Библиотеки идемпотентности Go для платежей и задач синхронизации
Библиотеки идемпотентности Go помогают платежным API и задачам синхронизации переживать повторные запросы, возвращать один и тот же результат и обеспечивать одну надежную запись в хранилище.
Содержание
Почему появляются дублирующие записи
Чаще всего дублирующие записи появляются из-за обычного сбоя, а не из-за какой-то драматичной ошибки. Запрос доходит до вашего сервера, код сохраняет платеж или вставляет строку, а потом ответ так и не возвращается вызывающей стороне. Клиент видит таймаут и считает, что ничего не произошло.
Это предположение часто неверно. Запись могла завершиться за долю секунды, а сеть потеряла ответ сразу после этого. Когда приложение повторяет попытку через несколько секунд, оно отправляет то же самое намерение еще раз, и ваш обработчик может принять его за совершенно новую работу.
С платежами это быстро становится дорогим. Клиент снова нажимает «Оплатить», потому что экран завис. Ваш backend теперь получает два корректных запроса на одну и ту же покупку. Если вы создадите новое списание оба раза, у вас уже не платежная проблема. У вас возвраты, обращения в поддержку и проблема с доверием.
Потоки синхронизации ломаются тише. Задача импорта записывает одну запись клиента, а потом падает до того, как пометит эту запись как завершенную. После перезапуска задача снова читает тот же источник и вставляет еще одну копию. Одна лишняя строка кажется мелочью, пока она не начнет попадать в отчеты, письма и последующие задачи.
Конкурентность добавляет еще один путь к дубликатам. Два воркера могут почти одновременно взять одно и то же событие из-за повторной доставки, позднего подтверждения или слабой блокировки. Каждый воркер думает, что именно он выполняет задачу. Каждый воркер пишет.
Обычно причины простые:
- клиент повторяет запрос после таймаута
- пользователь дважды нажимает одну и ту же кнопку
- очередь еще раз доставляет то же событие
- воркер перезапускается посреди обработки
Ничего из этого не редкость. Повторные попытки — нормальное поведение в продакшене. Именно поэтому библиотека идемпотентности Go так важна: она помогает сервису понять, что второй запрос — это то же самое действие, а не новое. Без такой проверки одна потерянная отдача может превратиться в дублирующее списание или в задачу по уборке, которую потом придется делать вручную.
Где именно в процесс попадают повторные попытки
Повторные попытки обычно начинаются еще до того, как ваш обработчик увидит проблему. Клиент отправляет запрос, сервер делает запись, а затем ответ теряется или приходит слишком поздно. Клиент считает, что вызов не удался, и отправляет тот же запрос еще раз. Так одно действие пользователя превращается в две записи.
На слабых соединениях это постоянно происходит в мобильных приложениях. Телефон переключается между сетями, приложение ждет слишком долго, и пользователь снова нажимает «Оплатить», потому что на экране ничего не изменилось. Первый запрос к этому моменту уже мог дойти до вашего сервера.
Браузеры добавляют свои сложности. Медленная страница оформления заказа провоцирует обновление, двойной клик или отправку через кнопку «Назад». Ни одно из этих действий не означает, что пользователю нужны два заказа. Обычно это значит, что страница плохо объяснила, что происходит.
Некоторые повторные попытки приходят из систем, которыми вы управляете:
- Воркер очереди завершает запись в базу, но не успевает отправить подтверждение. Очередь считает, что ничего не произошло, и снова доставляет ту же задачу.
- Cron-задача импортирует 8 000 записей, останавливается на 7 200 и на следующем запуске начинает с начала, потому что не сохранила прогресс.
- API-клиент ждет 10 секунд, хотя ваш сервер продолжает работать 12 секунд и в конце все-таки фиксирует изменение.
- Балансировщик или прокси может повторить вызов к upstream, если видит разорванное соединение.
