Бюджет задержки инструментов для помощников, которые кажутся быстрыми
Используйте бюджет задержки при вызове инструментов, чтобы измерять задержки при поиске, запросах и записях, задавать лимиты времени для действий и сохранять быстрые ответы помощника.
Содержание
Почему помощники кажутся медленными, даже если ответ верный
Пользователи оценивают помощника не только по качеству ответа. Они оценивают время ожидания до ответа, ритм этого ожидания и то, стоит ли задержка полученного результата.
Хороший ответ всё равно может казаться медленным, если он приходит через процесс с остановками и паузами. Помощник ищет, делает паузу, читает, снова пауза, затем пишет. Каждая пауза в логе выглядит небольшой. Пользователь ощущает их все.
Именно поэтому одна чистая семисекундная пауза часто кажется лучше, чем шесть коротких задержек, которые суммируются до того же времени. Одна пауза воспринимается как работа. Повторяющиеся паузы выглядят как колебание.
Небольшие задержки быстро накапливаются. Один запрос добавляет 400 мс. Второй поиск — ещё 700 мс. Затем система форматирует результаты, отправляет их обратно модели и просит ещё одну проверку. То, что выглядело как пара быстрых вызовов инструментов, превращается в несколько секунд.
Цена — не только во времени. Это внимание. Каждая дополнительная остановка делает помощника менее уверенным, даже если окончательный ответ верный. Люди начинают спрашивать себя: «Почему это заняло так много времени для чего‑то простого?»
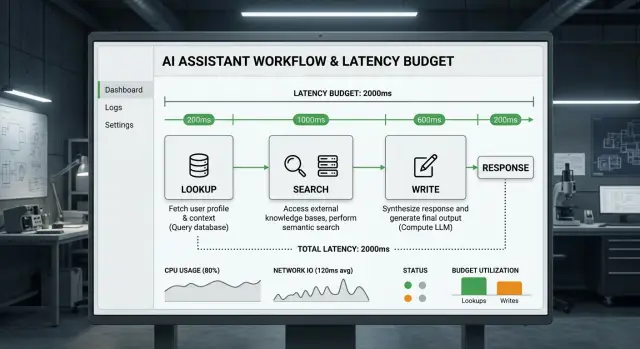
Большинство медленных ответов теряют время в одних и тех же местах: сетевой запрос к инструменту, выполнение работы самим инструментом, чтение моделью возвращённых данных и ещё один проход, чтобы превратить сырые результаты в аккуратный ответ.
Бюджет задержки при вызове инструментов помогает тем, что ограничивает, сколько задержки может создать задача. Для простого запроса техподдержки не нужно запускать пять инструментов только потому, что помощник может это сделать.
Важна полезная скорость, а не просто количество вызовов. Большинство пользователей предпочтут хороший ответ за три секунды, чем чуть более точный — за девять. Они также согласны подождать дольше, когда задача явно тяжёлая, например проверка истории заказов или сравнение нескольких записей.
Правило простое: используйте инструменты, когда они действительно меняют ответ. Если вызов даёт мало пользы, он только замедляет. Быстрый помощник кажется способным. Активный помощник чаще выглядит просто медленным.
Куда уходит время в одном ответе
Один ответ может скрывать много работы. Пользователь видит одно сообщение, но система могла сделать несколько небольших задач, прежде чем написать фразу.
Чтобы построить полезный бюджет задержки, разделите ожидание на время модели и время инструментов. Время модели покрывает чтение запроса, решение о следующем шаге и генерацию ответа. Время инструментов покрывает всё вокруг: получение данных, поиск по документам, разбор результатов и запись обновлений в другие системы.
Во многих помощниках время инструментов — более серьёзная проблема. Модель может требовать 1–2 секунды. Инструменты тихо добавляют ещё 4–5.
Большинство ответов состоит из небольшого набора действий. Помощник делает запрос одной записи, ищет по документам или прошлым случаям, очищает возвращённые данные или записывает что‑то в другую систему. Каждый шаг добавляет задержку в своём месте.
Сетевая задержка — это время «в пути» к другому сервису и обратно. Задержка логики приложения происходит внутри вашего кода, когда он проверяет права, преобразует данные, объединяет результаты, удаляет поля или ждёт в очереди.
