Бюджетирование роста диска для Postgres и объектного хранилища
Узнайте, как бюджетировать рост диска для Postgres и объектного хранилища, отслеживая действия клиентов, шаблоны использования и сигналы, которые показывают, где возникнет следующий лимит.
Содержание
Почему простой объём скрывает реальный риск хранения
График хранения, показывающий только суммарные гигабайты, выглядит спокойным вплоть до момента, пока перестаёт помогать. Линия растёт месяц за месяцем, и все предполагают, что следующий месяц будет похож. Потом один клиент меняет способ использования продукта — и следующий скачок совсем не похож на предыдущие десять.
Хранилище не растёт плавно и нейтрально. Оно растёт, когда люди совершают конкретные действия. Один клиент может добавлять тысячи мелких строк в Postgres каждый день и почти не сдвигать использование диска. Другой загружает изображения, генерирует миниатюры, сохраняет историю аудита и провоцирует дополнительные логи, повторы и бэкапы. Оба могут выглядеть похоже в отчёте по выручке, но их влияние на дисковую ёмкость будет совсем разным.
Простой пример всё проясняет. Клиент A использует инструмент для рабочих процессов и хранит задачи, комментарии и несколько вложений. Клиент B проводит полевые инспекции и загружает фото, PDF и версионированные отчёты для каждой работы. Если оба платят за один и тот же план, сырые итоги скрывают тот факт, что клиент B может создать в 10–50 раз больше нагрузки на хранилище.
Всё это — реальный риск. Проблемы редко начинаются с общего числа клиентов. Чаще они начинаются с изменения поведения, которое вы не смоделировали.
Свяжите рост хранения с действиями клиентов
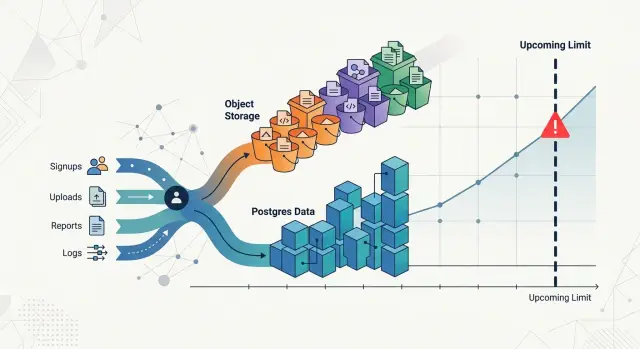
Хранилище обычно растёт потому, что пользователи совершают конкретные действия, а не потому, что данные появляются из ниоткуда. Чтобы бюджетирование роста диска работало, начните с действий в продукте и проследите каждое действие до создаваемого им хранения.
Сразу разделите Postgres и объектное хранилище. Они растут по разным причинам. Postgres увеличивается, когда пользователи создают строки, индексы, таблицы истории и метаданные. Объектное хранилище растёт, когда пользователи загружают изображения, видео, документы, бэкапы или экспортированные файлы. Один клиент может почти не нагружать базу, но быстро заполнять корзины большими медиафайлами. Другой может создать миллионы мелких записей и сделать Postgres основным узким местом.
Большинство команд могут начать с простой карты. Загрузки создают файлы в объектном хранилище и строки метаданных в Postgres. Сообщения создают строки, вложения, поисковые индексы и записи состояния прочтения. Экспорты создают временные файлы, итоговые файлы и историю задач. Логи и события создают большой объём строк, давление на хранение по времени и файлы архивации.
Здесь команды часто становятся небрежными: они считают только суммарные гигабайты и пропускают действия, стоящие за ними. Это скрывает реальный драйвер. Десять новых клиентов — не одно и то же, если один весь день отправляет текстовые сообщения, а другой раз в неделю хранит большие видеозаписи.
Также полезно пометить каждое действие как одноразовое или повторяющееся. Одноразовое действие — настройка аккаунта, первоначальный импорт или создание первого проекта. Повторяющееся — ежедневные загрузки, почасовые синхронизации, месячные экспорты или постоянное логирование событий. Повторяющиеся действия заслуживают большего внимания, потому что они превращают небольшую стоимость на пользователя в постоянный рост хранения.
Держите карту читабельной. Для многих продуктов достаточно четырёх корзин: загрузки, сообщения, экспорты и логи. Под каждой укажите действие клиента, что попадает в Postgres, что — в объектное хранилище и как часто это происходит.
Эта небольшая таблица обычно даёт лучший прогноз, чем сырая диаграмма объёма. Она также показывает, какое поведение клиента с наибольшей вероятностью первым выведет вас на предел по хранению.
