Библиотеки Node.js для событийных приложений, которые остаются портативными
Сравните библиотеки Node.js для событийных приложений с ретраями, потоками outbox и удобным локальным тестированием, чтобы код можно было переносить между брокерами.
Содержание
Почему привязка к брокеру становится проблемой
Обычно привязка начинается с удобства. Команда выбирает Kafka, RabbitMQ или Redis, а потом вставляет вызовы брокера прямо в логику заказов, код биллинга и фоновые воркеры. Сначала это кажется быстрым решением. Через несколько месяцев приложение уже не говорит о событиях простым языком. Оно говорит о топиках, exchange, правилах маршрутизации и очередях ретраев конкретного брокера.
Это меняет то, как люди пишут код. Вместо того чтобы публиковать обычное доменное событие и отдавать доставку адаптеру, разработчики начинают подстраивать бизнес-правила под возможности брокера. Обработчик возврата денег может зависеть от поведения партиций Kafka. Воркер для писем может рассчитывать на dead-letter-механику RabbitMQ. В этот момент брокер уже не просто инфраструктура. Он становится частью логики продукта.
Локальная разработка тоже усложняется. Обычный прогон тестов теперь требует Docker Compose, seed-скриптов, настройки брокера и часто ещё одного инструмента для просмотра сообщений. Новые разработчики тратят слишком много времени на запуск стека. На проверку того, делает ли код правильную вещь, времени остаётся меньше.
Ретраи только усугубляют ситуацию. Один сервис использует задержки брокера, другой — setTimeout, а третий кладёт упавшие задачи в таблицу и потом периодически опрашивает её. Проверки идемпотентности оказываются размазанными по хендлерам, контроллерам и cron-задачам. Система по-прежнему работает, но разбирать сбои становится трудно, потому что каждый путь подчиняется своим правилам.
Самая дорогая часть проявляется позже, когда команда хочет всё поменять. Может быть, Kafka кажется слишком тяжёлой для небольшого продукта. А может, Redis-задачи сначала устраивали, но потом понадобились более надёжная доставка или понятный аудит. Если бизнес-код везде обращается к брокеру напрямую, это уже не простая замена адаптера. Разработчикам приходится одновременно трогать хендлеры, тесты, логику ретраев, наблюдаемость и скрипты деплоя.
Вот почему архитектура Node.js без привязки к брокеру так важна. Если приложение описывает события один раз и передаёт доставку тонкому адаптеру, замена брокера становится рутинной задачей. Если нет, брокер становится частью кодовой базы, и каждое будущее изменение стоит дороже, чем должно.
Как сделать приложение независимым от брокера
Портативность начинается с самого события. Определяйте доменные события как обычные TypeScript-объекты, которые описывают то, что произошло в бизнесе, например OrderPaid или InvoiceSent. Держите payload только с бизнес-данными. Если событие имеет смысл только потому, что конкретный брокер добавляет к нему особые поля, ваше приложение уже зависит от этого брокера.
Используйте одну и ту же схему и при отправке, и при получении событий. Здесь хорошо подходят Zod или TypeBox. Проверяйте данные перед публикацией, а потом ещё раз в consumer. Звучит избыточно, но это экономит время, когда один сервис меняет имя поля или отправляет объект не той формы. А ещё так гораздо проще работать локально, потому что хендлеры можно проверять обычными объектами.
Большинству команд нужен совсем небольшой слой между кодом приложения и кодом сообщений:
- функция
publish(event) - функция
subscribe(eventName, handler) - одна схема на каждый тип события
- один адаптер для каждого брокера
Именно этот слой важнее, чем клиент конкретного брокера. Ваш сервис заказов должен вызывать publish, а не Kafka- или RabbitMQ-SDK напрямую. Если позже вы перейдёте с Redis Streams на NATS, вы замените адаптер, а не перепишете бизнес-логику.
Держите служебные метаданные доставки вне бизнес-кода. Номер попытки, message ID, настройки задержки, информация о партиции и детали dead-letter должны жить в envelope или транспортном слое. Хендлеру важны orderId и paidAt, а не заголовки брокера.
Пишите хендлеры так, чтобы их можно было запустить дважды без вреда. Дублированная доставка встречается в любой серьёзной системе. Обработчик платёжного события может сначала проверить, не пометил ли он уже заказ как оплаченный, прежде чем отправлять ещё один чек или снова менять остатки на складе. Эта привычка сильно снижает риск при смене брокера, потому что разные системы ретраят и повторно доставляют сообщения по-разному.
