Страницы CDN failover, которые помогают сайту оставаться полезным во время сбоев
Страницы CDN failover показывают понятную запасную версию, кэшированный контент и следующие шаги при проблемах у origin вместо пустой страницы ошибки.
Содержание
Что ломается при частичном сбое
Частичный сбой — это хаос. Для посетителя сайт не выглядит полностью недоступным. Он выглядит ненадёжным.
Главная страница может загрузиться из кэша, но поиск ничего не выдаёт. Страница товара открывается, а цены или остатки так и не появляются. Вход в аккаунт может не работать, хотя записи в блоге всё ещё открываются. Шапка и подвал видны, но основной блок крутится, зависает или выдаёт ошибку сервера.
Такое несоответствие быстро сбивает людей с толку. Если бы всё сломалось сразу, большинство посетителей поняли бы, что сайт недоступен, и попробовали бы позже. Когда ломаются только отдельные части, они продолжают кликать, обновлять страницу и гадать, не у них ли проблема.
Пустая страница ошибки только усугубляет ситуацию. Она не даёт ни направления, ни уверенности, ни следующего шага. Человек не понимает, ждать ему, обновлять страницу, писать в поддержку или уходить. Даже ограниченная страница лучше, если она говорит правду и всё ещё позволяет сделать что-то полезное.
Хорошая degraded-страница должна отвечать на несколько простых вопросов: что ещё работает, что временно недоступно, где найти важное — например, контакты или основную информацию о продукте, — и когда попробовать снова.
Частичные сбои редко затрагивают весь стек одновременно. База данных может подвиснуть, пока кэшированный HTML всё ещё загружается. API может упасть, а изображения, документация и статические страницы при этом останутся доступными. Origin может сломать оплату, действия в аккаунте или живой поиск, хотя обычный контент только для чтения по-прежнему открывается в браузере.
Именно здесь помогают страницы CDN failover. Они не притворяются, что приложение здорово. Они делают сайт полезным, когда динамические части перестают работать.
Цель простая: не упереться в тупик. Если полный опыт недоступен, отдайте честную урезанную версию. Дайте людям прочитать основы, понять проблему и сделать один понятный шаг. Это гораздо лучше, чем белый экран, туманная ошибка 500 или бесконечный спиннер.
Что нужно людям, когда origin перестаёт отвечать
Когда origin падает, большинству посетителей не нужен весь сайт. Им нужен простой ответ, несколько рабочих страниц и один понятный путь дальше. Если они видят пустую страницу ошибки, они решают, что всё сломано, и уходят.
Начните с честного сообщения. Скажите, что всё ещё работает, что нет, и когда будет следующее обновление. Строка вроде «Оформление заказа недоступно. Страницы помощи и контакты всё ещё работают. Следующее обновление через 15 минут» полезнее, чем любой общий 500 error.
Сделайте fallback-страницу полезной, а не декоративной. Люди часто приходят с простой задачей: проверить цены, найти шаги настройки, получить помощь с аккаунтом или связаться с человеком. Страница failover должна оставить эти базовые вещи доступными из кэша, чтобы сайт всё ещё отвечал на частые вопросы.
В большинстве случаев это значит показать короткий статус на простом языке, контакты или часы работы поддержки, базовую навигацию к нескольким кэшированным страницам, время последнего обновления и один следующий шаг, например «написать в поддержку».
Кэшированные важные страницы снимают лишнее напряжение в самый неудобный момент. Если человек всё ещё может прочитать цены, открыть документацию или найти помощь по оплате, сбой ощущается как ограничение, а не как катастрофа. Люди перестают обновлять страницу. Поддержка получает меньше повторных сообщений. Доверие падает не так сильно.
Один следующий шаг — это достаточно. Не отправляйте людей в лабиринт сломанных меню. Если не работает вход, направьте их в помощь по аккаунту. Если не открывается страница товара, оставьте кэшированное описание и вариант связи. Если на сайте консультирования ломается бронирование, покажите базовую информацию о услуге и email, чтобы разговор всё равно мог начаться.
Здесь многие команды перегибают палку. Вам не нужна уменьшенная копия всего сайта. Вам нужны страницы, которые отвечают на самые частые вопросы и снижают панику. Маленький честный fallback часто помогает больше, чем вылизанный экран аварии.
Сначала выберите самое важное
Когда origin начинает зависать, людям не нужен весь сайт. Им нужны несколько страниц, которые помогают закончить задачу, понять проблему или связаться с поддержкой. Если пытаться сохранить всё, запасной вариант обычно превращается в путаную, наполовину работающую копию.
