Библиотеки кэширования Redis для Node.js: что выбрать и почему
Библиотеки Node.js для кэширования на Redis отличаются настройкой, правилами TTL, повторными подключениями и использованием памяти. Сравните инструменты, которые меньше удивляют в повседневной работе.
Содержание
Почему этот выбор быстро становится запутанным
Большинство команд, которые смотрят на Node.js Redis caching libraries, хотят решить простую задачу. Страницы открываются медленно, база снова и снова обрабатывает один и тот же запрос, или сторонний API слишком дорого вызывать на каждый запрос. Кэш убирает повторную работу и делает время ответа менее дерганым.
Путаница начинается потому, что слово «кэш» может означать очень разные вещи. Одна библиотека — это прямой Redis client. Другая прячет Redis за небольшим API get и set. Третья хранит данные только внутри процесса Node.js. Все они могут ускорить запросы. Но ломаются они по-разному, когда появляется реальный трафик.
Неподходящий вариант обычно создаёт скучные, но дорогие проблемы. Данные о продукте устаревают, потому что никто не понимает, откуда взялся TTL. Сессии пропадают, потому что библиотека рвёт и заново открывает соединения под нагрузкой. Локальный кэш выглядит нормально в разработке, а потом разваливается, когда вы запускаете три процесса Node.js и каждый хранит свою копию одной и той же записи.
Бенчмарки тут говорят мало о чём. Сэкономить несколько миллисекунд в маленьком тесте важнее, чем понятное управление TTL, предсказуемые повторные подключения и доступ к тем командам Redis, которые вам реально нужны. В обычной рабочей нагрузке именно это решает, помогает кэш или превращается в ещё один источник багов.
Представьте сервис цен, который кэширует данные на 10 минут. Один процесс обновляет цену, другой всё ещё отдаёт свою локальную копию, и пользователи видят старые числа. Если helper library усложняет инвалидацию, команда начинает избегать её использования. Устаревшие данные накапливаются очень быстро.
Выбор сводится к трём простым вопросам. Может ли ваша команда быстро отлаживать библиотеку? Даёт ли она достаточно контроля над TTL, retry и инвалидацией? И сколько лишней поддержки она добавит, когда приложение будет работать каждый день, а не только на ноутбуке?
Лучший вариант редко бывает самым навороченным. Лучший вариант — тот, который остаётся понятным, когда растёт трафик, проходят деплои и кому-то нужно исправить баг в кэше до завтрака.
Три типа инструментов
Большинство команд сравнивают под одним названием три разных инструмента: прямые Redis clients, cache wrappers и локальные memory stores.
Redis clients
Redis client — это прямой вариант. Библиотеки вроде node-redis и ioredis открывают соединения, отправляют команды и показывают Redis почти таким, какой он есть. Это важно, когда вам нужны pipelines, pub/sub, streams, Lua scripts, transactions, cluster support или аккуратные правила retry.
Этот тип покрывает самый широкий круг задач. Если ваше приложение уже использует Redis для сессий, очередей, rate limits или locks, обычный redis client for node.js часто оказывается разумнее, чем добавлять ещё один слой. Вы сохраняете контроль над командами, поведением TTL и обработкой соединений.
Cache wrappers
Обёртки находятся на один уровень выше. Обычно они предлагают небольшой API вроде get, set и delete, а также дополнительные возможности вроде парсинга JSON или TTL по умолчанию. Это удобно, если вам нужен быстрый кэш и не хочется учить каждого разработчика всему набору команд Redis.
Минус проявляется позже. Обёртка может скрывать функции, которые в итоге всё-таки понадобятся: условные записи, атомарные счётчики, поля хэша или собственные правила истечения. Сначала она кажется аккуратной. Через шесть месяцев может начать давить рамками.
Local memory stores
Локальное хранилище в памяти держит данные прямо внутри приложения. Оно быстрое, простое и почти не требует настройки. Для одного процесса, короткоживущих значений и данных, которые можно дёшево пересчитать, setup с in-memory cache node.js вполне может подойти.
Но всё ломается, когда вы запускаете несколько экземпляров приложения. У каждого экземпляра своя копия, поэтому инвалидация быстро становится запутанной. Если всем серверам нужен один и тот же кэшированный результат, Redis обычно оказывается более чистым решением.
Вот где проходит настоящая граница: прямые clients — когда нужен контроль, wrappers — когда важнее удобство, а local caches — когда общее состояние не имеет значения.
Сначала сравните обработку соединений
Многие Node.js Redis caching libraries на первый взгляд похожи. Они читают, записывают и истекают одинаковые данные. Настоящие различия появляются тогда, когда Redis тормозит, исчезает на минуту или возвращается наполовину после обрыва сети.