Поэтому обработка дублирующих запросов начинается не в бизнес-логике. Если смотреть только на код платежей или синхронизации, вы упускаете половину картины. Повторная попытка часто стартует в приложении, браузере, очереди, планировщике или сетевом пути.
Это важно, когда вы выбираете библиотеки идемпотентности Go. Помощник, который сохраняет ключ уже после записи, в некоторых сценариях приходит слишком поздно. Нужно смотреть на весь путь: кто повторяет запрос, когда именно он это делает и отправляет ли он тот же самый body, тот же ключ идемпотентности или вообще ничего из этого.
Хорошая проверка очень простая. Отключите ответ после успешной записи и посмотрите, что начнет повторяться. Обычно вы обнаружите больше одного источника.
Идемпотентность и дедупликация — это не одно и то же
Идемпотентность и дедупликация решают похожие задачи, но делают разную работу. Идемпотентность означает, что один и тот же запрос всегда дает один и тот же результат. Если клиент дважды отправит «списать заказ 123 на $50» из-за таймаута, ваш API должен вернуть один результат, а не создать два списания.
Дедупликация уже уже по смыслу. Она пытается заметить повтор и проигнорировать его. Это хорошо работает для потоков событий, импортов, вебхуков и задач синхронизации, где одна и та же запись может прийти больше одного раза.
Разница важна, потому что повторяющийся ввод все равно может требовать ответа. При идемпотентности вы часто сохраняете первый результат и затем возвращаете его снова для следующих попыток. При дедупликации вы обычно просто отбрасываете лишнее событие и двигаетесь дальше. При этом вызывающая сторона может вообще не увидеть исходный результат.
Платежам часто нужны оба уровня сразу. Уровень API использует ключ идемпотентности, чтобы повторный запрос получил тот же ответ. Уровень воркера или сообщений тоже делает дедупликацию, потому что платежные шлюзы, очереди и вебхуки могут позже отправить то же сообщение еще раз.
Сначала выберите fingerprint запроса, а уже потом пишите код. Этот fingerprint определяет, что именно для системы значит «тот же запрос». В платежах это может быть ключ идемпотентности от клиента или серверная комбинация вроде ID продавца, ID заказа, суммы и валюты. В задаче синхронизации это может быть внешний ID записи плюс источник.
Слабый fingerprint быстро создает проблемы. Если строить его только по ID пользователя, два настоящих заказа могут слиться в один. Если строить его по случайному токену повторной попытки, одно и то же списание может пройти дважды.
Большинство библиотек идемпотентности Go помогают со storage, блокировками и повтором сохраненных ответов. Но они не выбирают fingerprint за вас. Это ваша задача, и именно здесь начинается множество ошибок в обработке дублирующих запросов.
Полезное простое правило: идемпотентность один раз отвечает на тот же запрос и повторяет тот же ответ, а дедупликация просто выбрасывает лишнюю копию. В идемпотентности платежей в Go обычно нужны оба подхода.
Путь запроса, который всегда возвращает один результат
Хороший идемпотентный поток делает одну простую вещь: он дает один и тот же ответ на один и тот же запрос, даже если клиент отправит его дважды. Это важно, когда телефон теряет соединение после нажатия «Оплатить», а приложение повторяет попытку секунду спустя.
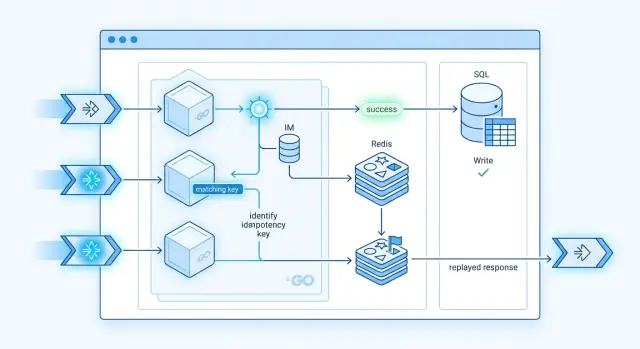
Самый безопасный вариант начинается до любых побочных эффектов. Не вызывайте платежного провайдера, не пишите заказ и не ставьте следующее задание в очередь, пока не проверите общее хранилище, которое видят все воркеры.
