Логируйте бизнес-события до вызовов модели в небольших командах
Небольшим командам стоит логировать бизнес-события до вызовов модели, чтобы объяснять сбои ИИ, отслеживать влияние на пользователей и быстрее чинить сломанные сценарии.
Содержание
Почему сбои кажутся случайными
Большинство сбоев ИИ кажутся случайными не потому, что модель загадочная. Они выглядят случайными, потому что логи начинаются слишком поздно.
К тому моменту, когда кто-то открывает инцидент, запись часто начинается с тайм-аута, невалидного JSON, пустого поля или отклонённого API-вызова. Это показывает, где сломалась система. Но не показывает, что именно хотел сделать пользователь.
Именно этот недостающий контекст меняет весь разбор. Ошибка парсинга говорит, что модель вернула неправильную структуру. Но не говорит, отправлял ли пользователь запрос на возврат, переписывал ответ в поддержку или обновлял заказ, который уже дважды менялся.
Даже полный набор из запроса и ответа часто недостаточен. Настоящая история живёт в бизнес-состоянии вокруг вызова: кто был пользователь, на каком экране он находился, что нажал, какой черновик уже существовал и какие другие системы изменились сразу после этого.
Представьте небольшую SaaS-команду, которая разбирает обращение в поддержку. Пользователь говорит: «Ваш AI изменил не ту заметку клиента, а потом всё сломалось». В логах видно один ответ модели и ошибку базы данных. Поддержке всё равно нужно понять, редактировал ли пользователь черновик или живую запись, успело ли приложение частично сохранить изменение, отклонила ли его другая служба и был ли это первый запрос или повторная попытка после медленного ответа.
Без такой временной линии команда каждый раз повторяет один и тот же ритуал. Один человек ищет старую переписку. Другой запускает запрос локально. Поддержка просит у клиента скриншоты. Баг, который можно объяснить за 10 минут, съедает полдня.
Именно поэтому полезно логировать бизнес-события до вызовов модели. Короткое событие вроде «пользователь запросил объяснение возврата для счёта 1842» часто полезнее огромного дампа запроса. Оно даёт поддержке понятную запись о намерении и даёт инженерам стартовую точку, которая совпадает с реальным рабочим процессом.
То же самое касается того, что происходит после вызова. Если модель предложила изменение, приложение его сохранило, отклонило или отправило на проверку? Сбой редко живёт только внутри модели. Обычно он проявляется там, где ответ встречается с правилами продукта, billing-логикой или правами доступа.
Когда этих событий нет, каждый инцидент кажется новым. Когда они есть, сбой перестаёт выглядеть мистическим. По цепочке можно прочитать простыми словами: что хотел сделать пользователь, что система знала в тот момент и что изменилось дальше.
Что записывать до вызова
Ответ модели гораздо проще оценить, если вы знаете, что приложение пыталось сделать ещё до того, как запрос покинул вашу систему. Если хранить только запрос и ответ, команды поддержки начинают гадать, а любой плохой ответ выглядит одинаково.
Сначала запишите цель пользователя простыми словами. «Клиент хочет изменить дату доставки» — это понятная история. Сырой идентификатор кнопки вроде submit_flow_17 — нет. Одно короткое предложение даёт всем одинаковый контекст, даже если они не видели экран, где всё началось.
Затем сохраните состояние пользователя, которое сформировало запрос. Обычно сюда входят страница или шаг, тариф или тип аккаунта, язык, недавние действия и любые факты, которые приложение уже знало, например «счёт просрочен» или «возврат уже один раз был проверен». Эти детали объясняют, почему одинаковый запрос даёт разные результаты у разных людей.
Также нужно записать, что приложение ожидало от следующего шага. Может быть, система должна составить письмо, пометить тикет для человека, обновить поле или остановиться и попросить подтверждение. Когда результат не совпадает с ожидаемым действием, отладка идёт намного быстрее.
