Библиотеки валидации и декодирования Go для более безопасных обработчиков
Библиотеки валидации и декодирования Go помогают раньше отбрасывать плохие данные, делать обработчики короче и упрощать тестирование и поддержку разбора запросов в Go.
Содержание
Почему плохие данные приводят к реальным багам
Большинство багов в обработчиках начинается ещё до того, как запускается бизнес-логика. Клиент отправляет "age": "ten" вместо числа или оставляет "email" пустым, а обработчик всё равно идёт дальше. Код может не упасть сразу, и из-за этого баг труднее отследить.
С JSON ситуация ещё хуже, потому что он может выглядеть аккуратно даже тогда, когда в нём ошибка. Опечатка вроде "frist_name" легко пройдёт, если декодер игнорирует неизвестные поля. Запрос выглядит валидным, хотя клиент так и не отправил ожидаемое поле.
Такие ошибки быстро расползаются. Вы сохраняете плохие данные, возвращаете неверную ошибку или ловите сбой через три функции. К этому моменту никто уже не хочет разбираться с исходным запросом.
Пустые обязательные поля создают другую проблему. Полезная нагрузка нормально декодируется в структуру Go, но нулевые значения просачиваются в бизнес-логику. Один пропущенный email или ID превращает короткий обработчик в набор проверок, которые потом повторяются в каждом downstream-функционале.
Несовпадения типов встречаются не реже. Query-параметры и значения форм приходят строками, а обработчик часто ждёт int, bool или дату. Если преобразование и проверка стоят рядом с вызовами базы и сервисным кодом, обработчик разрастается по неверной причине: он делает слишком много задач.
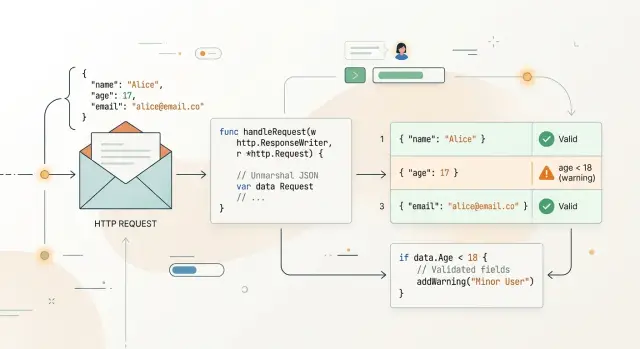
Хороший пример — signup-эндпоинт. Он ждёт целое число age, непустой email и никаких лишних полей. Если обработчик декодирует данные слишком свободно, "age":"18" может сломаться в одном месте, пустой email — в другом, а "emial" может вообще не вызвать ошибку. Пользователи получают непоследовательные сообщения, а команда — запутанный код.
Именно поэтому библиотеки валидации и декодирования Go так полезны. Строгое декодирование JSON в Go рано ловит неизвестные поля, а валидация запросов в Go не пускает в остальную часть приложения отсутствующие или испорченные данные. Итог простой: короче обработчики, понятнее ошибки и меньше багов, которые прячутся неделями.
Разделяйте декодирование и валидацию
Библиотеки валидации и декодирования Go работают лучше, когда вы считаете декодирование и валидацию двумя разными задачами. Декодирование берёт сырые данные из запроса и превращает их в структуру Go. Валидация проверяет, соответствуют ли значения в этой структуре вашим правилам.
Разница кажется небольшой, но она сильно меняет форму обработчика. Декодер отвечает на вопросы вроде: «Этот JSON валиден?» и «Могу ли я сопоставить эти поля с этой структурой?». Валидатор отвечает на другие: «Email пустой?», «Пароль слишком короткий?», «Клиент прислал значение вне допустимого диапазона?»
Когда вы смешиваете оба шага в одном блоке кода, обработчики быстро растут. Сначала идёт разбор, потом проверки полей, потом свои сообщения об ошибках — и вот уже один эндпоинт содержит 40 строк защитного кода до того, как начинает делать что-то полезное. Если разделить этапы, обработчик читается гораздо чище: декодировать, провалидировать, выполнить бизнес-логику, вернуть ответ.
