление черновика, проверка и действие. На бумаге каждый шаг выглядит безобидно. Слабое место — передача. Когда один инструмент передаёт работу следующему, он может урезать контекст, сместить смысл или добавить плохое предположение.
Модель маршрутизации может пометить вопрос о биллинге как мошенничество. Модель составления ответов затем пишет не тот тип ответа. Проверяющая система может проверять только тон и формат, поэтому плохое решение проходит и становится действием.
Представьте письмо: «Мы заплатили дважды. Можете вернуть один счёт?» Первая модель может пометить это как общий финансовый запрос. Следующая модель составляет вежливый ответ, но пропускает, что отправитель просил именно возврат, а не копию квитанции. Последняя автоматизация создаёт задачу низкого приоритета вместо отправки тому, кто может проверить статус оплаты.
Полезно думать о потоке как о эстафете. Каждый бегун хорошо выполняет свою часть, но каждый передачный момент — это место, где послание может смещаться. Если вы наблюдаете только финиш, вы пропускаете момент, где ошибка вошла в цепочку.
Где начинается расхождение
Обычно расхождение проявляется раньше, чем команды ожидают. Оно начинается, когда одна модель читает тот же ввод и видит другой путь, чем другая модель — задолго до того, как кто‑то заметит плохой итоговый ответ.
В федеративном потоке это легко пропустить. Одна модель классифицирует запрос, другая вытаскивает контекст, третья пишет ответ. Если первые две уже расходятся, последняя модель всё ещё может выдать отшлифованный ответ, построенный на неверной основе.
Проблему обычно можно заметить в нескольких местах. Две модели по‑разному ранжируют следующее действие. Одна модель показывает низкую уверенность, а другая звучит уверенно. Метки конфликтуют, например «вопрос по биллингу» против «безопасность аккаунта». Или одна модель запрашивает контекст, который другая проигнорировала.
Пример с ранжированием особенно важен. Если Модель A ставит «возврат» на первое место, а Модель B — «проверка на мошенничество», система не решает проблему формулировки. Она выбирает между разными бизнес‑действиями.
Поэтому расхождение часто важнее средней точности. Модель может хорошо показывать себя в тестах и при этом провалиться в тех случаях, которые обходятся дорого — в деньгах, доверии или времени. Точность показывает, как часто модель правильно пометила данные задним числом. Расхождение показывает, что система сейчас не уверена, на реальном кейсе, прежде чем ущерб распространится.
Отсутствие контекста делает ситуацию хуже. Одна модель может делать выводы только по последнему сообщению, в то время как другая смотрит на историю клиента и приходит к другому выводу. Этот конфликт полезен: он говорит, что рабочий процесс пока не имеет стабильного взгляда на дело.
Пример в поддержке проясняет это. Пользователь пишет: «Мне выставили двойную оплату, и теперь я не могу войти в аккаунт». Одна модель считает это проблемой оплаты. Другая — возможным захватом аккаунта. Если ждать до этапа финального ответа, система может отправить аккуратно сформулированное письмо о возврате и пропустить риск безопасности.
Люди дают наибольшую ценность именно на этих границах. Когда модели расходятся в ранжировании, метках или требуемом контексте, человек может принять одно чёткое решение и разблокировать остальную часть потока. Это занимает меньше времени, чем проверять каждый финальный ответ, и ловит проблемы, пока систему ещё можно перенаправить.
Как размещать точки проверки
Начните с простого плана рабочего процесса. Нарисуйте каждый шаг на одной странице от первого ввода до финального действия: приём, классификация, извлечение данных, составление, оценка, маршрутизация, одобрение и выполнение. На такой карте проблема обычно видна сразу. Команды часто наблюдают только финальный ответ и игнорируют ранний шаг, который направил работу по неправильному пути.
Далее отметьте шаги, которые могут изменить что‑то реальное. Неровное резюме обычно не требует человека. А списание денег, редактирование записи, отправка сообщения клиенту или перемещение задачи в очередь с повышенным приоритетом — часто требуют.
