Библиотеки Go для устойчивости API: практический стартовый набор
Библиотеки Go для устойчивости API помогают быстро добавить rate limits, retries и circuit breakers. Сравните надежные пакеты и соберите безопасный стартовый набор.
Содержание
Что идет не так, когда клиенты или API начинают шуметь
Сервис может выглядеть отлично на code review и все равно падать в продакшене. Чаще всего проблема начинается не с бизнес-логики, а с того, как ведет себя трафик.
Один слишком разговорчивый клиент, один всплеск от cron-задачи или один upstream API, который тормозит 30 секунд, могут превратить спокойную систему в кашу из очередей. Один клиент способен заполнить пул воркеров гораздо быстрее, чем ожидает большинство команд. Если он открывает слишком много соединений или шлет запросы в плотном цикле, его трафик начинает вытеснять всех остальных. Другие пользователи в итоге ждут позади работы, которую нужно было ограничить по скорости, отложить или отклонить сразу.
Медленные upstream-сервисы создают другой вид затора. Ваши обработчики висят на сетевых вызовах, goroutine заняты, сокеты остаются открытыми, а потребление памяти растет. Сначала ничего явно не ломается. Запросы просто становятся все медленнее, пока пользователи не начинают видеть таймауты.
Повторы часто делают инцидент только хуже. Неудачный запрос запускает новый запрос, потом еще один. Сервис, который и так с трудом справляется со 100 вызовами в секунду, внезапно может увидеть 300 или 500, потому что клиенты повторяют попытки одновременно.
Представьте простой Go-сервис, который вызывает payment API, email API и CRM. Payment API начинает тормозить, ваш сервис ждет, клиенты повторяют запросы, а пул воркеров заполняется. Вскоре даже вызовы к email и CRM начинают завершаться по таймауту, потому что процессу уже не хватает свободного дыхания.
Вот почему пользователи могут получать таймауты даже тогда, когда ваша бизнес-логика работает правильно. Код делает нужную вещь. Просто он делает ее слишком поздно, с слишком большим числом активных запросов и на зависимостях, которым уже нужно меньше нагрузки.
Что решают rate limiting, retries и circuit breaker
Когда API или клиент начинают шуметь, сбои редко начинаются с одного большого падения. Сначала накапливаются небольшие задержки. Очереди растут, вызывающая сторона слишком часто повторяет запросы, а слабый upstream получает еще больше нагрузки.
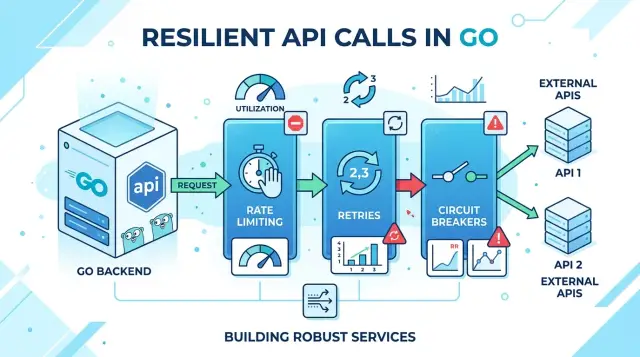
Эти три инструмента останавливают такую цепную реакцию на разных этапах.
Rate limiting ограничивает поток запросов еще до того, как очереди станут некрасивыми. Он защищает ваши воркеры, connection pool и внешние API от одного всплескового клиента или короткого пика трафика.
Retries помогают при кратковременных сбоях, например при сброшенном соединении, коротких проблемах DNS или одном 502 от gateway. Они дают запросу еще одну попытку, когда проблема, скорее всего, быстро исчезнет.
Circuit breaker следит за повторяющимися сбоями. Когда зависимость снова и снова начинает тормозить или возвращать ошибки, breaker открывается и на время блокирует новые вызовы вместо того, чтобы долбить сервис, который и так уже в беде.
Они немного пересекаются, но не заменяют друг друга. Retry не спасет API, который лежит десять минут. Circuit breaker не остановит ваш собственный сервис, если он взял на себя слишком много работы. Rate limit не восстановит запрос, который просто неудачно упал один раз.
Вместе они создают простую страховочную сетку. Rate limiting контролирует, сколько работы попадает в систему. Retries сглаживают краткие сетевые проблемы. Circuit breaker останавливает бесполезные попытки, когда зависимость явно нездорова.