Выбирайте числа, которые действительно приводят к росту
Большинство команд следят за суммарными гигабайтами и упускают причину. Хранилище растёт потому, что реальные клиенты создают строки, загружают файлы, сохраняют старые данные и повторяют эти действия неделя за неделей.
Хорошее бюджетирование роста диска начинается с частот, а не с итогов. База с 10 000 аккаунтов может расти медленно, если в месяц продукт использует только 800 клиентов. Гораздо меньший продукт может быстрее заполнить диски, если 50 клиентов ежедневно выполняют большие импорты и ничего не удаляют.
Начните с активных клиентов. Простое правило: клиенты, которые создавали данные, влияющие на хранение, за последние 30 дней. Это число гораздо полезнее, чем общее количество регистраций, потому что неактивные аккаунты не двигают линию Postgres или объектного хранилища.
Затем измеряйте поведение на одного активного клиента. Нужно знать, как часто происходит каждое действие, создающее хранение, а не только произошло ли оно однажды. Пользователь, который загружает по одному PDF в месяц, очень отличается от команды, отправляющей 20 000 событий в лог каждую день.
Несколько показателей обычно всё объясняют:
- активные клиенты по месяцам
- среднее число действий, создающих хранение, на одного активного клиента
- среднее число строк, добавляемых в Postgres за действие, или среднее число файлов, добавляемых в объектное хранилище
- средний байт на группу строк или файл, плюс как долго вы это храните
- доля нового хранения от топ-5% клиентов
Время хранения меняет всё. Если клиенты хранят данные 90 дней, у роста есть потолок. Если хранят навсегда, каждая загруженная активность накапливается поверх предыдущей. Команды часто отслеживают вставки и загрузки, а потом забывают про удаления, архивирование и правила TTL.
Следите за тяжёлыми пользователями. В многих продуктах небольшая группа создаёт большую часть роста. Один клиент может хранить миллионы записей о заданиях в Postgres. Другой — загружать большие медиафайлы и заполнять объектное хранилище быстрее, чем все остальные вместе взятые. Если вы сведёте всё в один аккуратный средний показатель, вы спрячете риск.
Простая привычка помогает: разделите клиентов на низкое, среднее и тяжёлое использование. Делайте прогноз для каждой группы отдельно. Это потребует немного больше работы, но покажет, откуда придёт следующий скачок и когда текущего объёма перестанет хватать.
Постройте простой прогноз шаг за шагом
Начните с одного сегмента клиентов. Не усредняйте всю базу в одну линию. Команда с редкими загрузками ведёт себя совершенно иначе, чем клиент, который синхронизирует файлы весь день — и именно в этих различиях кроются сюрпризы по хранению.
Выберите сегмент с похожим поведением и посчитайте действия, создающие данные, каждую неделю. Для большинства продуктов эти действия легко назвать: новые записи, обновления записей, увеличивающие текст или JSON-поля, загрузки файлов, генерируемые превью и логи, связанные с активностью клиента. Если у вас есть 4–8 недель данных, используйте их. Если нет — сделайте низкий и высокий сценарии.
- Посчитайте активных клиентов в сегменте.
- Оцените события хранения на клиента в неделю.
- Оцените среднее число байт, добавляемых в Postgres за событие.
- Оцените среднее число байт, добавляемых в объектное хранилище за событие.
- Оцените байты, удаляемые или перемещаемые через очистку, архивирование или удаление.
Преобразуйте поведение в чистый еженедельный прирост. Для первичного прогноза достаточно простой модели:
weekly Postgres growth =
active customers x events per customer x Postgres bytes per event
- bytes deleted or archived from Postgres
weekly object storage growth =
active customers x events per customer x object bytes per event
- bytes deleted, compacted, or expired
Очистка меняет картину сильнее, чем многие команды ожидают. Некоторые продукты удаляют черновики спустя 30 дней. Другие архивируют вложения из Postgres и хранят оригиналы в объектном хранилище. Некоторые ничего не удаляют — это незаметно месяц, но дорого через полгода.
Повторите ту же математику для следующего сегмента, затем сложите итоги. Держите один консервативный сценарий и один — для тяжёлого использования. Для бюджетирования роста диска обычно этого достаточно, чтобы увидеть, когда объём базы потребуется расширить, когда затраты на объектное хранилище начнут расти и какое поведение клиента вызывает скачок.
Небольшая таблица прогноза лучше сложной модели, которую никто не обновляет. Если сегмент растёт быстрее ожидаемого, сначала измените число событий. Сырые гигабайты показывают, что случилось. Действия клиентов объясняют, что будет дальше.
