Библиотеки Go для вебхуков: подписи, повторы и логи
Библиотеки Go для вебхуков помогают командам проверять подписи payload, отслеживать попытки доставки и воспроизводить сбои с меньшим количеством самописного кода и слепых зон.
Содержание
Почему с вебхуками быстро становится сложно
Вебхуки на бумаге выглядят просто. Сервис отправляет HTTP-запрос, ваше приложение его читает, и работа начинается. Путаница появляется, когда приходит реальный трафик и одно и то же событие прилетает дважды, приходит с опозданием или доходит до одного сервиса, но не до следующего.
Дублирование доставки — обычная, а не редкая история. Отправитель может повторить попытку, потому что ваш сервер ответил слишком медленно, балансировщик оборвал соединение или деплой перезапустил приложение в неудачный момент. Если ваш код считает каждую доставку новой, одно действие клиента может создать два письма, два изменения статуса или два списания.
Неверные подписи добавляют ещё один слой проблем. Запрос с первого взгляда может выглядеть совершенно нормально: валидный JSON, ожидаемое имя события, знакомые заголовки. Но если вы пропустите проверку подписи payload, можно принять поддельный запрос или отклонить настоящий из-за крошечного изменения тела — например, пробелов, кодировки или middleware, которое слишком рано прочитало тело.
Таймауты усложняют отладку, потому что скрывают настоящую причину сбоя. Отправитель знает только, что ваш endpoint не ответил вовремя. Ваша команда может видеть лишь размыту ошибку в одном сервисе, отсутствие логов в другом и никакой понятной записи о том, какой payload вообще дошёл. Без логирования попыток доставки людям остаётся только гадать.
Потом появляются точечные исправления. Один сервис хранит повторы в Redis, другой пишет сбойные события в Postgres, а третий просто логирует ошибку и надеется, что отправитель попробует ещё раз. В итоге у вас уже не одна система для вебхуков. У вас их четыре, и все с разными правилами.
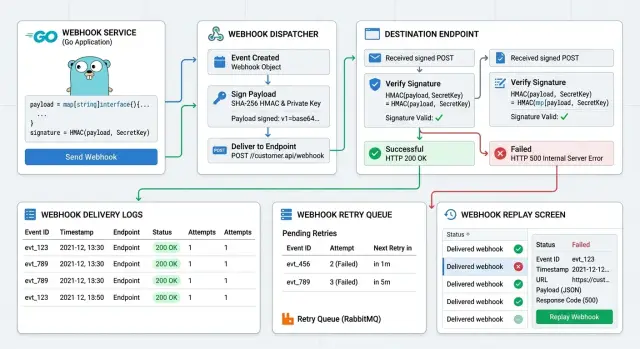
Именно поэтому библиотеки Go для вебхуков так важны. Они не решают абсолютно всё, но сильно сокращают количество вспомогательного кода вокруг проверки подписей, повторов, идемпотентности и воспроизведения сбойных вебхуков.
Что нужно вашей Go-настройке с первого дня
Большинство ошибок вебхуков начинается с одного плохого решения: считать HTTP-хендлер всей системой. Более безопасная Go-настройка держит путь запроса коротким и сохраняет достаточно деталей, чтобы потом объяснить любой сбой.
Сначала прочитайте сырое тело запроса и сохраните эти байты без изменений. Многие провайдеры подписывают оригинальный payload, поэтому если хендлер слишком рано распарсит JSON, проверка подписи может не пройти, даже если отправитель всё сделал правильно.
Запускайте проверку подписи payload до того, как начнёте доверять любому полю в теле. То есть до разбора бизнес-данных, до обновления записей и до запуска фоновых задач. Даже лучшие библиотеки Go для вебхуков не спасут поток, который доверяет непроверенному вводу.
После успешной проверки подписи сохраните ID события провайдера и результат каждой попытки обработки. Нужен простой след, который показывает, что произошло, а не загадка, которую придётся собирать по логам.
Полезная запись обычно включает:
- сырое тело запроса и нужные заголовки
- ID события у провайдера
- время начала и окончания попытки
- финальный статус и текст ошибки
Уберите повторы из пути самого запроса. Если зависимая система медленная или база данных перегружена, отправителю всё равно нужен быстрый ответ от вашего endpoint. Перенесите повторы в очередь или воркер, чтобы одна временная проблема не превращалась в гору дублирующихся доставок.
Важна и возможность воспроизведения. Один сбойный event во время деплоя не должен заставлять вас менять код, вручную запускать curl или придумывать payload из памяти. Сохраняйте достаточно данных, чтобы при необходимости воспроизвести одно событие с тем же телом и заголовками, и помечайте это воспроизведение как новую попытку.