Начните с модели подключения. Хорошая библиотека использует небольшое число долгоживущих соединений и делает это поведение понятным. Если helper незаметно открывает лишние сокеты на каждый запрос, растёт потребление памяти и становится намного сложнее понять, где именно произошёл сбой.
Несколько простых проверок быстро отсеивают лишнее. Нужно понять, переиспользует ли библиотека один client на процесс или слишком часто создаёт новые соединения. Ещё важно знать, что происходит после обрыва: повторяет ли она попытку, ставит ли команды в очередь или быстро падает с ошибкой? Если Redis обязателен для сессий, rate limits или координации задач, приложение должно также иметь понятный способ не запускаться, когда Redis недоступен.
Redis connection handling важнее, чем думают многие команды. Некоторые библиотеки бесконечно retry-ят почти без контроля. На первый взгляд это безопасно, но на деле может скрывать сбои и копить команды, которые приложению уже не нужны. Другие падают быстро, и с ними часто проще работать: проблема очевидна, а восстановление чище.
Поведение при запуске — ещё одно слабое место. Если Redis стоит на пути логина или координирует фоновые задачи, разрешить приложению стартовать без готового соединения — значит получить запутанные частичные отказы. Жёсткий провал старта шумнее, но отлаживать его гораздо проще.
Даже если сегодня у вас один узел Redis, стоит проверить, не станет ли позже неудобной поддержка cluster или Sentinel. Некоторые wrappers приятны в локальной разработке, а потом становятся тесными, когда появляются failover, replicas или изменения топологии. Простой client с понятными опциями обычно живёт дольше.
Ещё одна простая и неожиданно полезная проверка: посчитайте, сколько состояния подключения вашей команде нужно хранить в коде приложения. Если вокруг библиотеки приходится писать свои лимиты retry, проверки готовности, shutdown hooks и health reporting, то helper на самом деле не экономит время.
Контроль TTL важнее скорости
Когда команды сравнивают библиотеки для кэширования, слишком много внимания уходит на сырую скорость. На практике чаще важнее управление TTL.
Самая простая модель — fixed TTL. Вы храните значение на 60 секунд, 5 минут или час, а Redis удаляет его, когда время вышло. Это хорошо работает для данных, которые меняются по понятному графику, например для блока на главной странице, который обновляется каждые несколько минут.
Sliding TTL сбрасывает таймер каждый раз, когда кто-то читает значение. Он лучше подходит для сессий, rate limits и временного пользовательского состояния, чем для цен товаров или остатков. Если пользователи продолжают читать устаревшее значение, sliding TTL может продлить жизнь плохим данным дольше, чем вы планировали.
Manual invalidation даёт больше всего контроля. Ваше приложение удаляет или обновляет кэш, когда меняется источник. Это хорошо работает, если команда знает все места, где данные могут измениться. Но если вы пропустите один путь записи, устаревшие записи останутся.
Соответствие между данными и правилами TTL очень важно. Если кэшировать уровень запасов на 10 минут, когда заказы меняются каждые несколько секунд, пользователи увидят неверные числа. Если кэшировать настройки профиля всего на 5 секунд, вы добавите трафик к Redis почти без пользы.
Важно и TTL для отдельных элементов. Одни значения должны жить 30 секунд, другие — 6 часов. Если библиотека усложняет разный срок жизни для разных записей, это быстро чувствуется в реальном проекте.
Большинству команд хватает трёх простых схем: fixed TTL для предсказуемых данных с частым чтением, sliding TTL для состояния вроде сессий и manual invalidation для данных, которые должны меняться сразу.
Важно и поведение при промахе. Если популярная запись истекла и в приложение одновременно пришли 200 запросов, все они могут выполнить один и тот же запрос к базе. Это и есть cache stampede. Хорошие инструменты упрощают single-flight loading, background refresh, stale-while-revalidate или хотя бы простой lock, чтобы один запрос пересобирал значение, а остальные ждали или использовали старое.
Если библиотека даёт слабый контроль над TTL, вам придётся обходить это в коде приложения. Обычно это обходится дороже, чем сразу выбрать более подходящий вариант.
Ежедневная цена
Графики скорости сравнивать легко. А вот повседневные издержки команды ощущают каждый день.
Сложность установки важнее, чем кажется. Клиент, который работает с одним пакетом, коротким блоком конфигурации и обычными async-вызовами, обычно проще в эксплуатации, чем стопка helper-ов поверх helper-ов. Официальный Redis client сначала может казаться немного пустым, но тонкая настройка часто оказывается проще в отладке, чем wrapper, который скрывает состояние соединения и поведение retry.
