Буферизация загрузок Nginx: как исправить случайные сбои при больших импортах
Буферизация загрузок Nginx влияет на временные файлы, лимиты тела запроса и тайм-ауты. Узнайте простые настройки, которые помогут остановить случайные сбои при больших импортах.
Содержание
Почему большие загрузки падают случайно
Большие загрузки ломаются так, будто это происходит случайно, потому что файл проходит не по одному простому пути. Файл на 5 МБ может проходить каждый раз, а импорт на 500 МБ натыкается на лимит размера, заполняет временное хранилище или слишком долго идёт по медленному соединению. Поведение выглядит непоследовательным, хотя правило жёсткое.
Поэтому один человек может завершить загрузку, а другой — получить ошибку через несколько минут. Разница часто не связана с кодом импорта. Обычно дело в скорости сети, размере файла, свободном месте на диске для temp-файлов Nginx или в тайм-ауте, который истёк до окончания загрузки.
Одна из самых запутывающих вещей в буферизации загрузок — это то, что приложение может вообще не увидеть неудачный запрос. Обычно Nginx сначала читает тело запроса. Если он отклоняет загрузку из-за слишком большого тела, слишком медленного клиента или нехватки места в temp storage, запрос может завершиться раньше, чем приложение что-либо залогирует. Команда смотрит в логи приложения, видит почти ничего и думает, что проблема глубже, чем есть на самом деле.
Temp storage сильно добавляет путаницы. Nginx может держать часть загрузки в памяти и записывать остальное на диск, прежде чем передать данные дальше. Маленькие файлы скрывают проблему. Более крупные импорты её показывают. Временная область заполняется, общее хранилище переполняется или диск начинает работать настолько медленно, что срабатывает тайм-аут.
Медленное соединение делает картину ещё менее очевидной. Пользователь на быстром офисном интернете может загрузить тот же файл, который у другого человека на слабом Wi‑Fi или мобильной точке доступа падает каждый раз. Файл в обоих случаях нормальный. Один клиент отправляет его достаточно быстро, другой — нет.
Обычно простая закономерность становится заметной, когда вы сравниваете несколько удачных и неудачных загрузок. Смотрите на размер файла, общее время загрузки, свободное место в temp storage Nginx, качество сети и на то, получает ли приложение запрос вообще. Если маленькие файлы работают, большие обрываются на середине, а логи приложения молчат, начинайте с Nginx, а не с кода импорта.
Что делает Nginx до того, как файл увидит приложение
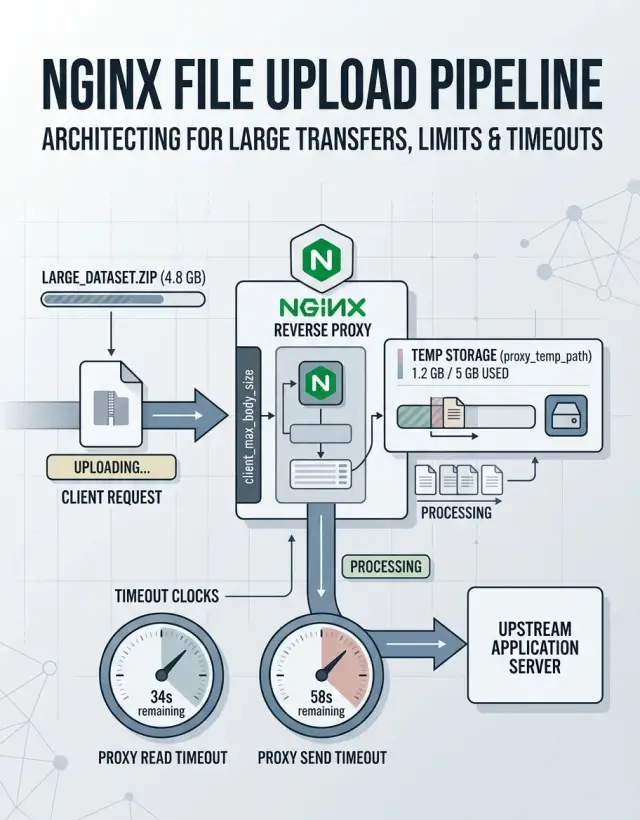
Когда кто-то загружает CSV на 500 МБ, приложение часто простаивает почти всё это время. Обычно Nginx сначала читает тело запроса, решает, где его хранить, и только потом передаёт его вашему бэкенду.