На бумаге это звучит скучно. В продакшене это экономит часы.
Выбирайте библиотеки под каждую задачу
Большинство команд продвигается дальше с небольшим набором узкоспециализированных инструментов, а не с одной огромной вебхук-фреймворк-системой. Хорошие библиотеки Go для вебхуков часто представляют собой просто стандартные части, которые хорошо делают одно дело, а затем аккуратно складываются вместе.
Для HTTP-endpoint начните с net/http, если хотите минимум лишних деталей. Добавьте chi, когда нужен аккуратный роутинг и middleware без тяжеловесности. Используйте gin только если ваше приложение уже работает на нём и команде нравится его стиль. Вебхукам не нужен тяжёлый веб-слой.
Для проверки подписи payload стандартного пакета crypto/hmac обычно достаточно. Он делает логику понятной: прочитать сырое тело, построить ожидаемый digest, сравнить его за постоянное время и решить, принимать ли событие. Если провайдер даёт маленький helper-пакет для своих заголовков и правил по времени, это может сэкономить время, но только если он не прячет слишком много.
Логированию с самого начала нужна структура. slog — хороший вариант по умолчанию в современном Go. zerolog — тоже отличный выбор, если вашей команде важны скорость и компактные JSON-логи. В обоих случаях логируйте одни и те же поля каждый раз: провайдер, ID события, ID доставки, результат проверки подписи, HTTP-статус, число повторов и время обработки.
Для хранения PostgreSQL трудно превзойти. Используйте pgx, если нужен прямой контроль и хорошая производительность. Используйте sqlc, если хотите типизированные запросы и меньше ошибок в ручном доступе к данным. Сохраняйте сырое тело запроса, нужные заголовки, текущий статус и каждую попытку доставки. Это даёт вам логирование попыток доставки и сильно упрощает воспроизведение сбойных вебхуков.
Повторы должны жить в очереди воркеров, а не в обработчике запроса. Asynq легко начать использовать, и он хорошо подходит для отложенных повторов. gocraft/work — тоже надёжный вариант, если ваша команда уже использует Redis-задачи.
Лёгкий набор по умолчанию выглядит так:
chiдля роутингаcrypto/hmacдля проверки подписи payloadslogдля JSON-логов- PostgreSQL с
pgxилиsqlc Asynqдля обработки повторов вебхуков
Такой стек хорошо закрывает скучные части, а именно это и нужно.
Проверяйте подписи до того, как доверять payload
Многие ошибки вебхуков начинаются с одной маленькой ошибки: приложение сначала парсит JSON, а проверяет подпись позже. Это меняет порядок. Отправитель подписал точные сырые байты, а не ваш распарсенный struct. Если вы поменяете пробелы, нормализуете поля или пересоберёте тело, проверка может не пройти, даже если событие настоящее.
В Go прочитайте r.Body один раз в срез байтов и сохраните этот срез без изменений для проверки. Используйте то же сырое тело, когда строите HMAC или другую проверку подписи. Только после успешной проверки стоит распарсить JSON в структуру и передавать его бизнес-логике.
Безопасный поток выглядит так:
- прочитать сырое тело как байты
- найти подходящий секрет по заголовкам запроса или конфигурации endpoint
- быстро отклонить запрос, если секрета нет или он неизвестен
- проверить окно времени, если провайдер его передаёт
- сравнить ожидаемую и полученную подписи с
subtle.ConstantTimeCompare
Проверка по времени важнее, чем многие думают. Если отправитель передаёт подписанную временную метку, старые запросы нужно считать подозрительными. Повторно отправленный payload с валидной подписью всё равно может навредить, если ваше приложение примет его через несколько часов. Небольшое окно, часто в несколько минут, снижает риск, не ломая нормальную доставку.
Используйте сравнение за постоянное время каждый раз. Обычное сравнение строк может выдать крошечные различия во времени. В Go subtle.ConstantTimeCompare — простое решение, которое убирает догадки.
Быстро отклоняя неизвестные секреты, вы также держите логи чище. Если вы обслуживаете вебхуки для нескольких клиентов, не перебирайте каждый сохранённый секрет, пока что-то не совпадёт. Сначала найдите нужный секрет. Если его нет, верните ошибку авторизации и запишите одну понятную причину.
Небольшой пример с платежом делает это наглядным. Провайдер отправляет событие во время деплоя. Ваш хендлер получает сырое тело, проверяет временную метку, проверяет HMAC и только потом разбирает JSON. Если деплой изменил вашу структуру события, проверка всё равно работает, потому что она зависит от сырых байтов, а не от текущего парсера.