Лишние пакеты добавляют реальный вес. Каждый serializer, decorator, adapter или helper — это ещё одна версия, за которой нужно следить, и ещё одно место, где может спрятаться баг. Wrapper может сэкономить 20 минут в первый день и отнять часы позже, когда нужно понять, откуда взялся TTL или почему начался цикл reconnect.
Скрытая работа обычно проявляется в рутинных задачах: понять, какой слой установил TTL, прочитать логи, где не видно попыток reconnect, замокать поведение кэша в тестах и убрать старый helper-код, когда команда меняет библиотеку.
Поддержка отладки хорошо отделяет удобные инструменты от раздражающих. Хорошие библиотеки позволяют легко увидеть события подключения, таймауты, промахи и ошибки сериализации. Если для базового логирования поведения кэша или вывода нескольких метрик нужен свой код, библиотека уже требует больше поддержки, чем должна.
Локальное тестирование — ещё один полезный фильтр. Если библиотека работает с обычным локальным Redis container и не требует тяжёлого test harness, команда будет тестировать чаще. А это важно, потому что баги кэша обычно скучные: устаревшие значения, неверные TTL, плохая инвалидация и тихие fallback-ы.
Поздняя замена — часто самая дорогая часть. Если обращения к Redis спрятаны за небольшим внутренним модулем кэша, заменить библиотеку неприятно, но можно. Если всё приложение зависит от специфичных для библиотеки decorators и формата результатов, уборка превращается почти в переписывание. Держите кэш ближе к краю кодовой базы — и будущая версия вас за это поблагодарит.
Практичный способ выбрать
Начните с тех данных, которые больнее всего пересчитывать заново. Если запрос может восстановить значение за 5 ms, кэш может добавить больше сложности, чем пользы. Если же там есть join в базе, внешний API или тяжёлая обработка JSON, это лучший первый кандидат.
Лучший выбор обычно определяется не самым длинным списком функций, а тем, как именно он ведёт себя при сбое. Одним командам нужен маленький локальный кэш и больше ничего. Другим нужен Redis, потому что несколько экземпляров приложения должны читать одно и то же кэшированное значение.
Локальная память хорошо подходит для небольших lookups, которые часто меняются и не требуют жёсткой синхронизации между серверами. Redis лучше подходит, когда несколько процессов Node.js должны видеть один и тот же ответ или когда кэш должен пережить перезапуск приложения. Вместе они тоже могут работать хорошо: локальная память — для самых горячих чтений, Redis — для общего состояния.
Назначайте одно правило TTL для каждого типа данных, а не для каждого endpoint. Сессионные данные, сведения о продукте, счётчики rate limit и отрендеренные фрагменты должны истекать по-разному. Команды попадают в проблемы, когда разработчики ставят случайные TTL во время работы над фичами и потом никогда их не приводят к одному стандарту.
Прежде чем окончательно выбирать redis client for node.js или wrapper, проверьте сценарии, которые ломаются под реальным трафиком. Перезапустите Redis, пока идут запросы. Заставьте одну команду зависнуть и дойти до timeout. Запустите приложение с пустым кэшем. Проверьте, что происходит, когда локальная память хранит устаревшие данные после обновления.
Добавьте метрики до широкого запуска кэша. Отслеживайте hit rate, miss rate, попытки reconnect, задержку команд и evictions. Без этого кэш может казаться быстрым в локальном тесте и всё равно тормозить страницы в продакшене.
Реалистичный пример общего кэша
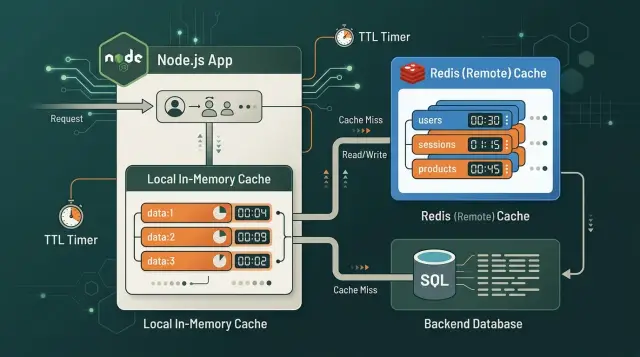
Представьте pricing API, который получает цены от поставщиков, добавляет вашу наценку и возвращает итоговую цену примерно за 250 ms. На одном сервере Node.js небольшой локальный кэш может сократить повторные запросы примерно до 20 ms. Это выглядит отлично.