Это деление важно. API поиска может отвечать за 400 мс, в то время как ваше приложение тратит ещё 900 мс на перестановку результатов и удаление лишнего текста. Если вы отслеживаете только общее время, вы пропускаете истинный источник замедления.
Повторы и таймауты часто создают худшие паузы. Один таймаут может превратить быстрый запрос в трёхсекундную задержку. Один повтор удваивает это. Дублирующие вызовы хуже — они добавляют ожидание, не принося нового результата. Две части рабочего процесса запрашивают один и тот же аккаунт — система получает его дважды, и пользователь платит временем за оба.
Чёткая трассировка одного ответа должна показывать каждый шаг, кто его запустил и сколько он занял. Команды часто обнаруживают, что сама модель вовсе не думала медленно. Она ждала инструменты, повторяла работу и тратила время на защитный код, который почти никогда не должен был запускаться.
Как задан бюджет задержки, который заметят люди
Пользователи не судят о скорости по вашим логам. Они судят по промежутку между их вопросом и первым полезным ответом. Хороший бюджет задержки начинается с одной жёсткой цели для этого промежутка и заставляет каждый поиск и запрос заслужить своё место.
Для обычного обоснованного ответа 3–5 секунд обычно воспринимаются нормально. Около 8 секунд уже начинает казаться медленно, если только задача явно не тяжёлая. Если вы регулярно не попадаете в цель, сократите поток работ, прежде чем добавлять новые инструменты.
Простой бюджет может дать модели 500 мс на чтение запроса и решение о действиях, 1–2 секунды на один поиск или запрос, ещё 500–800 мс на второй вызов инструмента только если первый результат слабый, и 700–1200 мс на финальный ответ.
Последний кусок важнее, чем многие команды ожидают. Если извлечение съедает весь бюджет, помощник всё равно кажется медленным, потому что пользователь снова ждёт пока он пишет. Зарезервируйте время на ответ заранее, даже если это означает меньше вызовов инструментов.
Устанавливайте лимиты для каждого действия, а не только для общего времени. Инструмент поиска, который иногда занимает 6 секунд, испортит весь опыт, даже если среднее время выглядит нормальным. Поставьте таймаут на каждый запрос, каждый поиск и каждую запись. Затем логируйте реальное время каждого из них.
Также нужна политика на случай, когда бюджет исчерпан. Не давайте помощнику копаться бесконечно. Он должен ответить с лучшей имеющейся информацией, указать на низкую уверенность или задать один короткий уточняющий вопрос вместо продолжительного ожидания.
Здесь команды часто застревают. Они оптимизируют полноту, но пользователи обычно предпочитают твёрдый ответ за 4 секунды, а не чуть лучше — за 12. Oleg Sotnikov делает тот же вывод в своей работе по lean AI first operations: более жёсткие лимиты часто заставляют проектировать систему лучше.
Если один ответ требует трёх поисков, запроса в базу и длинной черновой версии — бюджет что‑то говорит вам. Поток слишком дорог для этой задачи.
Как измерять каждый шаг
Начните с трассировок, а не со средних. Если вы хотите полезный бюджет задержки, измеряйте каждое действие с момента вызова инструмента до его возврата. Один медленный ответ обычно появляется из одного‑двух шагов. Средние скрывают это.
Для каждого шага храните небольшую запись: имя инструмента, время начала, время окончания, размер входных данных, размер результата, тип задачи, намерение пользователя, число повторов и итоговый статус. Обычно этого достаточно.
Размер важнее, чем команды ожидают. Запрос может быстро вернуться сам по себе, но следующий шаг записи замедлится, потому что теперь в подсказке большой набор результатов. Поэтому измеряйте каждый шаг, а не только итоговое время ответа.
После сбора нескольких сотен трассировок сгруппируйте их двумя способами. Сначала по типу задачи: lookup, search, summarize, rewrite или final answer. Затем по намерению пользователя: запрос возврата денег, устранение неполадок, статус заказа или вопрос по продажам.
Эти два вида групп обычно выявляют настоящую задержку. Поиск может быть в порядке для простых запросов, тогда как для устранения неполадок запускаются три поиска, долгое объединение контекста и перезапись, которая почти ничего не даёт. Глобальная средняя этого не покажет.
Просмотрите самые медленные трассы, прежде чем менять подсказки. Прочитайте полную последовательность и задайте два простых вопроса: какой шаг заставил пользователя ждать и улучшил ли этот шаг ответ достаточно, чтобы оправдать задержку? Часто команды тратят дни на переработку подсказок, когда реальная проблема — дублирующий запрос или проход очистки, который никому не нужен.
