Частный CI в изолированной сети: как запускать сборки без публичного облака
Частный CI держит сборки, секреты и логи внутри ограниченных сетей клиента. Узнайте о размещении раннеров, пути артефактов и шагах утверждения.
Содержание
Почему публичный облачный CI здесь не подходит
Частный CI обычно не опция — это требование политики. Некоторые клиенты запрещают внешние сервисы сборки, потому что как только публичный раннер получил репозиторий, код компании выходит из сети.
На этом политика редко останавливается только у исходников. Логи сборки могут раскрыть внутренние имена хостов, названия пакетов, флаги фич и данные клиентов. Переменные окружения, ключи подписи, тестовые данные и учётные данные для деплоя добавляют ещё больше риска.
Простой пример показывает проблему. Клиент хранит код на внутреннем сервере GitLab внутри частной сети, и в его правилах сказано, что код, секреты и логи должны оставаться там. Публичный CI ломает это правило ещё до первого теста, даже если у поставщика сильное шифрование и жёсткие права доступа.
Команды по комплаенсу заботятся и о прослеживаемости. Им важно знать, кто запустил сборку, какой коммит попал в неё, какие секреты использовались в задаче и кто утвердил релиз. Публичные CI-продукты могут фиксировать часть этих данных, но многие клиенты всё равно их отклоняют, потому что записи хранятся вне их контролируемых систем.
Командам при этом нужны быстрые сборки. Продуктовая работа не останавливается из‑за строгих правил безопасности. Если разработчики ждут часами ручных проверок или нужно кому‑то запускать скрипт на jump‑хосте, релизы замедляются и мелкие ошибки проскальзывают.
Здесь и возникают адхок‑скрипты сборки. Один инженер держит папку с shell‑скриптами, другой копирует артефакты вручную, и в итоге нет чистого аудита. Когда что‑то ломается, команда не может ответить на базовые вопросы вроде того, какая зависимость изменилась или какой бинарник действительно попал в прод.
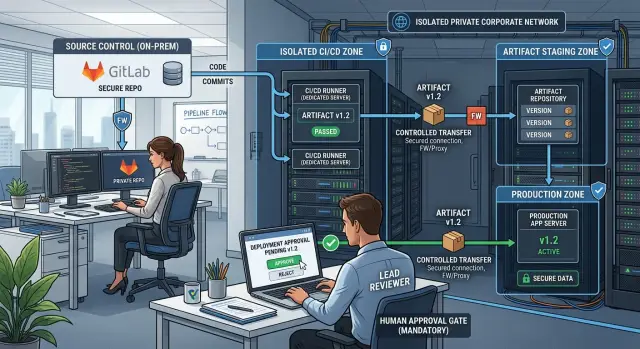
Лучшее решение простое: держать систему сборки внутри того же контролируемого окружения, где лежит код. Если код, секреты и логи должны оставаться в сети клиента, раннеры тоже должны быть там.
Как выглядит практичная конфигурация
Хорошая настройка приватного CI скучна в лучшем смысле слова. Задачи выполняются там, где нужно, артефакты проходят по небольшому числу контролируемых путей, и за каждым релизом стоит ясное решение.
Размещайте раннеры близко к коду, зеркалам пакетов и секретам, которые им нужны. Если репозиторий живёт внутри сети клиента, основные раннеры сборки тоже должны быть там. Это снижает число исключений в брандмауэре, ограничивает распространение секретов и облегчает трассировку ошибок.
Не просите один раннер делать всё. Раннеры сборки должны компилировать код и создавать пакеты в зоне разработки. Раннеры для тестов должны запускать автоматические проверки без доступа к ключам подписи. Отдельные раннеры для подписи располагаются в более строгом сегменте и подписывают только утверждённые артефакты. Раннеры релиза публикуют только те артефакты, которые уже прошли предыдущие проверки.
Команды безопасности обычно одобряют такую структуру, потому что её легко объяснить. Код поступает в одно место, артефакты движутся по контролируемым шагам, а креденшелы продакшна остаются в минимально необходимой зоне.