Но всё меняется, когда вы запускаете три или четыре сервера приложений за load balancer. На Server A в памяти может лежать свежая цена, на Server B кэша может не быть вообще, а Server C может всё ещё хранить более старое значение. Пользователи начинают получать разное время ответа, а иногда и разные цены.
Redis решает эту проблему общего состояния. Все серверы читают и пишут одно и то же кэшированное значение, поэтому один запрос прогревает кэш для всех. Это особенно важно, когда трафик распределяется между многими экземплярами или вы масштабируетесь в пиковые часы.
Здесь часто хорошо работает простой подход. Кэшируйте каждую цену товара в Redis примерно на 60 секунд. Держите маленький локальный кэш на 5–10 секунд, чтобы сократить повторные чтения Redis на одном и том же сервере. Когда из админки или из синхронизации с поставщиком приходит обновление цены, сразу удаляйте ключ в Redis.
Такой микс даёт скорость и не позволяет устаревшим данным задерживаться надолго. Короткий локальный TTL ограничивает расхождение между серверами, а инвалидация в Redis делает изменения общими.
При всплесках трафика разница становится особенно заметной. Без Redis каждый сервер в разное время промахивается по локальному кэшу и нагружает upstream pricing source. С Redis один сервер пересчитывает цену, сохраняет её, а остальные переиспользуют результат. Вам всё равно нужна защита от stampede, когда TTL истекает, но даже простой lock сильно сокращает дублирующую работу.
Для небольших команд обычно подходит такой практический раздел: local cache — для горячих повторных чтений внутри одного процесса, Redis — для всего, что должно оставаться общим и предсказуемым.
Ранние ошибки
Команды часто добавляют Redis, а потом пытаются кэшировать почти всё. Обычно это сначала кажется удачным, а потом заканчивается устаревшими данными, лишними багами и кэшем, которому никто не доверяет.
Каталог товаров, login session и feature flag не должны истекать одинаково. У цен TTL может быть коротким, потому что они часто меняются. Сессиям обычно нужен более долгий срок жизни и аккуратные правила обновления. А feature flags могут сломать релиз, если один сервер держит старое значение даже несколько минут.
Большие объекты — ещё один ранний сюрприз. Команда кэширует полный профиль пользователя, результат поиска или огромный JSON-документ, и время ответа становится хуже, а не лучше. Redis быстрый, но приложению всё равно нужно сериализовать данные перед записью и снова парсить их после чтения. В Node.js эта цена быстро заметна, когда объекты большие или запросов становится много.
Тихие fallback-ы — ещё одна плохая привычка. Запрос к Redis падает, приложение молча идёт в базу, а в логах почти ничего нет. С виду это безопасно, но на деле оно неделями скрывает реальные проблемы. Потом база получает весь трафик, задержка растёт, а никто не замечает, что Redis уже с прошлой недели работал плохо.
Ограничения по памяти тоже начинают мешать раньше, чем многие ждут. Если не задать понятные лимиты размера и правила eviction, Redis начинает удалять значения так, что со стороны приложения это выглядит случайным образом.
Скучная стартовая политика часто оказывается правильной: кэшируйте только медленные чтения, которые часто запрашивают; задавайте TTL по типу данных; держите payloads маленькими; логируйте ошибки Redis достаточно подробно, чтобы по ним можно было действовать; и задавайте лимиты памяти до того, как вырастет трафик. Эти правила простые, и именно поэтому они работают.
Проверки перед финальным решением
Быстрый демонстрационный запуск может скрыть проблемы, которые потом стоят вам недель. Прежде чем выбирать библиотеку, проверьте несколько базовых вещей:
- Убедитесь, что TTL можно задать в одном очевидном месте и проверить оставшийся TTL, не копаясь в коде wrapper-а.
- Остановите Redis на минуту в staging и посмотрите, как ведёт себя приложение. Оно должно падать понятным образом и чисто восстанавливаться.
- Проверьте, можете ли вы удалить одну запись, удалить группу записей и намеренно обновить данные, когда меняется источник.
- Найдите метрики, которые можно измерить сразу: hit rate, cache latency, использование памяти и количество reconnect.
Самая важная проверка для меня — восстановление после сбоя. Отключите Redis-соединение, подождите 60 секунд, потом верните его. Если запросы начинают копиться, логи взрываются или приложение продолжает отдавать сломанное состояние кэша, выбирайте другую библиотеку или делайте более тонкий слой поверх client-а.
Команды, которые работают с лёгкой операционной моделью, обычно предпочитают инструменты, которые можно наблюдать и отлаживать без догадок. Это хороший стандарт, который стоит перенять.