Если клиент передает ключ идемпотентности, используйте его. Если нет, соберите стабильный hash запроса из полей, которые определяют операцию. Hash должен игнорировать шум вроде временных меток или trace ID, иначе вы будете считать тот же запрос новым.
Простой поток выглядит так:
- Прочитайте запись идемпотентности по ключу или hash.
- Если нашли завершенную запись, верните сохраненный результат.
- Если ничего не нашли, создайте запись с уникальным ограничением и пометьте ее как
in_progress. - Только воркер, который выиграл эту вставку, выполняет запись.
- После успеха сохраните тело ответа, код статуса и любой внешний идентификатор, а затем верните их.
Именно на шаге резервирования многие команды ошибаются. Два запроса могут прийти одновременно, и оба могут пройти проверку «существует ли запись». Уникальный индекс, правило вставки один раз или короткая блокировка убирают эту гонку.
Когда приходит вторая повторная попытка, обработчик не должен снова запускать бизнес-логику. Он должен прочитать завершенную запись и воспроизвести тот же ответ. Если первый воркер все еще работает, можно немного подождать и опрашивать запись или вернуть временный статус, который подскажет клиенту повторить запрос с тем же ключом идемпотентности.
Postgres хорошо подходит для этого, потому что дает транзакции и уникальные ограничения в одном месте. Redis тоже может подойти, но только если аккуратно учитывать срок жизни и время блокировки. Для многих команд один надежный table — более чистый вариант.
Храните достаточно данных, чтобы ответ всегда был одинаковым. Одного только кода статуса недостаточно. Сохраняйте фактический результат, а также ID провайдера или ID строки, который доказывает, что запись уже произошла.
Полезные помощники на Go, которые стоит проверить
Большинство команд не решают обработку дублирующих запросов одним пакетом. Обычно они комбинируют тонкую HTTP-обертку, быстрый cache и надежное правило в базе данных. Такая смесь работает лучше, чем погоня за одним «магическим» решением.
Когда люди ищут библиотеки идемпотентности Go, им обычно нужны две вещи: не дать обработчику сделать одну и ту же работу дважды и вернуть тот же ответ при повторной попытке. Эти задачи связаны, но это не одно и то же.
Хорошая отправная точка — middleware. Он может читать заголовок Idempotency-Key, строить fingerprint запроса и оборачивать обработчик еще до начала любого платежа или записи. Если тот же запрос вернется через несколько секунд, middleware может вернуть сохраненный код статуса и body вместо повторного запуска бизнес-логики.
Но этой обертке все равно нужно место для хранения состояния. Обычно выбирают следующее, и каждый вариант решает свою часть задачи:
- Redis хорошо подходит для коротких окон повторных попыток. Блокировка
SETNXили маленькая запись с TTL могут остановить быстрые повторы и дать быстрый доступ. - SQL-таблицы с уникальными ограничениями дают надежную защиту. Уникальный индекс на что-то вроде
(account_id, idempotency_key)или бизнес-идентификатор может заблокировать вторую запись даже после перезапуска. x/sync/singleflightполезен внутри одного процесса Go. Если два goroutine одновременно запрашивают одну и ту же работу, он сводит их к одному выполнению.- У потребителей очередей должен быть свой защитный слой. Сначала сохраните message ID или event ID в таблицу обработанных записей, а подтверждение отправляйте только после фиксации записи в базе.
Redis быстрый, но не должен быть последней линией защиты для платежей. TTL истекают, cache очищают, а сеть ломается в самый неподходящий момент. Если вы списываете деньги с карты или создаете счет, держите надежную запись в SQL и, когда возможно, фиксируйте побочный эффект и запись идемпотентности в одной транзакции.
singleflight полезен, но его легко применить неправильно. Он работает только внутри одного процесса. Если ваш API запущен на трех pod'ах, каждый pod все равно может выполнить тот же запрос, если его не заблокирует Redis или SQL.