Для большинства небольших команд достаточно небольшого набора полей:
- короткое описание намерения, написанное для людей
- состояние пользователя, которое повлияло на запрос
- ожидаемое действие после ответа модели
- request ID, user ID и account ID
- точное время, часовой пояс и версия приложения
Эти идентификаторы важнее, чем кажется. Сотрудник поддержки может искать по аккаунту. Инженер может искать по request ID. У кого-то другого может быть только запись пользователя из billing-заметки или жалобы. Если одного из этих ID нет, цепочка часто рвётся.
Данные о времени и версии реально экономят время во время инцидентов. Если баг начался сразу после релиза мобильного приложения, обновления запроса или backend-деплоя, этот паттерн можно увидеть за минуты, а не читать разрозненные логи часами.
Почему время имеет значение
Если вы ждёте до вызова модели, чтобы записать историю, вы теряете именно ту часть, которая объясняет сбой. Тайм-аут, плохой ответ или ошибка API тогда выглядят как случайная поломка, а не как неудачная попытка сделать что-то конкретное для реального пользователя.
Событие должно существовать до отправки запроса. Вызов модели — только один шаг в более длинном действии. Полезная запись начинается в тот момент, когда пользователь нажимает, вводит, подтверждает или запускает workflow.
Небольшие команды чувствуют эту проблему особенно быстро. Когда один человек ведёт продукт, поддержку и разработку, у никого нет времени восстанавливать сломанный путь по разрозненным трассам. Событие до вызова даёт чистую стартовую точку простым языком: чего хотел пользователь, что увидело приложение и что система ожидала сделать дальше.
Сначала запись, потом вызов
Допустим, клиент просит отменить подписку и получить финальный счёт. Ваше приложение отправляет этот запрос в модель, чтобы классифицировать намерение и составить следующий шаг. Если вы логируете только после ответа модели, при неудачном вызове у вас почти ничего не останется. Вы будете знать, что API упал, но не будете знать, что именно просил клиент, какое состояние аккаунта было важно и собиралось ли приложение создать задачу для billing.
Если сначала записать бизнес-событие, сбой остаётся читаемым. Поддержка видит, что пользователь хотел отмену, у аккаунта был один открытый счёт, а модель так и не вернула пригодный ответ. Это сильно убирает гадание.
Вот в этот момент логирование бизнес-событий до вызовов модели перестаёт быть просто хорошей идеей и становится практической привычкой. Порядок меняет качество каждого последующего разбора.
Сохраняйте исходное состояние
Не перезаписывайте первое событие «очищенной» версией после вызова. Оставьте исходное состояние ровно таким, каким оно было в момент старта запроса. Если модель сломается, у вас всё равно останутся нетронутый вход, состояние пользователя в тот момент и точное намерение, которое приложение пыталось обработать.
Позже можно сравнить это намерение с ответом модели. Иногда модель отвечает не на тот вопрос. Иногда она даёт разумный ответ для устаревших данных аккаунта. Это разные проблемы, и время помогает их развести.
То же правило помогает с последующими задачами. После ответа система может поставить задачу в очередь, отправить письмо, обновить запись в CRM или открыть тикет. Когда эти шаги привязаны к более раннему событию, можно отследить, что именно выполнилось, а что остановилось. Без такого порядка команды часто обвиняют модель в багах, которые случились двумя шагами позже.
Хорошо выстроенное время превращает грязный инцидент в короткую временную линию, которую можно понять без пяти дашбордов.
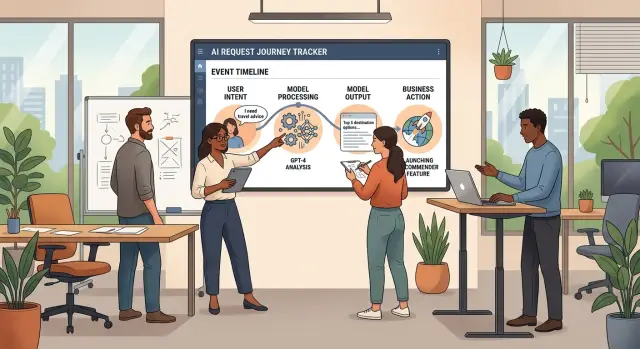
Простой поток событий
Небольшой команде от логов нужна одна вещь: история, которую можно быстро прочитать. Когда каждое действие пользователя оставляет след, который объясняет, чего хотел пользователь, что знало приложение, что сделала модель и что изменилось после этого, поддержка и разработка перестают спорить о том, где живёт баг.