Что делать дальше
Если у вас небольшое приложение и оно работает на одном или двух процессах Node.js, начните с локального кэша. Он быстрый, дешёвый и понятный. Если приложение уже использует несколько workers, background jobs или больше одного сервера, берите простой Redis client и управляйте TTL в коде, чтобы все сервисы следовали одним и тем же правилам.
Растущие системы обычно лучше всего работают с простым Redis client и тонким helper-слоем, которым владеет сама команда. Так сохраняется контроль над обработкой соединений, retry и правилами истечения, но поведение не прячется слишком глубоко внутри пакета. Смешанные нагрузки часто требуют сразу двух уровней: local cache для очень горячих чтений и Redis для общих данных, которые должны видеть несколько процессов.
Не тестируйте это на всём продукте. Выберите один реальный endpoint, который уже создаёт нагрузку, измерьте задержку и нагрузку на базу до кэширования, добавьте один слой кэша, задайте TTL, который соответствует тому, как часто меняются данные, и в течение недели отслеживайте hit rate, устаревшие ответы и количество Redis connection. Такой маленький эксперимент расскажет больше, чем долгий спор.
Если хотите получить второе мнение перед более широким запуском, oleg.is — хороший пример того, какой практический Fractional CTO help подходит для такой задачи. Oleg Sotnikov работает со стартапами и небольшими командами над lean infrastructure, AI-first engineering и архитектурными решениями, которые должны оставаться достаточно простыми для ежедневной работы.
Часто задаваемые вопросы
Стоит ли начинать с обычного Redis client или с cache wrapper?
Начните с обычного Redis client, если нескольким процессам Node.js нужно делить один и тот же кэш или если вы уже используете Redis для сессий, очередей или rate limits. Обёртку выбирайте только тогда, когда требования действительно простые и вам надолго достаточно get, set и delete.
Когда локального in-memory cache достаточно?
Локальная память хорошо подходит, если трафик обрабатывает один процесс, данные легко пересчитать заново, а небольшое рассогласование не мешает пользователям. Как только у вас несколько серверов или воркеров, каждый процесс хранит свою копию, и устаревшие данные быстро становятся проблемой.
Как выбрать правильный TTL?
Выбирайте TTL по типу данных, а не по endpoint. Для данных с частыми чтениями и более-менее предсказуемыми изменениями начинайте с fixed TTL, для сессий — с sliding TTL, а для значений, которые должны обновляться сразу, используйте manual invalidation.
Когда стоит использовать sliding TTL?
Sliding TTL подходит для состояния, похожего на сессии, потому что активные пользователи продлевают жизнь своим данным. Не используйте его для цен, остатков или других значений, которые должны истекать вовремя, иначе старые данные будут жить дольше, чем нужно.
Как не допустить устаревания данных на нескольких Node.js-серверах?
Используйте Redis как общий кэш и держите локальный кэш очень коротким — часто всего на несколько секунд. Затем удаляйте или обновляйте запись в Redis сразу после изменения исходных данных, чтобы все экземпляры приложения видели одно и то же обновление.
Что должно делать приложение, если Redis недоступен?
Сделайте так, чтобы приложение падало предсказуемо и понятно. Если Redis нужен для входа, rate limits или координации задач, не запускайте приложение без доступного Redis; если Redis только ускоряет чтение, логируйте сбой явно и делайте fallback, не скрывая проблему.
Как предотвратить cache stampede?
Пусть один запрос пересобирает значение, пока остальные ждут, используют старое значение или читают новое после того, как оно попадёт в Redis. Простой lock или single-flight helper обычно заметно сокращают дублирующую работу базы данных.
Плохо ли кэшировать большие JSON-объекты?
Большие payloads часто вредят больше, чем помогают, потому что Node.js всё равно должен сериализовать их при записи в кэш и снова парсить при чтении. Лучше кэшировать более мелкие фрагменты или финальный результат, который дороже всего считать.
Что нужно мониторить после внедрения Redis caching?
Смотрите на события подключения, повторные подключения, задержку команд, hit rate, miss rate и использование памяти. Если библиотека скрывает эти показатели или делает их неудобными для логирования, ежедневная отладка быстро становится утомительной.
Как безопаснее всего внедрять кэширование в Node.js-приложении?
Сначала протестируйте один медленный endpoint, измерьте задержку и нагрузку на базу до и после, а затем наблюдайте кэш неделю. Такой небольшой запуск покажет, действительно ли TTL, инвалидация и поведение при reconnect работают под обычным трафиком.