Таймауты и отмена через context связывают всю схему воедино. Таймаут задает жесткий верхний предел ожидания. Context cancellation говорит всем частям запроса остановиться, когда вызывающая сторона ушла, чтобы сервис не тратил CPU, память и исходящие соединения на работу, которая уже никому не нужна.
Если ваш сервис вызывает payment API, а тот замедляется на 20 секунд, rate limiting не дает входящему трафику завалить приложение, retries помогают восстановить несколько единичных сбоев, а breaker прекращает повторные вызовы, как только payment API явно становится проблемой.
Небольшой Go-стек, который закрывает большинство случаев
Чтобы сделать исходящие вызовы безопаснее, не нужен большой фреймворк. В Go лучший базовый вариант обычно — стандартный http.Client и несколько небольших библиотек вокруг него. Так поведение проще читать, тестировать и позже заменять.
Для ограничений внутри процесса трудно найти что-то лучше, чем golang.org/x/time/rate. Он хорошо работает со всплесками, остается компактным и удобно встраивается в handlers или в пути вызова клиентских запросов. Если один шумный пользователь или job начинает заваливать систему запросами, можно притормозить именно этот путь, прежде чем он потянет за собой все остальное.
Для повторов нужен другой инструмент. cenkalti/backoff дает гибкую настройку времени повторов с exponential backoff, лимитами и jitter. Для обычных HTTP-вызовов hashicorp/go-retryablehttp экономит время, потому что уже оборачивает HTTP-клиент и дает hooks для повторов. Так проще повторять транспортные ошибки или ответы 429 и 503, не размазывая retry-циклы по всему коду.
Circuit breaking — это последняя линия защиты. sony/gobreaker хорошо подходит, когда одна зависимость начинает массово зависать или отвечать ошибками. Библиотека маленькая, предсказуемая и легко настраивается. Когда доля ошибок растет, она перестает отправлять весь трафик в проблемную зависимость и дает upstream время восстановиться.
Простой стартовый стек выглядит так:
- stdlib
http.Clientдля таймаутов, transport и повторного использования соединений x/time/rateдля throttlingbackoffилиretryablehttpдля retriesgobreakerвокруг самой слабой внешней зависимости
Этого набора достаточно для многих команд, которые строят API-интеграции, внутренние сервисы или фоновые воркеры. Каждый элемент делает одну задачу, и ни один не заставляет переписывать все с нуля.
Стройте стек в таком порядке
Начинайте с границ отказа, а не с кода повторов. Если запрос может зависнуть навсегда, каждый следующий слой только добавляет давление и делает инцидент сложнее для чтения.
Сначала задайте таймауты и дедлайны через context. Дайте каждому запросу общий бюджет, а затем удерживайте каждый исходящий вызов внутри этого бюджета. Если у вызывающей стороны есть две секунды, один медленный API не должен съедать все время.
Потом ограничьте входящий трафик до того, как пойдут исходящие вызовы. Лимиты для каждого клиента работают лучше, чем один глобальный cap, потому что один шумный клиент не должен замедлять всех остальных.
Добавляйте retries только для временных ошибок. Таймауты, сброшенные соединения, ответы 429 и короткие всплески 5xx — нормальные кандидаты. Держите число повторов небольшим и добавляйте jitter, чтобы клиенты не повторяли запросы одновременно.
После этого поставьте circuit breaker вокруг той зависимости, которая чаще всего падает или тормозит под нагрузкой. Когда он открывается, надо быстро завершать запрос. Быстрая ошибка обычно лучше, чем очередь из зависших goroutine.
И наконец, логируйте решения, которые принимает ваш код. Фиксируйте попытки повторов, события открытия breaker и отклоненные лимитером запросы. Эти сигналы подскажут, у вас плохой клиент, слабый upstream или слишком щедрый таймаут.
Порядок важнее, чем точная библиотека, которую вы выберете. Breaker без дедлайнов все равно ждет слишком долго. Retries без лимитов могут превратить маленькое колебание в лавину.
Хорошо работает простое правило: отклоняйте лишнюю работу заранее, быстро останавливайте медленную работу и повторяйте только тогда, когда есть хороший шанс, что следующая попытка сработает.
Настраивайте лимиты так, чтобы они защищали пользователей и upstream-сервисы
Слишком жесткий лимит раздражает реальных пользователей. Слишком мягкий позволяет одному шумному клиенту замедлить всех остальных. Хорошие лимиты оставляют место для обычных всплесков, а потом отсекают трафик до того, как начнет дрожать ваше приложение, база данных или внешний API.