Тестировать тоже проще. Можно проверить декодер на битом JSON, неверных типах или пропущенных query-значениях. А потом проверить валидацию на обычных структурах, без сборки полноценного HTTP-запроса каждый раз. Это экономит время, а по ошибке сразу видно, что именно пошло не так.
Хороший пример — signup-эндпоинт. Если тело содержит некорректный JSON, декодер должен отклонить его до запуска валидатора. Если JSON корректный, но email пустой или пароль короче восьми символов, валидация должна поймать это следующим шагом. У каждого этапа одна задача.
Чёткие границы ещё и упрощают замену инструментов позже. Можно оставить ту же структуру и бизнес-логику, но поменять декодер тела или перейти от ручных проверок к пакету валидатора. Обработчик остаётся компактным, потому что каждая часть делает меньше. Обычно именно это отличает код, которому легко доверять, от кода, который постоянно удивляет.
JSON-декодеры, которые быстро падают при ошибках
Большинство Go-обработчиков отлично справляются со стандартной библиотекой. encoding/json вместе с json.Decoder часто более чем достаточно, и это ещё один пакет меньше в проекте.
json.Decoder лучше подходит для HTTP-обработчиков, чем json.Unmarshal, потому что он читает прямо из r.Body и позволяет включать более строгие правила. Это важно, когда вы хотите, чтобы плохие данные ломались сразу, а не проскальзывали дальше и вызывали странные баги позже.
Первое правило, которое стоит включить, — DisallowUnknownFields(). Без него клиент может отправить {\"emali\":\"[email protected]\"}, и Go молча проигнорирует опечатку, если в структуре ожидается Email. Обработчик может принять запрос, но пользователь получит сломанный результат. Строгое декодирование JSON в Go помогает избежать такого тихого сбоя.
UseNumber() помогает, когда числа должны оставаться точными. Особенно это важно, если вы декодируете в map[string]any или другие динамические типы. Без него декодер превращает числа в float64, а это может испортить большие ID и другие значения, которые вы не хотите округлять.
Небольшой общий помощник
Один общий помощник для декодирования держит все JSON-эндпоинты на одних и тех же правилах. И заодно делает обработчики короче.
func decodeJSONBody(r *http.Request, dst any) error {
dec := json.NewDecoder(r.Body)
dec.DisallowUnknownFields()
dec.UseNumber()
if err := dec.Decode(dst); err != nil {
return err
}
if err := dec.Decode(&struct{}{}); err != io.EOF {
return errors.New("body must contain a single JSON value")
}
return nil
}
Второй вызов Decode ловит лишний мусор после первого JSON-объекта, и это легко пропустить.
Такой помощник даёт каждому обработчику одинаковое поведение. Он отклоняет неизвестные поля, сохраняет точность больших чисел, не пропускает несколько JSON-значений в одном теле и декодирует данные в типизированную структуру, а не в рыхлые map. Когда команда пропускает этот шаг, каждый обработчик начинает жить по собственным правилам разбора. Именно так появляются непоследовательные ошибки.
Декодеры для query и form, которые стоит знать
gorilla/schema по-прежнему остаётся практичным вариантом для query-строк и form-данных. Он превращает url.Values в структуру, и обработчику больше не приходится таскать Get(), Atoi() и повторяющиеся if-блоки. Так шумный код разбора остаётся в одном месте, а форму запроса легко проверить глазами.
Он также аккуратно работает с повторяющимися параметрами. Если запрос отправляет tag=go&tag=api&tag=backend, это можно декодировать прямо в []string вместо ручного разбиения строк. То же самое подходит для групп чекбоксов в формах, где одно поле может передавать несколько значений.
type SearchInput struct {
Query string `schema:"q"`
Tags []string `schema:"tag"`
Page int `schema:"page"`
Limit int `schema:"limit"`
}
func readSearchInput(r *http.Request) (SearchInput, error) {
input := SearchInput{
Page: 1,
Limit: 20,
}
dec := schema.NewDecoder()
dec.IgnoreUnknownKeys(false)
if err := dec.Decode(&input, r.URL.Query()); err != nil {
return SearchInput{}, err
}
return input, nil
}
Значения по умолчанию здесь важны. Задавайте их в коде инициализации структуры, а не разбрасывайте потом по обработчику резервные варианты. Когда ревьюер откроет файл, он должен сразу видеть Page: 1 и Limit: 20.
