Библиотеки Go для SQL: raw SQL, конструкторы запросов и мапперы для команд
Библиотеки Go для SQL варьируются от database/sql и pgx до Squirrel и sqlx. Сравните скорость, понятность запросов и совместимость с миграциями для растущих команд.
Содержание
Почему команды смотрят дальше полноценных ORM
Полноценные ORM поначалу кажутся быстрым решением. Они прячут большую часть работы с базой за методами моделей, тегами и соглашениями, и на маленьком проекте это выглядит аккуратно. Проблемы начинаются, когда запрос начинает тормозить, preload забирает слишком много данных или join ведёт себя не так, как ожидали. Тогда команда перестаёт читать Go-код и начинает разбирать сгенерированный SQL, поведение драйвера и правила ORM.
Такой разрыв выматывает людей. Обработчик, который выглядел простым, внезапно делает три запроса. Поле, которое казалось необязательным, начинает падать из-за обработки NULL. Небольшое изменение схемы превращается в поиск по моделям, хукам и собственному коду маппинга. База данных делает ту же работу, но путь от запроса до SQL становится гораздо труднее отслеживать.
Многим Go-командам нужно обратное. Им нужны обычные запросы, понятные входные данные и результаты, которые без драматизма превращаются в структуры. Им хочется открыть один файл и увидеть, что именно попадает в базу. Им нужны логи, которые совпадают с кодом, который они написали. Когда запрос тормозит, они хотят настраивать именно этот запрос, а не гадать, что ORM собрал за кулисами.
Небольшие продуктовые команды часто приходят к этому через опыт. Сначала они берут ORM, чтобы двигаться быстрее. Через полгода у них уже есть собственные scopes, правила жадной загрузки, callbacks моделей и исправления запросов, разбросанные по всему проекту. Выпуск новых изменений замедляется, потому что любое изменение в базе даёт побочные эффекты.
Именно поэтому многие команды уходят от полноценных ORM к raw SQL-хелперам, builders или лёгким мапперам. Плюс здесь простой: меньше магии, больше явного кода. Да, вручную писать приходится больше. Но многие предпочитают именно такую цену, потому что код говорит правду.
Выигрыш — в более лёгкой отладке, более простых ревью и понятном пути от HTTP-запроса до SQL-запроса и структуры Go. Когда в кодовой базе уже есть реальный трафик и реальная поддержка, такая ясность важнее удобства.
Что означает контроль в повседневной работе на Go
Для большинства Go-команд контроль — это простая вещь. SQL можно прочитать без копания в слоях, поведение базы предсказуемо, а коллега может проверить изменение за несколько минут. Если запрос начинает тормозить, должно быть одно очевидное место, где это можно посмотреть.
Поэтому многие команды останавливаются на полпути до полноценного ORM. Они не против абстракции. Им просто нужно меньше скрытого поведения. Если join, фильтр или транзакция усложняются, код всё равно должен быть близок к SQL, который реально выполняется в продакшене.
Разные стили решают это по-разному. Хелперы оборачивают низкоуровневую работу вроде сканирования строк, обработки плейсхолдеров или управления соединениями, но сам текст запроса остаётся написан вручную. Builders собирают SQL в коде — это помогает, когда фильтры необязательны или отчёты ветвятся в разные стороны. Мапперы превращают результаты запросов в структуры с меньшим количеством повторений, но SQL обычно остаётся на виду.
Ни один из этих подходов не даёт идеального контроля всегда. Хелперы прямолинейны, но повторяются. Builders уменьшают возню со строками, но могут спрятать финальный запрос, если команда слишком на них полагается. Мапперы делают обработчики аккуратнее, но могут подталкивать к тому, чтобы накидать теги и магию на каждую модель.
Простой пример хорошо показывает этот компромисс. Допустим, у команды есть endpoint со списком заказов, пятью необязательными фильтрами и отдельным запросом на подсчёт. Хелпер отлично подойдёт, если правила почти не меняются. Builder имеет больше смысла, когда продукт постоянно добавляет новые комбинации фильтров. Маппер полезен, когда одна и та же форма результата появляется в нескольких обработчиках.
Обычно лучший вариант — тот, который оставляет меньше сюрпризов именно для этого сервиса. Держите SQL рядом с кодом, который его использует. Логируйте медленные запросы. Проверяйте планы для тех вызовов, которые весь день бьют в базу. Не существует одного стиля, который выигрывает везде, а смесь двух подходов в одной кодовой базе часто работает лучше, чем попытка заставить все сервисы жить по одной схеме.