Затем вырежьте или объедините слабые шаги. Объедините поиски по одному источнику. Уберите записи, которые только перефразируют текст. Если вы уже используете Grafana, Prometheus или Loki, отправляйте туда события времени, чтобы продукт и инженерия могли смотреть одни и те же трассы, вместо того чтобы спорить с разных дашбордов.
Простой способ найти задержку
Начните с одного реального вопроса, который пользователи задают часто. Повторяющиеся задержки вредят сильнее, чем редкие.
Запишите вопрос точно так, как его задаст пользователь. Не начинайте с большой блок‑схемы или набором средних. Один чёткий запрос даёт вам чистый путь для измерения.
- Перечислите каждое действие помощника в порядке выполнения.
- Зафиксируйте, когда каждое действие начинается и заканчивается.
- Сложите времена в одну сумму.
- Отметьте самый медленный шаг.
- Протестируйте более короткий путь и сравните новый итог.
Держите список буквальным. Если помощник проверяет статус аккаунта, ищет в документах, запрашивает базу и пишет заметку — запишите все четыре действия отдельно. Одна строка вроде «проверил» скрывает настоящую проблему.
Используйте реальное время по стене, а не догадки. Если поиск занял 800 мс, запишите 800 мс. Если модель потратила 1.4 секунды, прежде чем решить вызвать инструмент, тоже засчитайте это. Люди ощущают полное ожидание, а не только работу базы данных.
Небольшой пример делает это очевидным. Пользователь спрашивает: «Можете сказать, почему мой возврат не пришёл?» Помощник тратит 300 мс на выбор инструментов, 900 мс на проверку системы заказов, 1.6 с на получение платежных данных и 700 мс на запись внутренней заметки. Это 3.5 секунды до того, как ответ начнёт казаться полноценным.
Теперь протестируйте короткий путь. Возможно, заметка не нужна прямо во время разговора. Возможно, платежные данные важны только если проверка заказа показывает, что возврат был одобрен. Переместите или уберите один шаг и задайте тот же вопрос снова.
Это сравнение важнее абстрактной настройки. Если полный путь занимает 3.5 секунды, а короткий — 2.1, вы нашли задержку, которую люди чувствуют. Если качество ответа осталось тем же, короткий путь выигрывает.
Команды обычно усваивают одно простое правило: самый медленный шаг редко — модель. Это лишний запрос, повторяющийся поиск или запись, которые могли бы подождать до после ответа.
Пример поддержки, который выглядит реалистично
Представьте, что клиент спрашивает: «Почему моё заявление на возврат было закрыто, и можно ли его снова открыть?» У помощника есть доступ к справочным документам и прошлым тикетам. Это звучит полезно, но как именно он использует эти инструменты решает, будет ли ответ быстрым и точным или медленным.
В медленной версии помощник старается быть доскональным. Он ищет политику возвратов, затем биллинг‑доки, затем старые тикеты с похожими случаями и только после этого пишет ответ.
Примерная разбивка времени: 1.4 с на поиск по документам по возвратам, 1.7 с на поиск по биллингу, 3.2 с на поиск похожих тикетов и 2.6 с на написание и правку ответа. Это около 9 секунд без учёта оверхеда и дополнительных пауз модели. На практике часто выходит ближе к 10–11 секундам.
Ответ может быть верным, но он читается как отчёт. Пользователь задал один вопрос, а получил текст политики, фон и задержку, достаточную, чтобы задуматься, не застрял ли помощник.
Теперь сравните с коротким путём. Помощник делает один запрос в систему тикетов. Этот запрос возвращает статус тикета, код причины закрытия и прикрепленную заметку с подходящей политикой. После этого помощник отвечает.
Такая версия может занять 2.1 с на запрос и 1.4 с на финальный ответ. Итого около 3.5 с. Ответ зачастую даже лучше: «Ваш запрос на возврат был закрыт, потому что он поступил после 30‑дневного срока. Я не могу заново открыть этот тикет, но могу начать новую проверку, если это дублирующий платёж.»
Коротко, конкретно и полезно. Если один запрос уже содержит необходимые факты, три дополнительных поиска не делают помощника умнее. Они просто заставляют его дольше ждать.