Для form-отправок вызовите r.ParseForm() и декодируйте r.Form тем же способом. В итоге у вас один и тот же паттерн для query и form-input, а это делает обработчики последовательнее. Команды обычно пишут меньше багов, когда каждый путь запроса выглядит одинаково: декодировать, провалидировать, вернуть ошибки полей, потом выполнить бизнес-логику.
Используйте один и тот же формат ошибок для body, query и form-input. Если ошибки JSON возвращаются одним видом, а ошибки query — другим, клиентам приходится писать лишние условные ветки без всякой пользы. Достаточно простого формата:
source:body,queryилиformfield: имя входного поляmessage: простое понятное описание проблемы
Это значит, что page=abc в query-строке и неверный email в форме могут падать знакомым образом. Канал передачи меняется, а контракт остаётся тем же. Такая небольшая последовательность делает API проще тестировать и заметно приятнее использовать.
Пакеты валидации, которые подходят разным командам
Среди библиотек валидации и декодирования Go две покрывают большую часть повседневных задач: go-playground/validator и ozzo-validation. Обе помогают рано отбрасывать плохие данные, но ощущаются по-разному, когда вы читаете и поддерживаете код.
Используйте go-playground/validator, если вашей команде нравятся struct tags и правила в основном простые — проверки отдельных полей. Он держит распространённые правила рядом со структурой запроса, и маленькие обработчики легче просматривать. signup-запрос с полями вроде email, password и age может нести большую часть проверок прямо в структуре.
Используйте ozzo-validation, если вам удобнее задавать правила в коде Go, а не в тегах. Такой стиль проще читать, когда правила зависят друг от друга, часто меняются или требуют кастомной логики. Некоторым командам он нравится потому, что валидация выглядит как обычный код, а не как компактный язык тегов.
Если форма запросов у вас стабильная, а правила — привычные вещи вроде required, email, min или max, go-playground/validator обычно отлично подходит. Если валидация содержит ветвления, собственные сообщения или правила, завязанные на бизнес-контекст, ozzo-validation часто удобнее в долгую.
По возможности держите базовые правила рядом со структурой запроса. Обычно это значит, что длина, формат, обязательность и допустимые значения остаются рядом с типом входных данных. Это экономит время, потому что читателю не нужно искать по сервисному коду, чтобы понять, почему запрос не прошёл.
Валидируйте сразу после декодирования, до любого вызова сервиса или работы с базой данных. Если в запросе нет email или пришла некорректная дата, верните ошибку прямо там. Не начинайте транзакцию, не вызывайте другой сервис и не создавайте лишние объекты заранее. Такая привычка держит обработчики короткими и отсекает целый класс избежимых багов.
Хорошее правило простое: проверки формы запроса оставляйте на границе, а дальше передавайте в приложение чистые данные. Бизнес-код становится меньше, а путь ошибки — намного понятнее.
Простой поток обработки запроса
Обработчику легче доверять, когда он каждый раз следует одному и тому же порядку. Большинство библиотек валидации и декодирования Go хорошо ложатся в этот шаблон, и сам шаблон важнее названия пакета.
Сначала ограничьте размер тела запроса ещё до чтения. Небольшой лимит, например 1 MB для обычной JSON-формы, защищает от случайно огромных payload и дешёвых злоупотреблений. Так же он делает сбои понятными: запрос слишком большой, значит обработчик останавливается рано.
Затем декодируйте данные в request-структуру, которая принадлежит конкретному эндпоинту. Не декодируйте сразу в доменную модель. signup-запрос может содержать password_confirm, сырые строки или необязательные поля, которые бизнес-объекты вообще не должны хранить. Разделение транспортных данных и внутренних моделей делает следующий шаг гораздо чище.
Хороший поток выглядит так:
- Ограничьте размер тела запроса.
- Декодируйте JSON, query или form-данные в request-структуру.
- Отклоняйте неизвестные поля и неправильные типы во время декодирования.
- Запускайте валидацию и собирайте ошибки по полям.
- Вызывайте бизнес-логику только с чистыми, типизированными данными.