Начните историю в тот момент, когда пользователь делает что-то реальное. Это может быть клик по «Сгенерировать ответ», запрос на возврат или загрузка файла на проверку. Создайте в этот момент один request ID и несите его через весь запрос.
Этот request ID должен связывать отслеживание намерения пользователя, вызов модели и каждое последующее обновление. Если модель падает или ломается следующий шаг, команда сможет идти по одной цепочке вместо поиска по трём системам.
Обычно достаточно простого потока:
request_started— кто действовал, где он действовал и какой у запроса IDcontext_saved— намерение, важные входные данные и текущее бизнес-состояниеmodel_called— какая модель запускалась, какую версию промпта вы использовали и зачемchange_recorded— каждое обновление, которое приложение сделало после ответаrequest_finished— успех, частичный успех или ошибка простыми словами
Второе событие делает большую часть работы. Ещё до того, как модель увидит хоть что-то, запишите бизнес-факты, которые объясняют ситуацию. Если пользователь просит приложение переписать письмо со счётом, сохраните статус счёта, тип клиента, язык и то, это первый черновик или follow-up. Это даёт контекст без необходимости читать сырые payload'ы.
Когда вы отправляете вызов модели, сохраняйте тот же request ID. Добавьте достаточно деталей для отладки, но оставьте запись читаемой. Короткая пометка вроде «черновик ответа по просроченному счёту» помогает гораздо больше, чем огромный blob внутренних данных.
После ответа модели логируйте каждое изменение в том порядке, в котором его делает приложение. Возможно, оно создаёт черновик, обновляет запись в CRM и отправляет уведомление. Если обновление CRM ломается после сохранения черновика, лог должен показать именно такую последовательность.
Заканчивайте финальным событием, где написано, что произошло обычным языком. «Черновик создан, но отправка письма не удалась, потому что у записи клиента нет адреса» намного лучше, чем process_error.
Это не должна быть большая система. Для многих команд пяти понятных событий на запрос достаточно, чтобы объяснить запутанный сбой за пару минут.
Кейс поддержки, который наконец складывается в понятную картину
Пользователь открывает чат поддержки и говорит: «Ваше приложение одобрило мой возврат, но ничего не произошло». На первый взгляд кажется, что модель выдумала лишнее. Поддержка видит дружелюбный ответ AI, ошибку обновления платежа и растерянного клиента.
Ситуация становится намного понятнее, когда команда записывает бизнес-события до вызова. Важна не только сама подсказка. Важнее то бизнес-состояние, которое существовало за секунду до ответа модели.
В этом случае пользователь попросил приложение вернуть деньги за последний заказ. Приложению уже было известно кое-что, что не было очевидно из ответа модели: у аккаунта был ожидающий hold на возврат из предыдущего запроса. Эта деталь жила в платежной системе и была важнее формулировки в чате.
Что показывает цепочка событий
Чистая цепочка событий рассказывает историю по порядку. Сначала система зафиксировала намерение пользователя как «возврат последнего заказа» с order ID и account ID. Затем приложение записало текущее состояние аккаунта, включая pending refund hold. Только после этого оно вызвало модель, чтобы составить ответ.
Модель написала вежливое сообщение об одобрении: «Я помогу с этим. Ваш возврат обрабатывается». Пользователю это звучало нормально, но это не меняло правила платежей.
Через мгновение платёжная задача проверила аккаунт и отклонила изменение возврата. Причина была простой. Возврат уже был в процессе, поэтому система не стала запускать второй.
Теперь поддержке не нужно гадать. События показывают понятную последовательность: пользователь попросил возврат, на аккаунте уже был активный hold, модель вернула язык в стиле одобрения, а платёжная задача заблокировала изменение, потому что hold всё ещё был активен.