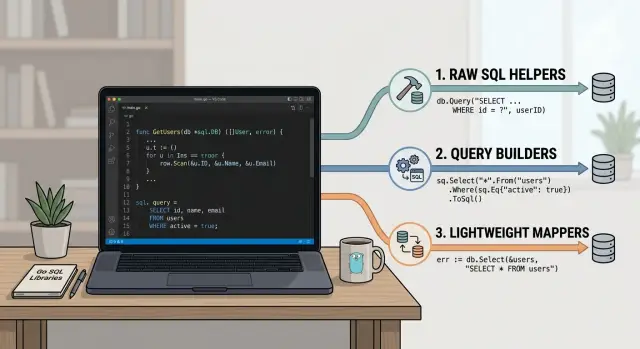
Сырые SQL-хелперы: database/sql и pgx
Большинство Go-команд начинают с database/sql не просто так. Он есть в стандартной библиотеке, не раздувает стек и делает каждый запрос максимально видимым. Если вам нужен контроль над SQL, транзакциями и использованием соединений, этот базовый вариант по-прежнему работает очень хорошо.
database/sql хорошо подходит и для постепенных изменений. Команда может оставить существующий SQL, переносить по одному пакету за раз и не делать большой переписывающий релиз. Это важно, когда вы уже знаете свою схему и не хотите инструмент, который прячет join'ы, фильтры или границы транзакций за большой API.
Компромисс становится очевидным, когда вы начинаете использовать его всерьёз. Вы пишете запрос, запускаете его, вручную сканируете каждое поле, обрабатываете NULL и повторяете это завтра снова. Небольшие приложения с этим живут. Более крупные кодовые базы обычно приходят к большому количеству похожего кода сканирования и нескольким хелперам, которые лишь частично уменьшают повторения.
Для проектов, завязанных на PostgreSQL, pgx часто ощущается лучше, чем опора только на database/sql. Он даёт более сильную поддержку PostgreSQL и открывает функции, которыми команды реально пользуются: лучшую работу с типами, пакетные операции, COPY и поведение, специфичное для PostgreSQL, которое универсальные драйверы обычно сглаживают. Если ваше приложение активно использует массивы, JSONB или большой поток записей, такой контроль обычно стоит того.
pgx также даёт команде более прямую ментальную модель PostgreSQL. Вы меньше боретесь с «низшим общим знаменателем» и больше работаете с той базой, которую действительно выбрали. Для продукта с тяжёлыми отчётами, фоновых задачами или загрузкой событий это экономит время и в разработке, и в отладке.
Хорошо работает простое правило. Используйте database/sql, когда нужна минимальная абстракция и широкая совместимость с драйверами. Используйте pgx, когда PostgreSQL находится в центре приложения и вам нужен весь его набор возможностей. Оставайтесь на сырых SQL-хелперах, если команда уверенно читает SQL и хочет явного поведения.
Цена при этом остаётся той же. Raw SQL-хелперы делают логику видимой, но не убирают ручной маппинг. Разработчикам всё равно нужна дисциплина в переиспользовании запросов, именовании и тестах. Без этого чистый слой данных быстро превращается в россыпь SQL-строк и копипасты со scan-блоками — по сути, это тот же ORM-sprawl, только в другой форме.
Конструкторы запросов для динамических запросов
Builder помогает тогда, когда форма запроса часто меняется. В реальных продуктах это случается чаще, чем люди ожидают. Страница поиска в админке сначала имеет только статус и email, а потом получает диапазоны дат, фильтры по командам, варианты сортировки и ещё один чекбокс почти каждый спринт.
Писать вручную все варианты быстро становится неудобно. Получаются длинные цепочки if, склейка строк и набор почти одинаковых SQL-запросов. Хороший builder делает эту логику понятной, но при этом даёт команде контроль над финальным запросом.
Вот где builders обычно и находят своё место: страницы админского поиска с множеством необязательных фильтров, отчёты с диапазонами дат и сортировкой, выгрузки, где пользователи могут выбирать столбцы или лимиты, и необязательные joins, например когда данные по аккаунту или биллингу нужны только иногда.
Плюс здесь не в магии. Плюс в структуре. Вместо того чтобы склеивать сырые строки, вы добавляете условия по шагам и держите параметры отдельно от текста SQL. Это снижает риск сломанных плейсхолдеров и упрощает ревью.
Необязательные joins — хороший пример. Если отчёту данные о клиентах нужны только иногда, builder может добавлять такой join только тогда, когда фильтр это действительно просит. Это намного аккуратнее, чем держать три или четыре отдельных шаблона запросов, которые со временем начинают расходиться.