Ошибки, из‑за которых агенты выглядят занятыми
Помощник может выглядеть активным, тратя секунды на работу, которая не улучшает ответ. Большинство медленных ответов возникает из нескольких привычек, которые кажутся безобидными в тестах, но в реальной работе раздражают.
Одна частая ошибка — вызывать инструменты до того, как модель собрала достаточно контекста. Если пользователь спрашивает: «Почему мой счёт не прошёл?» и помощник сразу открывает логи биллинга, историю заказов, заметки CRM и справочные документы, он тратит время на догадки. Короткое чтение запроса сначала часто убирает половину таких вызовов.
Другая проблема — запуск поиска по очереди, когда один более широкий поиск подошёл бы лучше. Команды дробят простой поиск на три шага, потому что так рабочий процесс выглядит аккуратно. Пользователям всё равно, как аккуратно это выглядело; им важно, что ответ пришёл за 6 секунд, а не 16.
Раннее написание длинных черновиков создаёт ту же трату времени. Некоторые агенты генерируют полный ответ, затем делают поиск и переписывают всё заново. Это тратит токены на текст, который модель потом выбрасывает. Короткий план, а затем один целенаправленный черновик обычно быстрее и проще контролируется.
Повторы должны иметь жёсткий лимит. Когда инструмент падает, многие агенты повторяют одно и то же действие с теми же входными данными в надежде, что следующий раз повезёт. Это редко помогает. Оставьте одну повторную попытку для временных ошибок, может быть две, если инструмент действительно ненадёжен, затем переключитесь на план Б или скажите пользователю, что мешает прогрессу.
Последняя ловушка скрыта в отчётности. Средние значения могут выглядеть здоровыми, в то время как один медленный запрос к базе данных или зависший поиск портит каждый десятый разговор. Отслеживайте медиану, но смотрите также на хвост — p95. Это число показывает, сколько времени занимают самые медленные 5% ответов, и пользователи замечают эти задержки быстрее всего.
Для небольших команд это важно вдвойне. Дополнительные вызовы инструментов увеличивают и время, и стоимость.
Прежде чем добавлять ещё один вызов инструмента
Большинство дополнительных вызовов инструментов не улучшают ответ. Они добавляют пару сотен миллисекунд, потом ещё немного, и простой ответ начинает казаться медленным. Относитесь к каждому запросу как к тому, что должен заслужить свою цену.
Начните с прямого вопроса: изменит ли этот вызов то, что увидит пользователь? Если ответ будет тот же, пропустите вызов. Приветствие, краткое объяснение, переформулировка или стандартная политика часто не требуют живых данных.
Проверьте подсказку, недавний чат и локальный кэш перед вторым запросом к инструменту. Спросите, достаточно ли данных, которым несколько минут. Используйте собственные знания модели для стабильных фактов, повторяющихся инструкций и простого форматирования. Поставьте жёсткий таймаут на медленные инструменты и переходите к более короткому ответу, если они не успевают.
Кэширование часто — самый простой выигрыш. Если помощнику нужны часы работы, правила доставки или настройка продукта, которые редко меняются, краткоживущий кэш обычно решает проблему. Нет смысла дергать сервис поиска при каждом запросе, если ответ меняется раз в неделю.
Будьте честны в том, что модель может ответить без помощи. Она не должна угадывать балансы аккаунтов или статус живого заказа, но может справляться с рутинными формулировками, сводками и общими объяснениями продукта. Многие команды вызывают инструменты просто потому, что могут, а не потому, что нужно.
Медленным инструментам нужен твёрдый стоп. Если поиск занимает 4 с и помогает лишь в одном запросе из двадцати, это плохая сделка. Пользователи замечают задержку быстрее, чем небольшой прирост полноты.
Простое правило: оставляйте вызовы инструментов на те моменты, когда важна свежесть, права доступа или точные записи. Всё остальное должно быть дешёвым, быстрым и скучным.
Что делать дальше
Выберите один рабочий поток, который происходит каждый день. Не начинайте с самого тяжёлого случая. Начните с того, что создаёт наиболее заметную задержку — статус заказа, квалификация лида или вопросы по аккаунту. Небольшой фикс в «шумном» пути обычно важнее, чем умный фикс в редком.