Реалистичный пример с двумя очень разными клиентами
Представьте SaaS для полевых команд. Они загружают наряды, фото и подписанные PDF. Приложение также хранит историю активности: каждая загрузка, комментарий, изменение статуса и действие «поделиться» записываются в Postgres.
Сравним двух клиентов на одном плане. Team Pine — 12 человек. Они загружают примерно 250 документов в месяц, большинство около 3 МБ. Они генерируют примерно 1 500 событий активности в день. Team Quarry — 45 человек. Они загружают около 5 000 документов в месяц, в среднем по 10 МБ, и многие файлы заменяются новыми версиями. Они также создают около 30 000 событий активности в день из‑за активного использования комментариев, утверждений и автоматизаций.
Эти две команды создают нагрузку в трёх местах:
- Живая часть Postgres растёт из метаданных, прав доступа, строк активности и индексов.
- Объектное хранилище растёт из загруженных файлов и дополнительных копий при ревизиях документов.
- Бэкап‑хранилище растёт потому, что ночные бэкапы базы данных и WAL‑архивы становятся больше с ростом churn в базе.
Предположим, что у сервиса 50 ГБ свободно на томе Postgres, 60 ГБ — для сохранённых бэкапов базы и 500 ГБ свободно в объектном хранилище.
Team Pine добавляет около 0.7 ГБ в месяц к Postgres. Их файлы добавляют около 1 ГБ в месяц в объектное хранилище. Бэкапы растут медленно, примерно на 1.5 ГБ в месяц. Ничего не выглядит критичным в ближайшее время. База имеет годы запаса, а объектное хранилище почти не меняется.
Team Quarry меняет картину быстро. Их история активности и индексы добавляют около 8 ГБ в месяц в Postgres. Их загрузки и версии файлов добавляют около 70 ГБ в месяц в объектное хранилище. Поскольку база меняется чаще, использование бэкапов растёт на ~12 ГБ в месяц.
Нагрузка не приходит везде сразу. Сначала начинает ощущаться корзина для бэкапов, примерно на 5‑м месяце. Том Postgres следует около 6‑го месяца. Объектное хранилище поначалу кажется безопасным — 500 ГБ звучит много — но при 70 ГБ в месяц ощущение тесноты появляется примерно к 7‑му месяцу.
Именно поэтому простое число клиентов вводит в заблуждение. Один тяжёлый клиент может съесть больше хранилища, чем десять лёгких. Если вы отслеживаете загрузки на одного пользователя, события активности на workflow и частоту версий файлов, вы увидите стену за месяцы и добавите ёмкость до того, как это станет аварией.
Заметить предупреждающие сигналы до столкновения со стеной
Проблема с хранилищем обычно проявляется в операциях раньше, чем в свободном месте на диске. Хорошее бюджетирование роста диска отслеживает эти ранние симптомы, потому что система может ощущаться нездоровой при 65% заполнения намного раньше, чем появится алерт о полном диске.
Бэкапы часто первыми начинают раздражать. Если ночной бэкап Postgres раньше выполнялся за 35 минут, а теперь — за два с половиной часа, риск уже не теоретический. Окно бэкапа начинает пересекаться с рабочими часами, тесты восстановления пропускают, и один неудачный запуск оставляет вас уязвимыми до следующего цикла.
Скорость запросов — ещё один ранний симптом. Большие таблицы и индексы не только занимают больше диска, они гонят через кэш больше данных, увеличивают работу по vacuum и делают простые чтения тяжелее. Дашборд, который загружался секунду месяц назад, а теперь — четыре, часто говорит вам о росте хранения больше, чем график использования.
У объектного хранилища есть свой сигнал: рост затрат, опережающий рост клиентской базы. Если число клиентов выросло на 12%, а счёт за объектное хранилище — на 40%, где‑то изменилось поведение. Возможно, один клиент начал загружать большие файлы, хранить больше версий или генерировать намного больше экспортов, чем ожидалось.
Операционная нагрузка обычно появляется до того, как диск заполнится:
- работы бэкапа начинают накладываться на другие задачи обслуживания
- autovacuum работает дольше и отстаёт
- тесты восстановления занимают так много времени, что команды перестают их регулярно выполнять
- счета за хранение растут быстрее, чем доход от аккаунтов, создающих данные
- шум в on‑call увеличивается, потому что задачи, запросы или загрузки не успевают в обычные окна
Два клиента могут добавить одинаковый сырой объём за месяц, но только один создаёт опасность. Один загружает статичные файлы один раз и редко трогает их снова. Другой делает частые обновления, версионированные экспорты и тяжёлые отчёты по растущим таблицам. Оба растят хранилище, но только второй одновременно добавляет нагрузку на бэкапы, индексы, обслуживание и затраты.