Но builders не спасают от плохих SQL-привычек. Они могут сделать плохой запрос проще в написании, а это всё равно плохой запрос. Если команда игнорирует индексы, выбирает все столбцы или продолжает накидывать joins, не проверяя план, builder не поможет.
Здесь важнее несколько привычек, чем сама библиотека. Логируйте финальный SQL и аргументы в разработке. Проверяйте планы запросов для медленных экранов с отчётами. Делайте фильтры предсказуемыми и называйте их понятно. Останавливайтесь, если builder читаеться хуже, чем обычный SQL.
Моя простая позиция такая: используйте builder для меняющихся фильтров, а не для каждого запроса в кодовой базе. Прямые чтение и запись часто остаются понятнее в raw SQL. Builders лучше всего подходят для той неловкой середины, где SQL остаётся обычным SQL, но условия меняются достаточно часто, чтобы ручная склейка строк стала проблемой поддержки.
Лёгкие мапперы, которые сохраняют SQL на виду
Лёгкие мапперы часто оказываются золотой серединой, с которой проще всего жить. Вы по-прежнему пишете SQL вручную, но перестаёте тратить время на повторяющиеся вызовы Scan и ошибки с порядком столбцов.
sqlx — самый типичный пример. Он остаётся близко к database/sql, поэтому ментальная модель остаётся простой. Вы пишете запрос, передаёте аргументы и маппите результат в структуру с db-тегами.
type UserRow struct {
ID int64 `db:"id"`
Email string `db:"email"`
Role string `db:"role"`
}
var user UserRow
err := db.Get(&user, `
SELECT id, email, role
FROM users
WHERE id = $1
`, userID)
Этот небольшой шаг убирает много шаблонного кода. Он также делает SQL простым для чтения на ревью. Никому не нужно гадать, что сгенерировала библиотека, а отладка остаётся прямой, когда запрос начинает тормозить или возвращает не ту форму данных.
Другие инструменты в стиле мапперов, например scany с dbscan, работают по той же идее. Они превращают строки в структуры, не превращая кодовую базу в паутину из моделей, хуков и скрытого поведения запросов. Лучше всего они работают с небольшими структурами, которые соответствуют одному результату запроса за раз.
UserListRow вполне может отличаться от UserDetailRow. Обычно это лучше, чем одна огромная структура User, которая пытается подойти для каждого endpoint'а, отчёта и фоновой задачи. Сначала команды часто сопротивляются этому, но маленькие структуры результата делают изменения безопаснее.
Лёгкие мапперы особенно хороши, когда команде нужны понятный SQL, собственные joins, common table expressions или специфичные для базы возможности без борьбы с системой. Они также хорошо подходят, если у вас уже есть сырые SQL-хелперы и вы хотите просто более удобный опыт разработки, а не полную переписывающую миграцию.
Это не магия. Вам всё равно нужно проектировать запросы, управлять транзакциями и думать об индексах. Для многих команд это хорошая сделка: вы экономите время на скучном маппинге строк, но сохраняете контроль над тем, что попадает в базу.
Как выбрать вариант для вашей кодовой базы
Начинайте с той базы, которую вы уже используете, и с тех запросов, которые уже отправляете в продакшен. Команды часто выбирают библиотеку по вкусу, а потом месяцами исправляют последствия этого выбора. Важнее должны быть схема, объём запросов и места, где что-то ломается, а не мода или привычка.
Разделите работу с запросами на несколько реальных категорий. Стабильные запросы, динамические запросы и пути с большим количеством записей обычно требуют разных инструментов. Запрос на вход в систему или фиксированный отчёт по биллингу можно оставить близко к raw SQL. Экран поиска с десятью необязательными фильтрами часто становится проще с builder. А горячие пути записи обычно выигрывают от прямого SQL и явных транзакций, потому что каждый дополнительный слой скрывает время выполнения и поведение блокировок.
Если ваша команда уже хорошо работает с database/sql, не думайте, что вам нужен более крупный шаг. Во многих кодовых базах database/sql вместе с небольшим хелпером или sqlx для удобства сканирования вполне достаточно. Если вы плотно используете PostgreSQL и хотите более жёсткий контроль, pgx часто выглядит чище, чем добавление маппера поверх всего остального.
Выберите один стиль по умолчанию для большей части нового кода, а затем разрешите несколько исключений. Используйте raw SQL для фиксированных запросов и горячих путей. Используйте builder для экранов и отчётов, где фильтры меняются. Используйте лёгкий маппер только тогда, когда он убирает повторяющийся scan-код и при этом не прячет SQL. Запишите эти правила в репозитории, а не держите в голове у кого-то одного.