Затем измерьте полный путь от сообщения пользователя до окончательного ответа. Бюджет задержки при вызове инструментов работает только тогда, когда вы видите каждый шаг отдельно. Если помощник тратит 600 мс на принятие решения, 1.8 с на поиск, 900 мс на запрос данных и 2 с на запись, задержка перестаёт быть загадкой.
Простой первый проход достаточен. Логируйте момент прихода сообщения. Логируйте время начала и конца каждого вызова инструмента. Логируйте, когда модель начинает черновик и когда заканчивает. Соберите эти числа в небольшой дашборд, который команда смотрит каждый день.
После этого задайте лимиты для наиболее частых действий. Держите лимиты простыми и запоминающимися. Например, кэш‑запрос — 300 мс, поиск — 1.5 с, запись — 2 с. Если одно действие постоянно не укладывается, исправляйте именно его, а не настраивайте всё вокруг одновременно.
Вырежьте шаги, которые не оправдывают время. Многие помощники делают лишний поиск, перечитывают ту же запись или зовут вторую модель для полировки, которую пользователи едва замечают. Если шаг добавляет задержку и мало меняет ответ — уберите его. Быстро и ясно обычно лучше, чем медленно и чуть красивее.
Команды часто застревают, когда помощник хорошо работает в демо, но тормозит в продакшне. Обычно это архитектурная проблема, а не подсказочная. Если вы сталкиваетесь с этим в реальном продукте, Oleg Sotnikov на oleg.is работает со стартапами и небольшими компаниями по архитектуре агентов, инфраструктуре и поддержке Fractional CTO. Иногда внешний взгляд достаточно, чтобы заметить лишний поиск, повтор или запись, из‑за которых хороший помощник кажется медленным.
Часто задаваемые вопросы
What is a tool use latency budget?
Бюджет задержки — это лимит времени для одного ответа. Он подсказывает помощнику, сколько времени можно потратить на чтение, вызовы инструментов и составление ответа, чтобы простой вопрос не превратился в длинную цепочку запросов.
How fast should an assistant feel for a normal question?
Для обычного, основанного на данных ответа стоит стремиться к примерно 3–5 секундам от сообщения пользователя до первого полезного ответа. Люди чаще терпимее, когда задача явно требует проверки живых данных или нескольких проверок.
Is the model usually the slow part?
Задержки от инструментов часто дают больший вклад в время ожидания, чем сам модельный шаг. Модель может думать и писать за секунду или две, в то время как поиски, запросы, повторы и код очистки добавляют ещё несколько секунд.
How do I measure where the delay comes from?
Начните со трассировки одного реального запроса и запишите каждый шаг в порядке выполнения. Логируйте имя инструмента, время начала, время конца, число повторов, размер входа, размер результата и итоговый статус, чтобы увидеть, где действительно происходит ожидание.
Why do a few small tool calls make replies feel slow?
Один запрос к инструменту может добавить несколько сотен миллисекунд, но несколько таких вызовов быстро суммируются. Повторяющиеся паузы воспринимаются хуже, чем одно чистое ожидание, даже если общее время в логах похоже.
When should I skip a tool call?
Пропускайте вызов инструмента, если он не меняет то, что пользователь увидит. Общие политики, простые переформулировки, стабильные факты и рутинные формулировки часто не требуют живых данных.
Why are duplicate lookups such a problem?
Дублирующие запросы тратят время без добавления новой информации. Они также создают впечатление неуверенности, поскольку помощник снова и снова запрашивает одну и ту же запись или обходит один и тот же источник.
What should the assistant do when a tool is slow or times out?
Установите твёрдый таймаут и держите повторные попытки на низком уровне. Если инструмент всё ещё не отвечает, ответьте на основе имеющейся информации, укажите низкую степень уверенности или задайте один короткий уточняющий вопрос, вместо того чтобы заставлять пользователя ждать.
Can caching help without hurting answer quality?
Да. Кэширование часто дает простой выигрыш в скорости для данных, которые редко меняются, например, часы работы магазинов, правила доставки или настройки продукта. Для свежих записей, прав доступа и точных данных аккаунта используйте живые запросы.
What metrics should I watch besides average response time?
Следите не только за средним временем ответа. Отслеживайте медиану, чтобы знать обычную скорость, но также смотрите p95, чтобы поймать более медленные ответы, которые пользователи замечают в первую очередь. Хорошая средняя может скрыть одну медленную операцию, которая портит разговоры.