У воркеров очереди та же проблема, только в другой форме. Брокер может дважды доставить одно и то же сообщение после таймаута или падения воркера. Если задача синхронизации импортирует клиента ext_123, сохраните этот внешний ID или message ID в таблице с уникальным ограничением еще до того, как объявите задачу завершенной.
Практический шаблон простой: middleware для захвата запроса, Redis для быстрого подавления повторов, SQL для финального решения «да или нет» и singleflight для шумных всплесков внутри одного экземпляра. Этот стек скучный, и именно поэтому он выдерживает повторные попытки.
Пример платежа: списать один раз, ответить дважды
Клиент нажимает «Оплатить», платежный провайдер принимает списание, а потом сеть теряет ответ по пути обратно. Ваш API выглядит так, будто он упал, хотя деньги уже ушли. Через несколько секунд приложение повторяет тот же вызов оформления заказа.
Этот второй вызов обязательно должен нести тот же ключ идемпотентности. Ваш сервис на Go проверяет этот ключ до того, как снова обратиться к платежному шлюзу. Если он находит завершенную запись для этого ключа, он пропускает шаг списания и возвращает сохраненный результат первого вызова.
Обычно простая запись хранит:
- текущий статус
- body ответа, который нужно вернуть
- срок действия
- сам ключ идемпотентности
На практике первый запрос записывает запись со статусом processing, отправляет списание, а затем обновляет запись на succeeded или failed с точным body ответа. Когда приходит повторная попытка, обработчик читает эту строку и отправляет клиенту тот же JSON. Клиент видит один ответ, даже если endpoint вызвали дважды.
Для платежей это важно, потому что «скорее всего списали» — этого недостаточно. Если второй запрос снова дойдет до шлюза, вы можете списать один и тот же заказ дважды. Если вместо этого вернуть первый сохраненный ответ, оформление заказа останется скучным, а это именно то, что нужно.
Небольшой пример все проясняет. Допустим, заказ 4819 стоит $49. Первый POST /checkout истекает по таймауту после того, как шлюз вернул charge ID ch_123. Ваш сервис сохраняет статус успеха, результат шлюза и срок действия, например 24 часа. Приложение повторяет запрос с тем же ключом идемпотентности. Вместо создания ch_124 ваш API возвращает исходный успешный payload с ch_123.
Срок действия не дает таблице разрастись бесконечно. Выбирайте окно, которое покрывает реальные повторные попытки и случаи из поддержки. Для платежей команды часто хранят такие записи дольше, чем ожидают, потому что клиенты повторяют попытки поздно, а у финансовой команды вопросы возникают еще позже.
Пример синхронизации: импортировать одну запись только один раз
Синхронизация CRM очень часто ломается самым обычным образом. Исходная система отправляет обновление клиента, сеть таймаутится, а потом то же обновление приходит снова через несколько секунд. Если воркер считает оба события новой работой, вы получите две записи, грязные логи и иногда двух клиентов в базе.
Более безопасный воркер дает каждому входящему изменению стабильную идентичность. Для задач синхронизации это обычно означает внешний ID клиента плюс номер версии или временную метку источника. Если CRM говорит, что клиент crm_4821 изменился в 2026-04-12T10:15:00, эта пара должна описывать только одно изменение, даже если воркер увидит его дважды.
Простое правило для воркера
Храните одну локальную запись клиента на каждый внешний ID и заставьте базу данных соблюдать это правило. Затем разрешите воркеру применять обновления только тогда, когда входящая версия новее уже сохраненной.
На практике поток очень простой:
- Воркер получает клиента
crm_4821с версией17. - Он проверяет, была ли версия
17для этого внешнего ID уже применена. - Если нет, он выполняет upsert для записи клиента.