По умолчанию Nginx не отправляет каждый байт в приложение сразу, как только он приходит. Он буферизует тело запроса. Небольшая часть может оставаться в памяти, но более крупные загрузки уходят во временные файлы на диске. Обычно эти файлы попадают в путь, указанный в client_body_temp_path.
Вот здесь и начинается множество «случайных» сбоев. Если temp-диск медленный, заполнен или используется вместе с другой нагрузкой, загрузка может упасть ещё до запуска вашего кода. В логах приложения всё выглядит нормально, потому что оно так и не получило файл.
Nginx также заранее проверяет лимиты размера. Если запрос больше, чем client_max_body_size, Nginx отклоняет его до того, как приложение увидит хотя бы один байт. Поэтому пользователь может получить ошибку 413, а на бэкенде при этом не будет ничего.
Важны и тайминги. Один тайм-аут определяет, как долго Nginx ждёт, пока клиент отправляет загрузку. Другие тайм-ауты отвечают за соединение с приложением и за то, как долго Nginx ждёт ответа после передачи запроса.
Базовый поток простой: клиент начинает отправлять файл, Nginx читает тело и проверяет правила размера, Nginx хранит тело в памяти, на диске или и там и там, и только после этого передаёт запрос приложению.
Последний шаг часто застает команды врасплох. Медленная загрузка может провести в Nginx несколько минут, пока приложение ещё ничего не делает. Если раньше срабатывает тайм-аут или заканчивается место в temp storage, импорт падает, а приложение даже не получает шанс обработать его.
Представьте пользователя, который загружает большой ZIP по слабому Wi‑Fi. Nginx читает его медленно, часть пишет во временное хранилище и передаёт дальше только тогда, когда тело полностью готово. Если загрузка слишком долго зависает или заканчивается место на диске, запрос обрывается именно там.
Начните с настроек, которые ломаются чаще всего
Большинство сбоев загрузки связано с одним и тем же небольшим набором настроек. Когда одна из них слишком мала, слишком коротка или указывает не на тот диск, импорт ломается только для некоторых файлов или только для части пользователей.
Начните с client_max_body_size. Если пользователь отправляет файл на 220 МБ, а Nginx разрешает только 100 МБ, запрос остановится, и приложение ничего не получит. Это легко пропустить, потому что маленькие тестовые файлы работают нормально, а реальные импорты от клиентов падают с ошибкой 413 или с неясным сообщением в браузере.
Затем проверьте client_body_buffer_size. Это не общий лимит загрузки. Эта настройка определяет, сколько тела запроса Nginx держит в памяти, прежде чем записать остальное на диск. Если буфер слишком мал для вашего потока запросов, Nginx будет чаще использовать temp-файлы. Это нормально, но тогда скорость диска и свободное место становятся гораздо важнее.
client_body_temp_path заслуживает отдельного внимания. Укажите его на диск с достаточным пространством, стабильными правами доступа и предсказуемой производительностью. Оставлять его на маленьком root-разделе — частая ошибка, когда пользователи загружают большие CSV, ZIP или медиафайлы. Заполненная временная область создаёт сбои, которые выглядят случайными, потому что зависят от времени и размера файла.
Медленным пользователям нужно достаточно времени, чтобы отправить тело запроса. client_body_timeout определяет, как долго Nginx ждёт между операциями чтения. Если кто-то загружает файл через слабый мобильный интернет или Wi‑Fi в отеле, короткий тайм-аут может оборвать нормальный импорт на середине.