Эта последовательность объясняет смешанные сигналы простыми словами. Модель была лишь частью проблемы. Приложение позволило модели говорить до того, как привязало сообщение к реальному бизнес-состоянию.
С такой цепочкой поддержка может ответить ясно: «На вашем аккаунте уже был открыт запрос на возврат, поэтому платёжная система заблокировала второй». Это гораздо лучше, чем говорить, что в системе произошла ошибка.
И у продуктовой команды появляется понятное исправление. Они могут блокировать язык одобрения, когда существует refund hold, или вообще пропускать модель для такого случая и возвращать прямое сообщение о статусе. В этом и есть настоящая польза бизнес-логирования событий и отслеживания последующих изменений. Это превращает запутанную AI-проблему в обычный продуктовый баг с понятной причиной.
Ошибки, из-за которых логи трудно использовать
Команды часто думают, что данных достаточно, потому что они сохранили запрос и ответ модели. Это не так. Такая запись показывает, что видела и сказала модель, но не показывает, что человек пытался сделать.
Если пользователь нажал «одобрить счёт», а ассистент ответил кратким summary, одного запроса не хватит, чтобы понять, не было ли у пользователя прав, не был ли счёт уже закрыт или не изменил ли запись другой job секунду назад. Обычно ответ лежит именно в недостающем бизнес-контексте.
Сырые дампы создают другую проблему. Инженеры ещё готовы терпеть огромный JSON-blob, но поддержка и founders обычно не будут его читать. Когда каждое событие — это просто payload за payload'ом, люди перестают пользоваться логами, потому что не могут быстро их просканировать.
Понятные подписи сильно помогают. invoice_approval_requested читать легче, чем стену из полей. trial_expired_blocked_checkout лучше, чем пытаться вывести причину из вложенного объекта. Сырые данные можно хранить, если они нужны, но рядом стоит ставить короткую человеческую метку.
Команды ещё и портят собственную историю, когда переименовывают события каждый спринт. В одном релизе это chat_start, в следующем conversation_opened, потом кто-то выпускает session_init. Теперь одно и то же действие выглядит как три разных тренда. Выберите одно имя события, держите его стабильным и добавляйте номер версии, когда меняются поля.
Ещё один частый пробел — состояние. Многие сбои понятны только тогда, когда вы логируете условия вокруг действия. Заблокированный аккаунт, истёкший план, отсутствующий документ или заблокированная запись могут быть важнее, чем ответ модели. Если это состояние пропустить, люди начинают обвинять модель в нарушении бизнес-правила.
Фоновая обработка делает проблему ещё хуже. Одно действие пользователя может запустить вызов модели, повторную попытку, job в очереди и последующее обновление через пять минут. Если не связать эти шаги с одним и тем же request ID или workflow ID, цепочка разваливается. Поддержка видит четыре несвязанные ошибки. Пользователь видел один клик.
Последующие изменения тоже должны попадать в цепочку. Если система создала черновик, отправила письмо, изменила статус или записала что-то в CRM, логируйте это простыми словами. Иначе вы знаете, что модель ответила, но всё ещё не знаете, что продукт на самом деле сделал.
Вот несколько простых правил, которые предотвращают большую часть таких проблем:
- логируйте намерение пользователя до вызова модели
- используйте короткие имена событий, которые можно прочитать
- держите названия стабильными между релизами
- записывайте бизнес-состояние, которое может заблокировать действие
- связывайте повторные попытки и фоновые задачи с исходным запросом
Если вы пропускаете этот контекст и вызов падает или повторяется, недостающая история исчезает. Тогда любой инцидент превращается в гадание.
Быстрая проверка перед релизом
Пропустите один сломанный запрос через staging и прочитайте цепочку событий так, как это сделал бы специалист поддержки. Вам нужна понятная история и быстро. Если человеку нужны три вкладки, запрос к базе и сообщение в Slack, чтобы понять, что случилось, логирование всё ещё слишком слабое.
Хороший review должен отвечать на пять простых вопросов:
- Звучат ли имена событий как бизнес-действия, которые человек может понять с первого взгляда?
- Можно ли увидеть, что именно хотел сделать пользователь, своими словами, а не названиями внутренних шагов?