Затем ищите расхождения, которые меняют ветвь. Не каждая разница важна. Если две модели спорят о формулировке, но выбирают один и тот же маршрут, скорее всего, чекпоинт не нужен. Если одна говорит «риск мошенничества», а другая — «обычный возврат», он нужен.
Простой тест помогает:
- Изменит ли этот шаг деньги?
- Обновит ли он данные, на которые опираются люди?
- Увидит ли это клиент?
- Изменит ли он срочность, владение или следующий рабочий поток?
Если ответ «да», задайте ещё один вопрос: может ли расхождение моделей изменить то, что произойдёт дальше? Если может — шаг заслуживает контрольной точки.
В потоке поддержки это видно легко. Одна модель читает сообщение, другая проверяет историю аккаунта, третья пишет ответ. Точка проверки не должна стоять только на финальном черновике, она должна быть раньше — там, где система решает между «возвратом», «технической проблемой» и «возможным злоупотреблением». Эта ветвь определяет сообщение, очередь и обновление записи.
Держите развертывание небольшим. Добавьте одну контрольную точку, измерьте, что она ловит, и посмотрите, достаточно ли часто это меняет следующую ветвь, чтобы оправдать задержку. Если нет — уберите её. Команды, проверяющие всё подряд, создают медленную работу и утомлённых ревьюеров. Команды, проверяющие критические ветви, ловят ошибки, которые действительно стоят денег, доверия или времени.
Сигналы, которые должны вызывать вмешательство человека
Лучшие точки проверки основаны на понятных сигналах, а не на интуиции. Человек должен подключаться, когда система показывает сомнение, когда части потока расходятся, или когда действие может причинить реальный вред.
Четыре сигнала хорошо работают в большинстве команд:
- Небольшой разрыв в оценках между опциями, когда лидер едва опережает следующую
- Низкая уверенность в финальной метке, резюме или решении
- Конфликт правил, например модель говорит «одобрить», а правило политики — «заблокировать»
- Отсутствие данных: нет истории аккаунта, отсутствует исходный документ или поля не совпадают
Эти сигналы важнее для действий, чем для черновиков. Если система пишет внутреннюю заметку или первичное резюме, часто можно позволить ей продолжить с пометкой‑предупреждением. Если речь идёт о юридическом сообщении, возврате денег, смене доступа к аккаунту или публикации для клиентов — отправляйте на проверку человеку первым.
Сначала держите пороги простыми. Можно проверять всё с уверенностью ниже 0.70, любые случаи, где две модели отличаются менее чем на 5%, или любой результат, нарушающий бизнес‑правило. Эти числа не обязаны быть идеальными в первый день. Они должны быть достаточно понятными, чтобы тестировать, а потом корректировать через несколько недель реальной работы.
Запишите путь проверки простым языком. Назовите, кто ревьюит каждый тип кейса, как быстро они должны реагировать и что могут отменять. Руководитель поддержки может подтверждать низкорисковые ответы клиентам за 30 минут. Финансовый менеджер должен одобрять изменения платежей до их отправки.
Важна ответственность. Если у очереди нет владельца, ревью превращается в задержку. Если ревьюеры не могут отменить неправильный вызов модели, ревью становится показухой.
Простой пример из поддержки клиентов
Клиент пишет после того, как заметил, кажется, двойной платёж. В федеративном потоке поддержки одна модель занимается триажем, другая пишет краткое резюме, третья готовит ответ, а четвёртая подготавливает обновление CRM. Такая цепочка экономит время, но она же создаёт точку, где небольшая ошибка может быстро распространиться.
Модель триажа видит «charged twice» и двигает кейс в сторону возврата. Она видела много таких тикетов и хочет быстро решить проблему. Вторая модель проверяет политику и сигнализирует проблему: одна из оплат, скорее всего, предварительная авторизация, а не завершённый платёж, так что поддержке стоит сверить статус оплаты перед тем, как обещать деньги обратно.
Если здесь никто не вмешается, остальной поток продолжит работу. Черновик ответа может сообщить клиенту, что возврат уже оформляется. CRM может записать «возврат одобрен». Другая система может поставить задачу финансам. В этот момент одна неверная догадка превратилась в три плохие записи и обещание, которое команде придётся отменять.