После окончания загрузки приложению может понадобиться ещё время, чтобы распарсить файл, распаковать архив, проверить данные или записать строки в базу. Здесь важны upstream-тайм-ауты. Если Nginx ждёт ответ всего 60 секунд, а вашему приложению нужно три минуты на обработку большого импорта, пользователь всё равно увидит ошибку, даже если файл уже дошёл.
Практическая отправная точка выглядит так:
client_max_body_size 250m;
client_body_buffer_size 512k;
client_body_temp_path /var/lib/nginx/body 1 2;
client_body_timeout 120s;
proxy_read_timeout 300s;
proxy_send_timeout 300s;
Разбирайте базу по порядку. Подберите client_max_body_size под реальные размеры файлов, убедитесь, что у temp-пути достаточно свободного места и правильные права доступа, настройте client_body_buffer_size с учётом лимитов по памяти и объёма загрузок, увеличьте client_body_timeout для медленных отправителей и поднимите upstream-тайм-ауты, если парсинг начинается только после завершения загрузки.
Если один импорт проходит на 20 МБ, но падает на 180 МБ, первым подозреваемым должен быть не код приложения. Обычно первым начинает говорить именно Nginx.
Настраивайте temp storage по шагам
Большие импорты часто падают потому, что Nginx записывает часть тела запроса на диск до того, как его прочитает приложение. Когда этот диск маленький, заполнен или занят, загрузка ломается так, что это выглядит случайностью.
Temp storage часто стоит проверить первым. Сначала найдите реальный путь, который Nginx использует для временных файлов тела запроса, а не тот путь, который вы предполагаете по старой заметке или неактуальной конфигурации.
Сначала найдите настоящий путь temp storage
Посмотрите client_body_temp_path в живой конфигурации:
nginx -T | grep client_body_temp_path
Затем проверьте свободное место на этом разделе во время реальной загрузки. Следите за диском, пока кто-то загружает файл, который обычно падает. Импорту на 2 ГБ нужно не только место для одного файла. Если одновременно загружают два или три пользователя, пространство исчезает очень быстро.
Маленькие root-разделы здесь создают много проблем. Логи, обновления пакетов и временные данные загрузок часто конкурируют за один и тот же диск. Когда они делят пространство, один шумный сервис может сломать импорт для всех остальных.
Если у вас именно такая схема, перенесите temp-файлы на более большой диск и по возможности держите их отдельно от логов:
client_body_temp_path /data/nginx/client_temp 1 2;
Создайте каталог, дайте пользователю Nginx права на запись, а затем перезагрузите Nginx. Меняйте понемногу. Не трогайте лимиты, тайм-ауты и temp storage одним коммитом, иначе вы не поймёте, что именно помогло.
Проверяйте по одному размеру
Простой рабочий ритуал лучше, чем большой повторный прогон:
- Загрузите один размер файла, который уже падает, например 200 МБ.
- Следите за свободным местом, активностью диска и error log Nginx.
- Повторите ту же загрузку дважды после каждого изменения.
- Переходите к большему файлу только после того, как меньший заработает.
- Добавьте одну параллельную загрузку и проверьте снова.
Это кажется медленным, но в итоге экономит время. Большинство «случайных» сбоев перестают выглядеть случайными, когда вы наблюдаете temp-диск во время реальных загрузок.
Задайте лимиты тела запроса в соответствии с реальными импортами
Лимит тела запроса должен исходить из реальных размеров загрузок, а не из догадок. Посмотрите логи импортов, обращения в поддержку или примеры файлов клиентов и найдите размер, который покрывает обычный сценарий. Если большинство импортов укладывается в 80 МБ, а некоторые доходят до 120 МБ, ставьте лимит под этот диапазон. Не прыгайте сразу до 2 ГБ только потому, что кто-то однажды об этом попросил.
Nginx применяет правила к телу запроса до того, как приложение сможет обработать файл. Если лимит слишком низкий, Nginx отклоняет запрос заранее, и пользователи видят сбои, которые кажутся случайными, особенно когда размеры файлов отличаются у разных клиентов.