Логируйте попытки, чтобы сбои были понятны
Даже с хорошими библиотеками Go для вебхуков большинство проблем всё равно превращается в разбор логов. Если событие падает в 2:13 ночи, команде нужна одна чистая запись, которая показывает, что пришло, что сделал ваш хендлер и почему провайдер попробовал ещё раз.
Начните с идентификаторов. Сохраняйте имя провайдера, ID события у провайдера и ID доставки для каждой попытки. Эти три поля отвечают на разные вопросы: какая система отправила запрос, какое это было событие и какая именно доставка дошла до вашего endpoint. Когда провайдер повторяет одно и то же событие пять раз, ID события остаётся тем же, а ID доставки меняется.
Небольшой набор полей закрывает большую часть боли:
- имя провайдера
- ID события и ID доставки
- время получения и длительность обработки
- код ответа и текст ошибки
- количество повторов или номер попытки
Время важнее, чем ожидают многие команды. Если ваш хендлер обычно отвечает за 80 мс, а некоторые попытки занимают 9 секунд, это указывает на медленный запрос к базе, блокировку или внешний API. Без замера времени каждый таймаут выглядит случайным.
Сохраняйте достаточно данных запроса, чтобы воспроизвести одно событие без догадок. Обычно это сырое тело, заголовки, нужные для проверки, и финальный результат обработки. Не нужно хранить вообще всё навсегда, но для сбойного события нужен один надёжный снимок. Если платёжное событие сломалось во время деплоя, вы должны суметь воспроизвести сбойный вебхук после исправления и убедиться, что тот же ввод теперь проходит.
Связывайте логи и метрики одними и теми же ID. Когда метрика показывает всплеск ответов 500, вы должны иметь возможность найти один event ID и увидеть все попытки по порядку, количество повторов и то, где хендлер потратил время. Тогда логирование попыток доставки становится полезным, а не шумным.
Повторные попытки и повторное воспроизведение без двойной работы
Сбойная доставка должна попадать в очередь, а не исчезать в логах приложения. Сохраняйте сырое тело, ID события, источник, число попыток, время следующего повтора и последнюю ошибку. Это даёт вам одно место для управления обработкой повторов вебхуков и одну запись, которую команда сможет потом проверить.
Время повтора имеет значение. Если вы каждые 10 секунд бьёте по одному и тому же сломанному endpoint, вы создаёте больше шума и больше нагрузки. Используйте вместо этого backoff: подождите немного после первого сбоя, потом увеличивайте интервал после каждого следующего. Простой график вроде 1 минута, 5 минут, 15 минут, 1 час и 6 часов часто достаточен для небольших систем.
Поставьте жёсткий предел. После фиксированного числа попыток пометьте доставку как сбойную и оставьте её на проверку. Бесконечные повторы скрывают настоящие проблемы, забивают очереди и делают логирование попыток доставки менее читаемым.
Прежде чем воркер что-то делает с payload, проверьте, не изменило ли это событие вашу систему ранее. Сохраните стабильный ID события в таблице до побочных эффектов или, если возможно, вместе с побочным эффектом в одной транзакции. Если воркер снова видит тот же ID, он должен залогировать "already processed" и выйти.
Даже с хорошими библиотеками Go для вебхуков командам всё равно нужен простой путь для воспроизведения. Действие replay должно использовать ровно сохранённый payload и проходить те же проверки подписи и идемпотентности, что и обычная доставка. Именно так вы воспроизводите сбойные вебхуки, не списывая деньги дважды и не отправляя дублирующиеся письма.
Команда повторного запуска полезна только тогда, когда она скучная и предсказуемая:
- Повторно поставить в очередь одно событие по ID
- Сохранить полную историю попыток
- Записать, кто запустил replay
- Записать причину воспроизведения
- Поддержать dry run для проверки логов
Команды с лёгкими процессами обычно любят такую модель, потому что она убирает самодельную склейку. Один воркер читает очередь, одна таблица отслеживает обработанные события, а одна команда replay закрывает редкие случаи, когда нужно вмешаться человеку.
Простая настройка в Go шаг за шагом
Сделайте первую версию скучной. Один HTTP-endpoint и один тип события дают вам чистый путь для проверки подписей, логирования и повторов до того, как появится больше вебхук-трафика. Многие команды ломают систему, добавляя пять провайдеров, три семейства событий и собственные правила уже в первый день.
- Примите запрос и прочитайте сырое тело один раз. Сохраняйте точные байты вместе с заголовками, потому что проверка подписи часто падает, если вы заново кодируете JSON.