Начинайте не только с requests per second, но и с размера burst. Многие приложения отправляют трафик рывками. Загрузка страницы может запускать несколько вызовов сразу, а мобильное приложение может переподключиться и выдать короткий всплеск после слабого сигнала. Если пользователь обычно делает два-пять быстрых запросов, burst в один — это слишком жестко. А если клиент внезапно шлет 200 запросов, это уже не нормальный всплеск.
Используйте больше одного лимита, если трафик приходит из разных источников. Глобальный cap защищает сервис целиком, а лимиты для каждого tenant или IP не дают одному клиенту, боту или плохому скрипту уронить остальных. Это особенно важно, когда вы вызываете внешние сервисы с жесткими квотами, потому что один tenant может сжечь общий бюджет для всех.
Когда вы отклоняете трафик, делайте это быстро и понятно. Возвращайте 429 с коротким сообщением и подсказкой по повтору, если она у вас есть. Не позволяйте запросам просто сидеть в очереди до таймаута. Зависание ощущается как баг. Чистый 429 говорит клиенту, что произошло, и освобождает ваших воркеров для тех запросов, которые вы действительно можете обслужить.
Более строгие лимиты ставьте вокруг дорогих путей. Upload файлов, генерация отчетов и fan out вебхуков могут съедать CPU, память, bandwidth или квоту стороннего сервиса намного быстрее, чем обычные чтения. Одного набора правил для стандартных endpoint и другого для дорогих endpoint обычно хватает.
После каждого изменения смотрите на длину очереди, tail latency вроде p95 или p99, частоту 429 и долю ошибок upstream. Если очереди растут или tail latency резко увеличивается, лимит, вероятно, все еще слишком щедрый. Если 429 растут, а система остается тихой, вы, скорее всего, занизили лимит. Лучшее значение почти никогда не оказывается первым.
Повторяйте правильные ошибки и быстро останавливайтесь на остальных
Retries помогают, когда сбой кратковременный. Они делают ситуацию хуже, когда запрос никогда не сможет пройти. Хорошее правило простое: повторяйте перегрузку и сетевые сбои, но не повторяйте плохие данные и проблемы с авторизацией.
На практике повторяйте 429, 502, 503, а также короткие сетевые ошибки, такие как connect timeout, resets и временные DNS-сбои. Останавливайтесь на 400, 401, 403 и validation errors, даже если сервер оборачивает их в обычный ответ 4xx.
Используйте exponential backoff с jitter, чтобы клиенты не повторяли запросы одновременно. Начинайте с малого, примерно с 100–200 миллисекунд, а потом удваивайте ожидание на каждой попытке. Добавляйте немного случайности к каждой задержке. Эта одна деталь удивительно хорошо предотвращает штормы повторов.
Задайте два лимита, а не один. Ограничьте число попыток и общий срок, который вы готовы тратить на retries. Для пользовательского трафика часто достаточно трех попыток. Если общий бюджет на повторы — две секунды, останавливайтесь, как только вы достигли двух секунд, даже если попытки еще остались. Пользователям важнее общее ожидание, а не то, сколько раз код старался.
POST требует особой осторожности. GET обычно безопасно повторять. А POST не всегда безопасен, потому что первый вызов мог уже успешно сработать, даже если клиент не увидел ответ. Если повторить списание, заказ или регистрацию, можно получить дубликаты.
Повторяйте POST только тогда, когда знаете, что операция идемпотентна. Обычно это значит одно из двух: API принимает idempotency key, либо ваша система умеет обнаруживать и игнорировать дубликаты. Если ничего из этого нет, лучше быстро вернуть понятную ошибку.
Для большинства Go-сервисов такой политики достаточно: повторяйте несколько кратковременных сбоев, используйте jitter и быстро отказывайтесь от постоянных ошибок.
Ставьте circuit breaker вокруг слабых зависимостей
Circuit breaker не дает вашему сервису долбить то, что уже и так ломается. Он особенно полезен для зависимостей вне вашего контроля: payment gateway, провайдеров email, fraud checks или медленного внутреннего сервиса другой команды. Если одна из таких зависимостей начинает зависать, breaker может не дать маленькой проблеме съесть все ваши goroutine и бюджет запросов.
Открывайте breaker при устойчивых сбоях, а не после одного неудачного запроса. Простое правило — открывать его после пяти подряд идущих ошибок для low volume вызовов. Для более загруженных endpoint лучше работает правило по доле ошибок, например открывать, если ломается половина из последних 20 вызовов. Выберите одно правило, посмотрите на него в продакшене и потом подстройте.