Оставляйте запас на накладные расходы multipart form. Загрузка из браузера — это не только сам файл. В запросе ещё есть границы формы, имена полей и заголовки. Накладные расходы обычно небольшие, но лимит, установленный ровно по размеру файла, всё равно может сработать слишком рано. Хорошее простое правило: добавьте 10–20% к самому большому обычному файлу, округлите до удобного значения вроде 100 МБ или 250 МБ и держите предел близко к реальному использованию.
Каждый слой должен говорить про лимиты одно и то же. Если Cloudflare, балансировщик, Nginx и приложение используют разные значения, сработает самый маленький лимит. Поэтому такие сбои часто списывают на приложение, хотя запрос до него даже не доходит. Проверьте лимиты на каждом прокси и затем согласуйте их с настройкой размера запроса или импорта в приложении.
Если файл слишком большой, скажите пользователю об этом прямо. Верните понятное сообщение с максимальным допустимым размером и, если возможно, предложите меньший экспорт или разделённый импорт. Чистая ошибка 413 гораздо лучше, чем тайм-аут, обрыв соединения или общее сообщение «upload failed».
Если вы поддерживаете импорт-системы для клиентов с очень разными размерами файлов, используйте отдельные маршруты или server block вместо одного огромного глобального лимита. Так обычные конечные точки останутся более строгими, а риск злоупотреблений снизится. Это также практичный подход в продакшн-системах, которые проверяет Oleg Sotnikov: лимиты задают по реальному трафику и повышают только там, где это действительно нужно.
Подбирайте тайм-ауты под медленные сети
Большие импорты обычно ломаются по двум разным причинам, и решение зависит от того, что именно вы наблюдаете. Иногда пользователь загружает файл по слабому соединению, и Nginx сдаётся раньше, чем тело запроса успевает прийти целиком. Иногда загрузка проходит, но приложению нужно дополнительное время, чтобы распаковать файл, проверить его или импортировать данные.
client_body_timeout отвечает за первый случай. Он определяет, сколько Nginx ждёт между частями тела запроса от клиента. Пользователь на Wi‑Fi в отеле или на мобильном интернете может делать паузы достаточно долго, чтобы упереться в стандартное значение, хотя файл бы успел загрузиться, если дать чуть больше времени.
Для приложений с тяжёлыми загрузками часто помогает увеличение client_body_timeout до практичного значения. Начинайте со среднего числа, а не с экстремального. Например, 120s или 180s дадут медленным соединениям запас, но не оставят мёртвые подключения висеть весь день.
После завершения загрузки важны уже другие таймеры. Если ваше приложение тратит две–четыре минуты на разбор CSV, распаковку архива или проверку строк перед ответом, смотрите на proxy_read_timeout. Эта настройка определяет, как долго Nginx ждёт данных от upstream-приложения.
proxy_send_timeout важен на этапе передачи. Nginx использует его, когда отправляет запрос вверх по цепочке к серверу приложения. Если Nginx буферизует тело и потом пересылает большой запрос на сервер приложения, который читает медленно, этот тайм-аут может сработать даже тогда, когда клиент уже закончил загрузку.
Простой стартовый вариант выглядит так:
client_body_timeout 180s;
proxy_send_timeout 180s;
proxy_read_timeout 300s;
Обычно этого достаточно для медленного, но реального трафика. Этого не хватит для сломанного job-процесса импорта, который никогда не заканчивается, и в этом суть. Слишком большие тайм-ауты скрывают настоящие проблемы. Если поставить везде час, упавшие воркеры, заблокированные диски и зависшие парсеры просто будут висеть дольше, прежде чем кто-то это заметит.
Используйте тайм-ауты так, чтобы они соответствовали нормальному поведению с небольшим запасом. Если пользователям нужно две минуты на загрузку в слабой сети, дайте им три. Если разбор больших файлов занимает 90 секунд, дайте приложению от трёх до пяти минут. Потом следите за логами. Если тайм-аут срабатывает, он должен говорить вам что-то полезное.
Простой пример импорта
Небольшая команда предлагает CSV-импорт для товарных данных. Один клиент загружает файл на 250 МБ из офисной сети, где скорость каждые несколько минут падает, а загрузка идёт рывками, а не ровным потоком.