Третий шаг экономит много времени потом. Если клиент отправляет age: "twenty" или добавляет поле, которое ваш API не принимает, ошибка должна возникнуть сразу. Строгое декодирование JSON в Go помогает поймать такие ошибки до того, как они просочатся в логи, вызовы базы данных или странные nil-проверки глубже в приложении.
Валидация идёт после декодирования, потому что лучше всего работает уже на типизированных данных. Когда структура заполнена, можно проверить обязательные поля, формат email, ограничения длины или допустимые значения. Если неправильно заполнены два или три поля, возвращайте сразу все ошибки по полям. Люди быстрее исправляют формы, когда видят полный список в одном ответе.
Типичная ошибка — смешивать эти этапы. Обработчик немного декодирует, немного валидирует, потом вызывает бизнес-код и надеется, что остальное поймается там. Так правила расползаются по кодовой базе. Оставляйте обработчик строгим на границе и передавайте внутрь только чистые данные. Сервисный код становится меньше, а ошибки проявляются ближе к настоящей причине.
Пример: signup-эндпоинт
Signup-обработчик — хорошее место, чтобы стать строже. Запрос маленький: email, пароль и необязательный referral code. Это позволяет легко отбрасывать плохие данные раньше и держать остальной код чистым.
Тип запроса может выглядеть так:
type signupRequest struct {
Email string `json:"email" validate:"required,email"`
Password string `json:"password" validate:"required,min=8"`
ReferralCode string `json:"referralCode" validate:"omitempty,alphanum"`
}
При строгом декодировании JSON в Go обработчик должен упасть на неизвестных полях ещё до запуска валидации. Если клиент отправит "pasword" вместо "password", это не мелкая опечатка. Это значит, что сервер вообще не получил поле, которое ему нужно. Декодер с DisallowUnknownFields() может остановить запрос прямо там и вернуть прямую ошибку.
Так клиент получает полезный ответ вместо расплывчатого «некорректный запрос»:
{
"errors": {
"pasword": "unknown field"
}
}
Если JSON по форме валиден, go-playground/validator может проверить содержимое. Пустой email должен провалиться. Пароль длиной пять символов — тоже. Referral code может оставаться необязательным, но если клиент его прислал, можно проверить и формат.
Ответ тоже может оставаться простым и конкретным:
{
"errors": {
"email": "email is required",
"password": "password must be at least 8 characters"
}
}
После этого у обработчика задача становится проще. Ему не нужно угадывать, чего не хватает, исправлять имена полей или протаскивать полусломанные данные глубже в приложение. Он может собрать доверенную входную структуру и спокойно передать её в сервисный слой.
Именно последний шаг особенно важен. Сервис должен получать данные, которые уже прошли декодирование и валидацию. Тогда он может сосредоточиться на бизнес-правилах, например проверить, существует ли уже email или активен ли referral code, а не разбирать ошибки запроса с сетевой границы.
Ошибки, из-за которых обработчикам трудно доверять
Обработчики ломаются, когда принимают слишком много, делают слишком много и слишком многое раскрывают. Сначала код может казаться коротким, но ошибки быстро становятся дорогими.
Распространённая ошибка — декодировать данные запроса прямо в модель базы. Так внешний ввод связывается с полями, которые вы не собирались открывать. Пользователь отправляет одно лишнее JSON-поле, и теперь обработчик может перезаписать внутренние флаги, статусы или timestamp-значения, которые должны находиться под контролем сервера.
Использовать одну структуру для всего — та же проблема. Тело запроса, query-параметры и сохранённая запись решают разные задачи. Если вы используете одну структуру для всех трёх, стирается грань между «что клиент может отправить» и «что приложение может хранить». Маленькие приложения какое-то время это переживают. Большие обычно потом жалеют.
Разрешать неизвестные поля ради видимой гибкости — тоже плохая сделка. Сначала это кажется дружелюбным, но потом скрывает баги клиента. Если клиент отправит "emial" вместо "email", строгое декодирование JSON в Go должно отклонить его сразу. Молчаливое принятие превращает понятную ошибку в сломанное поведение позже.
Проблемы начинаются и тогда, когда один блок кода совмещает проверку авторизации, разбор, валидацию, бизнес-правила и запись в базу. Тогда все ошибки выглядят одинаково, а любое изменение рискует принести новый баг. Разделяйте поток на шаги: определить пользователя, декодировать вход, провалидировать его, выполнить действие, потом собрать ответ. Так тесты становятся меньше, а код обработчика — понятнее.