Делайте период открытого состояния коротким. Десяти-тридцати секунд часто хватает, чтобы upstream восстановился, не блокируя трафик слишком долго. После этого пропускайте немного half-open probe-запросов. Обычно одного-двух проб достаточно. Если они проходят, breaker закрывается. Если снова падают, он быстро открывается обратно.
Fallback помогает только тогда, когда он правдивый. Возвращайте кэшированные курсы валют, устаревшие данные о товарах или упрощенный ответ, если этого достаточно, чтобы пользователь завершил задачу. Не делайте вид, что платежи, проверки личности или записи, которые должны произойти ровно один раз, прошли успешно.
Отслеживайте состояние breaker так же, как любой другой production-сигнал. Считайте открытия, half-open пробы, отклоненные вызовы и время восстановления. Выводите эти события в логи и метрики, чтобы понимать, помог breaker или просто спрятал более глубокую проблему.
Не оборачивайте им каждую функцию. Используйте breaker вокруг слабых зависимостей с понятным режимом отказа и заметным blast radius. Чистому внутреннему helper он не нужен. Как и быстрому локальному вызову, который и так ломается громко и дешево.
Простой пример: один сервис, три внешних вызова
Представьте SaaS-приложение, когда клиент меняет тариф. Запрос попадает в ваш Go-сервис, а тот обращается к Stripe, чтобы списать деньги, к SMTP-провайдеру, чтобы отправить чек, и к customer webhook endpoint, чтобы уведомить другие системы. К этим вызовам не стоит применять одни и те же правила. Если относиться к ним одинаково, одна медленная зависимость может потянуть вниз весь запрос.
Stripe — самый строгий случай. Платежный вызов должен использовать короткий таймаут и очень небольшое число retries. Если Stripe не отвечает вовремя, лучше быстро вернуть ошибку и показать пользователю понятное сообщение. Ждать 20 секунд и повторять пять раз обычно только ухудшает ситуацию. Вы рискуете дубликатами и страницей оплаты, которая выглядит сломанной.
Email устроен иначе. Пользователю не нужно ждать SMTP. Положите задачу на отправку письма в очередь и сначала верните HTTP-ответ. Потом worker может повторять попытки с backoff в фоне. Если почтовый сервер ненадолго недоступен, worker восстановится, не замедляя приложение.
Вебхуки требуют самой сильной защиты. Один шумный tenant может за несколько минут после массового импорта или sync job сгенерировать сотни исходящих вызовов. Поставьте перед webhook client rate limiter для каждого tenant, чтобы один клиент не вытеснял остальных. Затем заверните sender в circuit breaker. Если один адресат начинает зависать или возвращать ошибки, breaker откроется и остановит поток.
Разумная отправная точка проста. Для Stripe — таймаут в две-три секунды и максимум один retry. Для SMTP — асинхронная очередь с несколькими фоновыми retries. Для вебхуков — limiter для каждого tenant плюс breaker на клиенте.
Такое разделение сохраняет быстрые пользовательские запросы, защищает upstream-сервисы и не дает одному проблемному webhook target сжигать воркеры и соединения.
Частые ошибки, из-за которых маленький сбой превращается в инцидент
Даже с хорошими библиотеками неправильные настройки могут легко положить сервис. Большинство инцидентов начинается скромно: один медленный upstream, один всплесковый клиент, один таймаут, который длится чуть дольше, чем надо. А ваш собственный код защиты может превратить это в гораздо большую проблему.
Самая частая ошибка — слоеные retries. Если HTTP-клиент повторяет запрос три раза, сервисный слой делает то же самое три раза, а job runner повторяет еще раз, один неудачный вызов может превратиться в девять и более запросов. Под нагрузкой это становится всплеском трафика, который вы создали сами. За retries должен отвечать только один слой. Все остальные должны быстро падать.
Команды также часто ошибаются с общими limiters. Если поставить один rate limiter перед несвязанным трафиком, шумный путь может блокировать здоровые запросы. Всплеск логинов не должен замедлять доставку вебхуков. Нестабильный API партнера не должен съедать бюджет обычного пользовательского трафика. Разделяйте трафик по route, вызывающей стороне или зависимости, если риски разные.