Nginx первым принимает запрос. До того как приложение успеет что-то разобрать, Nginx сохраняет большую часть тела запроса в своей временной области. На этом сервере этот temp-path лежит на маленьком диске, где уже хранятся логи и другие временные данные. Примерно на середине загрузки диск заканчивается.
Со стороны клиента это выглядит случайно. Одна попытка долго висит. Другая заканчивается страницей ошибки. Команда открывает логи приложения и почти ничего не находит, потому что приложение так и не получило полный файл. Nginx упал раньше, поэтому парсер даже не успел стартовать.
Вот почему буферизация загрузок так легко вводит людей в заблуждение. Первое исправление часто звучит разумно, но ничего не решает. Команда увеличивает client_max_body_size, снова тестирует и всё равно получает сбои импорта. Эта настройка лишь говорит, насколько большим может быть запрос. Она не создаёт место на диске для temp-файлов и не даёт медленной сети больше времени.
Настоящее исправление гораздо менее эффектное: перенести путь временного тела на более большой диск, оставить достаточно свободного места не для одной, а для нескольких загрузок одновременно, увеличить client_body_timeout, чтобы медленная офисная линия успевала завершить отправку, и держать client_max_body_size выше реального размера файла с запасом.
После этого тот же CSV на 250 МБ проходит. Nginx пишет тело запроса, не забивая диск, загрузка остаётся открытой достаточно долго, и приложение наконец начинает разбирать строки, а не падает до старта.
Это важно и по другой причине. Когда путь загрузки уже работает, ошибки становятся нормальными и понятными. Если в CSV плохой столбец или битая строка, приложение может честно сообщить об этом. До исправления сервер прятал настоящую проблему за случайными сбоями.
Ошибки, которые постоянно повторяются
Самая частая ошибка проста: кто-то увеличивает client_max_body_size, видит, что несколько загрузок прошли, и решает, что проблема исчезла. Потом импорты снова начинают падать, потому что Nginx всё ещё нуждается в достаточном temp-space, праве на запись и разумных правилах буферизации, пока он принимает тело запроса.
Из-за этого разрыва возникает много запутанных сбоев. Лимит тела может быть нормальным, но каталог temp заполняется, диск начинает тормозить или запрос раньше отклоняет другой слой.
Обычная схема ещё ухудшает ситуацию. Команды держат temp-файлы Nginx на том же маленьком диске, где лежат логи, кэши приложения и системные файлы. Серия больших импортов быстро съедает свободное место, а логи продолжают расти. В результате всё выглядит грязно: одна загрузка проходит, следующая возвращает 413, 499, 502 или просто уходит в тайм-аут.
Это типичный паттерн в системах, которые аудирует Oleg Sotnikov. Сначала виноватым называют приложение, хотя сервер просто заканчивает место ещё до того, как запрос до него доходит.
Ещё одна повторяющаяся проблема лежит вне Nginx. Балансировщик, CDN, ingress controller или WAF могут иметь собственные лимиты размера тела и тайм-ауты. Можно поставить client_max_body_size 500m; в Nginx и всё равно падать уже на 100 МБ, потому что upstream-сервис обрывает запрос раньше.
Медленные пользователи показывают следующую слепую зону. Загрузки, которые проходят на быстром офисном интернете, могут ломаться у реальных пользователей на слабом Wi‑Fi, в гостиничном интернете или на мобильных данных. Если тестировать только в чистой локальной сети, значения тайм-аутов будут выглядеть нормально ровно до того момента, пока клиенты не начнут отправлять большие файлы из более медленных мест.
Последняя ошибка легко исправляется, но всё равно случается постоянно: менять пять настроек сразу. Если вы одновременно увеличиваете размер тела, переносите temp-файлы, поднимаете тайм-ауты, меняете буферизацию и перезагружаете всё вместе, вы теряете след. Когда загрузка начинает работать, вы не знаете почему. Когда всё равно падает, вы не понимаете, куда смотреть.