С сообщениями об ошибках тоже нужно быть аккуратными. Сырые ошибки декодера помогают разработчикам во время локальной проверки, но клиентам они часто раскрывают имена полей, внутренние типы или детали парсера. Лучше вернуть чистое сообщение вроде invalid request body или email must be a valid address, а полную ошибку залогировать на сервере.
Хорошие библиотеки валидации и декодирования Go помогают, но сами по себе не исправят неудачный дизайн. Безопасный шаблон выглядит просто:
- используйте request-структуру только для входных данных
- отклоняйте неизвестные поля
- валидируйте после декодирования
- сопоставляйте чистый ввод с доменной или database-моделью
- возвращайте короткие и понятные ошибки клиенту
Такой подход добавляет несколько строк. Но убирает очень много сомнений.
Быстрые проверки перед релизом
Хорошая схема для библиотек валидации и декодирования Go работает только тогда, когда каждый обработчик следует одним и тем же правилам. Если один эндпоинт использует строгое декодирование JSON, а другой тихо игнорирует мусорные поля, баги появятся очень быстро.
Начните с формы запроса. Дайте каждому эндпоинту свою request-структуру, даже если два эндпоинта похожи друг на друга. signup-запрос и запрос на обновление профиля могут иметь общие поля, но означают они разное и почти никогда не стареют одинаково.
Чеклист перед релизом
Перед запуском проверьте эти пункты по всему приложению:
- У каждого эндпоинта есть одна request-структура с именами и тегами, которые совпадают с контрактом API.
- Все обработчики вызывают один и тот же helper для декодирования, а он по умолчанию отклоняет неизвестные JSON-поля.
- В приложении создаётся один экземпляр валидатора, и он переиспользуется, вместо того чтобы собирать правила в каждом обработчике.
- Каждый обработчик возвращает ошибки в одном формате, с одинаковыми именами полей и логикой статус-кодов.
- Тесты покрывают отсутствующие поля, неправильные типы и лишние поля, которые клиенты не должны отправлять.
Второй пункт экономит больше времени, чем кажется. Если клиент отправит "emial" вместо "email", строгое декодирование должно сразу упасть. Молчаливое принятие сначала кажется удобным, а через две недели превращается в проблему для поддержки.
Один общий экземпляр валидатора тоже успокаивает код. Пользовательские правила, имена тегов и переведённые сообщения остаются в одном месте. Обработчики остаются короткими, потому что они просто декодируют, валидируют и передают чистые данные сервисному слою.
Делайте формат ошибок скучным и одинаковым. Если один обработчик возвращает {"error":"bad request"}, а другой — список проблем по полям, клиентам придётся писать лишнюю специальную логику без всякой причины. Выберите один формат и используйте его везде.
Тесты делают финальную зачистку. Для signup-эндпоинта отправьте пустое тело, строку там, где должно быть число, и одно лишнее поле, которое структура не разрешает. Если все три случая падают одинаково и понятно, обработчик, скорее всего, готов.
Что делать дальше
Начните с тех обработчиков, которые получают больше всего трафика или несут больше всего риска. Signup, login, checkout, сброс пароля, административные импорты и публичные webhooks обычно заслуживают внимания в первую очередь. Плохой путь декодирования в одном из этих эндпоинтов может надолго отнять время у поддержки.
Возьмите три или четыре обработчика и прочитайте их построчно. Если в одном блоке смешаны JSON-парсинг, значения по умолчанию, валидация, бизнес-правила и форматирование ошибок, приведите это в порядок до того, как добавите новые эндпоинты. Небольшие исправления здесь часто убирают проблемы копипаста по всему остальному коду.
После сравнения библиотек валидации и декодирования Go перестаньте искать и выберите один небольшой стек, которым команда действительно будет пользоваться. Команда получает больше пользы от одинаковой обработки запросов, чем от вечной погони за «лучшим» пакетом.