Circuit breaker может сработать слишком рано при запуске. Сервис поднимается, health checks уже идут, DNS еще прогревается, и breaker открывается еще до того, как начнется реальный трафик. Дайте сервису короткое окно прогрева или игнорируйте стартовые пробы, если они не похожи на обычный поток запросов.
Upstream-сервисы часто сами подсказывают, что делать дальше. Если они присылают заголовок Retry-After, а вы его игнорируете, вы долбите и без того страдающий API в самый неподходящий момент. Уважайте эту задержку, ограничивайте ее и двигайтесь дальше, если ожидание уже слишком длинное для пользователя.
Проблемы DNS и TLS застают многие команды врасплох, потому что тестируют только 500 и таймауты. В реальных системах сбои происходят еще до того, как запрос вообще доходит до сервера.
Более безопасный default простой: держите retries в одном слое, ограничители привязывайте к тому трафику, который они защищают, дайте breaker'у окно на прогрев и до релиза тестируйте DNS, TLS и connection errors. Такая дисциплина избавляет от многих неприятных ночей.
Быстрая проверка перед запуском
Сервис может отлично выглядеть в локальном тестировании и все равно быстро падать под реальным трафиком. Перед релизом проверьте защитные механизмы вокруг каждого исходящего запроса, а не только happy path.
Начните с таймаутов. У каждого вызова к внешнему API должен быть свой таймаут, даже если у client library уже есть дефолты. Если один провайдер зависнет на 30 секунд, эта задержка может разойтись по всему сервису и занять воркеры, которые должны обслуживать других пользователей.
Этот pre-ship checklist ловит большинство неприятных сюрпризов:
- Дайте каждому исходящему вызову свой таймаут, короче общего дедлайна запроса.
- Поставьте жесткий лимит на каждый retry loop. Двух-трех попыток обычно достаточно.
- Сделайте так, чтобы каждый rate limiter возвращал понятную ошибку или HTTP
429для клиентов. - Экспортируйте состояние breaker, чтобы было видно, открыт он, закрыт или в half-open.
- Запустите хотя бы один load test, который включает и всплеск трафика, и частично падающий upstream.
Retries требуют особой аккуратности. Retry без cap может превратить небольшое замедление в затор. Retry без задержки или jitter может сделать то же самое еще быстрее. Если зависимость возвращает явную client error, останавливайтесь сразу. Оставляйте retries для таймаутов, временных сетевых ошибок и небольшого набора ответов 5xx.
Circuit breakers легко добавить и так же легко проигнорировать. Не останавливайтесь на том, открывается breaker или нет. Убедитесь, что вы видите, когда он открывается, как долго остается открытым и восстанавливаются ли пробные запросы или снова падают.
Один тест может рассказать очень многое. Смоделируйте трафик в десять раз выше обычного на несколько минут, пока один upstream замедляется, а другой периодически возвращает 500. Если ваш сервис аккуратно сбрасывает нагрузку, ограничивает retries и держит latency предсказуемой, ваш стартовый стек, скорее всего, в хорошем состоянии.
Что делать дальше вашей команде
Сначала выберите один исходящий client и один upstream API. Это даст вам безопасное место, чтобы проверить подход, прежде чем затрагивать все сервисы. Если первый запуск пройдет удачно, остальная команда быстро скопирует этот паттерн.
Используйте этот первый этап, чтобы договориться о базовых вещах: один rate limiter, одна retry policy, один circuit breaker и одно место для метрик. Делайте код скучным. Цель — убрать догадки, а не строить собственный framework для устойчивости.
Небольшой rollout обычно проходит хорошо, когда команда выбирает клиент, который уже вызывает проблемы с таймаутами, пишет table tests для правил повторов и порогов breaker, выкатывает изменения за feature flag или сначала на малую долю трафика и после релиза смотрит на дашборды, чтобы подстроить числа по реальному трафику.
Table tests важны сильнее, чем ожидают многие команды. Они заставляют формулировать четкие правила вроде повторять 429 и временные сетевые ошибки, но никогда не повторять bad request. То же самое сделайте для breaker. Решите, сколько ошибок его открывает, как долго он остается открытым и как выглядит успешное восстановление.
После поэтапного запуска посмотрите, что реально изменилось. Смотрите на долю таймаутов, долю ошибок upstream, latency запросов и частоту повторов или открытий breaker. Реальный трафик показывает edge cases, которые локальные тесты не ловят. Какие-то лимиты покажутся слишком строгими. Какие-то — слишком мягкими.