Небольшие event-библиотеки внутри одного сервиса
Многое в событийной архитектуре начинается внутри одного процесса Node.js, а не с брокера. Во многих случаях библиотеки Node.js для событийных приложений особенно полезны именно на этом этапе: они помогают разделить действия и реакции ещё до того, как вы окончательно выберете Kafka, NATS или что-то другое.
EventEmitter2 хорошо подходит, когда одно действие должно запускать несколько внутренних хендлеров. Его wildcard-слушатели удобны, если вы называете события группами вроде user.* или billing.invoice.*, потому что код логирования, метрик или аудита может подписываться на них, не смешиваясь с основной бизнес-логикой.
Emittery — хороший вариант, когда хочется чего-то поменьше и с async по умолчанию. API у него простой, а promise-based listeners помогают лучше видеть, когда хендлер реально делает работу, например отправляет письмо или обновляет кэш.
Эти библиотеки должны оставаться внутри одного процесса. Они не переносят сообщения между контейнерами, не переживают перезапуск и не дают гарантий доставки. Если приложение запущено в трёх экземплярах Node.js, у каждого будет свой локальный bus.
Но это ограничение полезно, а не раздражает. Локальный event-слой даёт вам точку разделения: сервис может уже сейчас чётко эмитить бизнес-события, а позже вы сможете направить часть из них в таблицу outbox или в брокер, почти не переписывая код.
Простой пример помогает понять идею. Когда пользователь регистрируется, приложение может один раз эмитить user.created, а дальше отдельные хендлеры отправят приветственное письмо, создадут настройки по умолчанию и запишут аудиторский след. Код регистрации остаётся компактным, а вы видите, какие события достаточно стабильны, чтобы сохранить их и при росте системы.
Если вам нужны ретраи после перезапуска или доставка между сервисами, добавите это позже. Сначала сделайте названия событий и payload внутри сервиса чистыми.
Клиенты брокеров, которые можно заменить позже
Первый клиент брокера часто расползается по всему проекту. Вскоре ваши хендлеры уже знают о партициях Kafka, routing keys RabbitMQ или stream ID Redis. Когда это происходит, смена брокера быстро становится дорогой.
Выбирайте клиент, который подходит под текущий стек, а потом спрячьте его за одним небольшим адаптером.
- Используйте kafkajs, если Kafka уже есть в вашем стеке. Он даёт consumer group и admin-функции, которые нужны большинству команд, не заставляя бизнес-код думать об offsets.
- Используйте amqplib, если вам нужен RabbitMQ и полный контроль AMQP. Это низкоуровневый инструмент, и это полезно, но этот уровень должен оставаться рядом с транспортным слоем.
- Используйте nats, если вам нужен более компактный клиент. Его легко понять, и он хорошо подходит для простых схем publish-subscribe или request-reply.
- Используйте ioredis для лёгкого pub-sub или тестов с Redis Streams. Он удобен для локальной работы и ранних экспериментов, но не позволяйте особенностям Redis формировать всё приложение.
Хороший адаптер остаётся скучным. Обычно ему нужно всего несколько методов, например publish, subscribe и, возможно, ack, если этого требует модель доставки. Сохраните внутри адаптера имена сообщений, валидацию payload, сериализацию, заголовки и метаданные ретраев.
Ваш сервис заказов, биллинга или email-воркер должен получать обычные данные и возвращать обычные результаты. Он не должен знать, какой клиент подключён, как закодировано сообщение и какой брокер обеспечил доставку.
Такая граница полезна и в тестах. Реальный клиент можно заменить in-memory-фейком и проверить, как хендлеры реагируют на события, а не на детали транспорта. Команды, которые живут с компактной инфраструктурой, часто полагаются на этот подход, потому что он упрощает локальную разработку и избавляет от переписывания, когда выбор брокера меняется позже.
Инструменты для ретраев и отложенных задач
Ретраи звучат просто, пока каждый хендлер не начинает придумывать свои правила. Одна задача ждёт 5 секунд, другая пытается бесконечно, а третья прячет настоящую ошибку в логах. Перенесите эту логику в слой воркера. Бизнес-код должен решать, можно ли повторять действие. Очередь должна решать, когда и сколько раз.
BullMQ — практичный выбор, если Redis уже используется в вашем стеке. Он даёт отложенные задачи, счётчик попыток, backoff, управление concurrency и обработку ошибок почти без настройки. Для задач вроде «попробовать списать платёж ещё раз через 10 минут» или «отправить follow-up письмо завтра» он выглядит просто и понятно.
Если хочется меньше движущихся частей, воркеры на Postgres часто оказываются удобнее.