Хороший следующий шаг выглядит так:
- используйте один helper для JSON-декодирования и заставьте его отклонять неизвестные поля
- используйте один декодер для query- или form-входа вместо ручного разбора
- валидируйте request-структуры в одном месте, с одинаковыми правилами тегов везде
- возвращайте один и тот же формат ошибок для любого плохого запроса
- добавьте table tests и для принимаемых, и для отклоняемых данных
Сделайте это до того, как добавите следующую партию эндпоинтов. Если каждый новый обработчик следует одному и тому же шаблону, ревью идут быстрее, а баги заметить легче. Новым инженерам тоже проще встраиваться, потому что им не нужно гадать, как каждый эндпоинт обращается с плохими данными.
Ещё полезно получить внешний взгляд на ваш pipeline запросов. Свежий взгляд часто замечает слабые места, которые команда перестала видеть: поля, которые молча теряются при декодировании, сообщения об ошибках, меняющиеся от роуту к роуту, или правила валидации, лежащие не в том слое.
Если вашей команде нужен именно такой разбор, Oleg на oleg.is делает такую работу в рамках fractional CTO advisory. Для backend-команд короткий архитектурный разбор обработки запросов и дизайна API-ошибок может сэкономить много исправлений позже.
Лучший результат — это скучный код: короткие обработчики, строгие правила входных данных и ошибки, которые каждый раз выглядят одинаково.
Часто задаваемые вопросы
Почему стоит разделять декодирование и валидацию?
Разделяйте их, потому что они решают разные задачи. Декодирование проверяет, совпадают ли форма запроса и типы со структурой. Валидация проверяет, имеют ли уже декодированные значения смысл, например, не пустой ли email или не слишком ли короткий пароль. Когда эти шаги разделены, обработчики остаются компактными, а ошибка быстрее указывает на настоящую причину.
Что именно делает DisallowUnknownFields()?
Он говорит JSON-декодеру отклонять поля, которых нет в вашей структуре. Так сразу ловятся опечатки вроде emial, вместо того чтобы тихо игнорировать их и получать странное поведение позже.
Зачем использовать json.Decoder вместо json.Unmarshal в обработчиках?
json.Decoder читает данные прямо из r.Body, поэтому он лучше подходит для HTTP-обработчиков. Кроме того, он позволяет включить строгие правила вроде DisallowUnknownFields() и UseNumber(), чтобы раньше отбрасывать плохие данные.
Когда нужен UseNumber()?
Используйте его, когда декодируете в динамические типы вроде map[string]any и вам нужны точные числа. Без него Go превращает числа в float64, а это может испортить большие ID или значения, которые нельзя округлять.
Как обрабатывать query-параметры и form-данные?
Используйте общий декодер вроде gorilla/schema, чтобы убрать разбор query и form из логики обработчика. Вы декодируете в структуру, задаёте значения по умолчанию в одном месте и перестаёте повторять Get(), Atoi() и проверки ошибок в каждом роуте.
Стоит ли декодировать запросы напрямую в модель базы данных?
Нет. Декодируйте в request-структуру, которая принадлежит конкретному эндпоинту. Так поля транспорта, например password_confirm, не смешиваются с сохраняемыми данными, и клиенты не могут трогать значения, которые им не должны принадлежать.
В каком порядке должен работать безопасный обработчик?
Сначала ограничьте размер тела запроса, затем декодируйте его в request-структуру, отклоняйте неизвестные поля и неправильные типы, после этого запускайте валидацию и только потом вызывайте бизнес-логику. Такой порядок оставляет ошибки запроса на краю приложения.
Как должны выглядеть ответы API с ошибками?
Оставьте один скучный и одинаковый формат везде. Возвращайте источник данных, имя поля и понятное сообщение, которое клиент сможет исправить. Клиентам не нужен один парсер для ошибок JSON и другой для ошибок query или form.
Какой пакет валидации выбрать?
Выбирайте go-playground/validator, если команде нравятся struct tags и в основном нужны проверки вроде обязательных полей, формата email и длины. Выбирайте ozzo-validation, если хотите правила в коде Go, потому что они часто меняются или зависят от других полей.
Что нужно протестировать перед релизом обработчика?
Проверяйте то, что реально ломает обработчики: битый JSON, неправильные типы, отсутствующие обязательные поля, лишние поля и слишком большие тела запроса. Заодно убедитесь, что все роуты возвращают одинаковый формат ошибок, чтобы клиентам было проще предсказывать поведение.