- Если да, он пропускает запись и фиксирует повторное попадание.
Этот upsert важен. Без него две повторные попытки могут устроить гонку и вставить две строки еще до того, как код приложения это заметит. Уникальный индекс на внешний ID останавливает это на уровне базы данных. Версия или временная метка добавляют еще один слой защиты, чтобы старая повторная попытка не перезаписала более новое обновление.
Именно здесь дедупликация для задач синхронизации отличается от обычной проверки повторной попытки. Вы не только блокируете точные дубликаты. Вы еще и решаете, какое обновление победит, когда события приходят не по порядку.
Журнал задач должен это показывать. Одна запись говорит, что воркер применил клиента crm_4821 версии 17. Следующая запись для той же версии говорит: повторное попадание, изменений не записано. Этот лог скучный, и это хорошо. Это значит, что одно и то же обновление клиента может дважды попасть на endpoint, но в базе останется один аккуратный результат.
Ошибки, которые все еще создают дубликаты
Даже с хорошими библиотеками идемпотентности Go дубликаты все равно проскакивают, если fingerprint запроса или правило хранения выбраны неправильно. Большинство ошибок возникает из-за мелких решений, которые на тестах выглядят безобидно, а под реальным потоком повторных попыток ломаются.
Одна из частых ошибок — хешировать поля, которые меняются при каждой повторной попытке. Если в hash входит временная метка, trace ID, случайный nonce или время получения запроса, одно и то же бизнес-действие каждый раз получает другое значение идемпотентности. Пользователь нажимает «Оплатить» один раз, клиент повторяет запрос, а сервер думает, что получил два разных запроса.
Локальная память — еще один тихий провал. Она работает на одном ноутбуке и ломается в продакшене в момент, когда вы запускаете два экземпляра приложения, перезапускаете pod или выкатываете новую версию. Один сервер помнит первый запрос, другой — нет, и оба пишут. Для идемпотентности платежей в Go нужно общее хранилище, которое переживает перезапуски.
Сроки хранения тоже создают проблемы. Команды часто держат записи дедупликации всего несколько минут, потому что это кажется безопасным и дешевым. Потом медленная мобильная сеть, задержка в очереди или таймаут шлюза сдвигают повторную попытку за пределы этого окна. Вторая попытка приходит после истечения записи, и система снова создает то же списание или импорт.
Порядок тоже важен. Если вы вызываете платежный шлюз до того, как зарезервировали запись идемпотентности, два воркера могут начать гонку. Оба пойдут в шлюз, а потом оба попытаются сохранить результат. К этому моменту ущерб уже нанесен. Сначала зарезервируйте запись идемпотентности, пометьте ее как выполняющуюся, и только потом вызывайте внешнюю систему.
С ошибками 500 нужно быть особенно осторожным. Ответ 500 от приложения не всегда означает «ничего не произошло». Код может вернуть ошибку уже после того, как платежный провайдер принял списание, или после того, как база зафиксировала строку. Если считать любой 500 безопасным для повторной попытки, обработка дублирующих запросов ломается именно там, где это особенно важно.
Более безопасное правило выглядит так:
- Стройте значение дедупликации только из стабильных бизнес-полей.
- Храните записи в общем, надежном хранилище.
- Держите их достаточно долго для самой медленной реалистичной повторной попытки.
- Резервируйте запись до начала побочных эффектов.
- После 500 проверьте, не завершилась ли первая попытка, прежде чем повторять запрос.
Последний шаг очень помогает и в задачах синхронизации. Если воркер импорта падает после записи строки 842 из 1 000, слепой повтор может записать строку 842 дважды, если только задача не умеет спросить: «Я уже сделал именно эту запись?»