Свободное место говорит вам, когда вы почти на исходе. Операционная нагрузка говорит вам, что вы уже опоздали.
Ошибки, которые ломают прогнозы хранения
Прогноз хранения ломается, как только вы начинаете считать всех клиентов средними. Один загрузит пару PDF в неделю. Другой — зальёт записи с камер, сохранит каждую версию и синхронизирует старые данные из другой системы. Они могут быть на одном плане, но их кривые хранения совсем разные.
Ещё одна частая ошибка — использовать только прошлый месяц как прогноз. Это даёт аккуратную линию, но аккуратные линии врут. Хранилище обычно скачет, когда поведение меняется: клиент включает более длинную историю, импортирует бэклог, добавляет больше людей в команду или начинает прикреплять большие файлы.
Хорошее бюджетирование роста диска начинается с действий, а не с итогов. Считайте драйверы байт: загрузки на пользователя, средний размер файла, версия файлов, задачи экспорта, генерация отчётов и длительность хранения. Когда один из этих параметров сдвинется, хранилище может измениться быстро, даже если число клиентов останется стабильным.
Правила хранения и дублированные данные наносят тихий урон. Команды часто бюджетируют только первую копию файла и забывают о всех остальных. Если вы храните удалённые элементы 90 дней, делаете миниатюры изображений, сохраняете версии документов и повторяете неудачные загрузки без очистки, одно действие клиента может создать несколько объектов хранения.
У Postgres есть та же ловушка. Люди смотрят на размер таблицы и останавливаются, хотя базе часто нужно гораздо больше места «вокруг» данных.
Распространённые упущения:
- индексы, растущие вместе с большими таблицами
- бэкапы, снапшоты и история версий объектов
- WAL‑файлы, временные файлы и spill при сортировке во время тяжёлых запросов
- промежуточные копии, тестовые восстановления и остатки миграций
Эти «дополнения» важны, потому что они растут по другой шкале. Тихий месяц по пользовательским данным всё ещё может быть занятым месяцем для бэкапов или реиндексации. Команды обычно обнаруживают проблему во время обслуживания, когда использование диска всплескивает и свободного резерва уже нет.
Простое правило помогает: прогнозируйте три линии, а не одну. Отслеживайте первичные данные, сопутствующий оверхед и временные пики отдельно. Та же мысль встречается в бережливой инфраструктуре: убрав мусор, скрытые копии и кратковременные всплески увидеть гораздо проще.
Если ваша модель не объясняет, почему один активный клиент использует в 10 раз больше хранилища, чем другой, модель слишком проста. Исправьте это до следующей волны роста.
Короткий чеклист для ежемесячного обзора
Ежемесячный обзор работает лучше, когда занимает 20 минут и использует одни и те же числа каждый раз. Так бюджетирование роста диска остаётся привязанным к поведению клиентов, а не к догадкам.
Начните с роста хранения за прошлый месяц, но разбейте его по сегментам клиентов. Корпоративные аккаунты, тестовые пользователи и тяжёлые API‑клиенты часто создают разные паттерны в Postgres и объектном хранилище. Если один сегмент вырос немного в выручке, но сильно в строках или файлах — там и кроется риск.
Используйте короткий неизменный чеклист:
- Разбейте рост строк Postgres и рост объектного хранилища на сегменты, соответствующие тому, как клиенты используют продукт. Один большой клиент может скрываться в сумме и искажать картину.
- Просмотрите несколько действий клиентов, создающих большую часть роста. Частые примеры: загрузки файлов, экспорт отчётов, импорты, логи аудита, вложения в сообщениях и фоновые задания, записывающие снимки.
- Сравните прогноз с фактическими еженедельными числами, а не только с итогом на конец месяца. Еженедельный взгляд показывает дрейф раньше, особенно после релиза, изменения цен или активного онбординга.
- Пересчитайте запас с учётом обычных пиков. Не спрашивайте только «Сколько у нас свободного места?». Спросите: «На сколько недель нам хватит, если занятый клиент будет вести себя как в прошлом месяце?».
Этот обзор становится острее, если список действий небольшой. Большинству команд не нужно отслеживать двадцать драйверов — обычно хватает трёх‑четырёх, создающих основную долю новых строк и файлов.
Вы увидите это на практике быстро. Один клиент может импортировать большие датасеты по пятницам и выбивать рост Postgres выше среднего. Другой загружает изображения поддержки весь месяц и заполняет объектное хранилище, в то время как рост базы остаётся плоским. Суммарные гигабайты вряд ли объяснят любую из этих ситуаций.