Выберите страницы, которые всё ещё полезны во время сбоя. Для многих сайтов это главная, краткое описание продукта или услуги, цены, помощь со входом, документация, FAQ, контакты поддержки и простое статусное сообщение. Для SaaS-приложения страница помощи только для чтения часто важнее, чем полный дашборд. Для магазина важнее информация о доставке, возвратах и поддержке заказа, чем карусели рекомендаций.
Потом разделите контент на две группы. Первая — безопасна, даже если она немного устарела. Вторая — рискованна, потому что старые данные могут запутать людей. Публичные статьи помощи, описания продукта, инструкции по настройке и страницы с правилами обычно можно кэшировать. Персональные дашборды, остатки на складе, балансы аккаунтов и сроки доставки — обычно нет.
Хорошо работает простой фильтр:
- Оставляйте страницы, которые отвечают на срочные вопросы.
- Кэшируйте контент, который публичный и меняется медленно.
- Убирайте блоки, зависящие от живых API.
- Никогда не кэшируйте приватные или завязанные на аккаунт данные.
- Показывайте fallback быстро, если ожидание уже не приносит пользы.
Последний пункт важнее, чем кажется многим командам. Страница, которая зависает на 12 секунд, ощущается сломанной, даже если в итоге загружается. Более простая fallback-страница, показанная через 2–3 секунды, часто даёт людям лучший опыт, потому что она честная и полезная. Если живая страница не загружается быстро, не делайте вид, что она вот-вот восстановится.
Думайте в терминах задач, а не шаблонов. Человек, пришедший во время сбоя, обычно хочет одно из четырёх: проверить статус сервиса, найти обходной путь, связаться с поддержкой или получить базовую информацию о продукте. Если CDN может удержать эти пути с помощью кэшированного fallback-контента, сайт всё ещё выполняет свою задачу.
Как это настроить
Начните со сбоев, с которыми посетитель не может справиться сам. Хорошие триггеры failover обычно включают таймауты origin, ошибки соединения и серверные ошибки вроде 502, 503 и 504. Не включайте fallback для обычных страниц 404, неверных логинов или ошибок в форме. Эти случаи должно обрабатывать само приложение.
Простая настройка лучше, чем слишком умная.
Сначала выберите ошибки-триггеры. Ваш CDN должен переключаться на fallback только тогда, когда origin явно недоступен или слишком нестабилен, чтобы ответить. Если правило слишком широкое, вы скроете реальные ошибки приложения и усложните отладку.
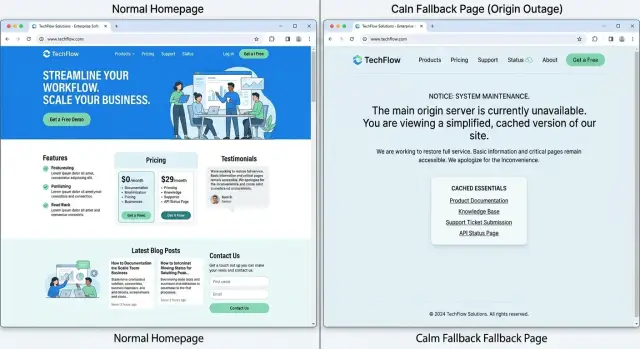
Затем соберите одну небольшую статическую страницу на edge. Оставьте чистый HTML, минимум CSS и, возможно, маленький логотип. Она должна быстро загружаться, объяснять, что у сайта временная проблема, и показывать, что сейчас всё ещё работает.
После этого заранее закэшируйте страницы, которые нужны людям чаще всего. Для многих сайтов это главная, цены или краткое описание продукта, справка, контакты и несколько базовых изображений или таблиц стилей. Если этих ресурсов нет в кэше к моменту сбоя, fallback-страница может выглядеть сломанной, даже если правило CDN сработало.
Потом уберите всё динамическое. Уберите формы, поиск, вход, корзину, действия в аккаунте и виджеты с живыми данными из fallback-опыта. Контактная форма, которая выглядит рабочей, но никогда не дойдёт до origin, хуже, чем отсутствие формы вообще.
И наконец, обязательно проверьте переключение специально. Заставьте origin вернуть 503, временно заблокируйте его в безопасной среде или используйте staging-домен, который имитирует сбой. Потом посмотрите, что реально видят пользователи, как быстро отвечает CDN и остаются ли кэшированные страницы читаемыми на телефоне и на компьютере.