- pg-boss подходит командам, которые уже доверяют Postgres в плане надёжности и не хотят добавлять Redis только ради задач.
- Graphile Worker очень прост в локальной разработке и хорошо работает, когда приложение и так вращается вокруг Postgres.
- BullMQ обычно лучше подходит, когда ожидается большой объём задач или Redis уже используется для кэша и сессий.
Это полезные библиотеки Node.js для событийных приложений, потому что они решают вопросы времени и повторов, не заставляя каждый хендлер содержать собственную логику ретраев.
Воркер для синхронизации платежей не должен содержать самодельные циклы и вызовы sleep. Задайте максимальное число попыток, правила задержки и backoff в одном месте. Тогда хендлер останется коротким: загрузить данные, вызвать API, сохранить результат, выбросить ошибку при сбое.
Также сохраняйте номер попытки и последнюю ошибку. Команде поддержки важно понимать, упала ли задача один раз из-за таймаута или шесть раз подряд, потому что внешний API продолжал отклонять запрос. Эта небольшая история экономит много времени, когда что-то ломается.
Graphile Worker и pg-boss особенно приятны на ноутбуке, потому что одного экземпляра Postgres часто достаточно. BullMQ тоже хорош локально, но только если Redis уже поднят в dev и test.
Варианты реализации паттерна outbox
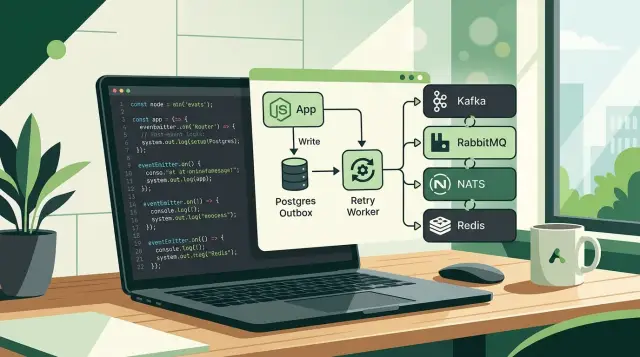
Паттерн outbox решает частую проблему: приложение сохраняет запись, а потом падает до публикации события. Чтобы избежать этого разрыва, бизнес-изменение и строку outbox нужно записывать в одной и той же транзакции базы данных. Если запись заказа прошла, строка события тоже должна сохраниться. Если транзакция не удалась, не останется ни одного из них.
Большинство команд делает это с помощью того слоя базы данных, который уже использует. Prisma, Drizzle, Knex и TypeORM умеют сохранять бизнес-данные и запись outbox вместе. Держите таблицу простой: имя события, payload, ID агрегата, время создания, статус и, возможно, счётчик попыток. Простые таблицы легче отлаживать в два часа ночи.
После этого запускается poller. Он читает новые строки outbox, публикует каждое событие и ждёт, пока брокер примет сообщение. Только после этого приложение должно пометить строку как отправленную. Если публикация не удалась, оставьте строку в pending или запишите ещё одну попытку. Так у вас появится понятный путь восстановления, а паттерн outbox в Node.js останется скучным в хорошем смысле.
Простой поток заказа выглядит так:
- Сохранить заказ и строку outbox в одной транзакции.
- Опросить неотправленные строки каждые несколько секунд.
- Опубликовать событие.
- Пометить строку как отправленную после подтверждения от брокера.
Если Postgres уже стоит в центре вашего стека, pg-boss или Graphile Worker могут сэкономить много времени. Оба варианта хорошо подходят, когда вам нужны ретраи, расписания и локальное тестирование без добавления ещё одной сущности в первый же день. Для многих небольших команд это правильный компромисс: меньше систем, проще отладка и есть путь сменить брокер позже, если приложение вырастет.
Настройка локальной разработки маленькими шагами
В первый день Kafka вам не нужна. Для локальной событийной разработки начните с Postgres или Redis и небольшого worker-процесса. Этого достаточно, чтобы смоделировать события, ретраи и паттерн outbox в Node.js без четырёх лишних причин для отладки.
Обычно простая схема включает три сервиса:
- приложение, которое пишет бизнес-данные и записи событий
- воркер, который читает события и доставляет их
- Postgres или Redis для хранения и очередей
Docker Compose делает это удобным. Одна команда должна поднимать весь стек, чтобы новый разработчик мог запустить приложение, вызвать действие и увидеть, как событие проходит через систему, за несколько минут.
Сделайте сбой заметным
Локальные настройки ломаются тихо. Сообщение может упасть, исчезнуть в логах, и никто этого не заметит. Сохраняйте неудачные доставки в таблице или очереди, которую можно просмотреть обычным запросом. Добавьте туда ошибку, число попыток, время следующей попытки и payload события.