Держите границы простыми для объяснения
Если границу приходится объяснять десять минут на доске — она, вероятно, слишком запутанная. Большинству команд хватает трёх зон: зона разработки, зона подписи и зона релиза. У каждой зоны должен быть небольшой набор задач, назначенный владелец и одна ясная причина для доступа.
Движение артефактов должно быть однонаправленным, когда это возможно. Задачи сборки должны пушить результаты в внутреннее хранилище артефактов, а последующие этапы тянуть оттуда. Прямое копирование раннер→раннер труднее аудировать, и люди быстро теряют понимание, откуда взялся файл.
Сделайте утверждения частью системы
Утверждение релиза должно происходить в той же системе, которая отслеживает пайплайн. Фиксируйте, кто продвинул артефакт, когда это сделал, какой коммит был утверждён и какой хэш артефакта перешёл дальше. Если клиент требует двух человек для утверждения продакшна, применяйте это правило в пайплайне, а не на устных договорённостях.
Именно это делает изолированные раннеры практичными. Настройка не должна быть навороченной — ей нужны простые зоны, узкие права и след релиза, который никто не придётся восстанавливать потом.
Куда размещать изолированные раннеры
Для частного CI самый безопасный дефолт прост: ставьте раннеры внутри сети каждого клиента, рядом с кодом, зеркалами пакетов и внутренними сервисами. Если у клиента есть отдельные окружения, держите раннер в той же зоне, где выполняется работа. Раннер сборки, которому нужны исходники и тестовые данные, не должен стоять в широком административном сегменте просто потому, что его так легче достать.
Это решение улучшает не только безопасность. Сборки обычно идут быстрее, когда раннеры тянут зависимости из локальных зеркал и пушат артефакты в внутреннее хранилище по коротким путям. Оно также устраняет многие странные отказы, вызванные брандмауэрами, прокси‑правилами или временными проблемами кросс‑сети.
Разделяйте пул раннеров
Не используйте одну группу раннеров для всего. Ежедневные сборки и тесты можно запускать на общих внутренних раннерах с жёсткими лимитами. Релизные задания требуют меньшего и более контролируемого пула. Эти релизные раннеры должны находиться в защищённом сегменте, принимать только помеченные или утверждённые пайплайны и заниматься подписью или финальной упаковкой только после явного одобрения конкретного человека.
Такое разделение поддерживает рутину и усложняет неправильное использование путей релиза. Если обычный раннер упал, вы теряете время; если тот же раннер ещё и публикует в прод, риск намного выше.
Права доступа должны быть узкими. Раннеру редко нужны широкие админ‑права. Дайте ему право получить репозиторий, скачать зависимости, писать логи и публиковать артефакты в одном одобренном месте. Если задаче нужны секреты — передавайте только те секреты, которые нужны для этого этапа. Не давайте раннеру доступа к файловым шарингам, управлению серверами или продакшн‑БД, если это действительно не требуется.
Размер машины важнее, чем думают команды. Сборки, нагруженные на CPU, хотят больше ядер, чем памяти. Крупные тест‑сюиты обычно нуждаются в быстром диске и достаточном объёме RAM. Мобильные или большие frontend‑сборки часто требуют локального кэширования. Релизные раннеры нуждаются в предсказуемой производительности больше, чем в чистой скорости.
Как безопасно перемещать артефакты
В частном CI доверие часто рушится во время передачи артефактов. Перемещайте релизный пакет, который сгенерировал раннер, а не весь workspace вокруг него.
Полный workspace несёт слишком много хлама: кэши, временные файлы, локальные логи, тестовые данные и иногда секреты. Если раннер собирает приложение, экспортируйте подписанный бинарник, пакет или контейнер‑образ и выбрасывайте остальное. Небольшие фиксированные выходы гораздо проще аудировать, чем гора оставшихся файлов.
Используйте один шлюз передачи
Применяйте одну контролируемую точку передачи между сетями. Это может быть внутренний репозиторий артефактов, промежуточный хост на границе или иной одобренный механизм передачи. Открытые сетевые шаринги стареют плохо: никто ими не владеет, их никто не чистит, и доступ со временем разрастается.