Держите fallback достаточно маленьким, чтобы просматривать его за несколько минут перед каждым релизом. Команды с компактной инфраструктурой часто справляются с этим лучше, потому что относятся к поведению при сбое как к части продукта, а не как к второстепенной детали. Хорошая цель — страница, которая быстро отвечает на три вопроса: что происходит, что ещё работает и как с вами связаться.
Напишите понятную degraded-реакцию
Люди прощают сбой быстрее, чем туманное сообщение. Если origin лежит, скажите простыми словами, что у сайта проблема. «Наше основное приложение сейчас недоступно» лучше, чем «Мы испытываем временные трудности».
Потом расскажите, что всё ещё работает. Если документация загружается из кэша, скажите об этом. Если цены, контакты или просмотр аккаунта только для чтения всё ещё отвечают через CDN, назовите каждый вариант отдельно. Сначала людям нужны не обещания. Им нужно понять, могут ли они закончить хотя бы одну маленькую задачу.
Хорошая degraded-страница быстро отвечает на четыре вопроса:
- Что сейчас сломано
- Что всё ещё работает из кэша или через failover
- Что пользователям делать дальше
- Когда стоит перестать повторять попытки и вернуться позже
Сохраняйте спокойный и прямой тон. Не извиняйтесь три абзаца подряд. Не гадайте о причине, если не знаете её точно. «Оформление заказа не работает, но страницы товаров и контакты поддержки всё ещё доступны» вызывает больше доверия, чем «Некоторые сервисы могут быть затронуты».
Следующие шаги должны быть конкретными. Предлагайте обновить страницу только если это действительно может помочь. Если сайт поддерживает режим просмотра только для чтения из кэша, скажите: «Вы всё ещё можете посмотреть сохранённые заказы, но не можете оформить новый». Если email или телефон поддержки всё ещё работают, вынесите эту информацию прямо на страницу failover. Во время сбоя пользователю не нужно искать другую страницу, которая тоже может не открыться.
Маленькие формулировки имеют значение. «Платежи приостановлены» яснее, чем «Обработка транзакций может быть ухудшена». «Поиск работает, изменения в аккаунте — нет» даёт людям достаточно информации, чтобы действовать. Чёткие границы снижают раздражение, потому что людям не приходится гадать.
Когда failover-страницы сделаны хорошо, сайт всё ещё кажется управляемым. Люди видят границу, выбирают следующий шаг и идут дальше, вместо того чтобы смотреть на пустую страницу ошибки.
Простой пример
Во время дневной распродажи один магазин потерял бэкенд checkout примерно на 40 минут. Страницы товаров и категорий всё ещё были полезны, но платёжный поток не мог достучаться до origin, поэтому покупатели видели ошибки как раз в момент оплаты.
Команда не отправила всех в тупик. Они оставили кэшированные страницы категорий и товаров доступными через CDN, чтобы люди могли продолжать выбирать, сравнивать варианты и сохранять товары на потом. Если бы сломалось сразу всё, магазин потерял бы гораздо больше визитов.
На маршрутах checkout они показывали короткую fallback-страницу вместо общей ошибки. Она объясняла, что всё ещё работает, а что нет. И ещё отвечала на первые два вопроса, которые люди задают, когда речь идёт о деньгах: «С меня уже списали деньги?» и «Что делать дальше?»
На fallback-странице оставили несколько базовых элементов:
- Текущие регионы доставки и примерные сроки
- Email и телефон поддержки
- Ясное указание, что попытка оплаты не завершена
- Предупреждение не отправлять тот же платёж дважды
Это предупреждение реально помогло. Когда люди повторяют оплату снова и снова, магазины часто получают двойные авторизации, больше обращений в поддержку и раздражённых покупателей, которые больше не доверяют сайту.
Поскольку просмотр страниц всё ещё работал, покупатели продолжали двигаться по кэшированному контенту вместо того, чтобы уйти после первой ошибки. Кто-то добавлял товары в списки желаний. Кто-то проверял доставку, прежде чем вернуться позже. У поддержки тоже было меньше путаных сообщений, потому что fallback-страница сразу отвечала на основные вопросы.
Когда команда восстановила checkout, они не потеряли вообще все сессии. Продажи всё равно просели, но сайт оставался полезным и спокойным под давлением. Именно это и делают хорошие failover-страницы. Они не делают вид, что ничего не сломалось. Они защищают доверие, пока вы чините то, что действительно вышло из строя.
Ошибки, из-за которых failover-страницы бесполезны
Failover-страница помогает только тогда, когда человек всё ещё может сделать что-то полезное. Слишком многие команды подменяют сайт общей страницей 500 и называют это резервным планом. Это не резервный план. Это тупик на фоне другого цвета.