Лучше работает более спокойный процесс. Меняйте одну настройку, тестируйте один известный размер файла, следите за свободным местом и логами Nginx во время загрузки и проверяйте лимиты на каждом участке до и после Nginx. На первый час это кажется медленнее. К концу дня обычно оказывается быстрее.
Быстрые проверки, прежде чем винить приложение
Многие сбои загрузки на самом деле не связаны с буферизацией. Файл ломается где-то на пути, а Nginx — просто первое место, где вы это заметили.
Начните с error log Nginx. Ищите 413, когда файл слишком большой, 408, когда клиент слишком долго отправлял данные, и сообщения о temp-файлах тела запроса, когда Nginx не хватило места или он не успевал писать достаточно быстро. Если команда уже собирает логи в Loki или другом инструменте, сначала отфильтруйте именно эти признаки. Пять минут здесь могут сэкономить часы догадок.
Потом проверьте диск, где лежат temp-файлы тела запроса. Большие импорты часто используют временное хранилище ещё до того, как приложение прочитает хотя бы байт. Если этот раздел почти заполнен, загрузки ломаются беспорядочно и непоследовательно. Один пользователь проходит с файлом на 300 МБ, другой падает на 280 МБ, и картина выглядит случайной, хотя на деле это просто нехватка свободного места и давление на I/O.
Краткий чек-лист помогает:
- Прочитайте error log Nginx в точное время сбоя.
- Проверьте свободное место и скорость записи на диске temp-файлов.
- Сравните лимиты размера на каждом участке пути.
- Засеките одну реальную загрузку на медленном соединении.
- Проверьте, может ли приложение обработать файл после того, как Nginx его принял.
Проверка размера важнее, чем многие думают. Вы можете задать client_max_body_size в Nginx, но балансировщик, CDN, ingress, framework или сервер приложения всё равно могут отклонить тот же файл раньше или позже. Если один слой позволяет 1 ГБ, а другой — 100 МБ, пользователи получают разные ошибки в зависимости от того, какой путь им попался.
Тайм-ауты тоже нужно тестировать в реальности, а не угадывать. Загрузите один образец файла с самой медленной сети, которую вы поддерживаете, и измерьте полное время запроса. Отельный Wi‑Fi или слабая мобильная точка доступа легко превращают безобидный импорт в тайм-аут. Если в реальном использовании загрузка занимает три минуты, проблема в 60-секундном тайм-ауте.
И наконец, убедитесь, что приложение может обработать файл после того, как Nginx его принял. Nginx может завершить всё чисто, а приложение — упасть во время парсинга, выйти за пределы памяти или словить тайм-аут на этапе импорта. Проверьте ещё и логи приложения, логи очередей и систему отслеживания ошибок. Когда обе стороны согласны в том, что произошло, исправление становится намного проще.
Что делать дальше, чтобы путь загрузки стал стабильным
Случайные сбои загрузок обычно возникают из-за несовпадающих лимитов, а не из-за одной сломанной настройки. Если вы хотите стабильный результат, сначала запишите три реальные цифры: самый большой файл, который отправляют пользователи, самое медленное соединение, которое вы хотите поддерживать, и свободное место, доступное для temp-файлов Nginx во время пикового трафика.
Эта простая база меняет весь разговор. Импорт на 2 ГБ по офисному оптоволокну и тот же импорт по гостиничному Wi‑Fi ведут себя совершенно по-разному. Если команда пропускает этот шаг, люди часто просто увеличивают client_max_body_size и всё равно получают сбои, потому что где-то ещё ломается место на диске, буферизация или тайм-аут.
Лучше работает простой план внедрения: сначала подкорректируйте лимиты размера тела, затем проверьте расположение temp-файлов и свободное место, потом увеличьте тайм-ауты чтения и отправки для медленных загрузок, протестируйте один размер файла, который должен пройти, и один, который должен не пройти, и фиксируйте каждое изменение вместе с точным результатом.
Меняйте по одной группе за раз. Если вы одновременно меняете лимиты, temp storage и proxy-настройки, вы не поймёте, что помогло, а что вызвало новую проблему.