Перед тем как файл пересечёт этот шлюз, просканируйте его. Запустите проверку на вредоносный код, проверку типа файла и простые политики — лимиты по размеру или запрещённые расширения. Если команда подписывает выходы сборки, перепроверьте подпись на границе, не полагаясь на то, что исходная сторона всё сделала правильно.
Каждый артефакт должен путешествовать с короткой записью, которую можно прочитать без рыться в логах раннера. Включите хэш файла, время сборки, ревизию источника, идентификатор раннера или сервисного аккаунта, который опубликовал его, и дату удержания с указанием владельца удаления.
Эта запись выполняет две задачи. Она доказывает, что файл в тесте или проде совпадает с тем файлом, который ушёл из зоны сборки. И она помогает держать хранилище под контролем — это часто важнее, чем команды ожидают.
Правила доступа должны быть жёсткими. Разрешите CI публиковать. Разрешите утверждённым пользователям или задачам деплоя тянуть. Право удалять дайте очень маленькой группе. Если удалить может каждый, кто‑то случайно подчистит не тот файл в загруженный пятничный вечер.
Простой паттерн работает хорошо. Изолированный раннер собирает подписанный пакет и пушит его в граничный репозиторий. Граничный хост сканирует его, сохраняет хэш и отметку времени, и ждёт утверждения. После этого целевая сеть тянет именно этот файл. Ничего лишнего не пересекает границу, и никто не должен доверять общей папке, полной загадочных файлов.
Управление утверждениями, которым люди будут следовать
Команды в закрытых сетях обычно не нуждаются в дополнительной автоматизации в самом конце. Им нужен ясный пауз перед продакшном. Сборки и тесты могут идти автоматически, но продвижение в прод должно ждать человеческого одобрения каждый раз.
Это утверждение должно происходить после появления артефакта. Команда утверждает не ветку или смутную задачу, а один конкретный билд для одной конкретной цели. Это небольшое изменение предотвращает множество ошибок.
Код‑ревью и утверждение релиза должны оставаться раздельными. Рецензент проверяет изменение до merge. Утверждающий релиза решает, следует ли этому конкретному артефакту идти в окружение прямо сейчас. Это разные роли. Один человек не должен тихо делать и то, и другое, кроме как в совсем маленькой команде без альтернатив.
Хороший экран утверждения должен показывать хэш коммита, ветку или тег, идентификатор артефакта или контрольную сумму, целевую среду, кто ранее утвердил билд в пайплайне, и версию для отката, готовую к использованию. Если чего‑то не хватает, люди начинают утверждать по памяти, сообщениям в чатах или заголовкам тикетов — и контроль исчезает.
Небольшой пример делает это конкретным. Разработчик смёрджил фикc в среду. Тесты прошли, и раннер выпустил артефакт build-4182. В пятницу вечером релиз‑менеджер видит, что build-4182 пришёл из коммита a41c9f, целится в prod-eu и имеет готовый пакет для отката. Он утверждает этот конкретный релиз. Он не утверждал «последнюю сборку».
Обходы на экстренные случаи должны иметь жёсткие ограничения. Дайте такое право очень небольшой группе. Заставьте обход истечь после использования и потребуйте от человека указать причину. Затем логируйте время, пользователя, тикет, коммит, артефакт и окружение. Если обход остаётся без следа, люди начнут обращаться к нему как к нормальному пути.
Лучший поток утверждения немного строг и немного скучен. Если посмотреть, что пойдёт в прод, можно за минуту — люди будут им пользоваться. Если это бумажная волокита, они найдут обход.
Внедрение по шагам
Частный CI обычно ломается, когда команда пытается перестроить весь процесс доставки за один проход. Меньшие пошаговые внедрения работают лучше. Выберите один путь релиза, ограничьте объём и докажите, что он работает, прежде чем копировать его на другие репозитории.
Начните с того, что нарисуйте текущий путь на одной странице. Покажите, где лежит код, какие сетевые зоны он пересекает, где сейчас выполняются сборки, куда попадают артефакты и кто утверждает релиз. Это быстро выявит неудобные места, особенно ручные копии файлов и скрытые шаги утверждения, которые помнит только один человек.