Худший вариант почти ничего не говорит. Пользователь не понимает, упал ли сайт у всех, прошёл ли заказ, и стоит ли пробовать снова позже. Короткое честное сообщение работает лучше: скажите, что часть сервиса недоступна, назовите, что ещё работает, и предупредите, что сейчас не стоит повторять.
Ещё одна частая ошибка — кэшировать не те страницы. Если CDN хранит экраны аккаунта, корзины, дашборды или что-то с личными данными, можно раскрыть приватную информацию или показать устаревшие сведения так, будто они актуальны. Это создаёт проблему больше, чем сам сбой. Кэшируйте только безопасный публичный контент и небольшой набор важного: статус, контакты поддержки, базовую информацию о продукте или страницу помощи только для чтения.
Некоторые команды пытаются скрыть сбой, чтобы сайт выглядел нормальным. Пользователи всё равно это замечают. Они кликают по страницам, натыкаются на случайные ошибки и теряют доверие быстрее, потому что им никто не объяснил, что изменилось. Честный текст лучше, чем фальшивая нормальность.
Где failover-страницы обычно ломаются
Degraded-страница должна убирать всё, что зависит от origin. Если на ней всё ещё есть сломанный поиск, неработающие отправки форм или кнопки, ведущие в checkout, вы снова отправляете людей в лабиринт. Отключите эти пути. Оставьте только то, что действительно работает.
Полезен короткий чек-лист:
- Уберите формы, которым нужна запись в реальном времени.
- Спрячьте действия, доступные только в аккаунте.
- Оставьте видимыми контакты поддержки и статус.
- Показывайте только тот контент для чтения, который остаётся точным.
Мобильную аудиторию часто игнорируют больше, чем команды готовы признать. Во время сбоя многие заходят с телефона через слабое соединение. Тяжёлые скрипты, большие изображения и сложные макеты только ухудшают плохую ситуацию. Делайте fallback-страницу лёгкой, простой и быстрой.
Хорошие failover-страницы говорят правду, защищают приватные данные и оставляют один-два рабочих пути вместо экрана, полного пустых обещаний.
Проверьте всё до следующего инцидента
Запланируйте короткое окно тестирования и намеренно отключите origin. Не гадайте. Failover-страница, которая выглядела хорошо в staging, может сломаться в production по банальным причинам: отсутствующий ресурс, устаревшее правило кэша или кнопка поддержки, ведущая на мёртвый backend.
Простой прогон показывает, делает ли ваша failover-страница свою единственную важную работу во время сбоя: сразу даёт человеку что-то полезное.
Что проверить
- Отключите origin на несколько минут и посмотрите, что реально получают пользователи в обычном браузере.
- Проверьте время загрузки из нескольких регионов. Fallback, который кажется быстрым рядом с вашим офисом, где-то ещё может тормозить.
- Прочитайте вслух каждую строку на странице. Так вы заметите туманную формулировку, сломанную дату и сообщение, которое звучит спокойнее, чем ситуация на самом деле.
- Откройте кэшированные страницы и убедитесь, что информация достаточно актуальна, чтобы помочь. Данные о продукте недельной давности могут быть нормальными. Цены, остатки или часы поддержки — не всегда.
- Проверьте путь к поддержке. Убедитесь, что статус, запасной способ связи, email или номер телефона по-прежнему работают, когда основное приложение не отвечает.
Делайте тест небольшим и скучным. Один человек может отключить трафик к origin, другой — проверить страницы с телефона и ноутбука, третий — убедиться, что сообщения поддержки корректны. Обычно это занимает меньше 30 минут.
Будьте строги к словам на странице. «У нас проблемы» лучше, чем общий error, но это всё равно заставляет людей гадать. Скажите, что ещё работает, что не работает и что делать дальше. Если действия в аккаунте недоступны, а документация, статус заказа или контакты всё ещё открываются, скажите об этом прямо.
Кэшированный fallback-контент тоже нуждается в сроке жизни, который соответствует реальности. Кэшировать главную на сутки может быть нормально. Кэшировать страницу биллинга на сутки — уже риск. Проверяйте каждую страницу с учётом этого.
Команды, которые проводят такой тест раз в несколько месяцев, обычно находят мелкие пробелы раньше пользователей.
Что делать дальше
Выберите одну страницу, на которую можно положиться, когда всё остальное нестабильно: простую failover-страницу с коротким статусом, понятной пометкой о том, что ещё работает, и одним следующим действием. Люди быстрее прощают ограничения, чем молчание.