Этот небольшой шаг быстро окупается. Когда кто-то меняет схему или ломает хендлер, команда видит, что именно сломалось, а не гадает.
Seed-скрипт тоже помогает сильнее, чем ожидают многие команды. Он должен создавать несколько реалистичных записей и публиковать примеры событий вроде order.created или invoice.sent. Хорошие тестовые данные превращают пустое локальное окружение в то, что можно проверить меньше чем за минуту.
Проверьте один неприятный случай
Запустите один тест, который убивает соединение с брокером или очередью в середине доставки. Потом проверьте, что воркер делает ретрай, ждёт и не теряет сообщение. Если этот тест падает, локальная среда говорит вам что-то полезное заранее, пока исправление ещё дешёвое.
Именно здесь многие библиотеки Node.js для событийных приложений либо выглядят практичными, либо начинают раздражать. Хорошая библиотека позволяет прогнать этот сценарий отказа без специальных облачных сервисов, скрытых демонов и горы конфигурационных файлов.
Сохраните первую версию скучной. Если Postgres плюс воркер чисто обрабатывают локальный поток, добавляйте RabbitMQ или Kafka позже — только когда трафик или размер команды действительно дадут для этого причину.
Простой пример потока заказа
Портативный поток событий начинается в базе данных, а не в брокере. Представьте checkout-сервис, который принимает платёж, сохраняет заказ и в той же транзакции добавляет ещё одну строку в таблицу outbox. Эта строка может содержать ID события, имя события order.paid, ID заказа и payload, который нужен остальной системе.
Эта мелочь очень важна. Если приложение сохранит заказ, но упадёт до публикации события, строка outbox всё равно останется. Ничего не потеряется, и вам не придётся полагаться на транзакции конкретного брокера, чтобы всё было безопасно.
Затем воркер опрашивает таблицу outbox, забирает неопубликованные строки и отправляет их через тонкий адаптер. Адаптер скрывает клиент брокера, поэтому воркер вызывает один метод вроде publish(eventName, payload). За этим методом один и тот же поток можно сегодня направить в Redis, а позже — в RabbitMQ, NATS или Kafka.
Email-сервис подписывается на order.paid и отправляет чек. Реальные системы ломаются скучно, поэтому этот сервис должен считать временные ошибки нормой. Если у провайдера писем случился timeout, сервис повторяет попытку через короткую задержку. Если он получает одно и то же событие дважды, он проверяет ID события в небольшой таблице обработанных событий и пропускает дубль.
Вот как выглядит чистая версия потока:
- Checkout сохраняет заказ и строку outbox вместе.
- Воркер читает ожидающие строки и публикует их через адаптер.
- Email-сервис повторяет временные сбои.
- Email-сервис игнорирует повторные доставки.
В локальной разработке это тоже остаётся простым. Вы можете запустить checkout-приложение, базу данных, воркер и email-consumer на одном компьютере, а потом заменить только адаптер, когда захотите протестировать другой брокер. В этом и есть практическая сторона архитектуры Node.js без привязки к брокеру: бизнес-поток остаётся тем же, а меняется только транспорт.
Ошибки, из-за которых смена брокера обходится дорого
Многие библиотеки Node.js для событийных приложений сначала выглядят портативными. Проблемы начинаются, когда код приложения знает слишком много об одном брокере и слишком мало о самом событии.
Распространённая ошибка — вызывать SDK брокера прямо из контроллеров или сервисных методов. Express-роут, который импортирует клиент Kafka или NATS, на первый день кажется безобидным. Через полгода логика публикации оказывается в десяти файлах, обработка ошибок отличается в каждом месте, а любая миграция превращается в поиск с заменой плюс охоту за багами.
Логика ретраев создаёт такой же хаос. Некоторые команды прячут циклы повторов прямо в хендлерах, с собственными sleep, счётчиками и catch-блоками. Это работает, пока не понадобятся другие правила ретраев, отложенная обработка или dead-letter. По возможности выносите политику повторов за пределы бизнес-логики. Хендлер должен решать, успешно ли выполнена работа, произошёл ли сбой или нужно подождать. Он не должен управлять собственным мини-планировщиком.
Имена событий тоже быстро устаревают, если команда пропускает версии и проверки схем. order.created — нормальный старт, но изменения накапливаются быстро. Один сервис отправляет новое поле, другой всё ещё ждёт старую форму, и никто не знает, какой payload безопасен. Небольшое правило версий и проверка схем экономят потом много боли.