Выберите один репозиторий, который часто деплоится, но не повредит бизнесу, если релиз задержится на день. Один сервис — достаточно. Одна политика ветки — достаточно. Если ваша команда может собрать, протестировать, подписать, передать и выпустить этот единственный сервис внутри частной сети, у вас есть шаблон на повтор.
Разверните раннеры в зонах, где должна происходить работа. В большинстве случаев это означает отдельный изолированный раннер для сборки и другой для тестов, каждый с минимально необходимыми правами. Держите права простыми и строгими. Раннер сборки не должен деплоить. Шаг деплоя не должен компилировать код.
Затем зафиксируйте путь артефактов. Дайте каждому артефакту контрольную сумму, версию и ясное место назначения. Если файл переходит из зоны сборки в staging, сделайте этот перенос явным и залогированным. Если вы подписываете релиз‑артефакты, проверяйте подпись до приёма на следующем этапе. Звучит придирчиво, но это экономит часы, когда кто‑то спросит: «А какой именно файл мы выпустили?»
Добавляйте ворота утверждения только там, где люди и так их ожидают: перед staging для чувствительных изменений и перед продом для каждого релиза. Держите шаг утверждения коротким: одно решение, один владелец, одно зафиксированное действие. Если утверждение требует десяти кликов, люди найдут обход.
Напишите плейбук на случай отказа заранее
Короткие рукбуки полезно писать, пока настройка ещё свежа. Описывайте первые по‑порядку отказы: раннер офлайн, зеркало пакетов недоступно, проверка передачи провалилась, несоответствие подписи, блокировка утверждения. Хороший плейбук подскажет, где логи, кто может утвердить повторную попытку и когда эскалировать.
Первый узкий rollout даст вам не просто диаграмму — он даст путь релиза, которым люди смогут пользоваться в обычный вторник.
Простой пример клиента
Поставщик ПО поддерживает внутренний инструмент отчётности для банка. Разработчики вендора пишут код и запускают локальные проверки в своей офисной сети, как любая продуктовая команда. Банк же не разрешает сборки на публичных сервисах. Всё, что компилирует релизный код, должно оставаться в приватном сегменте банка.
Это меняет форму пайплайна. Вендор сохраняет повседневную разработку у себя, но банк хостит раннеры. Когда разработчики готовят релиз, они не присылают готовый пакет в банк. Они отправляют проверенный снимок исходников через узкую контролируемую трассу, которую держит банк.
Раннеры банка стоят на системах без общего доступа в интернет. Они могут обращаться только к небольшому набору внутренних сервисов: зеркалу репозитория, кэшу пакетов и сервису подписи. Среда сборки намеренно скучная — и в этом смысл.
Нормальный релиз может выглядеть так. Разработчик тегирует версию и создаёт запрос на релиз. Сервис передачи тянет этот точный коммит, сканирует его и сохраняет хэши. Изолированный раннер собирает пакет внутри сети банка. Сервис передачи перемещает артефакт в staging для проверки. Менеджер релиза затем утверждает прод из отдельной консоли.
Этот последний шаг предотвращает распространённую проблему. Разработчики могут подготовить и запросить релиз, но не могут утвердить свой собственный деплой в прод. Релиз‑менеджеры могут утвердить или отклонить, но не могут изменить код. У каждого своя роль, и тропа аудита остаётся читаемой.
Если банк позже спросит: «Что именно было запущено во вторник?», команда ответит одним набором записей: ID коммита, хэши артефактов, результаты сканов, лог сборки и имя утвердившего. В регулируемых средах это важнее, чем чистая скорость.
Да, такая схема добавляет задержку. Релиз может занять на двадцать минут дольше, чем на публичном CI. Большинство банков считают эту цену приемлемой, если код остаётся в одобренных путях и каждая производственная правка имеет чистый след.
Ошибки, которые замедляют команды
Большинство задержек в частном CI возникает не из‑за сети, а из‑за процессных решений, которые поначалу кажутся приемлемыми, а затем съедают часы.
Одна распространённая ошибка — просить один изолированный раннер делать всё. Сборки, тесты, упаковка и срочные фиксы ждут в одной очереди. Вскоре одна медленная сборка тормозит всех, и команда начинает воспринимать задержку как норму.