Начните с малого. Большинству команд не нужен огромный набор для аварийного режима в первый же день. Одна fallback-страница и две-три кэшированные основные страницы уже делают плохой час гораздо более управляемым.
Обычно базовый набор включает:
- Failover-страницу с текущим статусом и ожидаемыми ограничениями
- Одну кэшированную страницу помощи, например с контактами или шагами поддержки
- Одну кэшированную бизнес-страницу, например с ценами, обзором продукта или документацией, которую люди проверяют перед покупкой или поиском решения
Потом зафиксируйте правила на бумаге. Решите, что запускает fallback, кто может менять сообщение, кто его утверждает, если это нужно, и кто возвращает обычный трафик. Если за эти шаги никто не отвечает, failover-страницы обычно запыляются до следующего инцидента.
Держите сообщение простым. Скажите, что origin испытывает проблемы. Скажите, что ещё работает. Скажите, что нет. Добавляйте время следующего обновления только если команда действительно может выполнить это обещание.
После каждого сбоя тратьте 20 минут на короткий разбор. Проверьте, что чаще всего спрашивали пользователи, что не смог отдать кэш и где формулировки вызвали путаницу. Потом упростите план. Уберите страницы, которыми никто не пользовался. Добавьте одну вещь, которую люди всё время искали.
Если команда застряла между «слишком много» и «ничего не делать», внешняя помощь может быть полезной. Oleg Sotnikov на oleg.is работает как Fractional CTO и консультант по инфраструктуре, и такой практический подход к failover-планированию хорошо подходит для этой работы.
Простой рабочий план лучше, чем идеальный план, который никто не обновляет.
Часто задаваемые вопросы
Что такое страница CDN failover?
Страница CDN failover — это небольшая статическая страница, которую CDN показывает, когда origin перестаёт отвечать. Она сообщает посетителям, что сломалось, что всё ещё работает из кэша, и что делать дальше, вместо пустого экрана ошибки.
Когда нужно включать failover?
Включайте её при сбоях, которые человек не может исправить сам: при таймаутах origin, ошибках соединения и ответах 502, 503 или 504. Не используйте её для обычных страниц 404, неверных паролей или ошибок в форме — такие случаи должно обрабатывать само приложение.
Какие страницы стоит кэшировать на случай сбоя?
Начните с самых нужных страниц на время сбоя: главной, описания продукта или услуги, документации, контактов и базовой справки. Выбирайте публичные страницы, которые всё ещё отвечают на частые вопросы, даже если приложение не загружается.
Что никогда не стоит кэшировать на странице failover?
Не храните в кэше приватные или быстро меняющиеся данные. Это касается страниц аккаунта, корзин, остатков, балансов, текущих сроков доставки и любой персональной информации, потому что устаревшие или раскрытые данные создают проблему больше, чем сам сбой.
Как быстро должна появляться fallback-страница?
Показывайте запасную страницу быстро. Если обычная страница всё ещё висит спустя пару секунд, большинство людей уже считает, что сайт сломался. Простая честная страница через 2–3 секунды обычно воспринимается лучше, чем ожидание 10 секунд ради возможного результата.
Что должно быть в сообщении о сбое?
Скажите, что не работает, что всё ещё доступно и что делать дальше. Фраза вроде Оформление заказа сейчас недоступно. Документация и контакты работают. Следующее обновление через 15 минут. даёт людям понятный ответ без догадок.
Стоит ли оставлять формы и вход на странице failover?
Нет. Уберите всё, что требует записи в origin в реальном времени: формы, вход, checkout, изменения в аккаунте и живой поиск. Если кнопка выглядит активной, но после нажатия всё равно ломается, доверие падает очень быстро.
Как протестировать failover до реального инцидента?
Да, короткую проверку провести стоит: намеренно отключите origin в безопасном окне. Потом откройте сайт с телефона и ноутбука, проверьте скорость загрузки из нескольких регионов и убедитесь, что все пути к поддержке и кэшированные страницы по-прежнему работают.
Может ли страница failover снизить нагрузку на поддержку во время сбоя?
Да, обычно это так. Когда посетители всё ещё могут читать цены, документацию, информацию о доставке или контакты поддержки, они перестают обновлять страницу и реже пишут в панике. Сбой всё равно неприятен, но он ощущается как ограничение, а не как полная остановка.
Нужна ли мне полная резервная версия сайта?
Нет. Большинству команд достаточно одной простой страницы failover и нескольких кэшированных основных страниц. Небольшая система, которую вы регулярно проверяете, лучше большого backup-сайта, который никто не обновляет.