Мониторинг важен не меньше, чем конфигурация. Настройте алерты на низкое свободное место на temp-томе, рост числа ошибок 413, повторяющиеся ответы с тайм-аутом и резкие всплески отменённых загрузок. Такие сигналы обычно появляются раньше, чем обращения в поддержку.
Если буферизация — только часть проблемы, проверяйте весь путь целиком. Воркеры приложения могут уходить в тайм-аут, пока Nginx ещё принимает данные. Контейнерное хранилище может заполниться, хотя основной диск выглядит нормально. Балансировщики и CDN тоже могут обрывать долгие загрузки раньше, чем ожидает приложение.
Когда загрузки проходят через Nginx, код приложения, воркеры и облачные лимиты, внешний аудит может сэкономить дни проб и ошибок. Oleg Sotnikov на oleg.is помогает стартапам и небольшим командам проверять инфраструктурные лимиты, пути загрузки и поток приложения в рамках работы Fractional CTO и консультаций для стартапов. Такой аудит особенно полезен, когда одни и те же сбои возвращаются снова и снова после небольших правок конфигурации.
Часто задаваемые вопросы
Почему логи приложения остаются пустыми, когда большая загрузка падает?
Nginx часто останавливает запрос ещё до того, как он попадёт дальше. Если файл превышает client_max_body_size, временный диск заполняется или клиент отправляет данные слишком медленно, приложение вообще не получает запрос. Сначала проверьте error log Nginx и диск с temp-файлами.
Что нужно проверить в первую очередь, если я вижу ошибку 413?
Начните с client_max_body_size. Если это значение меньше реального размера запроса, Nginx сразу вернёт 413, и приложение не увидит файл.
Ограничивает ли client_body_buffer_size максимальный размер загрузки?
Нет. client_body_buffer_size определяет только то, сколько тела запроса Nginx держит в памяти, прежде чем записать остальное на диск. Реальный лимит загрузки задаёт client_max_body_size.
Куда лучше поместить client_body_temp_path?
Укажите путь на диск с достаточным свободным местом, стабильной скоростью записи и правильными правами для пользователя Nginx. Лучше не использовать маленький root-раздел, где уже лежат логи и другие временные данные, потому что большие загрузки быстро его переполняют.
Сколько запаса нужно оставлять над реальным размером файла?
Оставьте небольшой запас сверх реального размера файлов. Простое правило — ставить лимит примерно на 10–20% выше самого большого обычного файла, чтобы накладные данные multipart не приводили к лишним ошибкам.
Какой тайм-аут помогает пользователям с медленным соединением?
Для медленных загрузок используйте client_body_timeout. Эта настройка показывает Nginx, сколько ждать между частями тела запроса от клиента, поэтому её увеличение помогает пользователям на слабом Wi‑Fi или мобильном интернете завершить загрузку.
Почему один и тот же файл у одного пользователя работает, а у другого нет?
Обычно дело не в самом файле, а в скорости сети, месте на temp-диске или тайм-ауте. Один пользователь отправляет тот же файл достаточно быстро, а другой позже упирается в тайм-аут или переполняет временную область.
Стоит ли менять лимиты, temp storage и тайм-ауты одновременно?
Нет. Лучше менять одну группу настроек, тестировать один известный размер файла и наблюдать за логом Nginx и temp-диском во время загрузки. Так вы поймёте, что именно помогло, а не будете гадать.
Может ли другой сервис отклонить загрузку, даже если в Nginx всё выглядит нормально?
Да. CDN, балансировщик, ingress controller, WAF или сам сервер приложения могут иметь меньший лимит размера тела запроса или более короткий тайм-аут. Сработает самый жёсткий лимит на всём пути, поэтому проверяйте каждый слой.
Как лучше всего проверять исправления после изменения конфигурации загрузок?
Запустите один размер файла, который должен пройти, и один, который должен не пройти. Измерьте время загрузки на медленном соединении, проверьте свободное место на диске temp-файлов Nginx и посмотрите error log Nginx в момент сбоя.