Именно тут имеет смысл человеческая проверка. Поместите ревьюера между местом расхождения и действиями, которые меняют деньги или историю клиента.
Человек часто решает это меньше чем за минуту. Он проверяет статус платежа, подтверждает, реальна ли вторая транзакция, и выбирает один путь: одобрить возврат, запросить проверку по биллингу или отправить другой ответ.
Короткая пауза предотвращает гораздо более длительную уборку позже. Без неё команде придётся править CRM, отменять запрос на возврат, отправлять сопроводительное извинение и объяснять клиенту смешанные сообщения. Одно ревью в точке расхождения стоит намного дешевле, чем исправление четырёх последующих ошибок.
Именно этот шаблон стоит тиражировать. Проверяйте до возврата и до обновления записи, а не после того, как клиент и ваши внутренние системы уже поверили в неверную информацию.
Ошибки, которые допускают команды
Самая распространённая ошибка — проверять всё подряд. Это звучит безопасно, но быстро создаёт узкое место. Ревьюеры устают от простых кейсов, кликают их поверхностно и пропускают случаи, требующие суждения.
Ещё одна ошибка — ставить ревью в самый конец. Если одна модель пишет письмо, другая обновляет CRM, а третья запускает возврат, поздняя проверка уже не предотвратит ущерб. Она будет заниматься его устранением.
Эта очистка быстро становится сложной. Неверное сообщение может уже оказаться в почтовом ящике клиента. Плохие данные могут храниться в двух системах. Исправление одной ошибочной меры может занять гораздо больше времени, чем её предотвращение.
Неясные правила — следующая проблема. Команды часто говорят: «отправляйте нестандартные случаи человеку», но никто не определяет, что значит «нестандартный». Ревьюер не может работать с расплывчатым правилом, и рабочий поток не сможет правильно маршрутизировать кейсы без порога.
Чёткие триггеры работают лучше, чем широкие метки. Кейс должен идти человеку, когда две модели расходятся по следующему действию, доверие падает ниже заданного уровня, действие меняет данные клиента, сумма возврата или юридический риск велики, или не хватает контекста.
Ещё одна ошибка — считать ревью тупиковой операцией. Ревьюеры исправляют выводы, но команда никогда не превращает эти исправления в лучшие подсказки, правила маршрутизации или защитные механизмы. Тогда та же ошибка вернётся на следующей неделе, и очередь ревью будет расти.
Это видно по паттерну. Ревьюеры постоянно правят одни и те же формулировки, сопоставления полей или выбор эскалации. Это не работа ревьюера — это работа системы.
Хорошие точки проверки остаются малыми, ранними и точными. Если команда не может объяснить, почему кейс попал к человеку, одной фразой — правило, вероятно, слишком расплывчатое.
Как держать ревью небольшим и полезным
Ревью становится дорогим, когда люди читают слишком много и решают слишком мало. Экран должен отвечать на один вопрос быстро: нужен ли этому кейсу выбор человека и если да — какой?
Большинство очередей засоряется потому, что команды бросают полную трассировку в интерфейс. Это замедляет людей. Ревьюеру обычно не нужна история подсказок, число токенов или каждая ветка рабочего процесса. Ему нужен ввод клиента, соперничающие выводы и короткая причина, почему система остановилась.
Лёгкий экран ревью обычно показывает только поля, связанные с решением, сигнал расхождения простым языком, выводы моделей рядом и действия, которые может выполнить ревьюер.
Этого достаточно для большинства случаев. Если две модели спорят о праве на возврат, покажите детали заказа, соответствующий фрагмент политики и два ответа. Не заставляйте ревьюера рыться во всех логах, чтобы понять, почему кейс попал к нему.
Группировка тоже помогает. Если десять кейсов имеют один и тот же паттерн, дайте одному человеку вернуть их пачкой. Люди работают быстрее и последовательнее, когда принимают один и тот же тип решения подряд. В поддержке и операциях повторяющиеся крайние случаи могут съесть полдня.
Здесь же проявляется смысл бережных AI‑операций. Малые команды лучше, когда ревью выглядит как триаж, а не расследование. Средний кейс должен занимать секунды, а не минуты.