- Проверьте подпись и время события до того, как начнёте разбирать что-то полезное. Если временная метка слишком старая или подпись не проходит, остановитесь и верните правильный статус.
- Сохраните попытку доставки до запуска бизнес-логики. Сохраните провайдера, ID события, время получения, выбранные заголовки, сырое тело и статус вроде "received".
- Отправьте событие в воркер или очередь. Ваш HTTP-хендлер должен оставаться коротким: проверить, сохранить, поставить в очередь, ответить.
- Когда воркер завершит работу, отметьте попытку как успешную. Если она упала, сохраните ошибку, запланируйте следующую попытку и оставьте тот же ID события, чтобы повторное воспроизведение сбойных вебхуков не создавало двойную работу.
Потом отделите транспортный код от бизнес-логики. Ваш платёжный код не должен разбираться в формате заголовков, а код проверки подписи не должен знать, как меняются счета. Такое разделение сильно упрощает тестирование проверки подписи payload и обработки повторов вебхуков.
Библиотеки Go для вебхуков помогают, когда вы сохраняете этот контракт маленьким. Пусть один пакет отвечает за проверку запроса, другой — за фоновые задачи, а ваш код решает, что означает событие. Это гораздо легче поддерживать, чем самодельную склейку, размазанную по хендлерам, cron-задачам и разовым скриптам.
Такая схема также делает логирование попыток доставки полезным, а не шумным. Если деплой ломает воркер, вы можете увидеть, отправил ли провайдер событие, приняло ли его приложение и когда именно должен быть следующий повтор.
Реальный пример: одно платёжное событие во время деплоя
Клиент оплачивает заказ в 14:03, ровно в тот момент, когда ваше приложение перезапускается для деплоя. Платёжный провайдер отправляет вебхук, открывает соединение и ждёт. Ваше приложение ещё поднимается, поэтому запрос упирается в таймаут.
Со стороны клиента ничего драматичного не происходит. Он уже заплатил. Путаница начинается внутри бэкенда, если вы не зафиксировали сбойную доставку достаточно чётко.
Хорошая запись в логе даёт достаточно данных, чтобы отследить событие без догадок. Нужны delivery ID провайдера, тип события, статус ответа и хэш тела. Хэш тела важнее, чем многим кажется. Он позволяет подтвердить, что повторная попытка несёт тот же payload, даже если она приходит минутой позже на другом экземпляре приложения.
Простой лог для первой неудачи может выглядеть так:
delivery_id=wh_8f31 event=payment.succeeded status=timeout body_hash=9d4c...
Через две минуты ваше приложение уже в порядке. Провайдер повторяет попытку, либо ваш собственный retry-воркер забирает сбойную доставку из очереди и пропускает её через тот же хендлер. Событие настоящее, подпись по-прежнему проходит, и на этот раз запрос завершается успешно.
Теперь идемпотентность тихо делает ту работу, которая спасает вас от плохого дня. Ваш хендлер проверяет, обрабатывал ли он уже delivery ID wh_8f31 или платёжный intent, который за ним стоит. Если да — он останавливается. Если нет — создаёт запись о платеже один раз, отправляет одно письмо с чеком и выходит.
Без этой проверки один таймаут быстро превращается в двойную работу:
- две записи о списании в базе данных
- два письма с чеком клиенту
- один тикет в поддержку с вопросом, почему так произошло
Именно поэтому командам стоит считать повторы нормальным трафиком, а не крайним случаем. Олег часто продвигает такой подход в продакшен-системах: логировать каждую попытку, сохранять путь для replay и делать каждую доставку безопасной для повторного запуска.
Ошибки, которые приводят к дублированию или потере работы
Большинство ошибок вебхуков начинается с одного неверного предположения: «запрос до нас дошёл, значит можно сразу его обработать». Такой короткий путь вызывает двойные списания, пропущенные обновления и долгую уборку позже.
Частая ошибка появляется первой. Команды парсят JSON до проверки подписи. На первый взгляд это безобидно, но проверка подписи обычно зависит от точного сырого тела запроса. Если ваш код прочитает тело, изменит его форму или снова сериализует, вы уже не сможете доказать, что отправитель подписал именно эти байты. Сначала прочитайте сырой payload, проверьте его, и только потом декодируйте.
Другая проблема возникает, когда команды хранят только обычные логи приложения. Stack trace или строка в stdout редко рассказывают полную историю. Нужна ещё и запись события с ID вебхука, временем доставки, результатом проверки подписи, кодом ответа, числом повторов и финальным статусом. Без этой записи нельзя понять, отправлял ли провайдер событие снова, потерял ли его воркер или ваш код обработал его дважды.