Быстрая проверка перед выпуском
Даже при хороших библиотеках идемпотентности Go небольшие пробелы все равно создают дублирующие записи. Проверьте поток как минимум на двух экземплярах приложения. Если экземпляр A обрабатывает первый запрос, а экземпляр B получает повторную попытку, оба должны читать и писать через одно общее хранилище. Локальная map подходит для демонстрации. Она ломается в тот момент, когда вы масштабируетесь.
Сделайте формат ключа идемпотентности стабильным для всех клиентов. Если мобильное приложение отправляет один формат, а веб-приложение — другой, одно и то же действие может превратиться в две записи. Выберите один формат, задокументируйте его и отбрасывайте плохие ключи как можно раньше. Скучные правила работают лучше, чем хитрые.
Путь повторного ответа должен совпадать с исходным результатом полностью. Если первый вызов вернул 201 с JSON-body, второй вызов должен вернуть тот же 201 и тот же body. Не переключайтесь на 200 и не добавляйте пометку, что ответ пришел из cache. Такие мелкие различия ломают вызывающую сторону и скрывают ошибки.
Перед выпуском проверьте следующее:
- Все экземпляры приложения используют одно общее хранилище для записей идемпотентности.
- Все клиенты строят один и тот же ключ идемпотентности для одного и того же действия.
- Повторный ответ возвращает тот же код статуса и тот же body, что и первый успешный запрос.
- Метрики считают hits, misses, locks и expiries.
- Плановая задача очистки удаляет старые записи до того, как таблица выйдет из-под контроля.
Метрики показывают, где поток начинает расходиться. Резкий рост misses часто означает, что один из клиентов изменил способ формирования ключей. Рост количества locks может означать медленные обработчики или воркеры, которые не завершаются. Числа по expiries подсказывают, работает ли задача очистки по расписанию.
Еще один тест ловит очень много проблем: отправьте 20 одинаковых запросов одновременно. Вам нужна одна запись в хранилище и 20 одинаковых ответов. Если вы получаете что-то другое, не выпускайте это в продакшен.
Что делать дальше
Начните с того endpoint'а, который обходится дороже всего, если срабатывает дважды. Для многих команд это «создать платеж», «создать счет» или «импортировать запись». Сначала исправьте один болезненный путь, а не пытайтесь сделать идеальным каждый обработчик сразу.
Первую версию держите простой. Добавьте одно хранилище, которое сохраняет ID операции, fingerprint запроса, статус и финальный ответ. Один этот шаг дает больше, чем три middleware-пакета, которые просто надеются, что они друг с другом согласуются. Некоторые библиотеки идемпотентности Go помогают с заголовками, блокировками или cache-обертками, но именно хранилище решает, вернется ли при повторной попытке первый ответ или будет сделана новая запись.
Потом попробуйте сломать все специально. Отправьте один и тот же запрос дважды. Убейте воркер после записи в базу, но до ответа. Принудительно вызовите таймаут клиента и повторите запрос, пока первый вызов еще работает. Попросите кого-нибудь из команды нажать кнопку отправки пять раз подряд. Эти тесты простые, и именно они ловят ошибки, которые обычно создают дублирующие списания или дублирующие импорты.
Короткий чеклист помогает не расползтись в сторону:
- выберите один endpoint с реальной бизнес-стоимостью
- сохраните состояние операции до побочных эффектов
- воспроизводите сохраненный ответ для того же запроса
- протестируйте таймаут, повтор, перезапуск и одновременную отправку
Задачи синхронизации нуждаются в том же подходе. Перезапущенный импорт должен видеть «уже обработано» и идти дальше. Он не должен гадать.
Если нужен внешний взгляд, Oleg Sotnikov может помочь как Fractional CTO. Он работает с проектированием API, lean-инфраструктурой и AI-augmented development setup, так что может посмотреть и на путь запроса, и на поведение в продакшене.
Начните с одного endpoint'а на этой неделе. Маленькая таблица с уникальным ограничением и сохраненным ответом лучше, чем хитрая схема, которая все равно пропускает два списания.