Такое правило важнее, чем кажется. Когда каждый сервис использует свой подход, качество ревью падает. Новые разработчики тратят время на изучение внутренних правил, которые меняются от папки к папке.
Проверьте выбор на одном сервисе, прежде чем распространять его на всю кодовую базу. Перенесите небольшой, но реальный участок работы, например внутренний admin API или модуль биллинга. Затем посмотрите на четыре вещи: понятность запросов, трудоёмкость тестов, скорость ревью и то, насколько болезненно ощущаются изменения схемы. Если этот пилот остаётся скучным в хорошем смысле, скорее всего, вы нашли подходящий вариант.
Реалистичный пример из команды
Команда из пяти человек начинает с Rails-приложения, где ActiveRecord используется почти везде. Всё работает, но команда устает от скрытых запросов, неожиданных joins и callbacks моделей, которые меняют логику checkout в местах, где этого никто не ждёт.
Они решают сначала перевести в Go две части продукта: оформление заказа и отчётность. Разделение практичное. В оформлении заказа небольшой набор стабильных запросов, а отчётность меняется каждый месяц, потому что продукт и финансы постоянно просят новые фильтры.
Для оформления заказа команда выбирает raw SQL с pgx для потоков оплаты, заказа и склада. Эти запросы затрагивают деньги, остатки и границы транзакций, поэтому им важно видеть каждый SELECT, UPDATE и COMMIT прямо в ревью кода. Когда кто-то меняет правило скидки, ревьюеры могут прочитать SQL и заметить риск за минуту.
Отчётность получают по-другому. Экран отчётов позволяет фильтровать по диапазону дат, статусу заказа, стране и каналу продаж. Писать это через простую склейку строк быстро становится неудобно, поэтому команда использует builder для этих endpoint'ов. Форма SQL при этом остаётся понятной, но никому не нужно вручную собирать десять версий одного и того же WHERE.
Для read-моделей и небольших админских инструментов они используют лёгкий маппер. Внутренняя страница со списком неудачных платежей или support-экран с последними возвратами не нуждается в тяжёлом подходе. Инструмент вроде sqlx убирает часть шаблонного кода сканирования строк, не пряча сам запрос. Часто это и есть та самая золотая середина в выборе database/sql vs sqlx.
Команда записывает три правила и придерживается их: стабильные бизнес-потоки используют raw SQL, динамический поиск и отчётность используют builder, а внутренние чтения и админ-страницы могут использовать лёгкий маппер.
Такая смесь делает миграцию спокойной. Ревью остаются короткими, потому что у каждого pull request есть понятная форма. Никто не пытается угадать, что сгенерировал ORM, и никто не пытается заново собрать Rails внутри Go. Это важнее, чем выбор «лучшего» инструмента.
Ошибки, которые снова приводят к расползанию, как у ORM
Обычно команды не выбирают грязный слой данных специально. Это происходит по одной маленькой уступке за раз. Сервис начинается с database/sql, потом кто-то добавляет sqlx ради сканирования, другой человек подключает builder для одной страницы отчётов, а в четвёртый пакет тихо попадает инструмент для миграций или генерации моделей. Через полгода никто уже не понимает, какой стиль считается стандартным.
Использовать несколько библиотек в одном сервисе — не всегда ошибка. Проблема начинается, когда каждый решает одну и ту же задачу разным инструментом. Ревью становятся медленнее, баги сложнее отслеживать, а новые разработчики тратят первую неделю на правила, которые никто не записал.
Ещё одна ошибка — прятать SQL в слоях-хелперах, которые никто не читает. Функция вроде GetActiveUsers() выглядит чисто, пока не выясняется, что она вызывает ещё три хелпера, добавляет тихие фильтры и меняет поведение в зависимости от флагов из другого места кода. SQL при этом никуда не исчез. Он просто переехал туда, где его перестали проверять.
Та же проблема возникает с builders. Они помогают, когда фильтры действительно динамические. Но для обычного запроса с одним join и двумя условиями они подходят плохо. Если простой SELECT превращается в длинную цепочку builder-вызовов, код стал хуже, а не лучше. Большинство разработчиков читает SQL быстрее, чем набор связанных method calls.
Признаки обычно знакомы: похожие запросы в одном пакете используют разные библиотеки, на ревью обсуждают Go-код, но пропускают сам SQL, разработчикам нужны helper-функции, чтобы понять базовую фильтрацию, а builders появляются там, где обычный SQL был бы короче.