- Видно ли состояние до запуска модели, например статус аккаунта, версию черновика, права доступа или выбранный язык?
- Можно ли проследить каждое изменение после ответа, включая записи, задачи в очереди, отправленные сообщения и пропущенные действия?
- Может ли коллега объяснить один неудачный запрос вслух меньше чем за минуту?
Имена важнее, чем многие команды ожидают. plan_change_requested говорит поддержке что-то полезное. pre_llm_step_2 — нет. Когда временная линия читается как короткий отчёт об инциденте, а не как дамп машины, люди действительно ею пользуются.
История пользователя должна оставаться видимой на всём протяжении запроса. «Пользователь попытался пересоздать счёт со старыми налоговыми настройками» — лучше, чем «промпт был собран и отправлен». Эта короткая строка даёт реальный контекст для отладки. Она ещё и уменьшает привычную игру в обвинения, когда поддержка винит модель, а разработка — плохой ввод.
Состояние до вызова — это место, где многие команды экономят не там, где нужно. Логируйте факты, которые формируют ответ: какую запись открыл пользователь, какая версия существовала, какие лимиты действовали и редактировал ли что-то человек до этого. Без такого снимка ответ модели висит в воздухе.
Затем проследите, что произошло после ответа. Приложение сохранило черновик? Отклонило вывод? Всё равно отправило уведомление? Отслеживание последующих изменений превращает расплывчатую жалобу в простое предложение.
Полезная заметка о сбое звучит примерно так: «Пользователь попросил переписать черновик контракта 3. Рабочее пространство было в режиме только для чтения. Модель вернула корректное summary, но шаг сохранения не удался, поэтому приложение показало устаревший текст и пропустило письмо». Один человек может прочитать это и понять, что чинить первым.
Если ваша команда не может собрать такую фразу из одной цепочки событий, не выпускайте это в прод.
Что делать дальше
Выберите один сценарий, который уже создаёт нагрузку на поддержку, и сначала добавьте логирование именно туда. Запрос на возврат, квалификация лида или изменение аккаунта — этого достаточно. Если на этой неделе вы сделаете только одно, начните записывать бизнес-события до вызовов модели в одном сценарии и посмотрите, что изменится.
Первую версию держите маленькой. Большинству команд лучше иметь пять понятных событий, которым они доверяют, чем двадцать, которые никто не читает. Базовый набор может выглядеть так: intent_received, user_state_checked, model_requested, action_applied и human_review_needed.
Эти названия важны. Если product, engineering и support используют одни и те же имена событий, сбой перестаёт звучать загадочно. Поддержка может сказать: «Система получила намерение пользователя, но действие не было применено», — и всем понятно, куда смотреть.
Используйте один и тот же принцип каждый раз, когда называете событие. Выберите формат вроде verb_noun и придерживайтесь его. Эта маленькая привычка быстро убирает путаницу, особенно когда разные люди читают логи под давлением.
Потом посмотрите на три недавних сбоя. Не десять. Только три. Прочитайте временную линию каждого и задайте два вопроса: чего хотел пользователь и что изменилось после вызова модели? Любой недостающий ответ показывает пробел в вашей схеме.
Скорее всего, вы заметите, что какие-то поля кажутся полезными, но в реальных инцидентах почти не помогают. Уберите их. Оставьте поля, которые команда читает каждый день: user ID, намерение запроса, имя модели, итог решения и последующее действие. Если никто не использует поле во время поддержки или отладки, это шум.
Ещё помогает делать логи читаемыми не только для инженеров. Если сотрудник поддержки не может объяснить цепочку событий клиенту за минуту, формулировка слишком техническая. Здесь выигрывает простой язык.
Реальный пример: пользователь просит изменить тариф, модель неверно понимает запрос, а billing обновляет не тот уровень. С чистыми бизнес-событиями команда видит исходное намерение, состояние пользователя до вызова, вывод модели и изменение billing, которое последовало за этим. Такая короткая цепочка может сэкономить долгий спор.