Функции, завязанные на конкретного брокера, — ещё одна ловушка. Если слишком рано строить архитектуру вокруг точных delay-очередей, правил маршрутизации или гарантий доставки одного продукта, вы перестаёте владеть дизайном. Им начинает владеть брокер. Оставляйте такие возможности на краях системы, пока не поймёте, что они действительно нужны.
Самая дорогая ошибка — отказаться от идемпотентности. Тогда каждый ретрай кажется опасным. Обработчик платежа, который безопасно игнорирует одно и то же событие дважды, намного легче переносить, тестировать и доверять ему. Если ретраи пугают команду, значит дизайн уже хрупкий.
Простое правило помогает: держите код брокера тонким, контракты событий — явными, а хендлеры — безопасными для повторного запуска.
Быстрые проверки перед выбором
Библиотека может отлично выглядеть в демо и при этом потом доставить много боли. Самый быстрый способ заметить проблему — проверить, как она ведёт себя на обычном ноутбуке, в CI и при сбое. Это скажет больше, чем список функций.
Когда вы сравниваете библиотеки Node.js для событийных приложений, держите проверки простыми и практичными:
- Запускайте всё приложение одной командой. Если для локальной настройки нужен длинный README, дополнительные shell-скрипты и ручное создание топиков, люди просто не будут этим пользоваться.
- Прячьте брокер за одним адаптером. Код приложения должен публиковать и принимать сообщения через ваш интерфейс, а не вызывать клиент конкретного вендора из каждого файла.
- Сразу исходите из повторной доставки. Если хендлер видит одно и то же событие дважды, он не должен дважды списывать деньги, отправлять два письма или записывать две строки.
- Дайте службе поддержки место, где можно смотреть на сбои. Понятная строка лога полезна, но небольшая таблица неудачных доставок полезнее.
- Проверяйте неприятные сценарии в CI. Публикация, ретраи, dead-letter и постоянный сбой должны быть покрыты автоматическими тестами.
Небольшой пример делает это очевидным. Если событие order.paid тайм-аутится, а воркер повторяет попытку, вы создаёте один счёт или два? Если вы поменяете один брокер на другой, вы измените один файл адаптера или двадцать файлов сервиса? Ответы показывают, насколько ваша архитектура действительно портативна.
Я бы ещё посмотрел, насколько пакет предполагает определённый стек. Некоторые инструменты незаметно затягивают вас в одну очередь, один облачный шаблон или одну модель хранения. Для маленького pet-проекта это может быть нормально. Для продуктовой команды это быстро становится дорогим.
Если нужен простой критерий, выбирайте инструмент, который облегчает локальную разработку, делает сбои видимыми и позволяет заменить себя без боли. Эффектные функции важны меньше этого.
Что делать дальше вашей команде
Если вы сравниваете библиотеки Node.js для событийных приложений, не усложняйте выбор больше, чем нужно. Начните с одного пакета для событий внутри процесса и одного инструмента для фоновой доставки. Так у команды появится понятное место для публикации событий уже сейчас, а ретраи и отложенная работа не будут засорять request-код.
Небольшая команда обычно двигается быстрее с таким коротким планом:
- Выберите одну event-библиотеку для использования внутри одного сервиса.
- Выберите один инструмент для задач или очередей, чтобы делать ретраи, задержки и backoff.
- Напишите один слой адаптера между приложением и клиентом брокера.
- Добавьте один реальный поток целиком и специально проверьте сценарии сбоев.
Code review важнее списка пакетов. Если событие меняет состояние, ревьюеры должны видеть контракт, правила ретраев, проверку идемпотентности и путь обработки ошибки в одном pull request. Скрытая логика повторов приводит к дорогим багам. Как и расплывчатые названия событий.
Не спешите доказывать, что приложение портативно, просто меняя брокеры в первый же день. Сначала докажите, что граница действительно есть. Прогоняйте один и тот же поток через адаптер в тестах, держите код, завязанный на брокер, в одном месте и убедитесь, что хендлеры остаются скучными. Если смена брокера требует трогать бизнес-логику, значит граница ещё не готова.
Полезная проверка простая: одна схема события, одна политика ретраев, одно правило идемпотентности, один скрипт для локального запуска. Если ваша команда может объяснить эти четыре вещи за пять минут, архитектура, скорее всего, в хорошем состоянии.
Если вам нужен внешний взгляд до того, как система вырастет, Oleg на oleg.is предлагает Fractional CTO помощь по архитектуре ПО, инфраструктуре и практичной автоматизации. Такой обзор особенно полезен на раннем этапе, когда цена изменения курса ещё невысока.