Дальше часто ломается обращение с артефактами. Если люди пересылают файлы в чатах, по почте или клепают ad‑hoc шаринги, никто не знает, какой пакет одобрен. Файл переименовывают, копируют дважды или заменяют на более новую сборку — и след аудита теряется.
Правила утверждения могут создать узкие места. Если одна старшая фигура должна утверждать каждый релиз, это работает, пока она не спит, не в отпуске или не в совещании. Тогда люди ищут обходы.
Логи важнее, чем кажется. Если система не фиксирует, кто собрал артефакт, кто переместил его в ограничённую зону и кто утвердил деплой, каждый инцидент превращается в догадки. Память людей различается, и это тормозит расследование.
Тестовые данные создают ещё одну тихую проблему. Команды часто копируют реальные данные в защищённые окружения ради скорости тестирования. Этот шаг может протолкнуть записи клиентов, секреты или внутренние бизнес‑данные в места, где им не место.
Несколько привычек предотвращают большую часть беды. Разделяйте раннеры по типам задач и уровню доверия. Перемещайте артефакты через один контролируемый путь. Назначайте роли утверждения с резервами, а не одного человека. Логируйте каждую передачу и каждое решение о релизе. Используйте маскированные или синтетические данные для тестов.
Частный CI работает лучше всего, когда безопасный путь ещё и простой. Если одобренный путь медленный и неудобный, команды начнут изобретать свои обходы.
Быстрая проверка перед развёртыванием
Большинство проблем с частным CI начинаются с мелких дыр, а не с больших архитектурных ошибок. У раннера нет владельца, токен не ротаируется или артефакт попадает в правильное место без доказательства происхождения — такие дыры молчат до провала релиза в шесть вечера.
Если хотите, чтобы настройка оставалась скучной, сначала проверьте владение и прослеживаемость. Система сборки внутри приватной сети должна быстро отвечать на пять простых вопросов: кто владеет этим раннером, какой секрет он использует, какой артефакт переместился, кто утвердил релиз и что случилось при сбое передачи.
Дайте каждому раннеру именованного владельца, а не только название команды. Включите план ротации для каждого секрета с датой, ответственным и путём замены. Прикрепите контрольную сумму и правило удержания к каждому артефакту. Назначьте резервного утвердителя для каждого шага релиза. Заставьте неудачные передачи оставлять читаемый трейс с именем артефакта, временной меткой, источником, назначением и понятным сообщением об ошибке.
Правило контрольных сумм важнее, чем ожидают многие команды. Если один раннер собрал пакет, а другой сегмент сети получил его, нужен быстрый способ доказать целостность файла. Это занимает несколько минут и может сэкономить часы споров.
Правила утверждения тоже требуют реалистичной проверки. Если рабочий процесс зависит от одного security‑лида, который часто оффлайн, люди найдут обход. Наличие основного и резервного утвердителя удерживает контроль без превращения каждого патча в проблему с расписанием.
Читаемые логи отказов — последнее испытание здравого смысла. «Transfer failed» бесполезно. «Checksum mismatch on artifact build-1842.tar at staging gateway» даёт команде то, что можно разгребать.
Следующие шаги для вашей команды
Начните с одного пути доставки, а не с целого парка сервисов. Выберите одно приложение или сервис и проследите путь от коммита до релиза: где код лежит, какие раннеры с ним работают, куда уходит артефакт, кто утверждает продвижение и где люди всё ещё передают файлы вручную. Такая карта обычно показывает реальную узкую точку за час.
Ручная передача файлов — частая отправная точка. Если один инженер скачивает сборку, переименовывает и загружает её куда‑то ещё, у вас уже есть слабое место. Оно замедляет релизы, скрывает исполнителя и усложняет аудит. Замените этот шаг первым на контролируемую передачу артефактов внутри сети клиента.
Пробелы в утверждениях требуют внимания до того, как добавлять больше автоматизации. Команды часто быстро автоматизируют сборки, а решения о релизе оставляют в чатах или на устных согласованиях. Простое правило работает лучше: определите, кто может утверждать, какие доказательства он должен видеть и где фиксируется утверждение. Если никто не может ответить на эти три пункта — остановитесь и исправьте это.