Если вам нужен еще один взгляд на границы сервисов, таймауты или инфраструктурные дефолты, Oleg Sotnikov на oleg.is делает Fractional CTO работу со стартапами и небольшими командами. Такой аудит помогает договориться о общих паттернах, не превращая работу над надежностью в длинный внутренний side project.
Часто задаваемые вопросы
Нужны ли мне rate limiting, retries и circuit breaker?
Используйте все три инструмента, если ваш сервис работает с внешними API или получает всплески трафика от клиентов. Rate limiting контролирует, сколько работы попадает в систему, retries помогают пережить краткие сбои, а breaker прекращает вызовы к upstream-сервису, который продолжает падать.
Если добавлять только что-то одно, начните с таймаутов и дедлайнов запросов. Они не дают медленным вызовам надолго занять весь сервис.
С чего лучше начать в Go-сервисе?
Начните с таймаутов и дедлайнов через context. Затем добавьте входные лимиты, потом небольшие повторы для временных ошибок и только после этого breaker вокруг самой слабой зависимости.
Такой порядок помогает остановить накопление медленной работы еще до того, как вы добавите более сложную логику.
Какие Go-библиотеки подойдут как стартовый набор?
Для большинства команд хорошо работает простой набор: http.Client для таймаутов и переиспользования соединений, golang.org/x/time/rate для ограничения потока, cenkalti/backoff или hashicorp/go-retryablehttp для повторов и sony/gobreaker для проблемного upstream-сервиса.
Этот стек остается небольшим и удобным для тестирования.
Как выбрать rate limit, который не будет раздражать реальных пользователей?
Начните с обычного трафика и оставьте запас на короткие всплески. Если пользователи часто делают по два-пять быстрых запросов, такой burst стоит разрешить, а трафик, который сильно выходит за рамки нормы, — уже ограничивать.
Используйте больше одного лимита. Глобальный cap защищает весь сервис, а лимиты по tenant или IP не дают одному шумному клиенту замедлить всех остальных.
Какие ошибки стоит повторять?
Повторяйте только кратковременные проблемы, такие как 429, 502, 503, ошибки соединения, сбросы и временные проблемы DNS. Сразу останавливайтесь на неверных данных, ошибках авторизации и большинстве ответов 4xx.
Держите число повторов небольшим и добавляйте jitter, чтобы клиенты не повторяли запросы одновременно.
Безопасно ли повторять POST-запросы?
Не всегда. GET обычно безопасно повторять, а вот POST может создать дубликаты списаний, заказов или регистраций, если первый вызов на самом деле уже прошел.
Повторяйте POST только тогда, когда API поддерживает idempotency keys или ваша система умеет безопасно обнаруживать дубликаты.
Когда circuit breaker должен открываться?
Открывайте его при повторяющихся сбоях, а не после одного неудачного запроса. Для небольшого трафика может подойти правило пяти ошибок подряд. Для более загруженных путей часто лучше ориентироваться на долю ошибок, например открывать breaker, если ломается половина из последних 20 вызовов.
Держите окно открытого состояния коротким, а затем пропускайте один или два пробных запроса для проверки восстановления.
Должны ли все внешние вызовы использовать одинаковые таймауты и политику повторов?
Нет. Для платежей, почты и вебхуков нужны разные правила. Платежный вызов должен быстро падать с коротким таймаутом и очень небольшим числом повторов. Почту обычно лучше отправлять через фоновую очередь. Для вебхуков нужны лимиты по tenant, а часто еще и breaker.
Если относиться ко всем вызовам одинаково, одна медленная зависимость может потянуть вниз весь запрос.
Какие ошибки превращают небольшой сбой в инцидент?
Сложенные друг на друга повторы создают много проблем. Если HTTP-клиент повторяет запрос, потом это делает сервис, а затем еще и job runner, одна ошибка может превратиться в лавину лишних вызовов.
Общие лимитеры тоже опасны. Если шумный маршрут или tenant делят один bucket с остальным трафиком, здоровые запросы могут начать блокироваться.
Что стоит проверить перед запуском?
Перед релизом проверьте каждый исходящий вызов. Для каждого из них должен быть таймаут короче полного дедлайна запроса, ограничение на число повторов, понятный ответ 429 и экспорт состояния breaker в логи или метрики.
Потом запустите нагрузочный тест, где есть и всплеск трафика, и медленный или нестабильный upstream. Вам нужно увидеть аккуратное сбрасывание нагрузки, короткие ожидания и отсутствие шторма повторов.