Логика повторов тоже часто подводит. Если вы делаете повтор внутри HTTP-хендлера, вы заставляете отправителя ждать, пока сервер делает лишнюю работу. Это часто заканчивается таймаутом, и провайдер отправляет тот же вебхук снова. Более хороший шаблон прост: принять запрос, сохранить его, быстро ответить и дать воркеру обрабатывать повторы в фоне.
Проверку времени тоже нужно делать аккуратно. Многие схемы подписей включают временную метку, чтобы остановить replay-атаки. Если часы сервера расходятся или окно слишком узкое, вы отклоняете настоящие события. Синхронизируйте время и оставляйте небольшой буфер на сетевую задержку.
Последняя ошибка — воспроизведение старых событий без идемпотентности. Replay должен помогать вам восстанавливаться, а не создавать новый ущерб. Сохраняйте event ID или delivery ID и делайте бизнес-операцию безопасной для единственного запуска. Если платёжный вебхук приходит три раза, система всё равно должна создать один результат, а не три.
Быстрые проверки перед релизом
Библиотеки Go для вебхуков сильно сокращают количество вспомогательного кода, но не доказывают, что ваша схема готова. Прогоните несколько неприятных тестов до выпуска. Десять минут здесь могут сэкономить часы догадок позже.
Начните с одного реального события в не-production среде. Потом заставьте команду отвечать на простые вопросы только по логам. Если одна доставка падает, сможет ли кто-то найти эту попытку, число повторов и последнюю ошибку меньше чем за пять минут? Если нет, логирование попыток доставки всё ещё слишком слабое.
Используйте то же событие, чтобы проверить сценарии, которые обычно ломаются:
- Измените один байт в теле и убедитесь, что проверка подписи payload быстро падает с понятной причиной в логах.
- Отправьте одно и то же событие дважды и убедитесь, что приложение делает работу один раз, а потом фиксирует дубликат.
- Спровоцируйте одну ошибку хендлера, проверьте обработку повторов вебхуков и убедитесь, что следующая попытка сохраняет тот же ID события.
- Воспроизведите сбойный вебхук из сохранённых данных или через админ-инструмент, не трогая код и не делая redeploy.
- Найдите событие по ID и посмотрите всю историю доставки в одном месте, а не в трёх инструментах.
Команды часто тестируют только happy path. Но скучные административные действия не менее важны. Если дежурный инженер не может воспроизвести сбойные вебхуки в 2 ночи без правки кода, у вас есть пробел в инструментах.
Небольшая тренировка помогает. Остановите воркер на минуту, отправьте одно тестовое событие, запустите его снова и посмотрите, как система восстанавливается. Вы хотите скучных результатов: одно сохранённое событие, несколько залогированных попыток и одна успешная запись обработки. Если вы не можете доказать это логами и ID, исправьте проблему до того, как её найдут клиенты.
Что делать дальше
Выберите одного провайдера вебхуков и нарисуйте весь путь на одной странице. Покажите, где ваш Go-сервис принимает запрос, проверяет подпись, сохраняет сырое тело, логирует попытку и отправляет сбои на повтор. Этот документ сэкономит больше времени, чем ещё один helper-пакет.
Если вы сравниваете библиотеки Go для вебхуков, держите первую версию узкой. Начните с одного провайдера, одного типа события и одного потока, который один инженер сможет отладить, не бегая по трём сервисам.
Разумный следующий спринт обычно включает четыре небольшие задачи:
- Проверить подпись payload до того, как код парсит JSON или трогает бизнес-логику.
- Писать одну запись доставки на каждую попытку со временем, ID события, статусом и текстом ошибки.
- Отправлять сбойные доставки в небольшую очередь повторов и добавить команду replay.
- Вместе с командой пересмотреть секреты, срок хранения логов и правила воспроизведения.
Держите очередь повторов скучной. Таблица в базе данных или Redis могут очень долго выполнять эту работу. Если деплой ломает один хендлер на 15 минут, вам нужно одно место, где видно, что упало, и где можно воспроизвести только эти события.
Запишите и правило для дубликатов. Если одно и то же событие приходит три раза, сервис должен проверить event ID и выполнить работу один раз. Команды часто пропускают это правило, потому что оно кажется очевидным, а потом неделями чистят дублированные заказы или повторные письма.
Когда схема начинает обрастать самодельной склейкой, остановитесь и наведите порядок. Олег Sotnikov может помочь спроектировать более чистый Go-бэкенд для проверки вебхуков, повторов и трассировки в роли Fractional CTO или советника. Сделайте всю систему достаточно простой, чтобы один инженер мог проследить сбойное событие от запроса до replay без догадок.