Практичный стартовый план короткий:
- Промапьте путь от коммита до продакшна для одного сервиса.
- Уберите одну ручную передачу артефакта.
- Добавьте ясный шаг утверждения с именованными владельцами.
- Логируйте каждую сборку, передачу и решение о релизе в одном месте.
- Повторяйте шаблон для следующего сервиса.
Держите первый rollout скучным. Вам не нужен идеальный инструмент в первый день. Вам нужен путь, которому люди доверяют и которым можно идти под давлением, особенно при срочных исправлениях.
Если нужна внешняя проверка, Oleg Sotnikov на oleg.is работает с такими настройками как Fractional CTO. Его опыт с self-hosted GitLab‑раннерами и приватной инфраструктурой подходит командам, которым нужна более строгая изоляция раннеров, чистый поток артефактов и правила утверждения, выдерживающие реальный аудит.
Выберите один сервис на этой неделе, помапьте путь и устраните первую неконтролируемую передачу. Обычно это снимает больше трения, чем ещё месяц дебатов.
Часто задаваемые вопросы
Почему некоторые клиенты запрещают публичный CI?
Потому что публичный раннер получает репозиторий, логи и часто секреты за пределами сети клиента. Если политика требует, чтобы код и записи сборок оставались в системах, которыми вы управляете, публичный CI нарушает это правило ещё до завершения задания.
Где должны располагаться изолированные раннеры?
Размещайте каждый раннер в том же сетевом сегменте, где выполняется его работа. Раннеры сборки должны быть рядом с зеркалом репозитория, кэшем пакетов и внутренними сервисами, которые им нужны; раннеры для подписи и релиза — в более жёстком сегменте с ограниченным доступом.
Должен ли один раннер выполнять сборку, тестирование, подпись и релиз?
Нет. Используйте одну группу для обычных сборок и тестов и меньший защищённый пул для подписи и релизов. Такое разделение поддерживает повседневную работу и предотвращает, чтобы скомпрометированный раннер получил доступ к инструментам продакшна.
Что должно пересекать границу между сетевыми зонами?
Перемещайте готовый пакет, бинарник или контейнерный образ, а не всю рабочую директорию. Оставляйте кэши, временные файлы, логи и всё остальное, чтобы было легко отследить один конкретный артефакт.
Как безопасно перемещать артефакты?
Используйте один шлюз передачи — внутренний репозиторий артефактов или граничный хост. Просканируйте файл, сохраните его хэш, запишите, кто опубликовал его, и позвольте следующему этапу вытащить именно этот артефакт после утверждения.
Как должно работать утверждение на продакшн?
Сделайте утверждение коротким и привязанным к одному точному артефакту. Утверждающий должен видеть коммит, идентификатор артефакта или контрольную сумму, целевую среду и версию для отката, а затем одобрить именно этот релиз, а не «последнюю сборку».
Что делать с обходами в экстренных случаях?
Ограничьте права обхода очень небольшой группой и делайте каждый обход однократным: он должен истечь после использования. Записывайте причину, пользователя, время, коммит, артефакт, тикет и целевую среду, чтобы обход не стал обычным путём.
Как вернуть это в продакшен, не перестраивая всё сразу?
Начните с одного сервиса, который часто деплоится, но не нанесёт серьёзного ущерба, если релиз приостановится на день. Помапьте путь контрольно, разместите раннеры в нужных зонах, заблокируйте передачу артефактов и добавьте один понятный шаг утверждения.
Какие записи нужно хранить для каждого артефакта?
Храните хэш файла, исходный ревиз, время сборки, раннер или учётную запись сервиса, дату хранения и утвердившего. Эти данные позволяют доказать, какой файл был выпущен, и сэкономят время при проверках.
Какие ошибки наиболее замедляют частный CI?
Чаще всего — когда один раннер делает всё, люди пересылают файлы вручную, или один человек утверждает всё. Исправьте это в первую очередь: разделяйте раннеры по типу задач и уровню доверия, делайте один контролируемый поток артефактов и назначайте резервных утвердителей.