Нужна также еженедельная проверка нагрузки ревью. Считайте, сколько кейсов каждая контрольная точка отправляет людям, сколько времени занимает их обработка и как часто ревьюер меняет результат. Если точка посылает много кейсов, но ревьюеры почти никогда не переопределяют систему — обрежьте её или удалите. Если маленькая точка ловит дорогие ошибки — оставьте.
Если вы строите такой процесс с нуля, внешний аудит может помочь. Oleg Sotnikov на oleg.is работает со стартапами и небольшими компаниями над AI‑ориентированной разработкой и дизайном рабочих процессов, включая места для человеческих контрольных точек, чтобы команды оставались быстрыми без потери контроля над рискованными решениями.
Быстрая проверка перед запуском
Хорошая предзапусковая проверка проста: может ли система приостановить высокоимпактное действие до того, как плохое решение превратится в реальное действие? Если поток может отправить сообщение, обновить запись, списать деньги или эскалировать кейс, пока люди «проверяют» его, значит ревью слишком поздно.
Ревьюерам нужен контекст, а не таинственная очередь. Флаг должен показывать причину простым языком, например: «классификатор намерения говорит возврат, модель политики — риск мошенничества» или «парсер адреса и модель биллинга расходятся по идентичности клиента». Если человеку придётся открыть пять инструментов, чтобы догадаться, что произошло, он поспешит или пропустит проверку.
Короткий предзапусковой чеклист ловит большинство слабых мест:
- Поток может остановить действия с высоким эффектом до одобрения человека
- Экран ревью показывает, почему кейс помечен и что сказали модели
- Логи показывают, какая модель расходится, по какому полю и на каком шаге
- Пороги соответствуют стоимости ошибки, а не желанию команды иметь меньшую очередь
Последний пункт важнее, чем многие думают. Ошибка низкого риска в теге продукта может вовсе не требовать ревью. Возможный дубликат списания, блокировка аккаунта или юридическая эскалация должны останавливаться быстро, даже если модели расходятся лишь немного.
Прогоните несколько «уродливых» тестовых кейсов перед запуском. Используйте примеры с противоречивыми сигналами, отсутствующими данными и реальными пограничными случаями. Затем задайте простой вопрос: как далеко это может уйти, прежде чем человек это увидит?
Если ответ — «сначала увидит клиент», — конфигурация требует доработки.
Что делать дальше
Начните с малого. Выберите одну ветвь, где неправильное решение стоит денег — например одобрение возврата, классификация документов или эскалация тикета. Затем установите один триггер ревью: например расхождение моделей выше порога или низкая уверенность в рисковом кейсе.
Не разбрасывайтесь по всему потоку в первый день. Одна ветвь даст достаточно данных, чтобы понять, что ломается, что замедляет и что люди делают быстрее, чем модели.
Отслеживайте небольшой набор метрик первые пару недель: ложные срабатывания, пропущенные кейсы, среднее время ревью на кейс и общий объём ревью в день. Эти числа покажут, оправдывает ли контрольная точка своё место.
Если время ревью растёт, а число пропущенных кейсов остаётся прежним — триггер, вероятно, слишком широк. Если ревьюеры постоянно ловят одну и ту же проблему — система говорит вам, где нужна постоянная правка.
Не оставляйте повторяющиеся решения навсегда в руках людей. Превратите стабильные выборы ревьюеров в правила маршрутизации, правки подсказок, изменение порогов или простую проверку валидации. Человеческая проверка работает лучше, когда люди учат поток тому, что ловить в следующий раз.
Дайте ревьюерам одно короткое поле для заметки при переопределении. Фраза вроде «неверный интент, маршрутизировать в биллинг» или «клиент просил отмену, а не возврат» часто достаточно, чтобы после нескольких дней выявить паттерн.
И если вам нужен второй взгляд перед добавлением новых моделей, ветвей или автоматизаций, Oleg Sotnikov может провести аудит рабочего процесса, найти рискованные точки решений и помочь сделать систему жёстче, не превращая ревью в узкое место.