Если фактический рост превышает прогноз две недели подряд — обновляйте модель немедленно. Ожидание следующего месячного обзора превращает небольшое отклонение в проблему ёмкости.
Превратите прогноз в рутину
Прогноз полезен только если команда им пользуется каждый месяц. Включите бюджетирование роста диска в тот же обзор, где вы смотрите выручку, состав клиентов и инфраструктурные расходы. Когда финансы и инженерия смотрят на одни и те же числа, хранение перестаёт быть неожиданным счётом и становится плановым решением.
Держите модель маленькой. Большинству команд нужно лишь несколько входных данных: активные клиенты, тяжёлые пользователи, средние загрузки или записи на клиента, период хранения и фактическое использование хранилища за прошлый месяц. Обновляйте эти числа, сравнивайте прогноз с реальностью и исправляйте допущения, которые дрейфуют.
Нужны также чёткие правила действий. Если никто не знает, когда вмешаться, модель превратится в таблицу, которой никто не пользуется.
- Пересматривайте прогноз раз в месяц, и раз в неделю, если рост ускоряется.
- Установите триггер, когда проектируемая ёмкость окажется в пределах 3–6 месяцев от лимита.
- Установите второй триггер, когда один клиент начнёт расти гораздо быстрее остальных.
- Решите, кто отвечает: инженерия, финансы или оба.
- Запишите первое действие для каждого триггера, чтобы команда не спорила во время инцидента.
Выбор правил хранения заслуживает отдельного решения, а не борьбы в последний момент. Если клиенты редко открывают файлы после 90 или 180 дней, архивируйте их раньше. Если набор данных в основном текстовый или содержит повторяющийся контент, протестируйте сжатие и измерьте реальную выгоду прежде, чем внедрять.
Если логи, превью или временные экспорты накапливаются без пользы, сократите период хранения и удаляйте их по расписанию.
Postgres требует той же дисциплины. Старые строки событий, трассы аудита и большие таблицы истории могут расти быстрее, чем данные, видимые клиентам. Если таблица растёт, но почти никто не читает старые записи — вынесите холодные данные из горячего пути до того, как это повлияет на время бэкапа, восстановление и свободное место.
Простая привычка работает: каждый месяц записывайте текущее использование, прогноз на 3, 6 и 12 месяцев и действие, которое вы предпримете, если линия останется неизменной. Одной страницы обычно достаточно, чтобы поймать следующую стену ёмкости вовремя.
Если модель всё ещё кажется шаткой, второе мнение экономит время. Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами по практической инфраструктуре, окружениям для AI‑проектов и планированию Fractional CTO. Короткий обзор может выявить неверные допущения по ретенции, архитектуре и затратам на хранение до того, как они превратятся в аварию или неприятный счёт.
Часто задаваемые вопросы
Why not just watch total storage used?
Total gigabytes show what already happened. A behavior-based forecast shows почему storage grows, so you can spot the next jump before a disk, backup pool, or storage bill turns into a problem.
What should I track first?
Start with the actions that create data every week. For most products, that means uploads, messages, exports, logs, and any background job that writes rows or files.
Should I forecast Postgres and object storage together?
No. Keep them separate from day one because they grow for different reasons. Postgres grows from rows, indexes, history, and churn, while object storage grows from files, versions, previews, and exports.
How do I define an active customer for this forecast?
Use a rule tied to storage creation, not logins. Count customers who created rows, uploads, exports, or other stored data in the last 30 days.
Why do heavy users throw off the forecast?
Averages hide the customers who create most of the pressure. If one account uploads huge files or creates heavy database churn, it can consume more storage than many light users combined.
What retention details matter most?
You need to know how long you keep live data, deleted items, backups, WAL, versions, and temporary files. Retention decides whether growth levels off or keeps stacking every month.
How much historical data do I need before I can forecast?
You can start with 4 to 8 weeks of real data if the product usage looks steady. If usage changes a lot, build a low case and a heavy-use case, then update the model every month.
What early signs tell me storage is becoming a risk?
Watch for backup jobs that run longer, restore tests that take too long, queries that slow down, and storage costs that rise faster than customer growth. Those signs usually show up before free space gets scary.
How often should we review the forecast?
Review it once a month in normal conditions. If growth speeds up, a large customer changes behavior, or a new feature starts writing lots of data, check it every week until the numbers settle.
When should we add capacity or bring in outside help?
Set a trigger before you feel pain, not after. If the forecast shows only 3 to 6 months of headroom, or one customer starts growing far faster than the rest, add capacity, tighten retention, or get an experienced engineer to review the model and the architecture.