Тесты не спасают от плохих запросов. Тест может пройти, хотя запрос всё равно сканирует слишком много строк, скрывает случайный cross join или зависит от поведения базы, которое будет мешать при росте. Команды должны проверять SQL так же внимательно, как проверяют Go-код. Читайте текст запроса, смотрите на форму результата и спрашивайте, поймёт ли это следующий человек за минуту.
Если вам нужен контроль без ORM-sprawl, выберите один стиль по умолчанию для каждого сервиса, запишите его и делайте исключения редкими. Это правило звучит скучно. Зато именно оно держит кодовую базу спокойной.
Быстрая проверка перед коммитом
Перед выбором библиотеки возьмите один реальный путь запроса. Используйте простой read, один write и один запрос с необязательными фильтрами. Инструмент может выглядеть аккуратно в демо и при этом начать раздражать, как только команда начнёт менять его каждую неделю.
Первая проверка простая: может ли новый коллега быстро прочитать запрос? Откройте код и попросите человека, который его не писал, объяснить, что именно попадает в базу, какие поля сканируются и куда уходят ошибки. Если ему приходится прыгать через хелперы, сгенерированный код и собственные обёртки, чтобы понять один запрос, это трение быстро расползётся.
Логи важны не меньше, чем стиль кода. Когда что-то начинает тормозить в продакшене, команде нужно видеть финальный SQL, bound-аргументы, если их безопасно выводить, и время выполнения. Если builder или mapper делает запрос приятнее для записи, но сложнее для проверки, отладка становится дорогой. Красивые цепочки методов не помогают, когда никто не видит точный statement, который выполнила база.
Следом проверьте миграции. Команды часто упускают этот момент. Если вы и так пишете миграции на обычном SQL, библиотека, которая оставляет SQL на виду, обычно подходит лучше. Если библиотека толкает вас к совсем другому стилю, чем ваши файлы миграций, у вас может получиться один способ менять схему и другой способ её запрашивать. Такое разделение быстро надоедает.
Тесты должны покрывать скучные случаи, потому что именно там живёт много багов с данными: пустые наборы результатов, NULL в необязательных столбцах, ошибки сканирования из-за неправильных типов полей, а также изменившийся порядок столбцов или пропущенные поля.
Небольшая тестовая таблица покажет очень многое. Попробуйте один nullable timestamp, один JSON-столбец и один left join, который иногда ничего не возвращает. Такая схема скажет вам больше, чем любая таблица возможностей.
Если библиотека остаётся читаемой, показывает реальный SQL в логах, подходит вашему способу делать миграции и проходит эти тесты без странных обходных путей, скорее всего, это безопасный выбор.
Что делать дальше для чистого перехода
Чистый переход начинается с малого. Не меняйте доступ к данным во всей кодовой базе за один проход. Сначала выберите один сервис и один тип запроса, например список с большим количеством чтений или один путь записи с понятными входом и выходом. Тогда у команды будет одна реальная проверка вместо долгого спора.
Выберите что-нибудь скучное специально. Экран поиска с необязательными фильтрами хорошо подходит для builder. Простой поиск аккаунта лучше оставить на raw SQL или небольшой маппер. Старый подход оставьте в остальной части приложения, пока тестируете новый. Ревью станут проще, и вы не получите неделю смешанных стилей.
Напишите одно короткое правило для команды до того, как что-то merge'ится. Сделайте его настолько простым, чтобы новый разработчик понял его в первый же день: используйте raw SQL для фиксированных запросов, которые должны оставаться легко читаемыми; используйте builder только тогда, когда фильтры, сортировка или joins меняются во время выполнения; используйте лёгкий маппер, когда сканирование строк повторяется, но SQL должен оставаться видимым; и держите транзакции, миграции и обработку ошибок явными.
Через две-три недели смотрите не на мнения, а на работу. Посмотрите на время ревью pull request'ов, на баги в запросах, найденные в тестах или продакшене, и на то, сколько кода пришлось поменять, когда поле или фильтр сдвинулись. Если один подход экономит несколько строк, но делает ревью медленнее, такая сделка обычно того не стоит.
Для многих команд правильный ответ — это смесь подходов. database/sql или pgx могут закрывать стабильные пути, а builder — несколько запросов, которые часто меняют форму. Так слой данных не превращается в ещё одну абстракцию, к которой никто не хочет прикасаться через полгода.
Если этот выбор влияет ещё и на скорость продукта, расходы на облако или более крупный рефакторинг, внешняя ревизия может помочь. Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами над Go-архитектурой, инфраструктурой и fractional CTO, и такая миграция хорошо вписывается в этот формат.