Если вам нужна вторая пара глаз, Олег Сотников на oleg.is работает со стартапами и небольшими командами над AI-first workflow, архитектурой продукта, инфраструктурой и поддержкой в формате Fractional CTO. Внешний разбор может помочь, когда команда понимает, что чего-то не хватает, но не может увидеть пробел ясно.
Лучший следующий шаг — маленький и практичный: разметьте один рискованный сценарий, разберите несколько сбоев, упростите схему и убедитесь, что поддержку можно читать без переводчика. Когда это заработает, переносите подход на следующий сценарий.
Часто задаваемые вопросы
Почему недостаточно логировать только запрос и ответ?
Потому что один только запрос и ответ показывают лишь то, что модель увидела и сказала. Они не показывают, чего хотел пользователь, какой записи он касался и что ваше приложение собиралось делать дальше.
Если сначала логировать намерение и бизнес-состояние, сбой читается как настоящая история, а не как случайная проблема с API.
Что нужно записывать до вызова модели?
Начните с одного короткого предложения о намерении на понятном языке, а затем сохраните состояние пользователя, которое повлияло на запрос. Добавьте такие вещи, как статус аккаунта, ID записи, экран или шаг, язык и то, что приложение ожидало сделать после ответа.
Также сохраните request ID, user ID, account ID, время, часовой пояс и версию приложения. Эти поля сильно упрощают поиск одного сломанного запроса по разным системам.
Когда лучше создавать событие?
Записывайте бизнес-событие до отправки запроса в модель. Если вызов зависнет или завершится ошибкой, у вас всё равно останется исходная причина запроса и состояние, которое приложение видело в тот момент.
Если ждать до ответа, вы потеряете именно ту часть, которая объясняет сбой.
Нужна ли большая система событий с самого начала?
Нет. Большинству небольших команд хватает маленького и одинакового по структуре потока. Часто пяти событий на один запрос достаточно, чтобы объяснить, что произошло.
Хорошо работает простой набор: запрос начат, контекст сохранён, модель вызвана, действие применено и запрос завершён.
Чем хорошее имя события отличается от плохого?
Используйте названия, которые звучат как бизнес-действия, а не как внутренняя механика. plan_change_requested сразу понятен. pre_llm_step_2 — нет.
Сохраняйте названия стабильными между релизами. Если меняются поля, добавляйте версию, а не переименовывайте одно и то же действие каждый спринт.
Нужны ли мне request ID, user ID и account ID?
Да. Один ID редко помогает во всём. Поддержка может искать по аккаунту, инженер — по request ID, а у billing может быть только запись пользователя.
Если сохранить все эти идентификаторы в одной цепочке, запрос можно найти с разных стартовых точек без догадок.
Нужно ли переписывать первое событие после ответа модели?
Оставьте первое событие ровно таким, каким оно было в момент старта запроса. Не заменяйте его «очищенной» версией после ответа модели.
Этот исходный снимок помогает сравнить намерение, состояние, ответ и последующие действия. Без него в цепочке легко спрятать устаревшие данные и неверные предположения.
Что считается последующим изменением?
Отслеживайте всё, что ваше приложение делает после ответа. Сюда входят сохранённые черновики, смена статуса, задачи в очереди, записи в CRM, уведомления, письма и шаги проверки человеком.
Эти изменения показывают, проблема в модели или в правилах и системах, которые сработали после неё.
Как понять, что наши логи действительно полезны?
Откройте один сломанный запрос и прочитайте цепочку как человек из поддержки. Если для объяснения проблемы нужны несколько инструментов и дополнительные сообщения, логов всё ещё слишком мало.
Хорошая цепочка позволяет одному коллеге вслух объяснить сбой меньше чем за минуту, простыми словами.
С чего лучше начать небольшой команде?
Выберите один сценарий, который уже создаёт нагрузку на поддержку, например возвраты, смену тарифа или обновление документов. Сначала добавьте туда небольшой набор понятных событий, а затем разберите несколько реальных сбоев и уберите поля, которыми никто не пользуется.
Такой подход быстро даёт практический результат. Когда схема заработает, переносите её на следующий рискованный сценарий.


